DIFFPOOL - Hierarchical Graph Representation Learning with Differentiable Pooling NIPS 2018
文章目录
-
-
- 1 相关介绍
-
- 相关概念
- 背景介绍
- 模型简介
- 2 相关工作
- 3 DIFFPOOL:可微的pooling方法
-
- 3.1 问题定义
-
- 图神经网络
- 堆叠GNNs和pooling层
- 3.2 通过学习聚类分配矩阵来进行可微的pooling
-
- Q1: 怎样学习聚类分配矩阵S?
- Q2: 假定聚类分配矩阵已存在,如何进行Pooling?
- Permutation invariance排列不变性
- 3.3 Auxiliary Link Prediction Objective and Entropy Regularization
- 4 实验
-
- 数据集
- 模型配置
- Baseline Methods
-
- 基于GNN的方法
- 基于核的方法
- 图分类实验结果
-
- 基于STRUCTURE2VEC的可微pooling
- 运行时间
- DIFFPOOL中聚类assignment分析
-
- 分层的聚类结构
- 稀疏子图结构 vs 稠密子图结构
- 具有类似表示的节点的assignment
- 预先定义的最大聚类数的灵敏度
-
论文:Hierarchical Graph Representation Learning with Differentiable Pooling
可微分pooling分层图表示学习
作者:Rex Ying, Jiaxuan You, Christopher Morris, Xiang Ren, William L. Hamilton, Jure Leskovec
斯坦福大学、南加州大学、德国多特蒙德工业大学
来源:NeurIPS 2018
论文链接:
Arxiv: https://arxiv.org/abs/1806.08804
github链接:https://github.com/RexYing/diffpool
Pyg pooling层实现:https://pytorch-geometric.readthedocs.io/en/latest/modules/nn.html#torch_geometric.nn.dense.diff_pool.dense_diff_pool
介绍视频:
Youtube: https://www.youtube.com/watch?v=tvbxKcy9brE&feature=youtu.be
优酷:https://v.youku.com/v_show/id_XNDEwNTYwNDUyMA==.html?spm=a2hzp.8244740.0.0
图神经网络(GNNs)通过有效地学习节点embeddings,对图表示学习领域有了彻底的革新,并在节点分类和链接预测等任务中取得了最新的成果。然而,当前的GNN图分类方法本质上是平面(flat)的,不能学习图的层次化表示。文中提出了DIFFPOOL模型,这是一个可微的图pooling模块,它可以生成图的层次化表示,并可以以端到端的方式与各种图神经网络架构相结合。DIFFPOOL为深度GNN的每一层的节点学习可微分的聚类分配,将节点映射到一组聚类,然后形成下一个GNN层的坍缩输入(coarsened input)。实验结果表明,与所有现有的pooling方法相比,将现有的GNN方法与DIFFPOOL相结合,在图形分类benchmarks上的平均准确率可提高5-10%,在5个benchmark数据集中有4个达到了state-of-the-art的水平。
1 相关介绍
相关概念
文中涉及到一些比较术语的词汇,先解释一下它们的意思:
- hard assignment:每个数据点都归到一个聚类(cluster),分配矩阵由0和1构成。
- soft assignment:把数据点归到不同的类,分到每个类有不同的概率,分配矩阵由(0,1)之间的小数构成。
- assignment matrix: S ( l ) ∈ R n l × n l + 1 S^{(l)} \in \mathbb{R}^{n_{l} \times n_{l+1}} S(l)∈Rnl×nl+1, n l n_l nl表示在第 l l l层的节点数, n l + 1 n_{l+1} nl+1表示在第 l + 1 l+1 l+1层的节点数, n l > n l + 1 n_l > n_{l+1} nl>nl+1,即行数等于第 l l l层的节点数(聚类数),列数代表第 l + 1 l+1 l+1层的节点数(聚类数)。assignment matrix表示第 l l l层的每一个节点到第 l + 1 l+1 l+1层的每一个节点(或聚类)的概率。
- hierarchical:指类似CNN一样,DIFFPOOL由多层网络堆叠而成。
- downsampling,pooling:池化、下采样,前一层把多个点归到一个聚类,在下一层用一个点表示聚类,达到节点数目降低的效果,整个过程和CNN类似。
- coarsened graph:坍缩了的图,因为按照pooling过程,每一层的一个点代表了前一层的一个聚类的点,所以在逐层传播过程中,图在“粗糙化”或“坍缩”。graph readout、graph coarsening 、graph pooling、graph downsampling都是类似的意思。
- end-to-end fashion:端到端的方式,DIFFPOOL不依赖于其他的聚类算法,类似于一个黑盒子,使用时不用关心中间过程,只需考虑输入输出。
- differentiable:Differentiable模型是可微的,可以采用SGD通过端到端的方式进行训练。
背景介绍
当前GNNs进行图分类的一个主要限制是,它们本质上是平面的(flat),它们沿着图的边传播信息,无法以层次化(hierarchical)的方式聚合信息。目前将GNNs应用于图分类时,标准的方法是为图中的所有节点生成embedding,然后对所有节点的embedding进行全局pooling操作,例如,使用简单的求和操作或神经网络(Gated graph sequence neural networks,ICLR 2016;Neural message passing for quantum chemistry,ICML 2017;Convolutional networks on graphs for learning molecular fingerprints,NIPS 2015等)。这种全局pooling方法忽略了图中可能存在的层次结构,并且不利于研究人员为整个图上的预测任务构建有效的GNN模型。简单来讲,它不希望先得到所有结点的embedding,然后再一次性得到图的表示,这种方式比较低效,而是希望通过一个逐渐压缩信息的过程就可以得到图的表示。
模型简介
文中提出的DIFFPOOL是一个可微的图pooling模块,它可以以层次化和端到端方式适应各种图神经网络架构。DIFFPOOL允许使用更深层次的GNN模型,这些模型可以学习图的分层表示。

- 图1是DIFFPOOL结构示意图
- 在每一层,运行一个GNN模型获得节点的embeddings,再用这些embeddings将相似的节点进行聚类得到下一层的坍缩输入,然后在这些坍缩的图上运行另一个GNN层。整个过程重复 L L L层,然后使用最后的输出表示进行图分类任务。
- 如图所示,层次化的GNN加入了pooling层,能够捕捉图的层次信息,扩大了感受野。但是,这里的Pooled network训练十分困难,需要两个Loss保证网络能够收敛,Pooled network的1,2,3层各不相同,需要分别训练。导致整个网络参数量巨大。
文中证明了DIFFPOOL可以与各种GNN方法相结合,平均提高了7%的准确率,在5个benchmark数据集中有4个达到了state-of-the-art的水平。
2 相关工作
文中工作建立在最近关于图神经网络和图分类的大量研究的基础上。
GNNs被广泛应用于各种任务中,包括节点分类、链路预测、图分类和化学信息学中。在图分类的任务中,应用GNNs的一个主要挑战是从节点embedding到整个图的表示。解决这一问题的常见方法有:
- 简单地在最后一层中将所有节点embedding求和(Convolutional networks on graphs for learning molecular fingerprints,NIPS 2015);
- 引入一个连接到图中的所有节点的“虚拟节点”来求平均值(Gated graph sequence neural networks,ICLR 2016);
- 使用深度学习架构来聚合节点embedding(Neural message passing for quantum chemistry,ICML 2017)。
然而,所有这些方法都有其局限性,即它们不能学习层次结构表示(即,所有节点的embedding都在一个单层中被pool),因此无法捕获许多真实世界中的图的结构。
最近的一些方法也提出了将CNN架构应用于连接(concatenate)所有节点的embedding:
- [PATCHY-SAN] Learning convolutional neural networks for graphs,ICML 2016;
- An end-to-end deep learning architecture for graph classification,AAAI 2018
但这些方法需要学习节点的排序,这通常是非常困难的,相当于求解图同构。
最后,有一些工作通过结合GNNs和确定性图聚类算法来学习层次图表示:
- Convolutional neural networks on graphs
with fast localized spectral filtering,NIPS 2016; - SplineCNN: Fast geometric deep learning with continuous B-spline kernels,CVPR 2018;
- Dynamic edge-conditioned filters in convolutional neural networks on graphs,CVPR 2017
与这些方法不同,DIFFPOOL寻求以端到端的方式学习图的层次结构,而不依赖于确定性的图聚类程序。
3 DIFFPOOL:可微的pooling方法
DIFFPOOL的关键思想是,它提供一个可微的模块去分层地pool图中的节点,从而支持构建深度、多层的GNN模型。
3.1 问题定义
- 定义一个图 G G G为 ( A , F ) (A,F) (A,F),其中 A ∈ { 0 , 1 } n × n A \in\{0,1\}^{n \times n} A∈{0,1}n×n是一个邻接矩阵, F ∈ R n × d F \in \mathbb{R}^{n \times d} F∈Rn×d是节点的特征矩阵(此处为了计数方便,假设节点特征维度为 d d d,实际不固定)
- 假设一个有标签的图集为 D = { ( G 1 , y 1 ) , ( G 2 , y 2 ) , … } \mathcal{D}=\left\{\left(G_{1}, y_{1}\right),\left(G_{2}, y_{2}\right), \ldots\right\} D={(G1,y1),(G2,y2),…},其中 y i ∈ Y y_{i} \in \mathcal{Y} yi∈Y是对应的图 G i ∈ G G_{i} \in \mathcal{G} Gi∈G的标签
- 图分类任务的目标是学习一个映射函数: f : G → Y f: \mathcal{G} \rightarrow \mathcal{Y} f:G→Y。这个函数将一个图映射到一个标签。
- 与标准的有监督机器学习相比,面临的挑战是需要一种从这些输入图中提取有用特征向量的方法。也就是说,为了应用标准的机器学习方法进行分类(例如神经网络),需要一个程序来将每个图转换成一个低维的向量。
- 文中并没有考虑边的特征,作者说使用论文(Dynamic edge-conditioned filters in convolutional neural networks on graphs,CVPR 2017)中的方法可以很容易的扩展文中的算法以支持边的特征
图神经网络
在图形神经网络的基础上,用一种端到端的方式为图分类学习一种有用表示。考虑采用以下通用的“消息传递”的GNNs:
H ( k ) = M ( A , H ( k − 1 ) ; θ ( k ) ) (1) \tag{1} H^{(k)}=M\left(A, H^{(k-1)} ; \theta^{(k)}\right) H(k)=M(A,H(k−1);θ(k))(1)
- H ( k ) ∈ R n × d H^{(k)} \in \mathbb{R}^{n \times d} H(k)∈Rn×d是 k k k层GNN的节点embedding,也就是所谓的“消息”
- M M M是一个消息传播函数,依赖于邻接矩阵和可训练的参数 θ ( k ) \theta^{(k)} θ(k),关于传播函数 M M M的实现有很多,比如可以用GraphSAGE,Neural Message Passing for Quantum Chemistry,GCN等
- 初始化时: k = 1 k=1 k=1,输入的节点embedding为 H ( 0 ) = F H^{(0)}=F H(0)=F
例如,用GCN实现传播函数 M M M:
H ( k ) = M ( A , H ( k − 1 ) ; W ( k ) ) = ReLU ( D ~ − 1 2 A ~ D ~ − 1 2 H ( k − 1 ) W ( k − 1 ) ) (2) \tag{2} H^{(k)}=M\left(A, H^{(k-1)} ; W^{(k)}\right)=\operatorname{ReLU}\left(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} H^{(k-1)} W^{(k-1)}\right) H(k)=M(A,H(k−1);W(k))=ReLU(D~−21A~D~−21H(k−1)W(k−1))(2)
- A ~ = A + I , D ~ = ∑ j A ~ i j \tilde{A}=A+I, \tilde{D}=\sum_{j} \tilde{A}_{i j} A~=A+I,D~=∑jA~ij, W ( k ) ∈ R d × d W^{(k)} \in \mathbb{R}^{d \times d} W(k)∈Rd×d是一个可训练的权重矩阵
- 文中提出的pooling模型可以使用任意一个能实现公式(1)的GNN模型,DIFFPOOL不需要去了解 M M M的实现方式,因此可以直接抽象写为 Z = GNN ( A , X ) Z=\text{GNN}(A,X) Z=GNN(A,X)。
- 一个进行 K K K次迭代公式(1)的GNN可以生成最终的节点embeddings, Z = H ( K ) ∈ R n × d Z=H^{(K)} \in \mathbb{R}^{n \times d} Z=H(K)∈Rn×d,其中 K K K的范围通常是2-6。
堆叠GNNs和pooling层
文中的目标是定义一种通用的,端到端的,可微的策略,使得可以用一种层次化的方式堆叠多层GNN模型。
给定一个GNN模块的输出 Z = GNN ( A , X ) Z=\text{GNN}(A,X) Z=GNN(A,X)和一个图的邻接矩阵 A ∈ R n × n A \in \mathbb{R}^{n \times n} A∈Rn×n,目标是寻找一种方式可以得到一个新的包含 m < n m
这个新的坍缩图(coarsened graph)作为下一层GNN的输入,重复 L L L次就可到了一些列的coarser。因此,目标就是需要学习一种pooling策略,这种策略可以泛化到具有不同节点、边的图中,并且能够在推理过程中能适应不同的图结构。
3.2 通过学习聚类分配矩阵来进行可微的pooling
DIFFPOOL方法通过使用GNN模型的输出学习节点上的聚类分配矩阵来解决上述问题。
Q1: 怎样学习聚类分配矩阵S?
定义第 l l l层学到的聚类分配矩阵为 S ( l ) ∈ R n l × n l + 1 S^{(l)} \in \mathbb{R}^{n_{l} \times n_{l+1}} S(l)∈Rnl×nl+1, n l n_l nl表示在第 l l l层的节点数, n l + 1 n_{l+1} nl+1表示在第 l + 1 l+1 l+1层的节点数, n l > n l + 1 n_l > n_{l+1} nl>nl+1,即行数等于第 l l l层的节点数(聚类数),列数代表第 l + 1 l+1 l+1层的节点数(聚类数)。assignment matrix表示第 l l l层的每一个节点到第 l + 1 l+1 l+1层的每一个节点(或聚类)的概率。
DIFFPOOL算法使用下式生成assignment矩阵 S ( l ) S^{(l)} S(l)和embedding矩阵 Z ( l ) Z^{(l)} Z(l):
Z ( l ) = G N N l , embed ( A ( l ) , X ( l ) ) Z^{(l)}=\mathrm{GNN}_{l, \text { embed }}\left(A^{(l)}, X^{(l)}\right) Z(l)=GNNl, embed (A(l),X(l))
S ( l ) = softmax ( GNN l , pool ( A ( l ) , X ( l ) ) ) S^{(l)}=\text{softmax}\left(\text{GNN}_{l, \text{pool}}\left(A^{(l)}, X^{(l)}\right)\right) S(l)=softmax(GNNl,pool(A(l),X(l)))
- GNN l , pool \text{GNN}_{l, \text{pool}} GNNl,pool表示第 l l l层的pooling GNN
- GNN l , pool \text{GNN}_{l, \text{pool}} GNNl,pool的输出维数对应于第 l l l层预定义的最大聚类数,是模型的超参数
- 使用聚类的邻接矩阵 A ( l ) A^{(l)} A(l)和特征矩阵 X ( l ) X^{(l)} X(l)生成一个assignment矩阵
- 这两个GNN使用相同的输入数据,但具有不同的参数,并扮演不同的角色:embedding GNN为这一层的输入节点生成新的embedding,而pooling GNN生成从输入节点到 n l + 1 n_{l+1} nl+1个聚类的概率。
Q2: 假定聚类分配矩阵已存在,如何进行Pooling?
假设 S ( l ) S^{(l)} S(l)已经预先计算好了。DIFFPOOL层可以表示为: ( A ( l + 1 ) , X ( l + 1 ) ) = DIFFPOOL ( A ( l ) , Z ( l ) ) \left(A^{(l+1)}, X^{(l+1)}\right)=\operatorname{DIFFPOOL}\left(A^{(l)}, Z^{(l)}\right) (A(l+1),X(l+1))=DIFFPOOL(A(l),Z(l)),即生成一个新的邻接矩阵 A ( l + 1 ) A^{(l+1)} A(l+1)和新的embeddings矩阵 X ( l + 1 ) X^{(l+1)} X(l+1)。具体地,可以分成下面两个部分:
X ( l + 1 ) = S ( l ) T Z ( l ) ∈ R n l + 1 × d X^{(l+1)}=S^{(l)^{T}} Z^{(l)} \in \mathbb{R}^{n_{l+1} \times d} X(l+1)=S(l)TZ(l)∈Rnl+1×d
- X i ( l + 1 ) X_i^{(l+1)} Xi(l+1)表示第 l + 1 l+1 l+1层聚类 i i i的embedding,即 G N N l + 1 , embed \mathrm{GNN}_{l+1, \text { embed }} GNNl+1, embed 的输入。
A ( l + 1 ) = S ( l ) T A ( l ) S ( l ) ∈ R n l + 1 × n l + 1 A^{(l+1)}=S^{(l)^{T}} A^{(l)} S^{(l)} \in \mathbb{R}^{n_{l+1} \times n_{l+1}} A(l+1)=S(l)TA(l)S(l)∈Rnl+1×nl+1 - A i j ( l + 1 ) A_{ij}^{(l+1)} Aij(l+1)表示第 l + 1 l+1 l+1层聚类 i i i和聚类 j j j之间的连接强度,即邻接矩阵
在倒数第二层,即 L − 1 L-1 L−1层时令assignment矩阵是一个全为1的向量,也就是说所有在最后的 L L L层的节点都会被分到一个聚类,生成对应于整图的一个embedding向量。这个embedding向量可以作为可微分类器(如softmax层)的特征输入,整个系统可以使用随机梯度下降进行端到端的训练。
Permutation invariance排列不变性
为了对图分类有效,pooling层在节点的各种排列下应该是不变的。
可得如下命题:
令 P ∈ { 0 , 1 } n × n P \in\{0,1\}^{n \times n} P∈{0,1}n×n是任意一个排列矩阵,只要 GNN ( A , X ) = GNN ( P A P T , X ) \text{GNN}(A, X)=\text{GNN}\left(P A P^{T}, X\right) GNN(A,X)=GNN(PAPT,X),那么 DIFFPOOL ( A , Z ) = DIFFPOOL ( P A P T , P X ) \text{DIFFPOOL}(A, Z)=\text{DIFFPOOL}\left(P A P^{T}, PX\right) DIFFPOOL(A,Z)=DIFFPOOL(PAPT,PX)。(即,只要满足使用的GNN方法是排列不变的,那么DIFFPOOL模型就是排列不变的)
证明:假设GNN模型是排列不变的,那么公式(5)和(6)就是排列不变的。由于任何排列矩阵都是正交的,所有在公式(3)和(4)中应用 P T P = I P^{T}P=I PTP=I就可以完成证明。
3.3 Auxiliary Link Prediction Objective and Entropy Regularization
在实践中,仅使用来自图分类任务的梯度信号很难训练pooling GNN(公式4)。这是一个非凸优化问题,并且在训练中pooling GNN很容易陷入局部极小值。为了缓解这个问题,使用用一个辅助的链路预测目标来训练pooling GNN。在每一层 l l l上,最小化 L L P = ∥ A ( l ) , S ( l ) S ( l ) T ∥ F L_{\mathrm{LP}}=\left\|A^{(l)}, S^{(l)} S^{(l)^{T}}\right\|_{F} LLP=∥∥∥A(l),S(l)S(l)T∥∥∥F,其中 ∣ ∣ ⋅ ∣ ∣ F ||\cdot||_F ∣∣⋅∣∣F表示Frobenius范数。深层次上的邻接矩阵 A ( l ) A^{(l)} A(l)是低层assignment矩阵的函数,在训练过程中会发生变化。pooling GNN的另一个重要特性(公式4)是,为每个节点的输出聚类通常都应该接近one-hot向量,以便清楚地定义每个聚类或子图的成员关系。因此,通过最小化 L E = 1 n ∑ i = 1 n H ( S i ) L_{\mathrm{E}}=\frac{1}{n} \sum_{i=1}^{n} H\left(S_{i}\right) LE=n1∑i=1nH(Si)来正则化聚类分配的熵,其中 H H H为熵函数, S i S_i Si为 S S S的第 i i i行。在训练期间,每一层的 L E L_{\mathrm{E}} LE和 L L P L_{\mathrm{LP}} LLP都加入到分类损失中。在实践中,观察到带有side objective的训练需要更长的时间收敛,但是仍然可以获得更好的性能和更多可解释的聚类分配。
4 实验
根据许多最新的图分类方法评估DIFFPOOL,目的是回答以下问题:
- Q1:DIFFPOOL和其他的pooling方法相比怎么样?(如sort pooling和SET2SET方法)
- Q2:DIFFPOOL与GNNs的结合与图分类任务(包括GNNs和基于核的方法)的最新技术相比如何?
- Q3:DIFFPOOL是否可以得到输入图上有意义,可解释的聚类?
数据集
图分类任务中常用的benchmark数据集
- 蛋白质数据集(ENZYMES,PROTEINS,D&D)
- 社交网络数据集REDDIT-MULTI-12K
- 科学协作数据集COLLAB
模型配置
- 在实验中,用于学习节点向量的GNN模型是GRAPHSAGE算法(因为作者发现GRAPHSAGE算法的性能要优于GCN)
- 使用GraphSAGE的“mean”聚合函数,并在每两个GraphSAGE层之后应用一个DIFFPOOL层
- 在数据集上总共使用了2个DIFFPOOL层
- 对于ENZYMES和COLLAB这样的小数据集,1个DIFFPOOL层可以达到类似的性能。每个DIFFPOOL层之后,在下一个DIFFPOOL层或readout层之前执行3层图卷积层。
- 分别用两种不同的稀疏的GraphSAGE模型计算embedding矩阵和assignment矩阵。
- 在2 个DIFFPOOL层的架构中,聚类数量设置为应用DIFFPOOL之前节点数量的25%,而在1个DIFFPOOL层的架构中,聚类数量设置为节点数的10%。
- Batch normalization在GraphSAGE的每一层之后应用。
- 实验还发现,在每一层的节点embedding中添加一个 l 2 l_2 l2正则化可以使训练更加稳定。
- 所有的模型都经过了3000个epoch的训练,当验证损失开始减少时,会提前停止。
- 执行10-fold交叉验证来评估模型性能
两个简化版的DIFFPOOL:
- DIFFPOOL-DET是一个使用确定性图聚类算法(Weighted graph cuts without eigenvectors a multilevel approach,2007)生成assignment matrix的DIFFPOOL模型。
- DIFFPOOL-NOLP是DIFFPOOL的一个变体,没使用链接预测。
Baseline Methods
在图分类的性能比较中,考虑了基于GNN(结合了不同的pooling方法)的baselines以及最先进的基于kernel的方法。
基于GNN的方法
- GraphSAGE with global mean-pooling
- STRUCTURE2VEC (S2V)
- ECC
- PATCHYSAN
- SET2SET
- SORTPOOL
基于核的方法
- GRAPHLET
- SHORTEST-PATH
- WEISFEILERLEHMAN kernel (WL)
- WEISFEILER-LEHMAN OPTIMAL ASSIGNMENT KERNEL (WLOA)
图分类实验结果
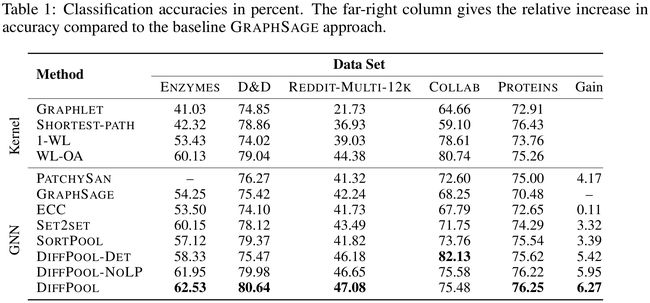
- 表1回答了Q1和Q2
- 简化的模型变体DIFFPOOL-DET在COLLAB基准测试上获得了最先进的性能。这是因为在COLLAB中许多协作图只显示单层的社区结构,而这些结构可以通过预先计算的图形聚类算法很好地捕获
- 一个观察结果是,尽管性能有了显著的提高,但是DIFFPOOL在训练的过程中可能是不稳定的,而且在不同的运行中,即使使用相同的超参数设置,准确性也会有显著的变化
- 增加链接预测使训练更加稳定,降低了不同训练中精度的标准差
基于STRUCTURE2VEC的可微pooling
- 除GraphSAGE外,DIFFPOOL还可以应用于其他GNN架构来捕获图数据中的层次结构。为了进一步回答Q1,还在Structure2Vec(S2V)上应用了DIFFPOOL。
- 使用三层架构的S2V进行实验。
- 在第一种变体中,在第一层S2V之后应用一个DIFFPOOL层,在DIFFPOOL的输出之上再叠加两个S2V层。
- 第二种变体在S2V第一层和第二层之后分别应用一个DIFFPOOL层。
- 两种算法均采用S2V模型计算embedding矩阵,采用GraphSAGE模型计算assignment matrix。
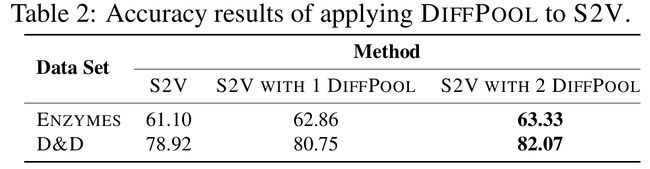
- 表2总结了将DIFFPOOL应用于S2V的分类准确率
- 可以观察到,DIFFPOOL显著提高了S2V在ENZYMES和D&D数据集上的性能。在其他数据集上也观察到类似的性能趋势。
- 结果表明,DIFFPOOL是一种在层次结构进行pool操作的通用策略,有益于不同的GNN体系结构。
运行时间
尽管应用DIFFPOOL需要对assignment matrix进行额外的计算,但DIFFPOOL在实践中并没有带来大量额外的运行时间。因为每个DIFFPOOL层通过提取图的坍缩表示来减少图的大小,从而加快下一层图的卷积运算。具体来说,发现使用DIFFPOOL的GraphSAGE比使用SET2SET pooling的GraphSAGE模型要快12倍,同时在所有的基准测试上仍然获得了显著的更高的准确性。
DIFFPOOL中聚类assignment分析
分层的聚类结构
为了解决Q3问题,将DIFFPOOL通过可视化不同层中的聚类分配。

- 图2:使用来自COLLAB数据集在DIFFPOOL中实现分层聚类分配的可视化图
- 图(a)显示了两层的分层聚类,其中第二层的节点对应于第一层的聚类
- 图(b和c)在不同的图中显示了另外两个例子中第一层的聚类
- 尽管实验中将聚类的数量设置为节点的25%,但GNN会自动学习为这些不同的图分配适当数量的有意义的聚类。
稀疏子图结构 vs 稠密子图结构
- DIFFPOOL学会了以非均匀的方式将节点压缩(collapse)成聚类,并且倾向于将密集连接的子图collapse成聚类。
- 由于GNNs可以有效地在密集的、类似于团的子图上执行消息传递,因此将这样密集的子图中的节点pooling(聚集)在一起不太可能导致结构信息的丢失。这直观地解释了为什么collapse稠密子图是一种有用的DIFFPOOL pooling策略。
- 稀疏子图可能包含许多有趣的结构,包括路径、循环和树形的结构,并且由于稀疏性导致的图中直径很大,GNN消息传递可能无法捕获这些结构。因此,通过分别pooling稀疏子图的不同部分,DIFFPOOL可以学习捕获稀疏图中出现的有意义的结构(如图2所示)。
具有类似表示的节点的assignment
由于assignment网络是根据输入节点及其邻居的特征来计算聚类分配的,所以具有相似输入特征和邻居结构的节点会有相似的聚类分配。
预先定义的最大聚类数的灵敏度
- assignment随着网络的深度和聚类的最大数量 C C C而变化。
- 使用更大的 C C C,pooling GNN可以建模更复杂的层次结构。但是,太大的 C C C会导致更多的噪音和更低的效率。
- 尽管 C C C的值是一个预定义的参数,但pooling网络可以通过端到端训练学习数量适当的聚类。
- 有些聚类可能不被assignment矩阵使用。未使用的聚类对应的列的所有节点的值都很低。在图2©中可以观察到这一点,其中节点主要被分到3个聚类中。
有错误的地方还望不吝指出,欢迎进群交流GNNs(入群备注信息!!!,格式:姓名(或网名) -(学校或其他机构信息)- 研究方向)。
