天池大赛——工业蒸汽量预测
从0开始学大数据分析与机器学习,简简单单写下竞赛心得。本文使用了多种机器学习回归算法,也运用了深度学习pytorch搭建神经网络来进行回归计算。
一、背景介绍
本文记录的是工业蒸汽量赛题,链接:AI训练营计算机视觉-阿里云天池
赛题背景
火力发电的基本原理是:燃料在燃烧时加热水生成蒸汽,蒸汽压力推动汽轮机旋转,然后汽轮机带动发电机旋转,产生电能。在这一系列的能量转化中,影响发电效率的核心是锅炉的燃烧效率,即燃料燃烧加热水产生高温高压蒸汽。锅炉的燃烧效率的影响因素很多,包括锅炉的可调参数,如燃烧给量,一二次风,引风,返料风,给水水量;以及锅炉的工况,比如锅炉床温、床压,炉膛温度、压力,过热器的温度等。
赛题描述
经脱敏后的锅炉传感器采集的数据(采集频率是分钟级别),根据锅炉的工况,预测产生的蒸汽量。
二、数据探索
将训练集和测试集下载到本地,打开jupyter notebook,导入相关包。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline开始导入数据。
train_data_file = "data/zhengqi_train.txt"
test_data_file = "data/zhengqi_test.txt"
train_data = pd.read_csv(train_data_file, sep="\t", encoding="utf-8")
test_data = pd.read_csv(test_data_file, sep="\t", encoding="utf-8")
#查看前几行数据
train_data.head()train_data的数据如下图:

查看训练集的基本信息如下图:
train_data.info()
可以看出:
1、共2888条数据,序号为0-2887
2、共39列,除去结果列,有38个特征向量
3、所有列无缺失值,类型为数值型
再调用describe()方法查看训练集的信息:

数据可视化
为了更直观的看出数据之间的关系,这时候需要进行数据可视化操作。
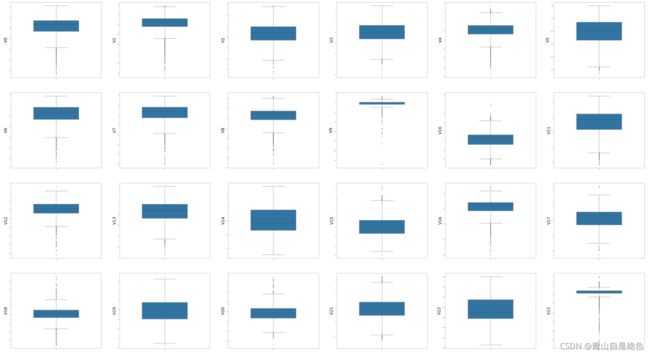
首先,绘制各项特征的箱型图:
column_list = train_data.columns.tolist()[:39] #列表表头列表
fig = plt.figure(figsize=(100, 100), dpi=75) #指定绘图对象的宽度和高度
for i in range(38):
plt.subplot(7, 6, i+1) #7行8列子图
sns.boxplot(data=train_data[column_list[i]], orient="v", width=0.5)
plt.ylabel(column_list[i], fontsize=36)
plt.show()运行效果如下图:
绘制各项特征的直方图和Q-Q图。Q-Q图是用来描述数据是否符合正态分布的,若点都落在直线上,说明数据符合标准正态分布。
#绘制所有变量的直方图和Q-Q图
train_cols = 6
train_rows = len(train_data.columns)
plt.figure(figsize=(4*train_cols, 4*train_rows))
i = 0
for col in train_data.columns:
i += 1
ax = plt.subplot(train_rows, train_cols, i)
sns.distplot(train_data[col], fit=stats.norm)
i += 1
ax = plt.subplot(train_rows, train_cols, i)
res = stats.probplot(train_data[col], plot=plt)
plt.tight_layout() #tight_layout会自动调整子图参数,使之填充整个图像区域
plt.show()效果如下图:

此处因篇幅限制,只放了部分图。
绘制各项特征的KDE图,KDE图用来反映训练集与测试集数据分布是否一致,如果训练集数据与测试集数据分布不一致,说明此项特征存在某些问题,在做模型训练时需要将其剔除。
train_cols = 6
train_rows = len(test_data.columns)
plt.figure(figsize=(4*train_cols, 4*train_rows))
for i in range(train_rows):
ax = plt.subplot(train_rows, train_cols, i+1)
ax = sns.kdeplot(train_data[column_list[i]], color="Red", shade=True)
ax = sns.kdeplot(test_data[column_list[i]], color="Blue", shade=True)
ax.set_xlabel(column_list[i])
ax.set_ylabel("Frequency")
ax = ax.legend(["train", "test"]) #图例
plt.show()效果如下图:

因篇幅限制,此处只放了部分图。从图中我们可以看出见图,特征变量v5、v9、v11、v17、v22、v28在训练集与测试集中的分布不一致,在训练模型时需删除此类特征。
接下来,我们计算各项特征的相关系数。
data_train1 = train_data.drop(["V5", "V9", "V11", "V17", "V22", "V28"], axis=1)
train_corr = data_train1.corr()
train_corr效果如下图:
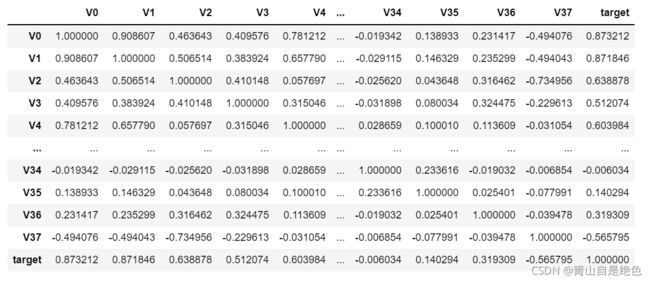
这么看好像很难看出点东西来,那咋办?当然是用数据可视化做成图标咯:
ax = plt.subplots(figsize=(20, 16)) #调整画布大小
ax = sns.heatmap(train_corr, vmax=0.8, square=True, annot=True) #画热力图效果如下图:
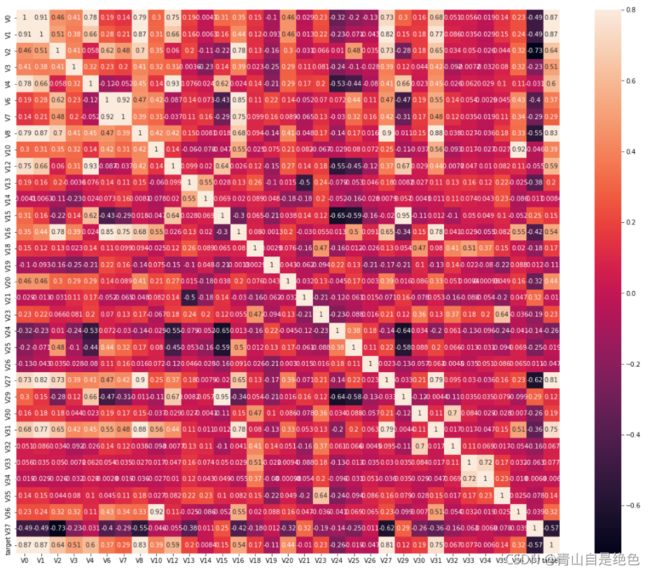
怎么样,加上这图是不是感觉逼格提高了很多,但是这图数据还是好多,没办法直观的看出想要的信息呀。别急,我们可以寻找10个与target变量最相关的特征变量,进一步减少数据量。
k = 10 #寻找k个与target变量最相关的特征变量
cols = train_corr.nlargest(k, "target")["target"].index #k个最相关的列的index
#cm = np.corrcoef(train_data[cols].values.T)
hm = plt.subplots(figsize=(10, 10)) #调整画布大小
hm = sns.heatmap(train_data[cols].corr(), vmax=0.8, square=True, annot=True) #画热力图
plt.show()效果如图:
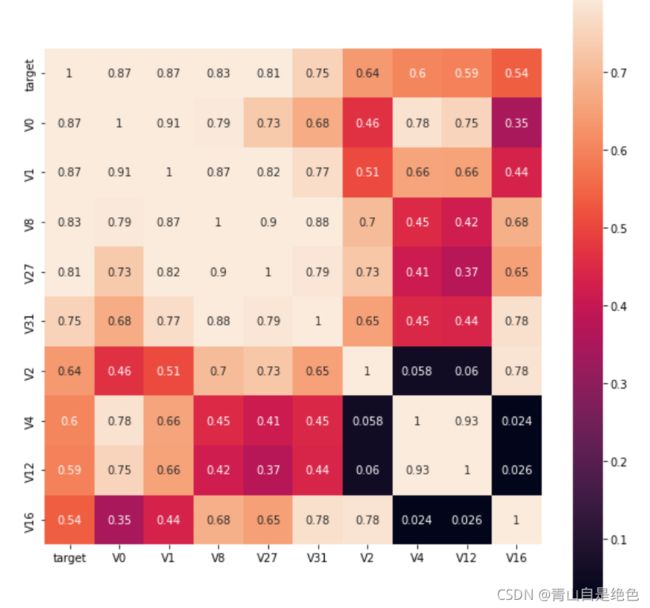
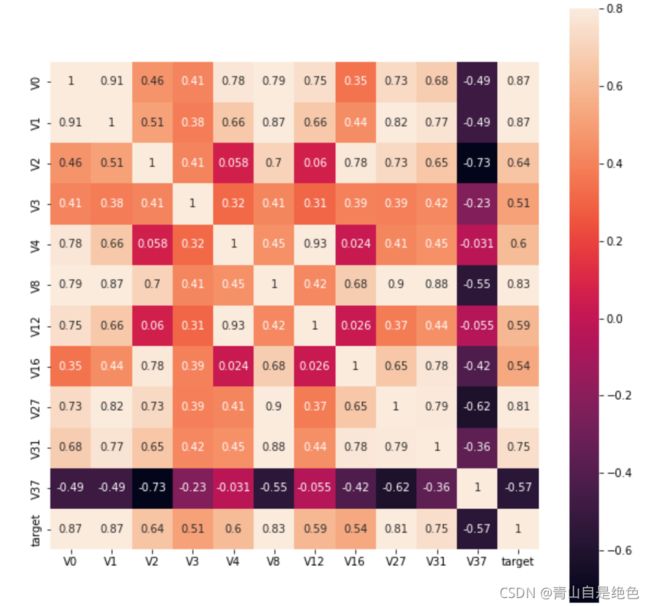
是不是顺眼多了。或者我们也可以找出相关系数大于0.5的特征:
rate = 0.5
top_corr_features = train_corr.index[abs(train_corr["target"]) > rate]
plt.figure(figsize=(10, 10))
hm = sns.heatmap(train_data[top_corr_features].corr(), vmax=0.8, square=True, annot=True) #画热力图效果如图:
三、模型建立
那么就先写写如何使用深度学习pytorch搭建神经网络来进行回归预测。
首先,导入相关包:
import pandas as pd
import torch
from torch import nn
from sklearn import preprocessing
import torch.optim as optim
import random
from sklearn.decomposition import PCA
读取数据:
#读取数据
#说明:数据无缺失值
train_data_file = "data/zhengqi_train.txt"
test_data_file = "data/zhengqi_test.txt"
#读取
train_data = pd.read_csv(train_data_file, sep="\t", encoding="utf-8")
test_data = pd.read_csv(test_data_file, sep="\t", encoding="utf-8")
在导入数据后,我们要对数据进行归一化处理,此时,如果先将训练集和测试集合并起来就更方便一点。做完归一化处理后再将数据拆分。
#将训练集和测试集合并
all_features = pd.concat((train_data.iloc[:,0:-1], test_data.iloc[:,0:]))#数据归一化
features_columns = all_features.dtypes[all_features.dtypes != "object"].index #列
#归一化函数
min_max_scaler = preprocessing.MinMaxScaler()
min_max_scaler = min_max_scaler.fit(all_features[features_columns])
#开始处理
all_features_scaler = min_max_scaler.transform(all_features[features_columns])
all_features_scaler = pd.DataFrame(all_features_scaler)
all_features_scaler.columns = features_columns
#拆分数据
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(train_data.target.values.reshape(-1, 1), dtype=torch.float32)简简单单做个特征工程,主要是用主成分分析法:
#PCA处理,进行特征降维
pca = PCA(n_components=16)
train_features_16 = pca.fit_transform(train_features)
test_features_16 = pca.transform(test_features)
train_features_16 = torch.tensor(train_features_16, dtype=torch.float32)
test_features_16 = torch.tensor(test_features_16, dtype=torch.float32)然后切分数据集,方便我们对模型进行评价。
#切分数据集
from sklearn.model_selection import train_test_split #切分数据
#切分数据集,训练集80%,测试集20%
train_data, test_data, train_target, test_target = train_test_split(train_features_16, train_labels, test_size=0.2, random_state=0)现在可以开始定义我们的神经网络了:
#定义神经网络
class MyNet(nn.Module):
def __init__(self, in_features, out_features=1):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(in_features, 12),
nn.GELU(),
nn.Linear(12, 10),
nn.GELU(),
nn.Linear(10, out_features),
)
def forward(self, x):
return self.fc(x)随手写一个神经网络,简简单单用上三个线性回归层,因为是回归问题,因此神经网络的输出是1就行了,此处激活函数用的是gelu,gelu效果要比relu好一点。
在跑神经网络的时候,如果有条件可以用GPU跑,速度比CPU快很多。
device = torch.device("cuda")
in_features = train_features_16.shape[1]
#print(in_features)
net = MyNet(in_features).to(device)
loss = nn.MSELoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
train_net = True
if train_net:
for epoch in range(230):
#net.train()
for X, y in data_iter(train_data, train_target, 210):
X = X.to(device)
y = y.to(device)
X_out = net(X)
l = loss(X_out, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
print("epoch: ",epoch, "train_loss: ",l.item())
#torch.save(net.state_dict(), 'model/model.pth')再用切分好的验证集试试网络:
#验证集损失
test_data = test_data.to(device)
test_target = test_target.to(device)
predict = net(test_data)
l = loss(predict, test_target)
print("the loss: ", l)接下来,把结果交上去就行啦:

哎,果然我还是个小菜鸡,哭···