Transformer详解:基于self-attention的大杀器
Transformer
话不多说,先上图,让大家对Transformer的结构有一个直观的认识,方便大家在看我后续的讲解中会更容易理解。
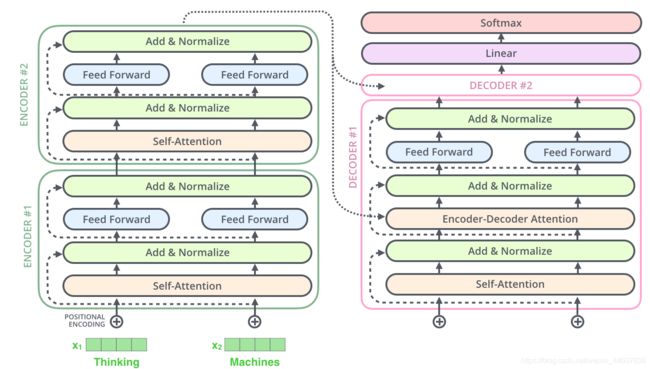
好,我们开始,先从encoder side开始。
Encoder Side
1.Self-Attention
我们已经知道在处理sequence数据时,我们最常用到的模型就是RNN,但是RNN有个非常大的问题,就是–Hard to parallel! 什么意思呢?也就是是说,我们使用RNN输出某个位置的ouput时,必须要make use of之前所有位置的输入,因此模型的这种结构化特征导致模型的输出也很难平行/并行化。
那么有什么方法来解决RNN的这个问题呢?换句话说,同样面对一个sequence输入的问题,有没有一个layer能够代替RNN,同时能够实现sequence输出的并行化呢?答案就是self-attention。
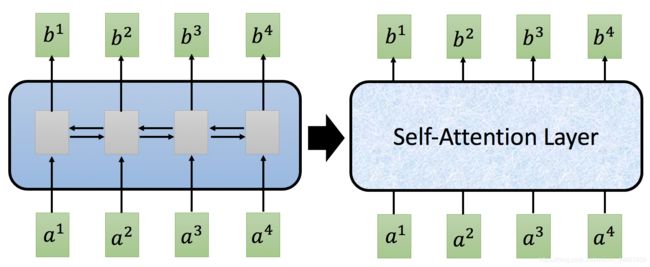
self-attention 不仅实现了b1,b2,b3,b4输出的并行化,同时也实现了每个输出的背后都完整的包含了整个序列的信息,类似于Bi-LSTM的效果。那么具体来说,self-attention是如何工作的呢?我们马上来一探究竟。
首先,我们对输入的每一个token(比如一句话为‘机器学习使我快乐’,token就是‘机’,‘器’,‘学’,‘习’,‘使’,‘我’,‘快’,‘乐’),取embedding,得到一系列特定维度的vectors。然后对于每一个word embedding,我们再构建出3个vector,分别为 query,key,value。那么如何从embedding vector 生成这3个不同的vector呢?我们需要3个参数矩阵,通过这3个矩阵的映射,从每个embedding分别构建出query,key,value,而这3个参数矩阵的值是通过模型的训练来学到的。下图清晰地展现了这一过程。其中的W_Q,W_K,W_V就是上面所说的参数矩阵。
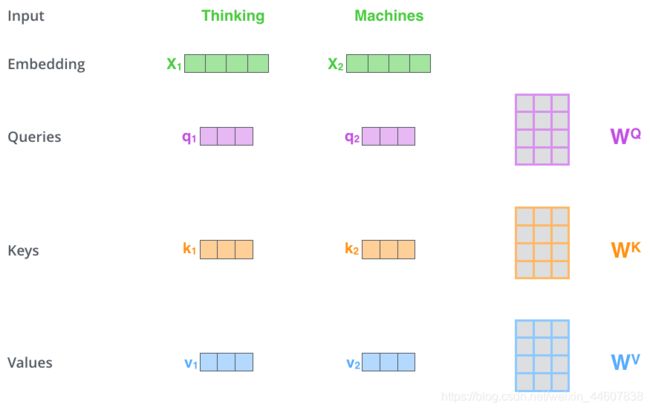
那么我们对于每个词构建出3个不同的vector的意义是什么呢?又为什么要这么取名字呢?相信大家看完我接下来的计算过程后,就会对3个vector的意义有一个清晰的认知。Let us start!
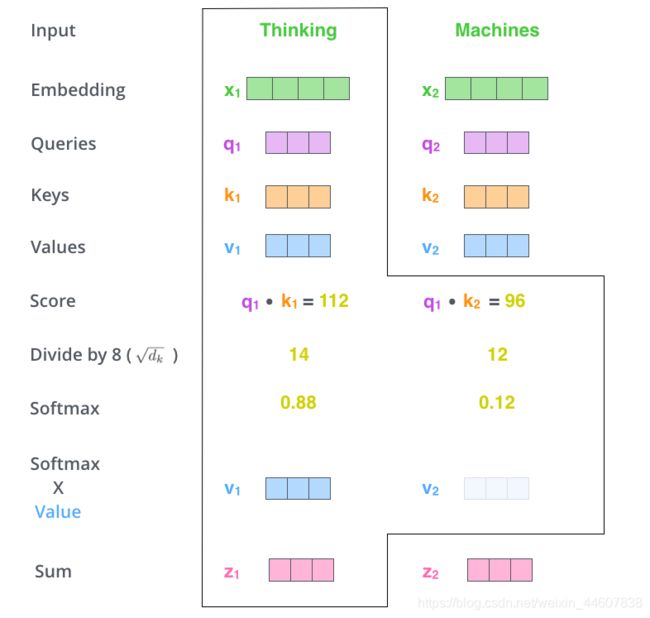
首先,对于input sequence中的每一个位置的word_t,我们要去计算整个句子中所有word 对于这个word_t的score,这个score可以近似地理解为相关性或相似性。当这个score越高时,代表这个位置上的word和我们的当前word_t的关联性越高,那么在对word_t的最终encode形成过程中,我们会赋予这个位置的word更多的attention。具体来说,给定某个word_t,我们拿它的 query vector( 主动找其他位置,包括自己)去和整个句子中的所有位置的word的key vector(被查询)做dot product。比如拿上图中的’Thinking’这个词作为例子,就是拿q1,去和k1,k2,…kn做dot product,其中n=len(sequence),也就是input 的长度。当然上述例子中只有两个词,那n=2。看起来我们已经完成了score的计算了,但是事实上,在原paper中,还有一个步骤就是对得到的score/sqrt(d_k), 其中d_k等于q和k的维度,比如64,那么score就要除以8,这个步骤的存在可以得到训练中更稳定的梯度,我自己的理解就是由于维度的增加带来的方差的增加,所以我们除以一个scale来平衡它。当然我们也可以选择其他的值。对于这个步骤感兴趣的读者可以阅读一下原paper。
总之现在我们有了一系列的scores了,接下来,我们需要对这些scores取softmax,也就是对于每一个词,我们得到一系列scores,同时sum(scores)=1,很显然的,在最终的一系列的scores中,这个词本身对应的score一般会是最大的,而input其他位置中的词,如果和我们当前位置的词相关性很大,那么它也会获得比较大的score,也可以理解为权重。下图清楚地描述了到softmax获取权重的过程。

在完成上述的softmax之后,我们发现目前我们已经使用了query 和 key,那么现在我们的value vector即将登场。在self-attention的最后一步中,我们拿我们的softmax的output,也就是input sequence每个位置对于当前位置词的一系列scores,去和每个位置词的value vector相乘,再求sum,来最终得到当前位置词的encode 结果,这个结果中包含了最重要的当前位置词本身的信息,同时也包含了整个input sequence中其他位置的词的信息。对于与当前位置词相关性很大的词,会给予较多的关注(更大的score),对于那些不相关的词,通过给予非常小的score。换句话说这个encoding的结果观察了整个input sequence,保留下重要信息,丢弃那些与当前位置词无关紧要的信息。OK,到此为止,最简单版本的self-attention layer介绍完毕。
下图展示了完整过程。
我们用matrix的形式再展示一遍,首先从embedding,通过 W_Q,W_K,W_V得到 Q,K,V。
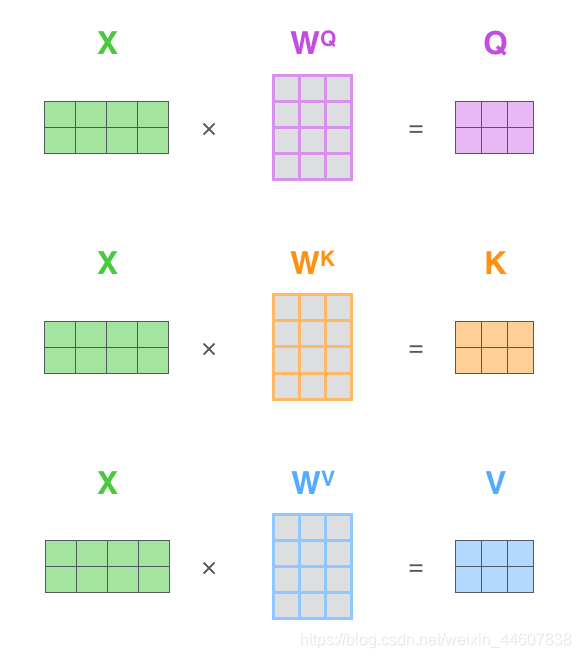
然后,经过如下的步骤得到最终的encoding 结果 Z。
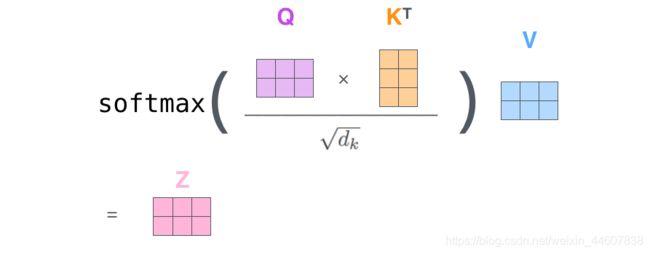
在原paper中,作者又拓展了上述简易版的self-attention。在上面的例子中我们只有一组Q,K,V。但是在实际使用中,不可能只使用一组,而是多组。这就是Multi-Headed Attention。说白了就是,我们通过设置num_head的数量,得到多组encoding的结果,Z0,Z1,…,最后把它们concate起来得到最终的结果。
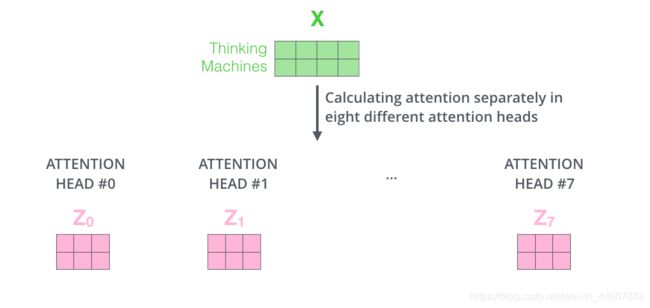
当然如果你想你的输出Z是指定维度的,你可以再concate完之后再通过一个矩阵运算得到你想要的维度,如下。
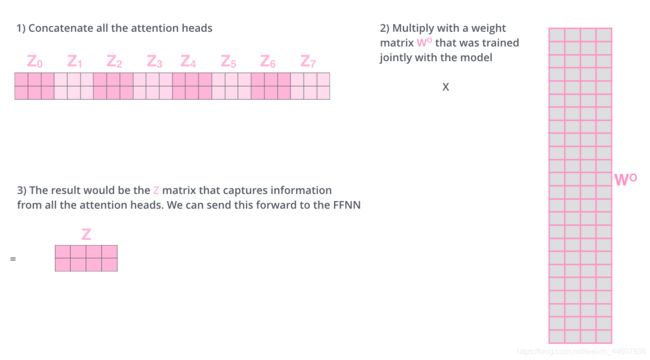
Multi-headed attention完整流程如下。
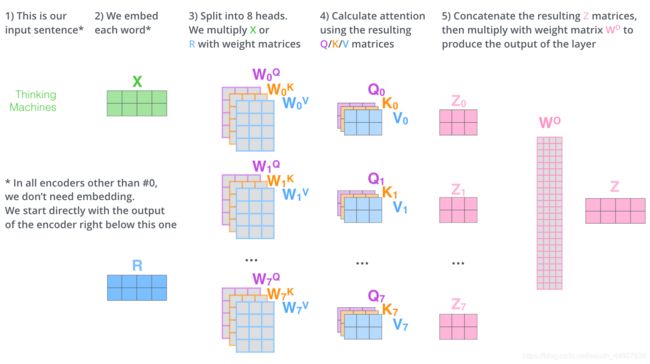
上面的self-attention过程看似十分完美,但是事实上,还存在一个非常大的问题,比如在上面的例子中,如果我将‘Thinking’和‘Machines’的位置互换,按照我们的直觉,得到的encoding output应该和之前是不一样的,但是,如果我们按照上述的流程,会发现计算结果完全没变。也就是说上述的self-attention并没有将location信息考虑进去。所以,我们在进行self-attention时,在输入每个词的embedding的同时,也会将location的信息额外进行添加,一个 positional encoding,将两者的合并后作为最终的input。之后我会将基于Keras和Tensorflow构建Multi-Headed Attention的代码贴出,但是在此之前,先让我们简单介绍一下Transformer结构中Self-Attention layer的后一层结构—Add-Normalize layer.
2.Add&Normalize
在Transformer的结构中,最重要的当然是我们的self-attention layer了。那么后面的这个add&Normalize究竟是在做什么呢?
先来解释一下Add操作。相信大家应该听说过残差网络,本质上来说,这个add操作就体现了残差网络中的思想。如下图
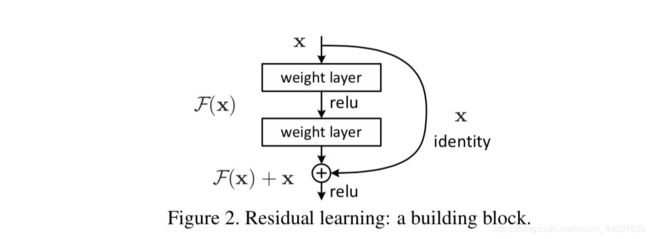
当我们的输入为x时,经过某个hidden layer的映射,我们得到F(x),但是我们在输出F(x)的同时,将输入x也同时添加后输出,但是需要保证F(x)的维度和x的维度是一致的。那么这个操作的意义是什么呢?最主要的就是避免网络退化,梯度衰减。当我们使用反向梯度传播算法进行梯度计算时,越是靠近input的layer的梯度越容易出现梯度衰减甚至消失的情况。但是通过在输出中添加x(输入)能有限地避免梯度消失。下面简单解释一下。假设我们不考虑激活函数的存在。
![]()
在深度网络中考虑任意两个layers l2>>l1,L1层的输出为a_l1,每一层的映射关系都为F(.),那么通过残差网络的思想,我们可以递归地得到

最终

那么我们在对a_l1层求梯度时,可以得到

因为l2是靠近输出的layer,那么梯度消失的情况就不会太糟,根据上述的表达式,我们会发现因为add的这个操作,即使反向传播到非常前面的层,因为1的存在,梯度消失的问题得到了有效的缓解。
OK,回到我们的Transformer,我们这里的add操作就是将self-attention这个layer的输出 F(x) + self-attention的输入 x.
当我们做完add之后,还有一步就是normalize。关于这个normalize,感兴趣的朋友可以去读一下layer norm的paper,这了不做具体说明了。大家应该知道另一种技术叫做Batch Norm,对于一个batch的数据,我们会将它的每一个特征维度下的数据转化为标准正态分布(mean=0,sd=1),而 layer norm的意思是我们会将不同的特征维度转为标准正态分布。
当我们经历完add&norm层的操作后,后面我们会接一个前馈神经网络,然后再经历一个add&norm。
那么以上就是encoder的一个完整的部分了,当然在实际使用中,我们往往会连接多个encoder,encoder1-encoder2-encoder3…
其实单单是encoder的结构已经能够解决非常多的机器学习问题了,比如各种分类问题,但是如果我们需要做序列预测类的问题,我们还需要我们的decoder。下面我们进入Transformer的Decoder 部分。
Decoder Side
在Decoder的每一个phase,会接收来自encoder的编码信息,同时接收序列的前一个输出作为当前输出的input。这里需要注意的一个点是,在每个phase的第一步self-attention时,实际上我们用的是masked multi-head attention,换句话说,我们只会用到当前已经生成的序列,后面未预测的部分masked,这个十分合理,因为我们不可能在生成序列的某个词时,还能够提前知道并利用后面的部分。其他的结构与encoder类似,这里不做重复说明了,大家可以仔细在看一下我在文章开头放的那张图。
在decoder的每一个phase都会输出一个预测值,这个output就是softmax 概率最大的位置对应的词,没什么特别的。
OKK,Transformer差不多就是这样了,下面是Encoder部分的简单代码实现。主要用的是Tensorflow中的Keras。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
#定义 Self Attention layer(multi-head)
class MultiHeadSelfAttention(layers.Layer):
def __init__(self,output_dim,num_heads):
super(MultiHeadSelfAttention,self).__init__()
self.output_dim=output_dim #output embedding dimension
self.num_heads=num_heads
if output_dim%num_heads!=0:
raise ValueError(f'output dimension={output_dim} should be divisible by number of heads={num_heads}')
self.projection_dim=output_dim//num_heads #output embedding dimension for each head
self.query_dense=layers.Dense(output_dim) #Query Matrix operation
self.key_dense=layers.Dense(output_dim) #Key Matrix operation
self.value_dense=layers.Dense(output_dim) #Value Matrix operation
self.comb_heads=layers.Dense(output_dim)
def attention(self,query,key,value):
#对于语句中的每一个词的 query_embedding q_i,计算 它与其余各词的key_embedding k_j for j=1,2,3..len(seq)
score=tf.matmul(query,key,transpose_b=True) #key 需要转置
#获取scale
dim_key=tf.cast(tf.shape(key)[-1],tf.float32)
scaled_score=score/tf.math.sqrt(dim_key)
#通过softmax获取weights
weights=tf.nn.softmax(scaled_score,axis=-1)
#对value加权平均得到output embedding
output=tf.matmul(weights,value)
return output,weights
def separate_heads(self,x,batch_size):
x=tf.reshape(x,(batch_size,-1,self.num_heads,self.projection_dim))
#将分离出来的num_heads这一维与之前的len_seq互换位置 1,2-->2,1
return tf.transpose(x,perm=[0,2,1,3])
def call(self,inputs):
batch_size=tf.shape(inputs)[0]
query=self.query_dense(inputs) #shape of query=(batch_size, seq_len,output_dim)
key=self.key_dense(inputs) #shape of key=(batch_size, seq_len,output_dim)
value=self.value_dense(inputs) #shape of value=(batch_size,seq_len,output_dim)
#separate heads
query=self.separate_heads(query,batch_size)
key=self.separate_heads(key,batch_size)
value=self.separate_heads(value,batch_size)
#shape of query,key,value=(batch_size,num_heads,seq_len,projection_dim)
attention,weights=self.attention(query,key,value) #(batch_size,num_heads,seq_len,projection_dim)
attention=tf.transpose(attention,perm=[0,2,1,3]) #(batch_size,seq_len,num_heads,projection_dim)
#concat the vectors for different heads
concat_attention=tf.reshape(attention,(batch_size,-1,self.output_dim))
output=self.comb_heads(concat_attention) #size=(batch_size,seq_len,output_dim)
return output
#定义Position encoding,弥补self-attention的位置信息损失
class Position_included_Embedding(layers.Layer):
def __init__(self,maxlen,vocab_size,ebed_dim):
super(Position_included_Embedding,self).__init__()
self.token_ebed=layers.Embedding(input_dim=vocab_size,output_dim=ebed_dim)
self.position_ebed=layers.Embedding(input_dim=maxlen,output_dim=ebed_dim)
def call(self,x):
maxlen=tf.shape(x)[-1]
positions=tf.range(start=0,limit=maxlen,delta=1)
positions=self.position_ebed(positions) #position embedding
x=self.token_ebed(x) #token embedding
return x+positions
#定义完整的Transformer block
class Transformer_Block(layers.Layer):
def __init__(self,ebed_dim,num_heads,ff_dim,rate=.2):
super(Transformer_Block,self).__init__()
self.attention=MultiHeadSelfAttention(ebed_dim,num_heads)
#为了apply add+norm 所以ffn的最终输出维度必须和 ffn的输入保持一致,也就是 ebed_dim
self.ffn=keras.Sequential([layers.Dense(ff_dim),
layers.Activation('relu'),
layers.Dense(ebed_dim),])
self.layernorm1=layers.LayerNormalization(epsilon=1e-6)
self.layernorm2=layers.LayerNormalization(epsilon=1e-6)
self.dropout1=layers.Dropout(rate)
self.dropout2=layers.Dropout(rate)
def call(self,inputs,training):
#1.self-attention layer
attention_output=self.attention(inputs)
#2.dropout layer
attention_output=self.dropout1(attention_output,training=training)
#3.apply add + norm
output1=self.layernorm1(inputs+attention_output)
#4.feed-forward nn layer
ffn_output=self.ffn(output1)
#5.dropout layer again
ffn_output=self.dropout2(ffn_output,training=training)
#6.apply add + norm again
return self.layernorm2(output1+ffn_output)
参考:https://jalammar.github.io/illustrated-transformer/