1. 什么是 StarRocks
- 新一代极速全场景MPP数据库,可以用 StarRocks 来支持多种数据分析场景的极速分析;
- 架构简洁,采用了全面向量化引擎,并配备全新设计的 CBO 优化器,查询速度(尤其是多表关联查询);
- 很好地支持实时数据分析,并能实现对实时更新数据的高效查询, 还支持现代化物化视图,以进一步加速查询;
- 用户可以灵活构建包括大宽表、星型模型、雪花模型在内的各类模型;
- 兼容 MySQL 协议,支持标准 SQL 语法,易于对接使用,全系统无外部依赖,高可用,易于运维管理。
2. 系统架构
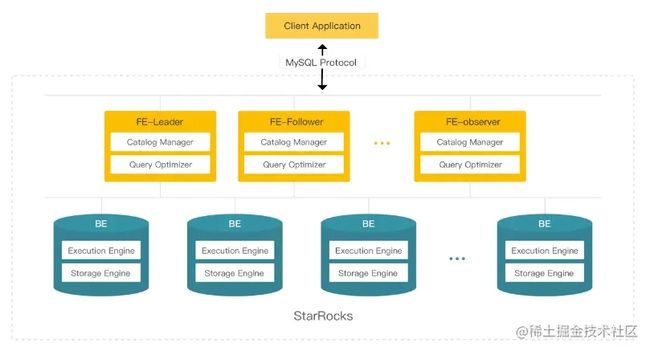
核心进程:FE(Frontend)、BE(Backend)。
注:所有节点都是有状态的。
FE(Frontend)负责管理元数据,管理客户端连接,进行查询规划、查询调度等工作。
- Leader:Follower会通过类Paxos的BDBJE协议选主出一个Leader,所有事务的提交都是由Leader发起,并完成;
- Follower:提高查询并发,同时参与投票,参与选主操作。
Follower
Observer:不参与选主操作,只会异步同步并且回放日志,主要用于扩展集群的查询并发能力。
BE(Backend)负责数据存储以及SQL执行等工作。
3. 存储架构
在StarRocks里,一张表的数据会被拆分成多个Tablet,而每个Tablet都会以多副本的形式存储在BE节点中,如下图:
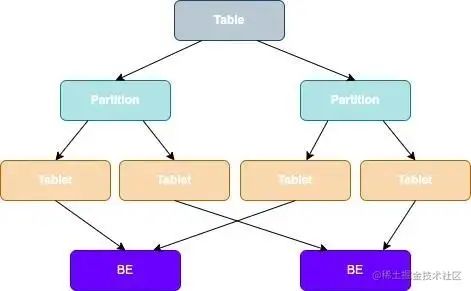
Table数据划分 + Tablet三副本的数据分布:

StarRocks支持Hash分布、Range-Hash的组合数据分布(推荐)。
为了等到更高的性能,强烈建议使用Range-Hash的组合数据分布,即先分区后分桶的方式。
- Range分区可动态添加和删减;
- Hash分桶一旦确定,不能再进行调整,只有未创建的分区才能设置新的分桶数。
分区和分桶的选择是非常关键的。在建表时选择好的分区分桶列,可以有效提高集群整体性能。
以下是针对特殊应用场景下,对分区和分桶选择的一些建议:
- 数据倾斜:业务方如果确定数据有很大程度的倾斜,那么建议采用多列组合的方式进行数据分桶,而不是只单独采用倾斜度大的列做分桶。
- 高并发:分区和分桶应该尽量覆盖查询语句所带的条件,这样可以有效减少扫描数据,提高并发。
- 高吞吐:尽量把数据打散,让集群以更高的并发扫描数据,完成相应计算。
3.1 表的存储
对表进行存储时,会对表进行分区和分桶两层处理,将表的数据分散到多台机器进行存储和管理。
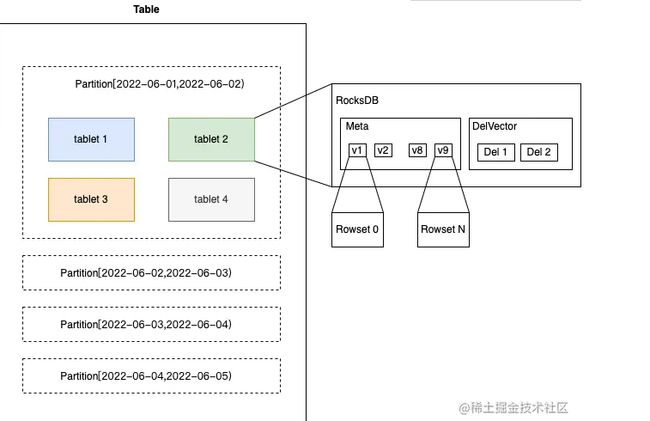
分区机制:高效过滤,提升查询性能。
- 分区类似分表,是对一个表按照分区键进行分割,可以按照时间分区,根据数据量按照天/月/年划分等等。可以利用分区裁剪对少数访问量,也可以根据数据的冷热程度把数据分到不同介质上。
分桶机制:充分发挥集群性能,避免热点问题。
- 使用分桶键Hash以后,把数据均匀的分布到所有的BE上,不要出现bucket数据倾斜的情况,分桶键的选择原则就是高基数的列或者多个列组合成为一个高基数的列,尽量将数据充分打散。
- 注:Bucket数量的需要适中,如果希望充分发挥性能可以设置为:BE数量 * CPU core/2,最好tablet控制在1GB左右,tablet太少并行度可能不够,太多可能远数据过多,底层scan并发太多性能下降。
Tablet:最小的数据逻辑单元,可以灵活设置并行计算资源。
- 一张表被切分成了多个Tablet,StarRocks在执行SQL语句时,可以对所有Tablet实现并发处理,从而充分的利用多机、多核提供的计算能力。
- 表在创建的时候可以指定副本数,多副本够保证数据存储的高可靠,以及服务的高可用。
Rowset:每一次的数据变更就会产生一个Rowset。
- 就是以组列存方式组织的的一些文件,每次的commit都会产生一个新的版本,每个版本包含哪些Rowset。
- 每次写入都会增加一个版本(无论是单条、还是stream load几个G的文件)。
Segment:如果一个Rowset数据量比较大,则拆分成多个Segment数据断落盘。
4. 需求背景
案例一:
- 业务背景
指标工厂服务主要面向业务人员,通过对业务指标的采集和处理,实时反映产品状态,为运营提供数据支撑、检测产品漏洞或服务异常、提供指标异常告警功能等。
- 业务场景分析
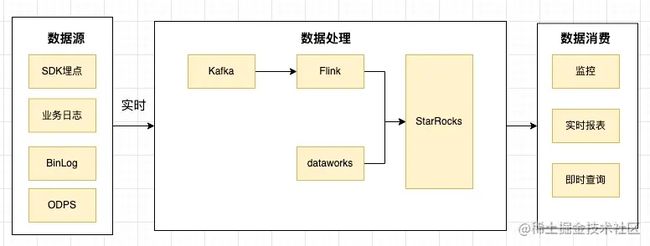
业务指标埋点方式多样,并不局限于某种方式,只要符合埋点标识明确、业务参数丰富、数据满足可解析的基本要求皆可作为数据源,大致可以分为:SDK、MySQL BinLog、业务日志、阿里云ODPS数据分析。
存在的挑战,各种业务场景众口难调,归纳数据特征如下:
- 需要全量日志明细;
- 需要数据可以始终是最新的,即满足实时更新场景;
- 需要对数据做层级聚合的,即可能是月、周、日、小时等;
- 需要可以承载更大的写入量;
- 每个业务数据都要灵活的配置数据的保存时间;
- 数据源来源多,报表定制化比较高,有多个数据源合并成一个大宽表的场景、也有多表连接的的需求;
- 各种监控图、报表展示、业务实时查询等,即较高的并非查询。
引入StarRocks
幸运的是StarRocks有比较丰富的数据模型,覆盖了上面的所有业务场景的需求,即:明细模型、更新模型、聚合模型、主键模型,同时选择更为灵活的星型模型代替大宽表的方式,即直接使用多表关联来查询。
- 明细模型:
- 埋点数据经过结构化处理后按明细全量存储;
- 该场景对DB在亿级数据量下查询性能有较高的要求;
- 数据可以通过配置动态分区来配置过期策略;
- 场景使用时从结构化数据选择个别字段维度在线聚合查询。
- 聚合模型:
- 埋点数据数据量巨大,且对明细数据不要求溯源,直接做聚合计算,比如计算PV、UV场景;
- 数据可以通过配置动态分区来配置过期策略。
- 更新模型:
- 埋点数据状态会发生变动,且需要实时更新数据,更新数据范围不会跨度多个分区的,比如:订单、优惠券状态等;
- 数据可以通过配置动态分区来配置过期策略。
基于以上业务场景的分析,这三种模型可以完美解决数据的问题。
需要实时的数据写入场景,我也沿用了业内流行的解决方案,即数据采集到 Kafka 之后,使用Flink做实时写入到StarRocks。StarRocks提供了非常好用的Flink-connector插件。
小tips:
1. 虽然StarRocks已经很好的优化了写入性能,当写入压力大,仍会出现写入拒绝,建议可适当增大单次导入数据量,降低频率,但同时也会导致数据落库延迟增加。所以需要做好一定的取舍,做到收益最大化。
2. Flink的sink端不建议配置过大,会引起并发事务过多的报错,建议每个flink任务source可以配置多些,sink的连接数不能过大。
小结
集群规模:5FE(8c32GB)、5BE(32c128GB)
目前该方案已支持数百个业务指标的接入,涉及几十个大盘的指标展示和告警,数据存储TB级,每日净增长上百G,总体运行稳定。
案例二:
- 业务背景
内部系统业务看板,主要服务于全公司员工,提供项目及任务跟踪等功能。
- 业务场景分析
分析业务特点:
- 数据变更频繁(更新),变更时间跨度长
- 查询时间跨度多
- 报表需准实时更新
- 关联维表查询多,部门/业务线/资源域等
- 冷热数据,最近数据查询频繁
- 历史架构与痛点
当初数据库选型时,结合业务特点,用户需要动态、灵活的增删记录自己的任务,因而选择了JOSN 模型减少了应用程序代码和存储层之间的阻抗,选择MongoDB作为数据存储。
伴随着公司快速快发,当需要报表展示,特别是时间跨度比较大,涉及到多部门、多维度、细粒度等报表展示时,查询时间在MongoDB需要执行10s甚至更久。
- 引入StarRocks
调研了StarRocks、ClickHouse两款都是非常优秀的分析型数据库,在选型时,分析了业务应用场景,主要集中在单表聚合查询、多表关联查询、实时更新读写查询。维度表更新频繁,即存储在MySQL中,StarRocks比较好的支持外表关联查询,很大程度上降低了开发难度,最终决定选用StarRocks作为存储引擎。
改造阶段,将原先MongoDB中的一个集合拆分成3张表。使用明细模型,记录每天的对应人员的任务信息,按天分区,由之前的每人每天一条记录改为,以事件为单位,每人每天可以多条记录。
实现频繁更新的维表,则选择使用外部表,减少维度数据同步到StarRocks的复杂度。
小结
改造前,MongoDB查询,写法复杂,多次查询。
db.time_note_new.aggregate(
[
{'$unwind': '$depart'},
{'$match': {
'depart': {'$in': ['部门id']},
'workday': {'$gte': 1609430400, '$lt': 1646064000},
'content.id': {'$in': ['事项id']},
'vacate_state': {'$in': [0, 1]}}
},
{'$group': {
'_id': '$depart',
'write_hour': {'$sum': '$write_hour'},
'code_count': {'$sum': '$code_count'},
'all_hour': {'$sum': '$all_hour'},
'count_day_user': {'$sum': {'$cond': [{'$eq': ['$vacate_state', 0]}, 1, 0]}},
'vacate_hour': {'$sum': {'$cond': [{'$eq': ['$vacate_state', 0]}, '$all_hour', 0]}},
'vacate_write_hour': {'$sum': {'$cond': [{'$eq': ['$vacate_state', 0]}, '$write_hour', 0]}}}
-- ... more field
},
{'$project': {
'_id': 1,
'write_hour': {'$cond': [{'$eq': ['$count_day_user', 0]}, 0, {'$divide': ['$vacate_write_hour', '$count_day_user']}]},
'count_day_user': 1,
'vacate_hour': 1,
'vacate_write_hour': 1,
'code_count': {'$cond': [{'$eq': ['$count_day_user', 0]}, 0, {'$divide': ['$code_count', '$count_day_user']}]},
'all_hour': {'$cond': [{'$eq': ['$count_day_user', 0]}, 0, {'$divide': ['$vacate_hour', '$count_day_user']}]}}
-- ... more field
}
]
)
改造后,直接兼容SQL,单次聚合。
WITH cont_time as (
SELECT b.depart_id, a.user_id, a.workday, a.content_id, a.vacate_state
min(a.content_second)/3600 AS content_hour,
min(a.write_second)/3600 AS write_hour,
min(a.all_second)/3600 AS all_hour
FROM time_note_report AS a
JOIN user_department AS b ON a.user_id = b.user_id
-- 更多维表关联
WHERE b.depart_id IN (?) AND a.content_id IN (?)
AND a.workday >= '2021-01-01' AND a.workday < '2022-03-31'
AND a.vacate_state IN (0, 1)
GROUP BY b.depart_id, a.user_id, a.workday, a.content_id,a.vacate_state
)
SELECT M.*, N.*
FROM (
SELECT t.depart_id,
SUM(IF(t.content_id = 14, t.content_hour, 0)) AS content_hour_14,
SUM(IF(t.content_id = 46, t.content_hour, 0)) AS content_hour_46,
-- ...more
FROM cont_time t
GROUP BY t.depart_id
) M
JOIN (
SELECT depart_id AS join_depart_id,
SUM(write_hour) AS write_hour,
SUM(all_hour) AS all_hour
-- 更多指标
FROM cont_time
GROUP BY depart_id
) N ON M.depart_id = N.join_depart_id
ORDER BY depart_id ASC
以查询报表2021/01/01~2022/03/01之间数据对比:
- StarRocks: 1次查询聚合,可完全通过复杂SQL聚合函数计算,耗时 295ms
- Mongodb: 需分2次查询+计算,共耗时3s+9s=12s
5. 经验分享
在使用StarRocks时遇到的一些报错和解决方案(网上资料较少的报错信息):
a.数据导入Stream Load报错:“current running txns on db 13003 is 100, larger than limit 100”
原因:超过了每个数据库中正在运行的导入作业的最大个数,默认值为100。可以通过调整max_running_txn_num_per_db参数来增加每次导入作业的个数,最好是通过调整作业提交批次。即攒批,减少并发。
b. FE报错:“java.io.FileNotFoundException: /proc/net/snmp (Too many open files)”
原因:文件句柄不足,这里需要注意,如果是supervisor管理进程,则需要将文件句柄的配置加到fe的启动脚本中。
if [[ $(ulimit -n) -lt 60000 ]]; then ulimit -n 65535 fi
c. StarRocks 支持使用 Java 语言编写用户定义函数 UDF,在执行函数报错:“rpc failed, host: x.x.x.x”,be.out日志中报错:
start time: Tue Aug 9 19:05:14 CST 2022
Error occurred during initialization of VM
java/lang/NoClassDefFoundError: java/lang/Object
原因:在使用supervisor管理进程,需要注意增加JAVA_HOME环境变量,即使是BE节点也是需要调用Java的一些函数,也可以直接将BE启动脚本增加JAVA_HOME环境变量配置。\
d. 执行Delete操作报错如下:
SQL > delete from tableName partition (p20220809,p20220810) where `c_time` > '2022-08-09 15:20:00' and `c_time` < '2022-08-10 15:20:00';
ERROR 1064 (HY000): Where clause only supports compound predicate, binary predicate, is_null predicate and in predicate
原因:目前delete后的where条件不支持between and操作,目前只支持 =、>、>=、<、<=、!=、IN、NOT IN
e. 使用Routine Load消费kakfa数据的时候产生了大量随机group_id
建议:建routine load的时候指定一下group name。
f. StarRocks连接超时,查询语句报错:“ERROR 1064(HY000):there is no scanNode Backend”,当重新启动BE节点后,短暂的恢复。日志报错如下:
kafka log-4-FAIL, event: [thrd:x.x.x.x:9092/bootstrap]: x.x.x.x:9092/1: ApiVersionRequest failed: Local: Timed out: probably due to broker version < 0.10 (see api.version.request configuration) (after 10009ms in state APIVERSION_QUERY)
原因:当Routine Load连接kafka有问题时,会导致BrpcWorker线程耗尽,影响正常访问连接StarRocks。临时解决方案是找到问题任务,暂停任务,即可恢复。
6. 未来规划
接下来我们会有更多业务接入 StarRocks,替换原有 OLAP 查询引擎;运用更多的业务场景,积累经验,提高集群稳定性。未来希望 StarRocks 优化提升主键模型内存占用,支持更灵活的部分列更新方式,持续优化提升 Bitmap 查询性能,同时优化多租户资源隔离。今后我们也会继续积极参与 StarRocks 的社区讨论,反馈业务场景。
以上就是得物基于StarRocks的OLAP需求实践详解的详细内容,更多关于得物StarRocks OLAP需求的资料请关注脚本之家其它相关文章!