数据挖掘思维和实战21 实践 4:用关联分析找到景点与玩法的关系
在前面的实践课程中,有的是注重对数据挖掘流程的讲解,有的是注重对算法实施的讲解。在这节课里,我们注重从实际的场景出发,使用数据挖掘流程来处理我们的景点与玩法的关系。接下来就让我们一起走进场景中,看看如何解决业务中的实际问题吧。
理解业务
在马蜂窝平台,有数以千万计的用户写下了他们旅行的感受,记录了他们旅行的瞬间;更有数以亿计的用户在浏览这些旅行相关的内容,以启发自己的旅行计划,制定可靠的旅行攻略。
但是在这些内容里,也存在着很多信息不准确、信息过时,或者有价值的信息过少等问题。用户想要从这些内容里找到自己所需要的信息,往往需要翻阅大量的内容,自己去判断哪些信息是准确的、有价值的,哪些信息是过时的、无意义的,这给有强烈的旅行需求的用户带来了一丝不便。
在旅行场景下,目的地和 POI(Point of Information)是非常重要的特征。因为旅行是一定要依托于一个具体的地理位置,去到一座城、进入一家店、感受一片风光。而这些地理位置所具备的特征往往是不容易随着时间的变化而变化的,也不会因为某个人的特定感受而发生改变。
那么有没有一种可能,我们在浩如云海的数据中去挖掘那些景点的特色,并把这些信息沉淀下来,形成更加简洁和有价值的信息,以帮助用户提升效率呢?
这就是我们的业务需求,即如何用我们现有的数据去挖掘景点与玩法的关系,从而把景点与玩法关联起来。
理解数据
了解了我们的业务需求点,接下来就是要看我们都有一些什么样的数据。
POI 信息
首先最重要的当然是 POI 信息,一份标准的 POI 名称是一个良好的开始。围绕着 POI 名称,还有很多 POI 的其他信息,比如经纬度、POI 的热度、POI 所属目的地的上下级关系等,这些信息可以帮助我们对 POI 进行筛选。
如下图所示,目的地“丽江”下属又有很多的 POI,比如丽江古城、束河古镇,这些都是已经结构化好的数据。
内容文本标签与 POI
像之前提到的,在我们积累的数据中,最核心的是用户写的各种游记、攻略等文本信息。这些内容都是用户出行的真实体验,但正由于是个人的体验,所以即便是对于同一个景点,不同的人体验也会不同。
比如你在景点恰好碰到一个小偷,或者脾气暴躁的工作人员,那你肯定体验不好;又或者是你去沙漠恰好遇到了下雨,去森林恰好遇到了寒流 / 叶子全都落了等情况,每一个旅行的人都会有自己的感受。
但是,我们希望的是通过大量的数据进行分析,这样既可以获得大多数人的体验效果,又能够兼顾到小部分人的特殊感受,从用户的角度出发去评价一个景点,而不是一个景点本身的属性。
在内容方面,我们早前就已经建立了一套完整的标签体系,这套标签体系中包含了大大小小六百多个标签,并按照层级结构划分成三层,标签粒度从粗到细。
第一层标签诸如旅行景色、旅行时间、旅行玩法、美食等;第二层包含城市景观、人文景观、冰雪运动、户外运动等;第三层级包含滑雪、爬山、自驾等最具体的标签,这里面已经收纳了比较完善的玩法标签。
当用户上传了自己写的内容之后,我们的算法处理流程会使用自然语言处理算法和图像处理算法来分析每一篇内容,并为其标注标签。
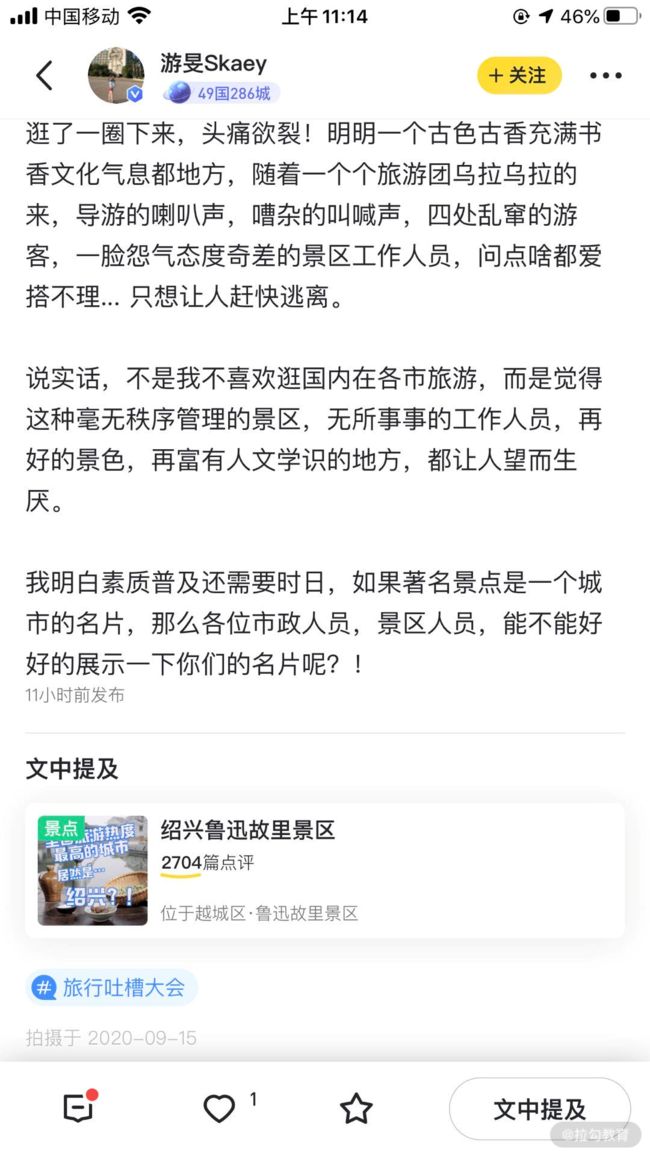
在我们的用户所写内容中,通常有这样两种情况:
第一种,如上面这个用户写的,其中只涉及一个景点“绍兴鲁迅故里景区”,在我们的后台可以看到,通过我们的算法挖掘之后,这条内容已经关联上“新攻略、名人故居、人文景观、观光景点、9月”这样几个标签。其中的“名人故居、人文景观、观光景点”都属于玩法类标签。由于这条内容介绍的景点很集中,所以这条内容上的标签迁移到 POI 上面也相对较准确。
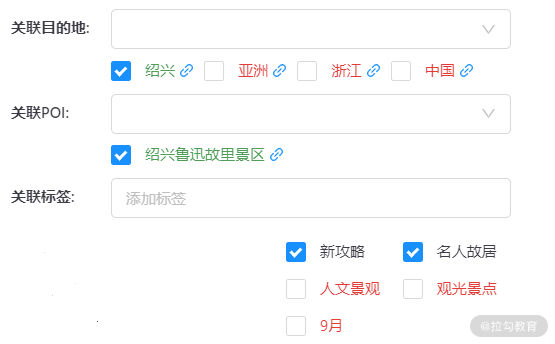
第二种情况,我们再来看一条数据。下图显示的这条内容讲解的是镇江一日游,其中涉及了很多的景点,还有出行路线等很多内容。
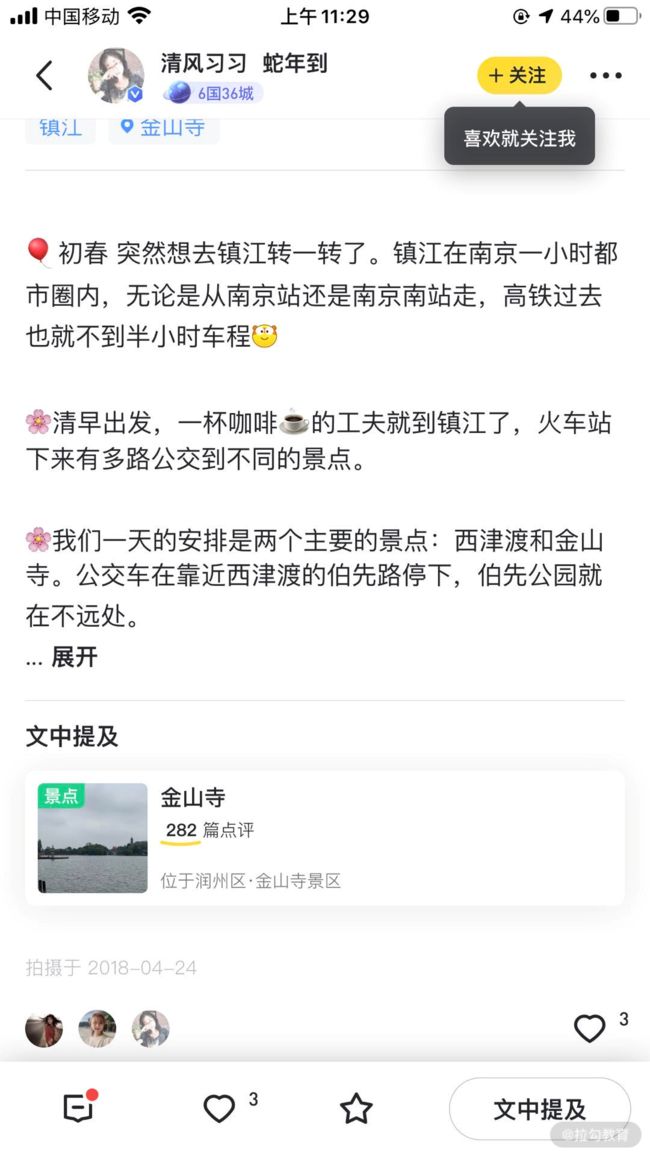
因此,在我们的后台可以看到,经过算法的挖掘之后,这条内容能够标注的标签也比较多:一日游、寺庙、日程、行程规划、观光景点、人文景观、公园、6月、春季、城市景观、博物馆等,都被标在了这条内容上面。
这里面的标签如果都跟金山寺做关联,那准确度肯定相对比较低,但是好在我们有众多的数据,可以进行交叉校验和筛选,最终那些出现较少的标签将会被筛掉。
了解了我们的业务和数据,我大致想到两个比较简单的构建景点与玩法关系的方案。
方案一:使用词向量模型构建词关系。
首先,不管是景点还是玩法,都是一个词汇,而这些词汇会经常出现在用户写的内容中,同时我们有大量的内容可供我们去构建预训练语言模型。
当然,现在网上有很多已经训练好的开源模型供大家使用, 但是网上的预训练模型往往使用的是比较常见的新闻语料,对于我们这种垂直领域的内容适配效果不太好。
在模型的选取上,我们还是使用了前面课时所用到的 Word2Vec 词向量模型,而没有选取比如 BERT,主要是受到机器条件的限制,如果要自行训练一个 BERT 模型,需要耗费大量的时间,而在效果上的差距不足以弥补时间上的损失。
关于 Word2Vec 的训练方式在实践 2(如何使用 word2vec 和 k-means 聚类寻找相似的城市)中已经讲解过,而这个算法我们也会在后面的课时里进行更详细的介绍。如果训练好了 Word2Vec 词向量模型,我们就可以使用在里面出现过的景点词汇与玩法词汇向量来计算关系的远近。
方案二:基于统计的关联关系挖掘。
除了上面的方案,第二个想到的方案就是根据我们算法,在每篇文章已经标注的玩法标签与景点信息中,计算景点与玩法共同出现的次数,然后通过关系挖掘中的支持度、置信度、提升度、确信度等指标进行筛选,以提升准确率。
当然,除了这两种方法,还有很多其他的方案,也可以把这种关联关系挖掘转换成分类任务等,这里暂且不涉及那些部分。
准备数据与模型训练
清楚了我们的业务需求和数据情况,并且已经有了一个大致的方案,那么接下来就是准备数据环节了。
首先我们需要准备好景点与玩法的词汇表,方便后面的筛选。玩法词相对比较简单,而景点词需要多费点心思,因为在景点 POI 中有很多重名的,或者别名,这需要在处理的时候特别注意。
针对方案一,我们需要准备的是所有分好词的内容,当然我们的分词系统需要加入景点与玩法词汇,以保证这些词可以优先被分出来。有了这些语料,就可以训练 Word2Vec 模型,然后根据景点 POI 和玩法词汇表,把 Word2Vec 中对应的词向量取出来,计算景点 POI 与每一个玩法词的距离,最终获得一个与 POI 词汇数一样的长度、与玩法词数一样维度的数据表,每一个维度存储 POI 与当前玩法词的向量距离。
这个方案的筛选,对于每一个 POI,首先保留前 30 个距离最近的标签,然后依赖于人工观察,以确认我们所需要保留的最小距离,然后把小于我们所设定阈值的标签去掉。
针对方案二,由于所有 POI 和标签特征都已经做好结构化,我们只需要去遍历数据库中的所有数据,并把对应的 POI 和标签逐个进行加法运算,最终获得每个 POI 对应共同出现过的标签及其次数。
在筛选的过程中,我们会参考每个标签和 POI 出现的绝对次数,配合支持度、置信度等几个指标设定阈值,最终保留我们认为足够置信的结果。下图就是我们对“洪崖洞”这个 POI 统计后的结果。

评估与应用
说起来两个关联挖掘的方案都不算太难,不过结果却是非常有价值的。当然,只产出了上面的内容只能算是一个良好的开端,这些东西最终要落地应用,还需要经过很多步骤。
首先,我们与运营一起对两个方案进行了效果的评估,这个评估主要依赖于人工校验的方式,借助人工的先验知识,来抽样检查结果的准确性。其中,方案二所挖掘到的效果相对较好,所以我们把它的结果作为基准数据,同时把方案一的结果作为辅助校验与方案二的结果融合在一起。
完成了评估,我们也就可以用这些数据去做一些有意思的事情,比如使用这些数据构建一个知识图谱。既然是针对大量的景点 POI 与玩法挖掘的关联关系,一个景点可以与多个玩法发生关系,一个玩法也可以与多个景点发生关系,一个目的地下可以有多个景点,这就构成了一张庞大的网状结构。所以可以想到的就是把这些数据沉淀在图数据库中,去建设一个知识图谱,以方便我们进行查阅。
下面这张图展示的就是我们构建的目的地知识图谱的展示页面,当然知识图谱中还包括了大量的其他技术手段,本小节所用到的关联关系只是其中的很小一部分,或者算是初步的骨架,如果后面有机会我们再去深入讲解相关的课程。
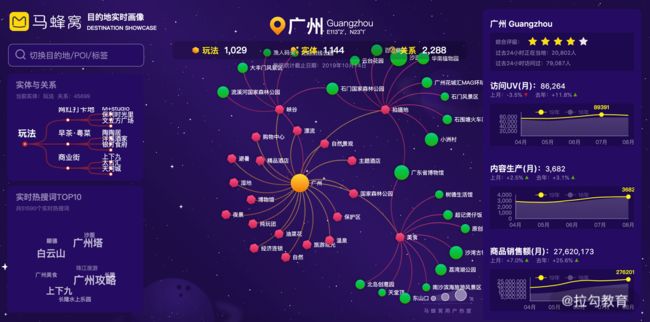
当然,景点与玩法的关系应用不只是图谱这一种形式,我们通过挖掘的手段获取了大量景点的玩法信息,这些信息来自无数的作者贡献的内容。其中所蕴含的丰富知识是有限的运营人员所无法覆盖的,所以这在我们的景点 POI 榜单生产、内容生产供需分析,甚至是推荐搜索系统中,都在持续发挥着作用。
总结
这一小节讲到这里就告一段落了,这节课里面没有涉及任何代码,而是主要从整个业务流程上讲解了具体去做一个关联分析项目的过程。
我们从提出去寻找景点与玩法的业务需求开始,深入理解了我们的业务与数据情况,接下来是制定我们的方案并实施。关联分析的方案几乎是基于统计来进行计算,所用到的方法通常都非常简单,只要我们解决了工程性的问题就不会有太大的难度。但是它所蕴藏的价值是巨大的,在最后,我简单介绍了我们所获得的结果与应用,并展示了我们目前的知识图谱页面。
通过这一小节的学习,不知道你是否又获得了一些启发呢?在你的日常工作中,是否也存在着可以进行关联关系挖掘的场景呢?
点击下方链接查看源代码(不定时更新)以及相关工具:
https://github.com/icegomic/GomicDatamining/tree/master/LagouCodes