spss分析方法-判别分析
判别分析是在分组已知的情况下,根据已经确定分类的对象的某些观测指标和所属类别来判断未知对象所属类别的一种统计学方法。
下面我们主要从下面四个方面来解说:
- 实际应用
- 理论思想
- 建立模型
- 分析结果
一、实际应用
判别分析最初应用于考古学, 例如要根据挖掘出来的人头盖骨的各种指标来判别其性别年龄等.。慢慢的成为一种常用的分类分析方法,其通过已知的分类情况,根据数据的特征对其他研究对象进行预测归类。
在实际生活中,判别分析也被广泛用于预测事物的类别归属。
企业营销中,营销人员可通过已有的客户特征数据(如消费金额、消费频次、购物时长、购买产品种类等),预测当前的消费者属于哪种类型的顾客(款式偏好型、偏重质量型、价格敏感型...),并根据其特点有针对性的采取有效的营销手段。或是根据各成分含量指标,判断白酒的品牌或水果的产地等。
除此以外,判别分析还可与聚类分析结合使用。比如,银行的贷款部门想要在发放贷款之前,可通过此方法判断申请人是否具有良好的信用风险。
二、理论思想
判别分析首先需要对研究的对象进行分类,然后选择若干对观测对象能够较全面描述的变量,接着按照一定的判别标准建立一个或多个判别函数,使用研究对象的大量资料确定判别函数中的待定系数来计算判别指标。对一个未确定类别的个案只要将其代入判别函数就可以判断它属于哪一类总体。
常用的判别分析方法有距离判别法、费舍尔判别法和贝叶斯判别法。
费舍尔判别法:
费舍尔判别法利用投影的方法使多维问题简化为一维问题来处理。其通过建立线性判别函数计算出各个观测量在各典型变量维度上的坐标并得出样本距离各个类中心的距离,以此作为分类依据。
贝叶斯判别法:
贝叶斯判别法通过计算待判定样品属于每个总体的条件概率并将样本归为条件概率最大的组。其主要思想如下:首先利用样本所属分类的先验概率通过贝叶斯法则求出样本所属分类后验概率,并依据该后验概率分布作出统计推断。
距离判别法:
距离判别思想是根据各样品与各母体之间的距离远近作出判别的。其通过建立关于各母体的距离判别函数式,得出各样品与各母体之间的距离值,判别样品属于距离值最小的那个母体。
三、建立模型
一般判别分析法的思路:
- 首先建立判别函数;
- 然后通过已知所属分类的观测量确定判别函数中的待定系数;
- 最后通过该判别函数对未知分类的观测量进行归类。
逐步判别分析法的思路:逐步判别分析分为两步
- 首先根据自变量和因变量的相关性对自变量进行筛选,
- 然后使用选定的变量进行判别分析。
逐步判别分析是在判别分析的基础上采用有进有出的办法,把判别能力强的变量引入判别式的同时,将判别能力最差的变量别除。最终在判别式中只保留数量不多而判别能力强的变量。
数据条件:
- 用户使用的分组变量必须含有有限数目的不同类别,且编码为整数。名义自变量必须被重新编码为哑元变量或对比变量。
- 个案独立的
- 预测变量应有多变量正态分布,组内方差-协方差矩阵在组中应等同。
- 组成员身份假设为互斥的(不存在属于多个组的个案),且全体为穷举的(所有个案均是组成员)。如果组成员身份为真正的分类变量时,则此过程最有效;如果组成员身份基于连续变量的值(如高智商与低智商),则用户需要考虑使用线性回归以利用由连续变量本身提供的更为丰富的信息。
一般判别分析案例:
题目:以下3种不同种类豇豆豆荚的质量、宽度和长度的统计表,每种类型都为20个样本,共60个样本。根据不同种类豇豆豆荚的特征,建立鉴别不同种类豇豆的判别方程。
一、数据输入

二、操作步骤1、进入SPSS,打开相关数据文件,选择“分析”|“分类 ”|“判别式”命令2、选择进行判别分析的变量。在“判别分析”对话框的左侧列表框中,选择“类型”进入“分组变量”列表框。单击“定义范围”按钮,在“最小值”和“最大值”中分别输入1和3,单击“继续”按钮返回“判别分析”对话框。分别选择“质量”“宽度”“长度”3个变量进入“自变量”列表框,选中“使用步进法”单选按钮。

3、设置判别分析的统计输出结果。
单击“判别分析”对话框中的“统计”按钮。在“函数系数”选项组中,选中“费希尔”和“未标准化”复选框;在“矩阵”选项组中,选中“组内协方差”复选框。设置完毕后,单击“继续”按钮返回“判别分析”对话框。

4、设置输出到数据编辑窗口的结果。单击“保存”按钮,选中“预测组成员”复选框。

5、其余设置采用系统默认值即可。单击“确定”按钮,等待输出结果。
四、结果分析
1、组统计量表可以看出,每一种豇豆豆荚的质量、宽度和长度的均值和标准差,也可以知道总样本的均值和标准差。

2、汇聚的组内矩阵表可以知道,各因素之间的协方差和相关系数。可以发现,各因素之间的相关性都较小,因此在判别方程中不需要剔除变量。

3、输入和删除变量情况统计表可以知道,第一步纳入的变量是质量,到第三步所有变量全部纳入,且从显著性值均为0可以看出,逐步判别没有剔除变量。

4、典型判别方程的特征值可以知道,特征根数为2,其中第一个特征根为77.318,能够解释所有变异的89.4%。

5、判别方程的有效性检验可以看出,显著性均为0,因此两个典型方程的判别能力都是显著的。

6、标准化的典型判别方程可以知道,本例中的两个标准化的典型判别方程表达式分别为:Y1=0.681*质量-0.674*宽度+0.612*长度Y2=0.363*质量+0.777*宽度+0.302*长度

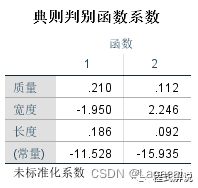
7、未标准化的典型判别方程可以知道,本例中的两个未标准化的典型判别方程表达式为:Y1=-11.528+0.210*质量-1.950*宽度+0.186*长度Y2=-15.935+0.112*质量+2.246*宽度+0.092*长度
8、贝叶斯的费希尔线性判别方程可以得到3个分类方程。在这里我们只写出第一个分类方程。Y1=-90.708+2.557*质量+18.166*宽度+1.922*长度 9、判别分析在数据编辑窗口的输出结果新产生的变量记录是每一样品的判别分类结果,可以看出,样品判别分类结果与实际类别是一致的。
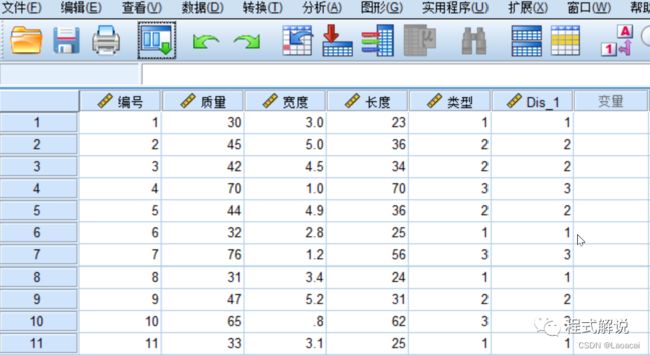
9、判别分析在数据编辑窗口的输出结果新产生的变量记录是每一样品的判别分类结果,可以看出,样品判别分类结果与实际类别是一致的。
分析结论:
通过判别分析可以知道,在本案例中,3种豇豆豆荚的样品判别分类结果与实际类别是一致的。另外,我们可以得到不同的判别方程,分别包括标准化的典型判别方程、未标准化的典型判别方程和贝叶斯的费希尔线性判别方程,方程的表达式见上面的结果分析。
参考案例数据:
【1】spss统计分析与行业应用案例详解(第四版) 杨维忠,张甜,王国平 清华大学出版社
(获取更多知识,前往gz号程式解说)
原文来自https://mp.weixin.qq.com/s/Yapg-5jwMK6cITG_FZsfVA
