深度学习 Day13——利用卷神经网络实现猴痘病的识别
深度学习 Day13——利用卷神经网络实现猴痘病的识别
文章目录
- 深度学习 Day13——利用卷神经网络实现猴痘病的识别
-
- 一、前言
- 二、我的环境
- 三、前期工作
-
- 1、导入依赖项并设置GPU
- 2、导入数据集
- 3、查看数据集
- 四、数据预处理
-
- 1、加载数据
- 2、检查数据并可视化数据
- 3、配置数据集
- 五、构建CNN网络
- 六、编译模型
- 七、训练模型
- 八、模型评估
-
- 1、绘制Loss(损失)图和Accuracy(准确性)图
- 2、在本地指定图片进行预测
- 九、尝试增加卷积层
- 十、尝试调整模型参数
- 十一、最后我想说
一、前言
- 本文为365天深度学习训练营 中的学习记录博客
- 参考文章地址: 深度学习100例-卷积神经网络(CNN)猴痘病识别 | 第45天
- 作者:K同学啊
前段时间,重庆市出现了中国内地首例输入性猴痘病例,那么什么是猴痘病呢?
猴痘是一种人畜共患病,即由动物传染给人类的疾病。病例通常发生在热带雨林附近,那里有携带病毒的动物。猴痘病毒感染的证据已经在松鼠、冈比亚鼠、睡鼠、不同种类的猴子和其他动物身上发现。
正好切合实际,本期我们将利用CNN实现猴痘病的识别,学习一下在医学领域用深度学习进行病状识别操作,来见识一下深度学习的强大所在。
注意:本期博客内出现的猴痘病症状照片可能会引起部分人的不适,请留意!!!
二、我的环境
- 电脑系统:Windows 11
- 语言环境:Python 3.8.5
- 编译器:DataSpell 2022.2
- 深度学习环境:TensorFlow 2.3.4
- 显卡及显存:RTX 3070 8G
三、前期工作
1、导入依赖项并设置GPU
导入依赖项:
from tensorflow import keras
from tensorflow.keras import layers,models
import os, PIL, pathlib
import matplotlib.pyplot as plt
import tensorflow as tf
和之前一样,如果你GPU很好就只使用GPU进行训练,如果GPU不行就推荐使用CPU训练加GPU加速。
只使用GPU:
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
使用CPU+GPU:
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
2、导入数据集
data_dir = "E:\深度学习\data\Day13"
data_dir = pathlib.Path(data_dir)
3、查看数据集
查看数据集内有多少张图片:
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:",image_count)
运行的结果是:
图片总数为: 2142
从数据集内返回一张图片查看一下:
Monkeypox = list(data_dir.glob('Monkeypox/*.jpg'))
PIL.Image.open(str(Monkeypox[0]))

四、数据预处理
1、加载数据
我们使用image_dataset_from_directory方法将我们本地的数据加载到tf.data.Dataset
中,并设置训练图片模型参数:
batch_size = 32
img_height = 224
img_width = 224
然后我们将数据分成测试集和验证集加载进来,这里引入了一个新概念——验证集,前面我们都只接触学习了训练集和测试集,在机器学习中这三种数据集非常容易弄混淆,特别是验证集和测试集,下面我们来分别对三种数据集进行简单的介绍:
-
训练集
顾名思义,就是用来训练模型内参数的数据集,这个容易理解。
-
验证集
它是用于在训练过程中检验模型的状态和收敛情况的,验证集通常用于调整超参数,根据几组模型验证集上的表现决定哪组超参数拥有最好的性能。我们后面就需要进行选择最好性能的模型参数,同时验证集在训练过程中还可以用来监控模型是否发生过拟合。
-
测试集
它是用来评价模型的泛化能力的,意思是之前模型使用验证机确定了超参数,使用训练集调整了参数,最后使用一个从没有见过的数据集来判断这个模型是否能正常工作,就是将我们的训练的模型放入真实环境下进行测试看它训练的怎么样。
-
三者的关系
打个比方,训练集就像我们学习用的课本书籍,我们利用这些进行知识学习,验证集就相当于老师平时为我们布置的作业,老师可以通过学生的作业情况知道不同的学生的学习情况和进步的速度,而测试集就也是学期末检验考试,检测学生一学期知识掌握情况,而且考的题目是老师自己出了,学生没有做过,用于考察学生的学习能力和举一反三的能力。
介绍完上面这些,我们现在来将数据加载进来:
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 2142 files belonging to 2 classes.
Using 428 files for validation.
Found 2142 files belonging to 2 classes.
Using 1714 files for training.
这里也可以看到我们两个数据分别有多少文件。
然后我们再利用class_name输出我们本地数据集的标签,标签也就是对应数据所在的文件目录名:
class_names = train_ds.class_names
print(class_names)
['Monkeypox', 'Others']
2、检查数据并可视化数据
在可视化数据前,我们来检查一下我们的数据信息是否是正确的:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 224, 224, 3)
(32,)
可以看出这是一批180×180×3的32张图片,然后我们将数据进行可视化看看:
plt.figure(figsize=(20, 10))
for images, labels in train_ds.take(1):
for i in range(20):
ax = plt.subplot(5, 10, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")

可以看见每张照片都对应一个标签并且照片大小都一致。
3、配置数据集
配置数据集之前我们需要了解其中的三个函数:
- **shuffle()**函数用来打乱数据集中数据顺序,可以防止数据过拟合,使模型得到更加正确的特征。因为深度学习机器学习对数据的要求需要满足独立同分布,我们打乱数据就可以满足其随机性,使训练的模型更好。
- **prefetch()**函数用于生成从给定数据集中预取指定元素的数据集。预取与训练步骤的预处理和模型执行重叠。当模型执行训练步骤 s 时,输入管道正在读取步骤 s+1 的数据。这样做可以将步骤时间减少到训练的最大值(而不是总和)以及提取数据所需的时间,加速运行,如果不使用这个函数方法,那么CPU和GPU/TPU在大部分时间内都是处于空闲状态。
- **cache()**函数转换可以在内存或本地存储中缓存数据集。这将避免在每个时期执行一些操作(如文件打开和数据读取)。下一个 epoch 将重用缓存转换缓存的数据。也可以加速运行。
具体的函数说明大家可以去TensorFlow官方文档去看一下。
AUTOTUNE = tf.data.experimental.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
这里第一段代码是我修改之后的,原来是:AUTOTUNE = tf.data.AUTOTUNE
如果你运行出现如下这样的错误,改成和我一样的就行:
AttributeError: module 'tensorflow._api.v2.data' has no attribute 'AUTOTUNE'
五、构建CNN网络
有关CNN网络的知识可以去我之前的博客看一下,更好的是去网上找一些大佬的博客文章看一下,在这里我就不再重复介绍了。
num_classes = 2
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.Dropout(0.3),
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.Dropout(0.3),
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(num_classes) # 输出层,输出预期结果
])
model.summary() # 打印网络结构
打印出来的结果是:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling (Rescaling) (None, 224, 224, 3) 0
_________________________________________________________________
conv2d (Conv2D) (None, 222, 222, 16) 448
_________________________________________________________________
average_pooling2d (AveragePo (None, 111, 111, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 109, 109, 32) 4640
_________________________________________________________________
average_pooling2d_1 (Average (None, 54, 54, 32) 0
_________________________________________________________________
dropout (Dropout) (None, 54, 54, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 52, 52, 64) 18496
_________________________________________________________________
dropout_1 (Dropout) (None, 52, 52, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 173056) 0
_________________________________________________________________
dense (Dense) (None, 128) 22151296
_________________________________________________________________
dense_1 (Dense) (None, 2) 258
=================================================================
Total params: 22,175,138
Trainable params: 22,175,138
Non-trainable params: 0
_________________________________________________________________
六、编译模型
设置损失函数、优化器,指标为准确率。
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=1e-4)
model.compile(optimizer=opt,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
七、训练模型
这里我们导入keras函数中回调函数callbacks中ModelCheckpoint方法,用于将在每个epoch后保存模型到filepath中,file path后缀必须是.h5,它的函数模型是:
keras.callbacks.ModelCheckpoint(filepath,
monitor='val_loss',
verbose=0,
save_best_only=False,
save_weights_only=False,
mode='auto',
period=1)
函数内的参数作用分别是:
| 参数名 | 说明 |
|---|---|
| filepath | 字符串,保存模型的路径,filepath可以是格式化的字符串,里面的占位符将会被epoch值和传入on_epoch_end的logs关键字所填入。 |
| monitor | 需要监视的值,通常为:val_acc 或 val_loss 或 acc 或 loss |
| verbose | 信息展示模式,0或1。为1表示输出epoch模型保存信息,默认为0表示不输出该信息 |
| save_best_only | 当设置为True时,将只保存在验证集上性能最好的模型 |
| save_weights_only | 若设置为True,则只保存模型权重,否则将保存整个模型(包括模型结构,配置信息等) |
| mode | ‘auto’,‘min’,‘max’之一,在save_best_only=True时决定性能最佳模型的评判准则,例如,当监测值为val_acc时,模式应为max,当检测值为val_loss时,模式应为min。在auto模式下,评价准则由被监测值的名字自动推断。 |
| period | CheckPoint之间的间隔的epoch数 |
from tensorflow.keras.callbacks import ModelCheckpoint
epochs = 50
checkpointer = ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=1,
save_best_only=True,
save_weights_only=True)
history = model.fit(train_ds,
validation_data=val_ds,
epochs=epochs,
callbacks=[checkpointer])
它训练的结果是:
Epoch 1/50
54/54 [==============================] - ETA: 0s - loss: 0.7823 - accuracy: 0.5251
Epoch 00001: val_accuracy improved from -inf to 0.53505, saving model to best_model.h5
54/54 [==============================] - 22s 402ms/step - loss: 0.7823 - accuracy: 0.5251 - val_loss: 0.6773 - val_accuracy: 0.5350
Epoch 2/50
54/54 [==============================] - ETA: 0s - loss: 0.6754 - accuracy: 0.5770
Epoch 00002: val_accuracy improved from 0.53505 to 0.56776, saving model to best_model.h5
54/54 [==============================] - 21s 390ms/step - loss: 0.6754 - accuracy: 0.5770 - val_loss: 0.6652 - val_accuracy: 0.5678
Epoch 3/50
54/54 [==============================] - ETA: 0s - loss: 0.6545 - accuracy: 0.6342
Epoch 00003: val_accuracy improved from 0.56776 to 0.64019, saving model to best_model.h5
54/54 [==============================] - 21s 390ms/step - loss: 0.6545 - accuracy: 0.6342 - val_loss: 0.6428 - val_accuracy: 0.6402
Epoch 4/50
54/54 [==============================] - ETA: 0s - loss: 0.6316 - accuracy: 0.6365
Epoch 00004: val_accuracy improved from 0.64019 to 0.66355, saving model to best_model.h5
54/54 [==============================] - 21s 397ms/step - loss: 0.6316 - accuracy: 0.6365 - val_loss: 0.6277 - val_accuracy: 0.6636
Epoch 5/50
54/54 [==============================] - ETA: 0s - loss: 0.6062 - accuracy: 0.6739
Epoch 00005: val_accuracy improved from 0.66355 to 0.69626, saving model to best_model.h5
......
Epoch 45/50
54/54 [==============================] - ETA: 0s - loss: 0.1699 - accuracy: 0.9405
Epoch 00045: val_accuracy did not improve from 0.85280
54/54 [==============================] - 21s 387ms/step - loss: 0.1699 - accuracy: 0.9405 - val_loss: 0.4511 - val_accuracy: 0.8458
Epoch 46/50
54/54 [==============================] - ETA: 0s - loss: 0.1817 - accuracy: 0.9352
Epoch 00046: val_accuracy did not improve from 0.85280
54/54 [==============================] - 22s 413ms/step - loss: 0.1817 - accuracy: 0.9352 - val_loss: 0.4760 - val_accuracy: 0.8388
Epoch 47/50
54/54 [==============================] - ETA: 0s - loss: 0.1848 - accuracy: 0.9312
Epoch 00047: val_accuracy did not improve from 0.85280
54/54 [==============================] - 21s 393ms/step - loss: 0.1848 - accuracy: 0.9312 - val_loss: 0.4502 - val_accuracy: 0.8388
Epoch 48/50
54/54 [==============================] - ETA: 0s - loss: 0.1845 - accuracy: 0.9288
Epoch 00048: val_accuracy did not improve from 0.85280
54/54 [==============================] - 21s 390ms/step - loss: 0.1845 - accuracy: 0.9288 - val_loss: 0.4344 - val_accuracy: 0.8318
Epoch 49/50
54/54 [==============================] - ETA: 0s - loss: 0.1652 - accuracy: 0.9405
Epoch 00049: val_accuracy did not improve from 0.85280
54/54 [==============================] - 21s 389ms/step - loss: 0.1652 - accuracy: 0.9405 - val_loss: 0.4286 - val_accuracy: 0.8505
Epoch 50/50
54/54 [==============================] - ETA: 0s - loss: 0.1792 - accuracy: 0.9277
Epoch 00050: val_accuracy did not improve from 0.85280
54/54 [==============================] - 21s 392ms/step - loss: 0.1792 - accuracy: 0.9277 - val_loss: 0.4359 - val_accuracy: 0.8505
val_loss,val_acc=model.evaluate(val_ds,verbose=2)
14/14 - 1s - loss: 0.4359 - accuracy: 0.8505
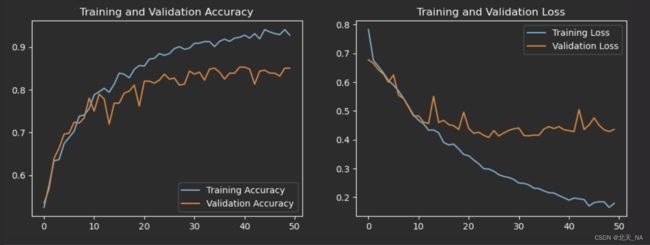
可以看出测试集accuracy为0.8505。
如果你在训练模型的时候报如下的错误:
AttributeError: module 'h5py' has no attribute 'File'
这是因为这个库不规范造成的,你需要先利用pip卸载这个库,然后再使用conda安装这个库,就可以解决了。
八、模型评估
1、绘制Loss(损失)图和Accuracy(准确性)图
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
2、在本地指定图片进行预测
我们预测的时候加载效果最好的模型权重进行预测:
model.load_weights('best_model.h5')
from PIL import Image
import numpy as np
img = Image.open("E:\深度学习\data\Day13\Monkeypox\M30_02_12.jpg") #这里选择你需要预测的图片
image = tf.image.resize(img, [img_height, img_width])
img_array = tf.expand_dims(image, 0)
predictions = model.predict(img_array) # 这里选用你已经训练好的模型
print("预测结果为:",class_names[np.argmax(predictions)])
它运行的结果是:
Monkeypox
九、尝试增加卷积层
在前面构建CNN网络的时候我们加深网络结构试一下:
num_classes = 2
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样
layers.BatchNormalization(),
layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.BatchNormalization(),
layers.Dropout(0.3),
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层3,2*2采样
layers.BatchNormalization(),
layers.Dropout(0.3),
layers.Conv2D(128, (3, 3), activation='relu'), # 卷积层4,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层4,2*2采样
layers.BatchNormalization(),
layers.Dropout(0.3),
layers.Conv2D(256, (3, 3), activation='relu'), # 卷积层5,卷积核3*3
layers.Dropout(0.3),
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(512, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(num_classes) # 输出层,输出预期结果
])
model.summary() # 打印网络结构
打印的结果是:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling_1 (Rescaling) (None, 224, 224, 3) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 222, 222, 16) 448
_________________________________________________________________
average_pooling2d_2 (Average (None, 111, 111, 16) 0
_________________________________________________________________
batch_normalization (BatchNo (None, 111, 111, 16) 64
_________________________________________________________________
conv2d_4 (Conv2D) (None, 109, 109, 32) 4640
_________________________________________________________________
average_pooling2d_3 (Average (None, 54, 54, 32) 0
_________________________________________________________________
batch_normalization_1 (Batch (None, 54, 54, 32) 128
_________________________________________________________________
dropout_2 (Dropout) (None, 54, 54, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 52, 52, 64) 18496
_________________________________________________________________
average_pooling2d_4 (Average (None, 26, 26, 64) 0
_________________________________________________________________
batch_normalization_2 (Batch (None, 26, 26, 64) 256
_________________________________________________________________
dropout_3 (Dropout) (None, 26, 26, 64) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 24, 24, 128) 73856
_________________________________________________________________
average_pooling2d_5 (Average (None, 12, 12, 128) 0
_________________________________________________________________
batch_normalization_3 (Batch (None, 12, 12, 128) 512
_________________________________________________________________
dropout_4 (Dropout) (None, 12, 12, 128) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 10, 10, 256) 295168
_________________________________________________________________
dropout_5 (Dropout) (None, 10, 10, 256) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 25600) 0
_________________________________________________________________
dense_2 (Dense) (None, 512) 13107712
_________________________________________________________________
dense_3 (Dense) (None, 2) 1026
=================================================================
Total params: 13,502,306
Trainable params: 13,501,826
Non-trainable params: 480
_________________________________________________________________
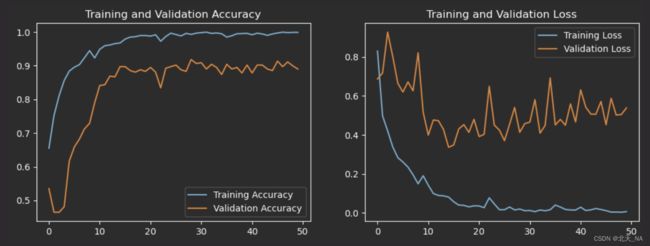
然后后面的过程不变,我们看看最后测试集accuracy是否提高了。
调整之后绘制的Loss(损失)图和Accuracy(准确性)图:
val_loss,val_acc=model.evaluate(val_ds,verbose=2)
14/14 - 1s - loss: 0.5382 - accuracy: 0.8902
可以看出测试集accuracy相比于开始提高了。
十、尝试调整模型参数
前面的模型参数调整为:
batch_size = 32
img_height = 180
img_width = 180
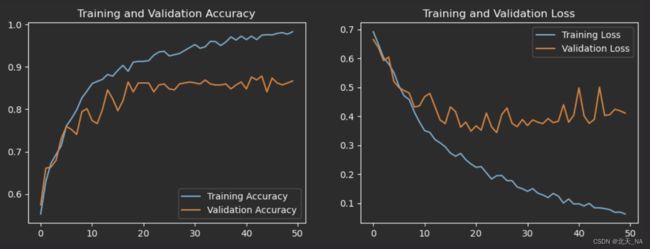
其他的不变,再次进行训练模型查看最后测试集accuracy是否提高了。
调整之后绘制的Loss(损失)图和Accuracy(准确性)图:
val_loss,val_acc=model.evaluate(val_ds,verbose=2)
14/14 - 1s - loss: 0.4107 - accuracy: 0.8668
可以看出相比于前面的调整测试集accuracy下降了,但还是比开始的accuracy高一点。
十一、最后我想说
大家还可以尝试将上面两个调整方法结合起来训练试试,也可以调整epochs次数,还有GPU和CPU切换尝试等等,有很多种组合调整方式,因为本人机器并不太好,所以就没有依次去实验,因为本人电脑性能不够,加上训练时间太长,所以就尝试了两种,见谅。(连续训练模型容易导致电脑发烫严重,请分开进行测试!)
另外设置动态学习率本人实属不会,水平有限,大家可以去网上看看其他大佬的设置,并进行尝试。
最后,深度学习需要大家去不断摸索,不断总结,进行各种模型改进,算法优化等等,来训练出一个优质的模型并运用在解决实际问题上。