Oracle数据库是如何执行SQL的
文章目录
- 1、参考资料
- 2、Oracle SQL执行过程
-
- 2.1、SQL语句的执行过程
-
- 2.1.1、全局角度来看SQL请求的执行过程
- 2.1.2、数据库端处理SQL具体过程
- 2.2、Oracle对解析过程的优化
-
- 2.2.1、减少硬解析 -- 软解析(Soft parse)
- 2.2.2、进一步减少软解析 -- 软软解析(Soft soft parse)
- 2.2.3、一次解析,多次执行 -- 客户端语句缓存(statement cache)
- 2.2.4、最高境界,不执行sql -- SQL结果集缓存
1、参考资料
oracle concepts ->Overview of SQL Processing
SQL Parsing Flow Diagram (Doc ID 32895.1)
Overview of SQL Statement Processing Phases (Doc ID 199273.1)
《Oracle编程艺术 深入理解数据库体系结构》
《基于Oracle的SQL优化》
2、Oracle SQL执行过程
2.1、SQL语句的执行过程
2.1.1、全局角度来看SQL请求的执行过程
从用户端发送一条请求,请求中需要处理数据,发送SQL语句给数据库去执行示意图如下:

1. 用户发送一个服务请求,应用通过线程池(充分合理的协调利用cpu 、内存、网络、i/o等系统资源)来高效的利用资源,当处理的请求中需要访问数据库时,执行SQL语句的请求就要从数据库连接池get connection可以快速和数据库建立连接,节省了连接数据库的时间。因为连接数据库比较慢,所以有必要提前按照连接池配置的大小来初始化连接。
2. 连接池初始化过程中是如何与数据库建立联系?
连接池发出连接请求,ojdbc驱动通过IP+端口+服务名与远程数据库连接,数据库主机上处理网络请求的是监听程序。
监听器是数据库服务器端的“门卫”,监听器注册了数据库实例信息,当它接收到请求时,会用自己的配置文件检查这个请求,如果服务名不对或者IP地址是受限的,则不允许连接数据库。
Oracle处理连接请求有两种方式:
1)、专用服务模式(dedicated server) 目前生产使用,也是最常用方式
如果通过直连方式建立专用服务器连接,监听器就会为我们创建一个专用服务器进程,就是上图中看到的Server Process。在linux中是通过fork()系统调用方法来创建这个新的专用服务器进程,所以看到的父进程(PPID)都是1。这个新的进程“继承”了监听器建立的连接,此时就与数据库“物理”地连上了。示意图如下:
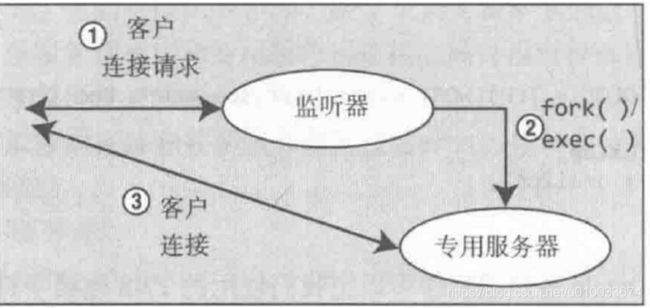
在这种模式下,对于每一个客户端(或应用的数据库连接池)会话都会新建一个专用的服务器进程,会话与专用服务器进程是一对一映射关系,这个服务器进程用来接收和执行SQL、读取数据或者在数据库缓存中查找想要的数据等。
2)、共享服务模式方式
请求连接共享服务器时,监听器的行为和专用服务器不一样,实际上监听器进程知道实例中运行了哪些调度程序,监听接收到连接共享服务器请求后,它会从调度程序池中选一个调度程序进程。监听器向客户连接返回如何与调度程序进程连接的信息,做了一次连接请求“转发”,把连接请求转发给调度进程后,监听器的工作就完成了。客户连接接下来与监听器断开连接,并与调度进程直接连接,最后客户连接与数据库建立了连接。这个过程如下图所示:
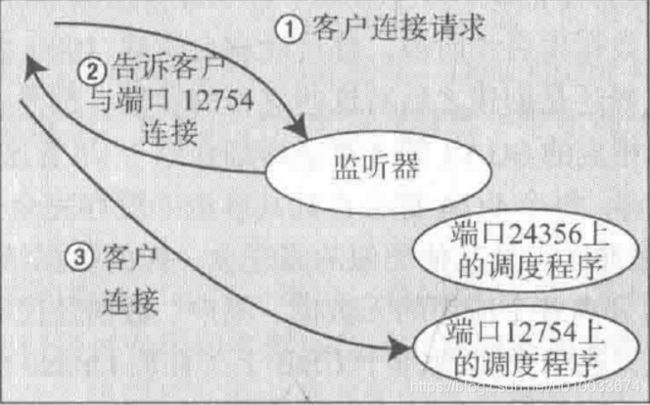
相比于专用服务器模式,服务器不会为每个用户连接创建新的进程。Oracle使用一个“共享进程池”为多个用户提供连接服务,共享服务器实际上就是一种连接池机制,和应用端的数据库连接池目的是一样的。所有的用户连接会话共享池子中的连接进程。
与专用服务器大的区别在于:客户进程不与共享服务器直接通信,专用服务进程会与专用服务器直接通信,因为是共享的,不能建立一对一的专有机制。所以,oracle使用了一组调度程序(dispatcher或叫分派程序)进程。客户进程通过网络与一个调度器进程进行通信,调度程序进程将客户的请求放入SGA的请求队列;第一个空闲共享服务器会得到这个请求并进行处理;当完成SQL执行命令后,共享服务器会把相应放在原调度程序(即接收请求的调度程序)的响应队列中。期间,调度程序进程一直在监视这个队列,当它发现有结果后,就会把结果回传给客户进程。如下示意图:

调度过程说明: 调度程序首先将请求放在SGA的请求队列中①。空闲可用的共享服务连接进程从请求队列中取出②并处理。共享服务器处理结束后,再把响应(返回码、数据等)放到响应队列中③,接下来调度程序拿到这个响应④,回传给客户连接。
3. 服务器进程接收到SQL语句请求后,在数据库中进行一系列解析工作,最终生成SQL执行计划,这一步骤有很多优化点,后面详细分解。
4. 执行SQL语句阶段
1)查询语句,服务器进程从实际数据文件(表)或数据库缓冲区高速缓存中存储的值中检索任何必需的数据值。
2)DML语句,服务器进程修改 SGA(database buffer cache) 中的数据。因为提交了事务处理,所以日志写进程 (LGWR) 会立即将该事务处理记录到重做日志(redo log)文件中。数据库写进程 (DBWn)按照触发条件将修改后的数据块永久刷入磁盘。
5. 如果事务处理成功,服务器进程将通过网络向应用程序发送一条消息。如果事务处理不成功,则传送一条错误消息。
6. 在整个SQL处理过程中,其它后台进程同时在运行,用于监视是否有需要干预的情况。比如,某用户对应的server process出现了异常,后台pmon进程对该服务器进程进行清理和回收。
2.1.2、数据库端处理SQL具体过程
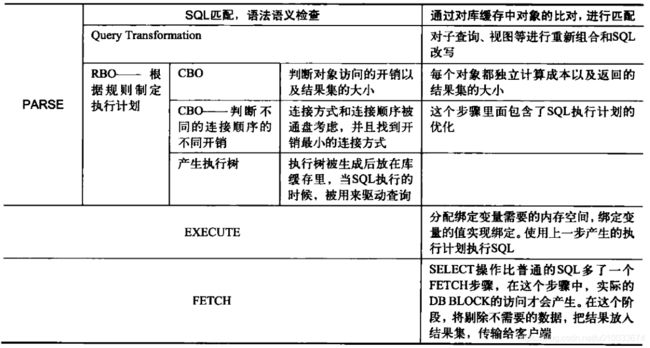
现在具体来说说sql在数据库端处理流程。按照oracle官方的说法,SQL语句的执行有以下步骤:
| 编号 | 步骤 | 说明 |
|---|---|---|
| 1 | Syntactic | 语法检查 |
| 2 | Semantic | 确认所有对象都存在并且可以访问 |
| 3 | View Merging | 进行查询重写优化 |
| 4 | Statement Transformation | 将复杂查询分解 |
| 5 | Optimization | 确定访问方式,选择优化策略 |
| 6 | QEP Generation | 形成执行计划。QEP(query execution plan) |
| 7 | QEP Execution | 运行执行计划 |
上面写的7个步骤中,前面6个步骤就是通常说的解析(parsing),第7个步骤就是通常说的SQL执行(execution)。同样来自oracle官方文档Overview of SQL Statement Processing Phases (Doc ID 199273.1),详细的描述了每个过程中数据库都在做什么,如下图:
2.2、Oracle对解析过程的优化
2.2.1、减少硬解析 – 软解析(Soft parse)
什么是硬解析? 硬解析(Hard parse) 即把整个SQL语句的执行需要完完全全的解析,生成执行计划。
而硬解析的代价挺高的,生成执行计划需要耗用CPU资源,以及共享内存(主要是SGA中shared pool区域)资源。shard pool的一个组件库缓存(libary cache) 使用闩(latch)和mutex来保护共享内存结构。闩是锁的细化,是一种轻量级的串行化设备,有锁池和排队机制。当进程申请到闩后,则这些闩用于保护共享内存的数在同一时刻不会被两个以上的进程修改。在硬解析时,需要申请闩的使用(shared pool latch),大量的闩的使用由此造成需要使用闩的进程排队越频繁,性能则逾低下。具体更深入的细节,Oracle官方文档并未透漏太多,这里也不做细讲,有兴趣的参考网络上的文章以及流露出来的DSI文档。
由于硬解析对数据库性能损耗比较严重,所以oracle就把执行过的sql的执行计划缓存到共享池(shared pool)里面,当遇到重复执行的SQL从共享池里面匹配到执行计划后,直接去执行即可,跳过完整解析的很多步骤,从而提高SQL运行效率,从共享池中匹配到执行计划,直接去执行sql的过程叫软解析(Soft parse),如下图所示:
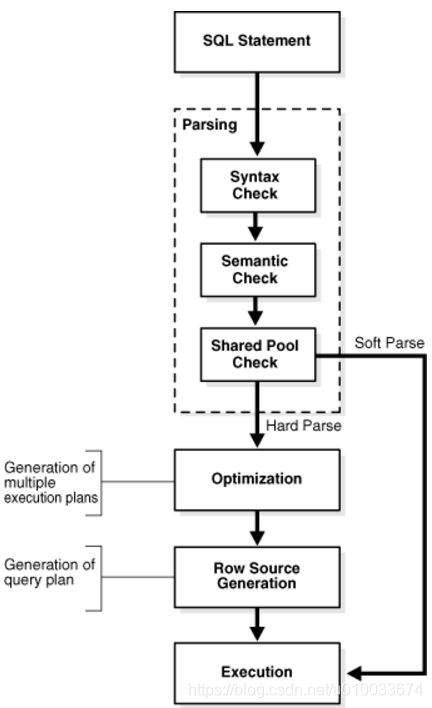
当应用程序发出SQL语句时,应用程序对应的服务器进程对数据库进行解析调用(parse call),以准备执行该语句。解析调用打开或创建游标。
游标(cursor) 可以简单理解为是执行sql的载体。具体是特定于会话的私有SQL区域的句柄,该区域保存已解析的SQL语句和其他处理信息。游标和私有SQL区域在PGA中。如下图所示:
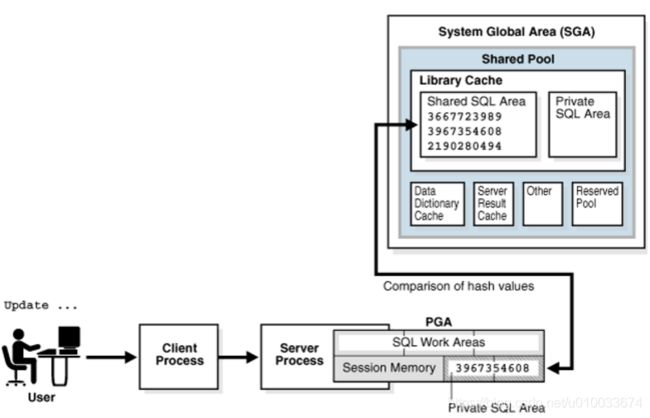
接着上图,具体是如何做shared pool check最后命中libary cache中的缓存的对象(执行计划):
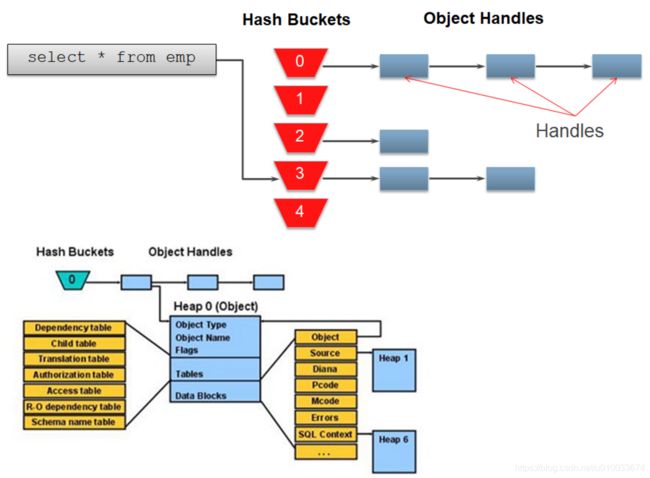
上面两个扣来的图可以看出,整个库缓存可以看做是由一组Hash Bucket组成,每一个Hash Bucket都对应不同的哈希值,对于单个Hash Bucket而言,里面存储的就是哈希值相同的所有库缓存对象句柄,同一个Bucket中不同的库缓存对象句柄(父游标句柄)之间用指针连接起来,组成了一个库缓存对象句柄链表(Library Cache Object Handles。
图例中,当oracle执行目标sql "select * from emp"时,首先对该sql的sql文本进行hash运算,然后根据计算的hash值去相关Hash Bucket中遍历对应的库缓存对象句柄链表,如果找到了对应的库缓存对象句柄(父游标句柄),接着继续通过父游标的heap 0中相关信息,遍历子游标句柄,最终找到子游标中该SQL的执行计划、解析树等对象;如果找不到对应的库缓存对象句柄,或者找到父游标但对应的子游标没有,则意味着要做硬解析的工作,需要从头把硬解析后的执行计划、解析树等对象链接在相关的Hash Bucket中的库缓存对象句柄链接表中。
总结来看: 硬解析和软解析重要的一个区别是shared pool check(检查组件libary cache)是否能找到缓存的执行计划相关信息
2.2.2、进一步减少软解析 – 软软解析(Soft soft parse)
软解析会搜索shared pool中library cache 过多的软解析仍然可能会导致系统问题,特别是如果有少量的SQL高并发地进行软解析,会产生library cache latch或者是share方式的mutex争用,比如数据库中出现大量的library cache相关等待事件。看oracle是如何优化这一点的
shared cursor概念:
了解了上面讲的库缓存结构后,shared cursor就是指缓存在库缓存里的一种库缓存对象,也是一种库缓存对象之一。shared cursor存储了目标sql的sql文本、解析树、该sql所涉及的对象定义、该sql所使用的绑定变量类型和长度、执行计划等信息。简单点说cursor就是为了执行sql的,是执行sql的载体。
session cursor概念:
它是当前session解析和执行sql的载体,属于客户端所属会话私有的,存储在PGA里面,session cursor与session是一一对应的,不同session的session cursor之间不共享,而shared cursor是所有会话可以共享的。
session cursor中存储的是库缓存中对象句柄的地址、sql文本hash等信息,并没有像shared cursor一样存储sql文本、执行计划等信息,就是个指向要访问具体对象句柄的链接,如果缓存了session cursor就可以直接访问到执行计划,省去了通过层层搜索库缓存的很多步骤。
客户端sql执行时必须要有一个session cursor,并且只能对应一个shared cursor,前面讲过 一个shared cursor却可以同时对应多个session cursor。
session cursor 会经历Open、Parse、Bind、Execute、Fetch、Close中的一个或多个阶段。
什么是软软解析:
如果数据库参数session_cached_cursor值大于0,当满足一定额外条件(session cursor对应的SQL解析和执行次数超过3次),虽然sql执行完毕客户端发送了close cursor命令,但oracle不会对session cursor完全执行close操作,将其标记为soft closed,同时将其缓存到当前session PGA中,当目标sql再次被重复执行时shared cursor和session cursor中都能匹配到记录,意味着oracle执行sql时节省了open一个新cursor所消耗的资源和时间,colse cursor也不需要做了(soft close),只需要做Parse、Bind、Execute、Fetch; 并且在Parse期间根据缓存在session cursor中的句柄链接地址,也就是子游标堆6的DS(堆描述符),直接访问到执行计划对象句柄,省去了不少搜索库缓存句柄。
试想,如果某个父游标下子游标数量很多,搜索整个链表的时间过长,执行sql频次又很高,那么软软解析的优势就会体现出来。
子游标堆6的DS(堆描述符):

游标共享过程和对应解析类型:
无论是硬解析、软解析还是软软解析,oracle在解析和执行目标sql时,始终会去匹配当前session的session_cached_cursor缓存。
硬解析情况: 如果在当前session的pga中找不到匹配的session cursor,oracle就会去库缓存中找是否存在匹配的Parent Cursor。如果找不到,oracle就会新生成一个session cursor和一对shared cursor(parent cursor和child cursor);如果找到了匹配的parent cursor,但找不到匹配的child cursor,oracle就会新生成一个session cursor和一个child cursor(挂载匹配到的parent cursor)。以上这两个过程对应的都是硬解析。
软解析情况: 如果在当前session的pga中找不到匹配的缓存session cursor,但在库缓存中找到了匹配的parent cursor和child cursor,则oracle会新生成一个session cursor并重用刚刚找到的匹配parent cursor和child cursor,这个过程对应的就是软解析。
软解析(软软解析)情况: 如果在当前session的pga中找到了匹配的缓存session cursor,此事就不再需要重新生成一个session cursor,并且也不再需要像软解析那样去库缓存中层层查找匹配到parent cursor、child cursor,因为oracle此时可以重用找到的匹配session cursor,并且可以通过这个session cursor中记录的对象句柄地址直接访问到执行该sql所需的对象(包括执行计划句柄等),这个过程就是软软解析。
2.2.3、一次解析,多次执行 – 客户端语句缓存(statement cache)
前面讲的软软解析过程中,在session_cached_cursor做了一次查找命中,数据库把软软解析算作一次解析,seeion cursor做了软关闭并额外记录些信息。数据库做这些事情还是会有很少量的性能损耗,如果sql执行量非常大的话,这些累计的性能损耗就不得不重视了。
数据库上连接的应用可能有好几百个,如果让客户端应用来做类似session_cached_cursor做的事情,就可以在提升数据库性能的前提下减轻数据库负载。
客户端statement cache缓存游标,可以实现当执行close cursro命令时跳过关闭命令,不会将关闭命令发送给oracel去执行,而前面讲的数据库端session_cached_cursor是将游标soft close并记录额外的信息方便快速打开并复用。由于cursor在客户端程序发出关闭命令后,跳过了关闭,并没有真的关闭,所以客户端缓存对应的session cursor一直处于打开状态,从而节省了open cursor、parse、close cursor这些步骤。
以下是Druid(德鲁伊)开启语句缓存解析次数和执行次数前后对比:
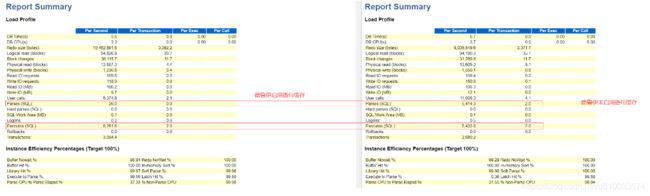
在同样的应用压测场景下,应用响应时间以及TPS有小幅度提升,如果SQL执行量特别大的时候,还是可以考虑该功能的。
2.2.4、最高境界,不执行sql – SQL结果集缓存
对于某些表数据不频繁变更的静态查询类SQL,如果把相同sql查询的结果缓存起来,就不需要去执行sql了,更没有sql语句解析一说。Oracle提供了服务器端result cache和OCI客户端查询缓存两种方式。
服务器端result cache:
由数据库参数RESULT_CACHE_MODE(默认值MANUAL)、RESULT_CACHE_MAX_SIZE(结果集缓存总大小)控制。默认情况下查询语句指定了/+RESULT_CACHE/优化器提示,那么结果被缓存。
应用场景:生产系统中不会开启该参数值为auto,会引起性能问题,以及不可预知的bug问题。所以服务器端结果集缓存功能并不适用。
OCI客户端查询缓存:
关于oracle OCI接口介绍参考:https://www.oracle.com/cn/database/technologies/appdev/oci.html
在使用oracle调用接口(oci)客户端的应用中可以将经常执行查询的结果集缓存在本地。为了利用客户端缓存,必须在数据库中设置参数:
client_result_cache_size(默认值0):
所有oci客户端进程获取最大的缓存,它可以被客户端配置文件或sqlnet.ora配置参数oci_result_cache_size所覆盖。
client_result_cache_lag(默认3000毫秒):
指定自从上一次往返于服务器以来的最长时间,OCI客户端查询需要在此时间之前往返于服务器,以获取与客户端缓存的查询相关的任何数据库变化。
应用场景:生产环境的应用中使用oci方式比较少,大部分使用jdbc方式连接数据库。所以,oci客户端查询缓存不常用。
sql结果集缓存最佳实践:
使用以redis为代表的内存数据库,由代码去灵活控制结果缓存策略,比如:当某表上其中一行数据发生更改后,redis中相应的key就可以置为失效。