python 高级特性
一:切片
取一个list或tuple的部分元素是非常常见的操作。比如,一个list如下:
>>> L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']
取前3个元素,应该怎么做?
以前的方法:
>>> [L[0], L[1], L[2]]
['Michael', 'Sarah', 'Tracy']
之所以是笨办法是因为扩展一下,取前N个元素就没辙了。取前N个元素,也就是索引为0-(N-1)的元素,可以用循环:
>>> r = []
>>> n = 3
>>> for i in range(n):
... r.append(L[i])
>>> r
['Michael', 'Sarah', 'Tracy']
对应上面的问题,取前3个元素,用一行代码就可以完成切片:
>>> L[0:3]
['Michael', 'Sarah', 'Tracy']
L[0:3]表示,从索引0开始取,直到索引3为止,但不包括索引3。即索引0,1,2,正好是3个元素。
如果第一个索引是0,还可以省略:
>>> L[:3]
['Michael', 'Sarah', 'Tracy']
python中提供了切片(Slice)操作符 , 可以方便的获取list或tuple中的某一段元素 。

二:迭代
迭代是Python最强大的功能之一,是访问集合元素的一种方式 。


如何判断一个对象是一个可迭代对象。

遍历二维list

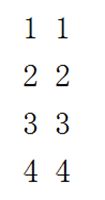
enumerate函数
Python内置的enumerate函数可以把一个list变成索引-元素对,这样就可以在for循环中同时迭代索引和元素本身:
>>> for i, value in enumerate(['A', 'B', 'C']):
... print(i, value)
...
0 A
1 B
2 C
三:列表生成式
列表生成式即List Comprehensions , 是Python内置的非常简单却强大的可以 用来创建List 的生成式 。
列表普通定义如下:
list1 = [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] # 普通自定义列表生成式:会将所有的结果全部计算出来,把结果存放到内存中
list1 = []
for x in range(10):
list1.append(x * x)
print(list1)
list1 = [x * x for x in range(10)]
要生成list [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]可以用list(range(1, 11)):
>>> list(range(1, 11))
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
但如果要生成[1x1, 2x2, 3x3, ..., 10x10]怎么做?
一般方式:
>>> L = []
>>> for x in range(1, 11):
... L.append(x * x)
...
>>> L
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
列表生成式的方式:
>>> [x * x for x in range(1, 11)]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
写列表生成式时,把要生成的元素x * x放到前面,后面跟for循环,就可以把list创建出来
for循环后面还可以加上if判断,这样我们就可以筛选出仅偶数的平方:
>>> [x * x for x in range(1, 11) if x % 2 == 0]
[4, 16, 36, 64, 100]
还可以使用两层循环,可以生成全排列:
>>> [m + n for m in 'ABC' for n in 'XYZ']
['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']
四:生成器
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
一边循环一边计算的机制,称为生成器:generator。
五:生成器创建
创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:

创建L和g的区别仅在于最外层的[]和(),L是一个list,而g是一个generator。
六:生成器遍历
1、next() 方法可以访问生成器的内容,不可逆。

2、通过for循环来遍历,因为generator也是可迭代对象:

七:生成器--YIELD
yield关键字
带有 yield 的函数在 Python 中被称之为 generator(生成器)

八:迭代器
可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
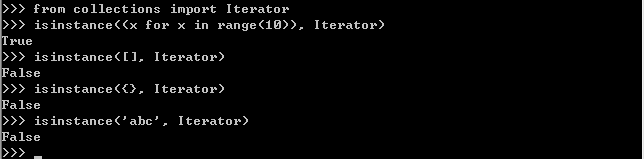
使用isinstance()判断一个对象是否是Iterator对象:
小结:
1、凡是可作用于for循环的对象都是Iterable类型;
2、凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
3、集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。