[面经整理](机器/深度学习篇)
文章目录
- ~~~~~~~~~~~~ 机器学习 ~~~~~~~~~~~~
- 特征工程
-
- 为什么需要做特征归一化?
- 常用的归一化方法有哪些?
- transforms.Normalize()与transforms.ToTensor()(标准化-归一化)
- 为什么要标准化
- 模型评估
-
- 准确率的局限性
- 精确率与召回率的权衡
- AUC和交叉熵在分类上的区别与联系
- AUC& ROC
-
- ROC 与 PR
- 如何判断过拟合与欠拟合
- 欠拟合、过拟合及如何防止过拟合
- L1和L2正则化为什么可以防止过拟合
- 实现参数的稀疏有什么好处?
- 经典方法
-
- 线性回归梯度下降
- 逻辑回归梯度下降
- 推导逻辑回归的损失函数和梯度计算
- 简单概括一下SVM
- SVM如何处理多分类问题?
- 为什么SVM对缺失数据敏感?
- 为何将原始问题转为对偶问题?/ 引入对偶算法的优点?
- SVM核函数的选择
- LR逻辑回归和SVM的联系与区别
- 降维
-
- 简述主成分分析PCA工作原理
- PCA的优缺点
- LDA介绍一下
- PCA和LDA有什么区别
- SNE
- t-SNE
- 非监督学习
-
- 聚类和分类的区别
- 简述K均值算法的具体步骤
- 时间复杂度/空间复杂度
- K均值算法的优缺点是什么?如何对其进行调优?
- Kmeans数据不平衡问题
- 合理选择K值
- 初始点怎么选取,为什么敏感?你有什么改进的点?
- 聚类的评定标准
- 高斯混合模型的核心思想是什么?它是如何迭代计算的?
- 集成学习
-
- 集成学习分哪几种?他们有什么异同?
- 什么是偏差和方差
- 如何从减小方差和偏差的角度解释Boosting和Bagging的原理?
- GBDT的基本原理
- 梯度提升和梯度下降的区别和联系是什么?
- XGBoost和GBDT的不同
- AdaBoost
- 前向神经网络
-
- 写出多层感知机的平方误差和交叉熵损失函数
- 平方误差函数和交叉熵损失函数分别适合什么场景?/LR不使用MSE而使用交叉熵损失函数的原因
- ~~~~~~~~~~~~ 深度学习 ~~~~~~~~~~~~
- 图像/视频质量评价
-
- 常见的图像质量评价指标
-
- PSNR
- SSIM
- 学习感知图像块相似度(Learned Perceptual Image Patch Similarity, LPIPS)
- IQA模型性能评价指标(PLCC、SROCC、KROCC、RMSE)
-
- SROCC斯皮尔曼等级相关系数
- PLCC皮尔逊线性相关系数
- KROCC肯德尔等级相关系数
- RMSE均方根误差
- 算法场景设计题:运动模糊图像清晰度评价指标设计
- 算法场景设计题:有一片天空和湖水,天上有云,湖里有倒影,请问怎么设计一个算法可以去除天空和水里的云
- 模型训练
-
- Batch Norm
-
- Batch Norm 为什么有效?/为什么要做Batch Norm
- Batch Norm 可以防止过拟合吗?
- Batch Norm 训练和测试的区别
- 介绍跨卡同步BN
- 介绍BN及其变体
- 样本不平衡问题
-
- 样本不平衡的根本影响
- 判断解决不均衡的必要性
- 样本不均衡解决方法
-
- 1. 数据层面
- 2. 损失函数层面
- 3. 模型层面
- 4. 决策及评估指标
- 优化器
-
- 随机梯度下降SGD
- AdaGrad(自适应学习率算法)
- RMSProp
- Adam
- 常用激活函数
- Transformer
-
- 除以dk的作用
- 使用多头注意力的意义
- 为什么在进行多头注意力的时候需要对每个head进行降维?
- Transformer的非线性来自于哪里?
- Transformer相比RNN/LSTM有什么优势
- Transformer中为何会有Queries、Keys和Values矩阵,只设置Values矩阵本身来求Attention不是更简单吗
- Self-Attention 的时间复杂度是怎么计算的?
- 为什么FFN有两层,先升维再降维?
- 注意力机制是为了解决什么问题而提出来的?
- Transformer的位置信息和bert位置信息有什么不一样
- 简单介绍一下Transformer的位置编码?有什么意义和优缺点?
- 你还了解哪些关于位置编码的技术,各自的优缺点是什么?
- Encoder端和Decoder端是如何进行交互的?
- Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?
- Transformer的并行化提现在哪个地方?
- Decoder端可以做并行化吗?
- 简单讲一下Transformer中的残差结构以及意义。
- 你对attention机制的理解是什么?attention机制的优势和劣势分别在哪里?
- 卷积神经网络
-
- 怎么使⽤⼩卷积核代替⼤卷积核
- 大卷积核和小卷积核比较
- 小卷积核和大卷积核的应用场景
- 简述分组卷积及其应用场景
- 自监督学习
-
- 自监督和无监督学习的区别
- 什么是对比学习
- 对比学习在解决什么问题?
- 为什么现有的方法解决不了这个问题?
- 常见的对比学习方法(三种对比学习机制的比较)
- 自监督学习的定义
- 自监督学习如何评价性能?
- 自动编码器与自监督学习
- 为什么自监督学习能学到新信息 ?
- 设计一个自监督学习任务还需要考虑什么?
- 自监督学习性能的可能提升角度
- 循环神经网络
-
- Dropout为什么可以缓解过拟合问题?
- RNN与LSTM区别
- GRU网络对LSTM网络的改进
陆续更新。。。
~~~~~~~~~~~~ 机器学习 ~~~~~~~~~~~~
特征工程
为什么需要做特征归一化?
参考链接
_第1张图片](http://img.e-com-net.com/image/info8/b6615693bd25425a9b5a8dd3be446e79.jpg)
多维情况下可以分解成多个维度上分别下降,参数W为向量,但学习率只有1个,即所有参数维度共用同一个学习率(暂不考虑为每个维度都分配单独学习率的算法)。收敛意味着在每个参数维度上都取得极小值,每个参数维度上的偏导数都为0,但是每个参数维度上的下降速度是不同的,为了每个维度上都能收敛,学习率应取所有维度在当前位置合适步长中最小的那个。
常用的归一化方法有哪些?
_第2张图片](http://img.e-com-net.com/image/info8/5262fcb836a54324ae43b5612441738e.jpg)
_第3张图片](http://img.e-com-net.com/image/info8/b7e7871453a14ceba2a276647bf0becd.jpg)
transforms.Normalize()与transforms.ToTensor()(标准化-归一化)
transforms.Normalize()
功能:逐channel的对图像进行标准化(均值变为0,标准差变为1),可以加快模型的收敛
- output = (input – mean) / std
- mean:各通道的均值
- std:各通道的标准差
- inplace:是否原地操作
transforms.ToTensor()
-
transforms.ToTensor()函数的作用是将原始的PILImage格式或者numpy.array格式的数据格式化为可被pytorch快速处理的张量类型。
输入模式为(L、LA、P、I、F、RGB、YCbCr、RGBA、CMYK、1)的PIL Image 或 numpy.ndarray (形状为H x W x C)数据范围是[0, 255] 到一个 Torch.FloatTensor,其形状 (C x H x W) 在 [0.0, 1.0] 范围内。 -
那么归一化后为什么还要接一个Normalize()呢?
Normalize()是对数据按通道进行标准化,即减去均值,再除以方差数据如果分布在(0,1)之间,可能实际的bias,就是神经网络的输入b会比较大,而模型初始化时b=0的,这样会导致神经网络收敛比较慢,经过Normalize后,可以加快模型的收敛速度。
因为对RGB图片而言,数据范围是[0-255]的,需要先经过ToTensor除以255归一化到[0,1]之后,再通过Normalize计算过后,将数据归一化到[-1,1]。 -
那transform.Normalize()是怎么工作的呢?以上面代码为例,ToTensor()能够把灰度范围从0-255变换到0-1之间,而后面的transform.Normalize()则把0-1变换到(-1,1).具体地说,对每个通道而言,Normalize执行以下操作:
image=(image-mean)/std
其中mean和std分别通过(0.5,0.5,0.5)和(0.5,0.5,0.5)进行指定。原来的0-1最小值0则变成(0-0.5)/0.5=-1,而最大值1则变成(1-0.5)/0.5=1.
即:用给定的均值和标准差分别对每个通道的数据进行正则化。具体来说,给定均值(M1,…,Mn),给定标准差(S1,…,Sn),其中n是通道数(一般是3),对每个通道进行如下操作:
output[channel] = (input[channel] - mean[channel]) / std[channel]
为什么要标准化
谈谈DNN中的标准化(Normalization)
主要是因为:深度学习中的 Internal Covariate Shift 问题及其影响。
1.1 独立同分布与白化
机器学习界的炼丹师们最喜欢的数据有什么特点?窃以为,莫过于“独立同分布”了,即independent and identically distributed,简称为 i.i.d. 独立同分布并非所有机器学习模型的必然要求(比如 Naive Bayes 模型就建立在特征彼此独立的基础之上,而Logistic Regression 和 神经网络 则在非独立的特征数据上依然可以训练出很好的模型),但独立同分布的数据可以简化常规机器学习模型的训练、提升机器学习模型的预测能力,已经是一个共识。
因此,在把数据喂给机器学习模型之前,“白化(whitening)”是一个重要的数据预处理步骤。白化一般包含两个目的:
(1)去除特征之间的相关性 —> 独立;
(2)使得所有特征具有相同的均值和方差 —> 同分布。
白化最典型的方法就是PCA,可以参考阅读 PCAWhitening。
1.2 深度学习中的 Internal Covariate Shift
深度神经网络模型的训练为什么会很困难?其中一个重要的原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。为了训好模型,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。
Google 将这一现象总结为 Internal Covariate Shift,简称 ICS. 什么是 ICS 呢?
1.3 ICS 会导致什么问题?
简而言之,每个神经元的输入数据不再是“独立同分布”。
其一,上层参数需要不断适应新的输入数据分布,降低学习速度。
其二,下层输入的变化可能趋向于变大或者变小,导致上层落入饱和区,使得学习过早停止。
其三,每层的更新都会影响到其它层,因此每层的参数更新策略需要尽可能的谨慎。
模型评估
准确率的局限性
_第4张图片](http://img.e-com-net.com/image/info8/3a993b65c4b74546bd036c111fed91f2.jpg)
精确率与召回率的权衡
定义辨析:
实际上非常简单,精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP),也就是
![]()
而召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。
![]()
其实就是分母不同,一个分母是预测为正的样本数,另一个是原来样本中所有的正样本数。
_第5张图片](http://img.e-com-net.com/image/info8/0bd1d25e513c4820b67bbdb469510956.jpg)
举个栗子
假设我们手上有60个正样本,40个负样本,我们要找出所有的正样本,系统查找出50个,其中只有40个是真正的正样本,计算上述各指标。
- TP: 将正类预测为正类数 40
- FN: 将正类预测为负类数 20
- FP: 将负类预测为正类数 10
- TN: 将负类预测为负类数 30
准确率(accuracy) = 预测对的/所有 = (TP+TN)/(TP+FN+FP+TN) = 70%
精确率(precision) = TP/(TP+FP) = 80%
召回率(recall) = TP/(TP+FN) = 2/3
精准率和召回率的关系,F1 分数:
通过上面的公式,我们发现:精准率和召回率的分子是相同,都是 TP,但分母是不同的,一个是(TP+FP),一个是(TP+FN)。两者的关系可以用一个 P-R 图来展示:
_第6张图片](http://img.e-com-net.com/image/info8/ab0e2f4ccda14ed5a90b6641251b5c30.jpg)
如何理解 P-R(查准率-查全率)这条曲线?
有的朋友疑惑:这条曲线是根据什么变化的?为什么是这个形状的曲线? 其实这要从排序型模型说起。拿逻辑回归举例,逻辑回归的输出是一个 0 到 1 之间的概率数字,因此,如果我们想要根据这个概率判断用户好坏的话,我们就必须定义一个阈值 。通常来讲,逻辑回归的概率越大说明越接近 1,也就可以说他是坏用户的可能性更大。比如,我们定义了阈值为 0.5,即概率小于 0.5 的我们都认为是好用户,而大于 0.5 都认为是坏用户。因此,对于阈值为 0.5 的情况下,我们可以得到相应的一对查准率和查全率。
但问题是:这个阈值是我们随便定义的,我们并不知道这个阈值是否符合我们的要求。 因此,为了找到一个最合适的阈值满足我们的要求,我们就必须遍历 0 到 1 之间所有的阈值,而每个阈值下都对应着一对查准率和查全率,从而我们就得到了这条曲线。(原点代表阈值最大时的)
有的朋友又问了:如何找到最好的阈值点呢? 首先,需要说明的是我们对于这两个指标的要求:我们希望查准率和查全率同时都非常高。 但实际上这两个指标是一对矛盾体,无法做到双高。图中明显看到,如果其中一个非常高,另一个肯定会非常低。选取合适的阈值点要根据实际需求,比如我们想要高的查全率,那么我们就会牺牲一些查准率,在保证查全率最高的情况下,查准率也不那么低。
F1 分数:
但通常,如果想要找到二者之间的一个平衡点,我们就需要一个新的指标:F1 分数。
_第7张图片](http://img.e-com-net.com/image/info8/aeac622f637e416fb3018202944672e5.jpg)
AUC和交叉熵在分类上的区别与联系
-
当训练和测试的数据集中的正例比例不同的时候会影响交叉熵的值。如果训练集和测试集的正例比例不同,那么模型越复杂,越接近临界值的样本(越难判断结果的样本)就越容易受到训练集中正例比例的影响而偏离真实分布。
-
有些损失函数基本不受训练集和测试集的正例比例不同的影响,比如AUC。
AUC& ROC
机器学习 | 模型评估: ROC曲线与AUC值
阈值为0.5:
_第8张图片](http://img.e-com-net.com/image/info8/f359c0150035456ba05cc9df9a8feeb0.jpg)
阈值为0-1任意
_第9张图片](http://img.e-com-net.com/image/info8/d6fb4d913d9c4143b2bffe4af999486c.jpg)
_第10张图片](http://img.e-com-net.com/image/info8/072cb2f2904840bb9a5bcf18843813f9.jpg)
_第11张图片](http://img.e-com-net.com/image/info8/132a46c2f72d45189886b46d675de5e4.jpg)
_第12张图片](http://img.e-com-net.com/image/info8/fd01530d0cf4418ba3a7e534c8574fc7.jpg)
FPR越小越好,TPR越大越好
_第13张图片](http://img.e-com-net.com/image/info8/5802592c31a94eafb9bbbb2d3f6295af.jpg)
_第14张图片](http://img.e-com-net.com/image/info8/463b4c02568c460db5cceaf58c9968b2.jpg)
- 宏观:针对每一个类别画出ROC曲线,分别求AUC值,然后对所有AUC值做某种平均,作为整个模型所有类别的宏观AUC值
- 微观:每一层表示每个样本预测成各个类别的概率:
_第15张图片](http://img.e-com-net.com/image/info8/fd8547a36d9043cea8e96400851f79f9.jpg)
ROC 与 PR
类别不平衡问题
这里特指负样本数量远大于正样本时,在这类问题中,我们往往更关注正样本是否被正确分类,即TP的值。PR曲线更适合度量类别不平衡问题中:
- 因为在PR曲线中TPR和FPR的计算都会关注TP,PR曲线对正样本更敏感。
- 而ROC曲线正样本和负样本一视同仁,在类别不平衡时ROC曲线往往会给出一个乐观的结果。
_第16张图片](http://img.e-com-net.com/image/info8/6461dea68a014f848a29068f29242cca.jpg)
如何判断过拟合与欠拟合
训练集和验证集的误差都较高,但相差很少——>欠拟合
训练集误差较低,验证集误差比训练集大较多——>过拟合
判断方法
从训练集中随机选一部分作为一个验证集,采用K折交叉验证的方式,用训练集训练的同时在验证集上测试算法效果。下图的横坐标用拟合函数多项式的阶数笼统地表征模型拟合能力:
_第17张图片](http://img.e-com-net.com/image/info8/d25c07f78fd74b23a4702f0aa63f9ba8.png)
_第18张图片](http://img.e-com-net.com/image/info8/8bb3e40785574b8eac2c1385b883d8d2.jpg)
简单模型(左边)是偏差比较大造成的误差,这种情况叫做欠拟合, 而复杂模型(右边)是方差过大造成的误差,这种情况叫做过拟合。
欠拟合、过拟合及如何防止过拟合
过拟合和欠拟合是用于描述模型在训练过程中的两种状态。一般来说,训练过程会是如下所示的一个曲线图。
_第19张图片](http://img.e-com-net.com/image/info8/c0fb593fb9cc4b108f52373b9c3077ae.jpg)
训练刚开始的时候,模型还在学习过程中,处于欠拟合区域。随着训练的进行,训练误差和测试误差都下降。在到达一个临界点之后,训练集的误差下降,测试集的误差上升了,这个时候就进入了过拟合区域——由于训练出来的网络过度拟合了训练集,对训练集以外的数据却不work。
过拟合和欠拟合产生的原因:
欠拟合(underfitting):
模型复杂度过低
特征量过少
过拟合(overfitting):
数据 模型 正则 集成
过拟合是指训练误差和测试误差之间的差距太大。换句换说,就是模型复杂度高于实际问题,模型在训练集上表现很好,但在测试集上却表现很差。模型对训练集"死记硬背"(记住了不适用于测试集的训练集性质或特点),没有理解数据背后的规律,泛化能力差。
注:对于决策树模型,如果我们对于其生长没有合理的限制,其自由生长有可能使节点只包含单纯的事件数据(event)或非事件数据(no event),使其虽然可以完美匹配(拟合)训练数据,但是无法适应其他数据集
解决方法:
_第20张图片](http://img.e-com-net.com/image/info8/4934563f4ea7498aa4ec24f3e427c9b9.jpg)
减少特征数:
欠拟合需要增加特征数,那么过拟合自然就要减少特征数。去除那些非共性特征,可以提高模型的泛化能力.
_第21张图片](http://img.e-com-net.com/image/info8/9486ddcee25546a6bf849d70d9434aae.jpg)
增加更多的特征,使输入数据具有更强的表达能力。特征挖掘十分重要,尤其是具有强表达能力的特征,往往可以抵过大量的弱表达能力的特征。特征的数量往往并非重点,质量才是,总之强特最重要。能否挖掘出强特,还在于对数据本身以及具体应用场景的深刻理解,往往依赖于经验。
L1和L2正则化为什么可以防止过拟合
L1是通过**稀疏参数(减少参数的数量)来降低复杂度,L2是通过减小参数值的大小(权重衰减)**来降低复杂度。下面我们从梯度角度进行分析。
L1正则化
L1正则化的损失函数为:
_第22张图片](http://img.e-com-net.com/image/info8/6a8ad39fb582443eaf465a60cbf8908c.jpg)
上式可知,**当w大于0时,更新后的参数w变小;当w小于0时,更新后的参数w变大;**所以,L1正则化容易使参数变为0,即特征稀疏化。因此它的效果就是让w往0靠,使网络中的权重尽可能为0,也就相当于减小了网络复杂度,防止过拟合。
L2正则化
L2正则化的损失函数为:
_第23张图片](http://img.e-com-net.com/image/info8/58a182bf6393474ba3994a83b834fd5a.jpg)
由上式可知,正则化的更新参数相比于未含正则项的更新参数多了![]()
项,当w趋向于0时,参数减小的非常缓慢,因此L2正则化使参数减小到很小的范围,但不为0。
一个所谓“显而易见”的解释就是:更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合刚刚好(这个法则也叫做奥卡姆剃刀),而在实际应用中,也验证了这一点,L2正则化的效果往往好于未经正则化的效果。
_第24张图片](http://img.e-com-net.com/image/info8/1165e94b3ed649bfadab8ab2181a28d1.jpg)
实现参数的稀疏有什么好处?
因为**参数的稀疏,在一定程度上实现了特征的选择。**一般而言,大部分特征对模型是没有贡献的。这些没有用的特征虽然可以减少训练集上的误差,但是对测试集的样本,反而会产生干扰。稀疏参数的引入,可以将那些无用的特征的权重置为0.
经典方法
线性回归梯度下降
_第25张图片](http://img.e-com-net.com/image/info8/26650df5552b4f4d88581a11e7abc0f4.jpg)
_第26张图片](http://img.e-com-net.com/image/info8/719549f391a94124b1dabd941a3d2375.jpg)
_第27张图片](http://img.e-com-net.com/image/info8/b00d1865157e47b79bb0054415bad344.jpg)
_第28张图片](http://img.e-com-net.com/image/info8/0ce44c42a38f433b996676cea47bb8c2.jpg)
_第29张图片](http://img.e-com-net.com/image/info8/5d500e1be18c4c14acfc7b7fd1e4b37f.jpg)
逻辑回归梯度下降
_第30张图片](http://img.e-com-net.com/image/info8/852382cfecaf4f72bb73e0a13cea8336.jpg)

_第31张图片](http://img.e-com-net.com/image/info8/2619c83f71bb424da17f44224c762d6e.jpg)
_第32张图片](http://img.e-com-net.com/image/info8/91048ac2d3a047828eac4cecd8d637e4.jpg)
_第33张图片](http://img.e-com-net.com/image/info8/82290f5ea9a34b72911937edd1b9d87c.jpg)
推导逻辑回归的损失函数和梯度计算
推导逻辑回归的损失函数
逻辑回归的损失函数与损失函数的梯度公式推导
_第34张图片](http://img.e-com-net.com/image/info8/d77943686b0247d39d7a0c00e491fec5.jpg)
_第35张图片](http://img.e-com-net.com/image/info8/3e56d53b1bae41499d0ec5ecb6e8b99f.jpg)
它表示将这两个数值向量对应元素相乘然后全部相加起来得到z值,其中向量x是分类器的输入数据,向量w就是我们要找到的能使分类器尽可能准确的最佳参数。
由上述公式就可得:
_第36张图片](http://img.e-com-net.com/image/info8/bd7fd935b7d34ed5afec779d737e7017.jpg)
其中 h w ( x ) h_w(x) hw(x)的作用就是给定输入时,输出分类为正向类(1)的可能性。例如,对于一个给定的x, h w ( x ) h_w(x) hw(x)的值为0.8,则说明有80%的可能输出为正向类(1),有20%的可能输出为负向类(0),二者成补集关系。
对于一个二分类问题而言,我们给定输入,函数最终的输出只能有两类,0或者1,所以我们可以对其分类。
_第37张图片](http://img.e-com-net.com/image/info8/7d003a01a8a8498ebeb1a54a616e87f4.jpg)

为了运算便捷,我们将其整合为一个公式(极大似然估计),如下:
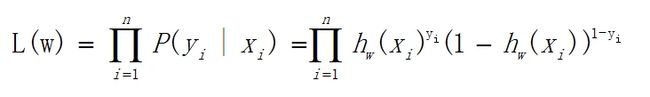
由于乘法计算量过大,所以可以将乘法变加法,对上式求对数,如下:
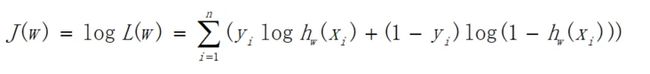
可以看出当y=1时,加号后面式子的值为0;当y=0时,加号前面式子的值为0,这与上文分类式子达到的效果是一样的。L(w)称为似然函数,J(w)称为对数似然函数,是依据最大似然函数推导而成。此时的应用是梯度上升求最大值,如果梯度下降求最小值,可在公式之前乘以-1/n。
_第38张图片](http://img.e-com-net.com/image/info8/7e7c366962f647fd844d116ed91b8dde.jpg)
补充:
_第39张图片](http://img.e-com-net.com/image/info8/05058ba8aa8c41fdac3a27425ed753cf.jpg)
逻辑回归损失函数,并推导梯度下降公式
_第40张图片](http://img.e-com-net.com/image/info8/a56caffb69014f5a9af7b176c5401d76.jpg)
逻辑回归损失函数及梯度推导公式如下:
_第41张图片](http://img.e-com-net.com/image/info8/e3cb66f4cfd740988198d265e29b7d9d.jpg)
求导:
_第42张图片](http://img.e-com-net.com/image/info8/cc91309186f84c378ab9194ebcf98160.jpg)
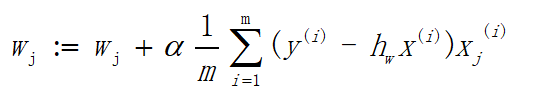
如果利用将对数似然函数换成损失函数J(Theta),则得到的是有关计算梯度下降的公式,如下:
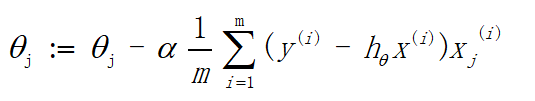
简单概括一下SVM
SVM 是一种二分类模型。它的基本思想是在特征空间中寻找间隔最大的分离超平面使数据得到高效的二分类,具体来讲,有三种情况(不加核函数的话就是个线性模型,加了之后才会升级为一个非线性模型):
- 当训练样本线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机;
- 当训练数据近似线性可分时,引入松弛变量,通过软间隔最大化,学习一个线性分类器,即线性支持向量机;
- 当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
SVM如何处理多分类问题?
一种是直接法,直接在目标函数上修改,将多个分类面的参数求解合并到一个最优化问题里面。看似简单但是计算量却非常的大。
另外一种做法是间接法:对训练器进行组合。其中比较典型的有一对一,和一对多。
- 一对多:每次将一个类型作为正例,其他的作为反例,训练出k个分类器,当有一个新的样本来的时候,用这k个分类器来测试,哪个分类器的概率高,那么这个样本就属于哪一类;
- 一对一:任意两个类训练出一个分类器,如果有k类,一共训练出C ( 2 , k ) 个分类器,这样当有一个新的样本要来的时候,用这$C(2,k) $个分类器来测试,每当被判定属于某一类的时候,该类就加一,最后票数最多的类别被认定为该样本的类。
为什么SVM对缺失数据敏感?
这里说的缺失数据是指缺失某些特征数据,向量数据不完整。1. SVM 没有处理缺失值的策略。2. SVM的效果和支持向量点有关,缺失值可能影响支持向量点的分布。
为何将原始问题转为对偶问题?/ 引入对偶算法的优点?
- 一是对偶问题往往更容易求解。当我们寻找约束存在时的最优点的时候,约束的存在虽然减小了需要搜寻的范围,但是却使问题变得更加复杂。为了使问题变得易于处理,我们的方法是把目标函数和约束全部融入一个新的函数,即拉格朗日函数,再通过这个函数来寻找最优点;
- 二是方便引入核函数,(因为对偶问题涉及的是数据的内积计算)进而推广到非线性分类问题。
_第43张图片](http://img.e-com-net.com/image/info8/1176c6f2b6b847c0807b62e2b8295b5b.jpg)

SVM核函数的选择
_第44张图片](http://img.e-com-net.com/image/info8/2602f973e8f5432f98ae4b6349380177.jpg)
LR逻辑回归和SVM的联系与区别
相同点:
(1) LR和SVM都是监督的分类算法。
(2) 如果不考虑核函数,LR和SVM都是线性分类算法,也就是说他们的分类决策面都是线性的。
(3) LR和SVM都是监督学习算法。
(4) LR和SVM都是判别模型。
判别模型和生成模型是两个相对应的模型。
判别模型是直接生成一个表示或者的判别函数(或预测模型)
生成模型是先计算联合概率分布然后通过贝叶斯公式转化为条件概率。
SVM和LR,KNN,决策树都是判别模型,而朴素贝叶斯,隐马尔可夫模型是生成模型。
区别点:
1、损失函数的不同
LR是cross entropy
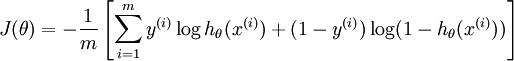
SVM的损失函数是最大化间隔距离
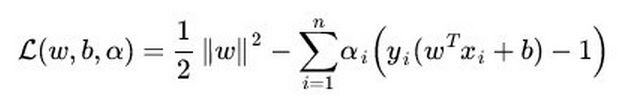
逻辑回归方法基于概率理论,假设样本为1的概率可以用sigmoid函数来表示,然后通过极大似然估计的方法估计出参数的值
支持向量机基于几何间隔最大化原理,认为存在最大几何间隔的分类面为最优分类面
2、SVM不能产生概率,LR可以产生概率
LR本身就是基于概率的,所以它产生的结果代表了分成某一类的概率,而SVM则因为优化的目标不含有概率因素,所以其不能直接产生概率。
3、SVM自带结构风险最小化,LR则是经验风险最小化
在假设空间、损失函数和训练集确定的情况下,经验风险最小化即最小化损失函数
结构最小化是为了防止过拟合,在经验风险的基础上加上表示模型复杂度的正则项

4、SVM会用核函数而LR一般不用核函数
SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算量。 而LR则每个点都需要两两计算核函数,计算量太过庞大
5、LR和SVM在实际应用的区别
根据经验来看,对于小规模数据集,SVM的效果要好于LR,但是大数据中,SVM的计算复杂度受到限制,而LR因为训练简单,可以在线训练,所以经常会被大量采用
6、SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
注意:逻辑回归(Logistic Regression)是统计机器学习中经典的分类方法,这个算法容易让人望文生义地理解为是回归算法,其实叫逻辑回归并不是为了刻意地制造歧义,因为它本质上和线性回归并无差别,只是最后利用了Sigmoid函数作为激活函数,将回归得到的值作为激活函数的输入,最后将输出映射到(0,1)区间上;若是用于二分类(其实逻辑回归也常用于二分类),假如指定阈值为0.5,大于0.5的数据分类为正样本,小于0.5归为负样本,以此达到分类的效果;逻辑回归还有另一个特性,不仅可以得出分类的结果,还可以得到具体的概率值,原因是显然的。
_第45张图片](http://img.e-com-net.com/image/info8/1bde3b3d79354e0cab302e166cbb9a42.jpg)
降维
_第46张图片](http://img.e-com-net.com/image/info8/c5fd9040fcd5422aa68cf2b151002049.jpg)
一个月刷完机器学习笔试题300题(15)
简述主成分分析PCA工作原理
-
PCA旨在找到数据中的主成分,并利用这些主成分表征原始数据,从而达到降维的目的。无监督学习降维法。
-
工作原理可由两个角度解释,第一个是最大化投影方差(所期望的是在投影的维度上,新特征自身的方差尽量大,
方差越大特征越有效,尽量使产生的新特征间的相关性越小);第二个是最小化平方误差(样本点到超平面的垂直距离足够近)。
形象解释:
_第47张图片](http://img.e-com-net.com/image/info8/6681e0d93d124fe4bcaa91a0da46e591.jpg)
- 做法是数据中心化之后,对样本数据协方差矩阵进行特征分解,选取前d个最大的特征值对应的特征向量,即可将数据从原来的p维降到d维,也可根据奇异值分解来求解主成分。
补充:特征分解
特征分解求解PCA步骤:
_第48张图片](http://img.e-com-net.com/image/info8/d5cad149338a4747a1758007d4175530.jpg)
奇异值分解步骤:
_第49张图片](http://img.e-com-net.com/image/info8/0900df5b0cb34a7fb257d2323d0df704.jpg)
PCA的优缺点
优点
(1)仅仅需要以方差衡量信息量,不受数据集以外的因素影响
(2)各主成分之间正交,可消除原始数据成分间的相互影响的因素
(3)计算方法简单,主要运算是特征值分解,易于实现。
缺点
(1)主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强
(2)方差小的非主成分也可能含有对样本差异的重要信息,因此降维丢弃可能对后续数据处理有影响
(3)PCA属于有损压缩
LDA介绍一下
线性判别分析(Linear Discriminant Analysis, LDA)
是一种基于有监督学习的降维方式,
将数据集在低维度的空间进行投影,
要使得投影后的同类别的数据点间的距离尽可能的靠近,
而不同类别间的数据点的距离尽可能的远。
有点像聚类?
LDA的中心思想是:
最大化类间距离
最小化类内距离。
_第50张图片](http://img.e-com-net.com/image/info8/56c106b1291e4248a85165541520d9c3.jpg)
_第51张图片](http://img.e-com-net.com/image/info8/2135c7f760e14573aa730db79914c4fd.jpg)
_第52张图片](http://img.e-com-net.com/image/info8/ad326d2d690d41a799ddf98899c74293.jpg)
PCA和LDA有什么区别
_第53张图片](http://img.e-com-net.com/image/info8/56a383a6f9854f1481dc1c84ee3091fc.jpg)
_第54张图片](http://img.e-com-net.com/image/info8/3dcc4f473ed34596aa67f5a80e1c070b.jpg)
SNE
_第55张图片](http://img.e-com-net.com/image/info8/88f64c772dc640a3adfb48fc9e206507.jpg)
_第56张图片](http://img.e-com-net.com/image/info8/6b4c0525a2d24b2587c164494e5ef037.jpg)
t-SNE
_第57张图片](http://img.e-com-net.com/image/info8/17afdadc4cd64d0190659b1b332e2413.jpg)
_第58张图片](http://img.e-com-net.com/image/info8/1e7fabc0746f4616b36352f50a996174.jpg)
_第59张图片](http://img.e-com-net.com/image/info8/5b7d14ac71b944ba99923d9f67e7fde9.jpg)
_第60张图片](http://img.e-com-net.com/image/info8/296e67c9199c404fabd1a777c6ce9ca9.jpg)
非监督学习
聚类和分类的区别
分类:类别是已知的,通过对已知类别的数据进行训练和学习,找到这些不同类的特征,再对未知类别的数据进行分类。属于监督学习。
聚类:事先不知道数据会分为几类,通过聚类分析将数据聚合成几个群体。聚类不需要对数据进行训练和学习。属于无监督学习。
关于监督学习和无监督学习,这里给一个简单的介绍:一般而言,是否有监督,就看输入数据是否有标签,输入数据有标签,则为有监督学习,否则为无监督学习。
_第61张图片](http://img.e-com-net.com/image/info8/1215a45181da4f8781cacc1e90118459.jpg)
聚类是将数据对象的集合分成相似的对象类的过程。使得同一个簇(或类)中的对象之间具有较高的相似性,而不同簇中的对象具有较高的相异性。如下图所示
_第62张图片](http://img.e-com-net.com/image/info8/56595d03df2840708a80fa40c7c265a7.jpg)
简述K均值算法的具体步骤
_第63张图片](http://img.e-com-net.com/image/info8/787ed28dc5344dc9ae945fe49464460a.jpg)
_第64张图片](http://img.e-com-net.com/image/info8/5459bd33ea02462b9b73da99f1a55c6c.jpg)
时间复杂度/空间复杂度
_第65张图片](http://img.e-com-net.com/image/info8/a7f17ca107a64c108b06235c52599694.png)
K均值算法的优缺点是什么?如何对其进行调优?
_第66张图片](http://img.e-com-net.com/image/info8/4a88a98778d64050b1d6822340fa91da.jpg)
Kmeans数据不平衡问题
-
产生平衡的聚类并不是k-means目标的一部分。事实上,具有平衡集群的解决方案可能是任意糟糕的(只考虑具有重复项的数据集)。K-means最小化平方和,将这些对象放入一个簇中似乎是有益的
-
SMOTE算法是用的比较多的一种上采样算法
_第67张图片](http://img.e-com-net.com/image/info8/6a4d7f95b6b548f2b1abfde4608fff01.jpg)
然而,如图2所示,该算法在处理不平衡和噪声方面存在一些弱点。其中一个缺点源于SMOTE 随机选择少数实例以均匀的概率进行过采样 。虽然这种方法可以有效地打击阶级间的不平衡,但问题是类别内部的不平衡和小的分离被忽略。计算许多少数类样本的输入区域很有可能被进一步夸大,而样本稀少的少数类区域可能保持稀疏[39]。
另一个主要问题是SMOTE可能会进一步放大数据中存在的噪声。当线性插值一个有噪声的少数样本时,可能会发生这种情况,该样本位于多数类实例及其最近的少数邻居之间。该方法容易产生噪声,因为它不能区分重叠的类区域和所谓的安全区域
_第68张图片](http://img.e-com-net.com/image/info8/5b23e369ced64539965eb2f30ba52dd3.jpg)
合理选择K值
_第69张图片](http://img.e-com-net.com/image/info8/1acb1d65a7ac4ba7a48a5ba8e9354965.jpg)
_第70张图片](http://img.e-com-net.com/image/info8/c8430143ac734c278e05ddecc4cf6532.jpg)
初始点怎么选取,为什么敏感?你有什么改进的点?

_第71张图片](http://img.e-com-net.com/image/info8/7cfc2d5a7ae64d57b2fb9ce06b5747ca.jpg)
_第72张图片](http://img.e-com-net.com/image/info8/967193be28a14e7ebeccb1cc14c65db9.jpg)
聚类的评定标准
_第73张图片](http://img.e-com-net.com/image/info8/66058c448d1e4a87b6e3e4da59d77c6d.jpg)
高斯混合模型的核心思想是什么?它是如何迭代计算的?
_第74张图片](http://img.e-com-net.com/image/info8/351f912ea86f4281960c69bf38a989f7.jpg)
_第75张图片](http://img.e-com-net.com/image/info8/e85b041bb1c043f38ca43565e1f4d4a3.jpg)
_第76张图片](http://img.e-com-net.com/image/info8/f01b303a727743d997f34e795b795026.jpg)
_第77张图片](http://img.e-com-net.com/image/info8/2586ad02c25744298eef48b59ed2f768.jpg)
集成学习
_第78张图片](http://img.e-com-net.com/image/info8/87c2e6d48b234ba2900b8322fad8388a.jpg)
集成学习分哪几种?他们有什么异同?
boosting:
_第79张图片](http://img.e-com-net.com/image/info8/ca94a8dac8bb433cb103d379d1a77e8b.jpg)
_第80张图片](http://img.e-com-net.com/image/info8/6897a351dae64f8c84f66436a2e6acd6.jpg)
bagging:
_第81张图片](http://img.e-com-net.com/image/info8/28b7bd630c0e4724a0c9d9c27742018f.jpg)
什么是偏差和方差
_第82张图片](http://img.e-com-net.com/image/info8/75d0de709321461690434668cba28353.jpg)
_第83张图片](http://img.e-com-net.com/image/info8/37560416d0ee4fecbf1d74603c5ec010.jpg)
如何从减小方差和偏差的角度解释Boosting和Bagging的原理?
_第84张图片](http://img.e-com-net.com/image/info8/c964c17bc52b40e5b666e9e3dfb73a67.jpg)
_第85张图片](http://img.e-com-net.com/image/info8/c2a892434bd9435ba6a142c0331f14d9.jpg)
GBDT的基本原理
_第86张图片](http://img.e-com-net.com/image/info8/5ffd667c8f564e23b1a35161df505d86.jpg)
_第87张图片](http://img.e-com-net.com/image/info8/ca4ca8331f4c4c79829450de48f72a68.jpg)
_第88张图片](http://img.e-com-net.com/image/info8/d4a136dd7b0f41e7b8463baf59b7de63.jpg)

_第89张图片](http://img.e-com-net.com/image/info8/4f825faa58ce43d3806055c79b38bad5.jpg)
梯度提升和梯度下降的区别和联系是什么?
_第90张图片](http://img.e-com-net.com/image/info8/8655de8afe0f4de1bbc0aef44b3103af.jpg)
XGBoost和GBDT的不同
机器学习算法中 GBDT 和 XGBOOST 的区别有哪些?
- 基分类器:XGBoost的基分类器不仅支持CART决策树,还支持线性分类器,此时XGBoost相当于带L1和L2正则化项的Logistic回归(分类问题)或者线性回归(回归问题)。
- 导数信息:XGBoost对损失函数做了二阶泰勒展开,GBDT只用了一阶导数信息,并且XGBoost还支持自定义损失函数,只要损失函数一阶、二阶可导。GBDT将目标函数泰勒展开到一阶,而xgboost将目标函数泰勒展开到了二阶。保留了更多有关目标函数的信息,对提升效果有帮助。
- 正则项:XGBoost的目标函数加了正则项, 相当于预剪枝,使得学习出来的模型更加不容易过拟合。
- 列抽样:XGBoost支持列采样,与随机森林类似,用于防止过拟合。
- 缺失值处理:对树中的每个非叶子结点,XGBoost可以自动学习出它的默认分裂方向。如果某个样本该特征值缺失,会将其划入默认分支。(在逻辑实现上,为了保证完备性,会将该特征值missing的样本分别分配到左叶子结点和右叶子结点,两种情形都计算一遍后,选择分裂后增益最大的那个方向(左分支或是右分支),作为预测时特征值缺失样本的默认分支方向。)
- 并行化:注意不是tree维度的并行,而是特征维度的并行。XGBoost预先将每个特征按特征值排好序,存储为块结构,分裂结点时可以采用多线程并行查找每个特征的最佳分割点,极大提升训练速度。// 支持并行化,这是XGBoost的闪光点,虽然树与树之间是串行关系,但是同层级节点可并行。具体的对于某个节点,节点内选择最佳分裂点,候选分裂点计算增益用多线程并行。训练速度快。通俗、有逻辑的写一篇说下Xgboost的原理,供讨论参考
XGBOOST:
决策树的学习过程就是为了找出最优的决策树,然而从函数空间里所有的决策树中找出最优的决策树是NP-C问题,所以常采用启发式(Heuristic)的方法,如CART里面的优化GINI指数、剪枝、控制树的深度。这些启发式方法的背后往往隐含了一个目标函数,这也是大部分人经常忽视掉的。xgboost的目标函数如下:
_第91张图片](http://img.e-com-net.com/image/info8/5f4f0f234a2241508a0a3cc79d944760.jpg)
其中正则项控制着模型的复杂度,包括了叶子节点数目 T和leaf score的L2模的平方:
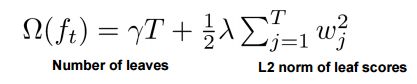
那这个跟剪枝有什么关系呢???
跳过一系列推导,我们直接来看xgboost中树节点分裂时所采用的公式:
_第92张图片](http://img.e-com-net.com/image/info8/1bc35eb1908a48bdbc33f706f2a3ffb5.jpg)
这个公式形式上跟ID3算法(采用entropy计算增益) 、CART算法(采用gini指数计算增益) 是一致的,都是用分裂后的某种值 减去 分裂前的某种值,从而得到增益。为了限制树的生长,我们可以加入阈值,当增益大于阈值时才让节点分裂,上式中的gamma即阈值,它是正则项里叶子节点数T的系数,所以xgboost在优化目标函数的同时相当于做了预剪枝。另外,上式中还有一个系数lambda,是正则项里leaf score的L2模平方的系数,对leaf score做了平滑,也起到了防止过拟合的作用,这个是传统GBDT里不具备的特性。
_第93张图片](http://img.e-com-net.com/image/info8/8bce7fa01b9d4317b30c6491a5596817.jpg)
AdaBoost
和 AdaBoost 一样,Gradient Boosting 也是重复选择一个表现一般的模型并且每次基于先前模型的表现进行调整。不同的是,AdaBoost 是通过提升错分数据点的权重来定位模型的不足而 Gradient Boosting 是通过算梯度(gradient)来定位模型的不足。因此相比 AdaBoost, Gradient Boosting 可以使用更多种类的目标函数。
理解AdaBoost:
_第94张图片](http://img.e-com-net.com/image/info8/1923a6fbfc28495c8750eb40996e5b79.jpg)
_第95张图片](http://img.e-com-net.com/image/info8/eb206d0dd83b4502b67bdb1c02eacc9a.jpg)
不断重复这一过程。
_第96张图片](http://img.e-com-net.com/image/info8/ab3bb0202b7148a19d8d8bccef6fa704.jpg)
_第97张图片](http://img.e-com-net.com/image/info8/fda2c93318314843bcd55eebeb015e0b.jpg)
_第98张图片](http://img.e-com-net.com/image/info8/0b8a825b311e4c9f8615b2df293a075f.jpg)
_第99张图片](http://img.e-com-net.com/image/info8/f991cb1c55a94404be43afb08b807baa.jpg)
前向神经网络
写出多层感知机的平方误差和交叉熵损失函数
_第100张图片](http://img.e-com-net.com/image/info8/4f013b11098c439e9a4336421e9ad4dc.jpg)


平方误差函数和交叉熵损失函数分别适合什么场景?/LR不使用MSE而使用交叉熵损失函数的原因
平方损失函数与交叉熵损失函数都可以用作为机器学习模型的目标函数,但是在何种场景下使用何种损失函数才是较为合理的选择呢?一般来讲,如果学习模型致力于解决的问题是回归问题的连续变量(输出为连续,并且最后一层不含sigmoid/softmax激活函数),那么使用平方损失函数较为合适;若是对于分类问题的离散Ont-Hot向量,那么交叉熵损失函数较为合适。
_第101张图片](http://img.e-com-net.com/image/info8/6bdb8e5e19ca448bba95b41a3ebcdaf2.jpg)
_第102张图片](http://img.e-com-net.com/image/info8/7ed4cbd960ff4672aa756f8c3dc06d71.jpg)
_第103张图片](http://img.e-com-net.com/image/info8/2326758ecf424b04b69b8212283e30cb.jpg)
_第104张图片](http://img.e-com-net.com/image/info8/cfd12ff387bb4fab92a306da5951005e.jpg)
如果是交叉熵,距离target越远,微分值就越大,就可以做到距离target越远,更新参数越快。而平方误差在距离target很远的时候,微分值非常小,会造成移动的速度非常慢,这就是很差的效果了。
参考链接
_第105张图片](http://img.e-com-net.com/image/info8/3ca8228ffd91451e8811428100471410.jpg)
可以看出,使用MSE作为损失函数的话,它的梯度是和sigmod函数的导数有关的,如果当前模型的输出接近0或者1时,img就会非常小,接近0,使得求得的梯度很小,损失函数收敛的很慢。
但是如果使用交叉熵的话就不会,它的导数就是一个差值,误差大的话更新的就快,误差小的话就更新的慢,因此,我们需要用交叉熵而不是MSE作为损失函数。
如果用数学证明很难理解,这里提供一张动图,可以帮助理解交叉熵(Cross Entropy)和方差(Square Error)的区别:绿线为交叉熵的平均loss曲线(凸函数),红线为平均方差loss曲线(非凸函数,有多个局部最优解),分别用来解决一个简单的二分类问题。
_第106张图片](http://img.e-com-net.com/image/info8/06608c6fb7374628a5ee868229214472.jpg)
~~~~~~~~~~~~ 深度学习 ~~~~~~~~~~~~
图像/视频质量评价
_第107张图片](http://img.e-com-net.com/image/info8/24e18ddb85754a109e07940b9397d091.jpg)
常见的图像质量评价指标
方法是先计算出被评价图像的某些统计特性和物理参量,最常用的是图像相似度的测量。图像相似度的测量通常是用处理后的图像与原图像之间的统计误差来衡量处理图像的质量,若误差越小,则从统计意义上来说,被评价图像与原图像的差异越小,图像的相似度就越高,获得的图像质量评价也就越高。
此种评价方法大多适用于黑白图像及灰度图像的质量评价。常用的图像相似度测量参数有平均绝对误差(ME) 、均方误差(MSE)、归一化均方误差(MSE) 、信噪比(SNR)和峰值信噪比(PSMR )等。
PSNR
信噪比SNR:
图像的信噪比应该等于信号与噪声的功率谱之比,但通常功率谱难以计算, 有一种方法可以近似估计图像信噪比,即信号与噪声的方差之比。首先计算图像所有象素的局部方差,将局部方差的最大值认为是信号方差,最小值是噪声方差,求出它们的比值,再转成dB数,最后用经验公式修正。
图像的信噪比的计算公式如下:
_第108张图片](http://img.e-com-net.com/image/info8/6a4f44ba5f8949aa9d5cc7060bb988c9.jpg)

PSNR:
峰值信噪比经常用作图像压缩等领域中信号重建质量的测量方法,它常简单地通过均方差(MSE)进行定义。PSNR (Peak Signal to Noise Ratio):也是讯杂比,只是讯号部分的值通通改用该讯号度量的最大值。以讯号度量范围为0到255当作例子来计算PSNR时,讯号部分均当成是其能够度量的最大值,也就是255,而不是原来的讯号。
注:如果抛开名称上的“峰值”以及百度百科上的定义,我认为这里用最大值可能是为了比较明显的表现出图像处理的结果。
_第109张图片](http://img.e-com-net.com/image/info8/4b0e40c2bb974d7b8be363acccf91a4c.jpg)
_第110张图片](http://img.e-com-net.com/image/info8/b4885ac662ae43ee84c5bb05c7f45709.jpg)
其中,MSE表示当前图像X和参考图像Y的均方误差(MeanSquare Error),X(i,j),Y(i,j)分别代表对应坐标处的像素值,H、W分别为图像的高度和宽度;n为每像素的比特数,一般取8,即像素灰阶数为256. PSNR的单位是dB,数值越大表示失真越小。因为数值越大代表MSE越小。MSE越小代表两张图片越接近,失真就越小。
优缺点:
PSNR是最普遍,最广泛使用的评鉴画质的客观量测法,不过许多实验结果都显示,PSNR的分数无法和人眼看到的视觉品质完全一致,**有可能PSNR较高者看起来反而比PSNR较低者差。**这是因为人眼的视觉对于误差的敏感度并不是绝对的,其感知结果会受到许多因素的影响而产生变化(例如:人眼对空间频率较低的对比差异敏感度较高,人眼对亮度对比差异的敏感度较色度高,人眼对一个区域的感知结果会受到其周围邻近区域的影响)。
PSNR是最普遍和使用最为广泛的一种图像客观评价指标,然而它是基于对应像素点间的误差,即 基于误差敏感的图像质量评价。由于并未考虑到人眼的视觉特性(人眼对空间频率较低的对比差异敏感度较高,人眼对亮度对比差异的敏感度较色度高,人眼对一个 区域的感知结果会受到其周围邻近区域的影响等),因而经常出现评价结果与人的主观感觉不一致的情况。
信噪比和峰值信噪比的关系:
_第111张图片](http://img.e-com-net.com/image/info8/edf26f28e7ae4b0ebb264e8bee336bd4.jpg)
python代码实现PSNR计算:
# PSNR.py
import numpy
import math
def psnr(img1, img2):
mse = numpy.mean( (img1 - img2) ** 2 )
if mse == 0:
return 100
PIXEL_MAX = 255.0
return 20 * math.log10(PIXEL_MAX / math.sqrt(mse))
SSIM
-
SSIM是一种衡量两幅图片相似度的指标。
出处来自于2004年的一篇TIP,标题为:Image Quality Assessment: From Error Visibility to Structural Similarity ,与PSNR一样,SSIM也经常用作图像质量的评价。 -
结构相似性指数(SSIM)度量从一幅图像中提取3个关键特征:亮度 对比度 结构
两幅图像的比较就是根据这3个特征进行的。
结构相似性度量系统的组织和流程如下图所示。X和Y分别为参考图像和样本图像。
_第112张图片](http://img.e-com-net.com/image/info8/673c74f6176f4b90ba64a2e67858c03e.jpg)
_第113张图片](http://img.e-com-net.com/image/info8/20b998d0e7244f4ca8d59ffab9cacc52.jpg)
这个系统计算2幅给定图像之间的结构相似度指数,其值在-1到+1之间。值为+1表示两张给定的图像非常相似或相同,值为-1表示两张给定的图像非常不同。这些**值通常被调整到范围[0,1],**其中极端值具有相同的含义。
亮度:亮度通过对所有像素值进行平均测量。用μ表示,公式如下:
_第114张图片](http://img.e-com-net.com/image/info8/c2b92f170d514f699bcc95eb692700aa.jpg)
式中,xi为图像x的第i个像素值,N为像素值的总数。
对比度:取所有像素值的标准差(方差的平方根)来测量。用σ表示,表示为:
_第115张图片](http://img.e-com-net.com/image/info8/8c2ee314426e41978349406009dd198b.jpg)
其中x和y为两幅图像,μ为图像像素值的平均值。
结构: 结构比较是通过使用一个合并公式来完成的(后面会详细介绍),但在本质上,我们用输入信号的标准差来除以它,因此结果有单位标准差,这可以得到一个更稳健的比较。
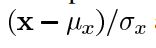
其中x是输入图像。
- 现在我们已经建立了这三个参数背后的数学直觉。我们还没有完成数学运算,还有一点。我们现在缺少的是比较函数,它可以在这些参数上比较两个给定的图像,最后,一个组合函数,将它们组合在一起。在这里,我们定义了比较函数,最后定义了产生相似性指标值的组合函数。
亮度比较函数: 由函数定义,l(x, y),如下图所示。μ表示给定图像的平均值。x和y是被比较的两个图像。
_第116张图片](http://img.e-com-net.com/image/info8/dbdea440d53443fd90d0fe079a2c92fa.jpg)
其中C1为常数,保证分母为0时的稳定性。C1这样给出:
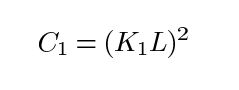
**对比度比较函数:**由函数c(x, y)定义,如下图所示。σ表示给定图像的标准差。x和y是被比较的两个图像。
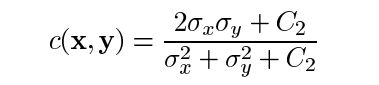
其中C2这样给出:
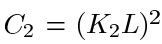
结构比较函数:由函数s(x, y)定义,如下图所示。σ表示给定图像的标准差。x和y是被比较的两个图像。
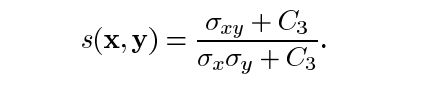
其中σ(xy)定义为:
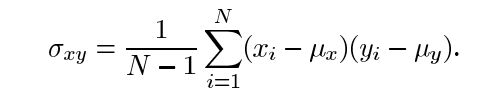
最后,SSIM定义为
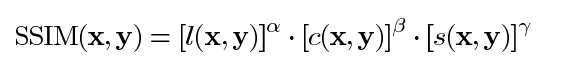
其中 α > 0, β > 0, γ > 0 表示每个度量标准的相对重要性。为了简化表达式,我们设:
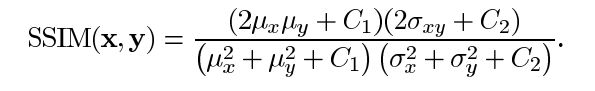
-
结构相似指标可以衡量图片的失真程度,也可以衡量两张图片的相似程度。与MSE和PSNR衡量绝对误差不同,SSIM是感知模型,即更符合人眼的直观感受。
-
SSIM 是一种用来评测图像质量的一种方法。由于人类视觉很容易从图像中抽取出结构信息,因此计算两幅图像结构信息的相似性就可以用来作为一种检测图像质量的好坏.
-
首先结构信息不应该受到照明的影响,因此在计算结构信息时需要去掉亮度信息,即需要减掉图像的均值;其次结构信息不应该受到图像对比度的影响,因此计算结构信息时需要归一化图像的方差;最后我们就可以对图像求取结构信息了,通常我们可以简单地计算一下这两幅处理后的图像的相关系数.
-
然而图像质量的好坏也受到亮度信息和对比度信息的制约,因此在计算图像质量好坏时,在考虑结构信息的同时也需要考虑这两者的影响.
同样MSE下,不同SSIM展现的图片结果:
_第117张图片](http://img.e-com-net.com/image/info8/4a4dacec39664a75830e036f46cada24.jpg)
_第118张图片](http://img.e-com-net.com/image/info8/4fb82688c0684eba891c2b99489e1014.jpg) LPIPS
LPIPS
学习感知图像块相似度(Learned Perceptual Image Patch Similarity, LPIPS)
学习感知图像块相似度(Learned Perceptual Image Patch Similarity, LPIPS)也称为**“感知损失”(perceptual loss),用于度量两张图像之间的差别**。来源于CVPR2018的一篇论文《The Unreasonable Effectiveness of Deep Features as a Perceptual Metric》,该度量标准学习生成图像到Ground Truth的反向映射强制生成器学习从假图像中重构真实图像的反向映射,并优先处理它们之间的感知相似度。LPIPS 比传统方法(比如L2/PSNR, SSIM, FSIM)更符合人类的感知情况。LPIPS的值越低表示两张图像越相似,反之,则差异越大。
_第119张图片](http://img.e-com-net.com/image/info8/3f3f163889db402b85cfdc84e5a020e0.jpg)
IQA模型性能评价指标(PLCC、SROCC、KROCC、RMSE)
评估图像质量评价算法性能的几个常用的标准
图像质量评估不同于传统意义上的图像识别,其本身是一项主观性较强的任务,无法单纯通过评判准确性来衡量算法模型的性能。其性能好坏通常是评估主观评分和算法评分的相关度,如果两者相关度较高,则说明质量评估算法性能较好,反之则较弱。
那么什么是相关呢?简单的说就是当一个或几个相互联系的变量取一定数值时,与之相对应的另一个变量的值虽然不确定,但它仍然按某种规律在一定范围内变化,变量间的这种关系,被称为相关关系。
相关关系可以用相关系数来评价,其绝对值越高表明其越相关,否则反之。相关系数的取值一般在-1到1之间。可以回想一下我们学过的概率论与数理统计中的相关系数,当两个随机变量的相关系数的绝对值为1时,可以将一个随机变量表示为另一个随机变量的一元线性函数,这时变量的相关度最高。例如Y=a*X+b。但是当其相关系数的绝对值小于1时,就不会有这么明确的函数关系。此时的相关度较小。下图是两个变量相关的示例,图中的每一点是变量X,Y的一对取值。可以看出这两个变量近似于线性相关,其相关系数接近于1。
_第120张图片](http://img.e-com-net.com/image/info8/223ef4cb527148d8b736ddaef1014918.jpg)
常用的用于图像质量评估的指标主要有四个:PLCC,SROCC,KROCC 和 RMSE。
SROCC斯皮尔曼等级相关系数
斯皮尔曼等级相关系数( Spearman rank-order correlation coefficient,SROCC) , 也有一部分文献写成SRCC或 “斯皮尔曼秩相关系数” ,用于衡量IQA算法预测的单调性。
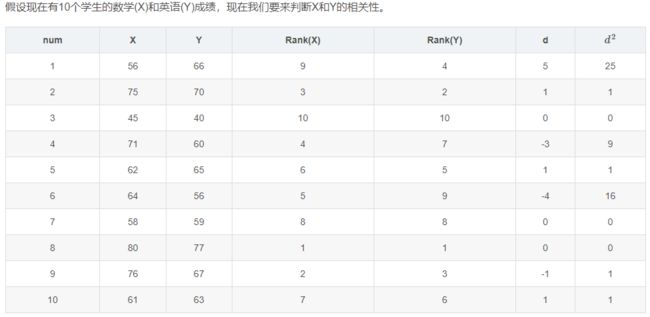
如上表所示,X列表示某个学生的数学成绩,Y列表示其对应的英语成绩。然后分别对数学成绩和英语成绩进行等级划分,分数最高的划分为1,最低的划分为10,其它的以此分别划分为2到9之间的一个整数。划分后如Rank(X)列和Rank(Y)列所示。然后对得到的每一个同学的数学成绩等级减去英语成绩等级得到数据列d,然后对d平方得到d的平方数据列。
在这个过程中如果某几个同学的某一门成绩相同,例如张三和李四的数学成绩都是70,假设它们被划分的等级分别为3和4,反之亦然,则需要先对等级划分进行平均,这里等级平均后是3.5,然后把它们的等级划分都定为3.5。下面我们就可以来计算它们的SROCC了。
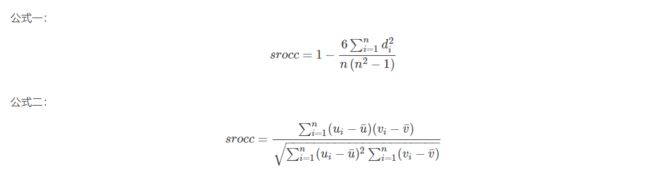
对于以上两个公式,当某个特定的数据集合(如数学成绩)中有相等的值时使用公式二,否则使用公式一。其中n为采集的数据样本中数据对的个数,上例中n为10。其中u¯和v¯分别为某个特定的数据集合在完成等级划分之后的等级平均值,比如上例中数学成绩的等级平均。ui和vi分别对相应数据对的等级划分。
我们从以上例子可以看出srocc主要评价的是两组数据的等级相关性。也就是对于两个变量的一些数据对(如上例所示),数据对的意思是当一个变量取一个值时观察到另一个变量取到的值,当对每个变量的数据进行等级划分后,我们可以得到每个变量的等级序列,如上例中的Rank(X)和Rank(Y),若两个变量的srocc越高则表明它们的等级相关性较高(比如对于上例中任意的i,若Rank(xi)=Rank(yi),则表明它们的等级相关非常高,srocc=1),否则反之。
PLCC皮尔逊线性相关系数
皮尔逊线性相关系数(Pearson linear correlation coefficient,PLCC)用于评估 IQA 模型预测的准确性,也有一些文献写成线性相关系数(Linear correlation coefficient,LCC)。PLCC评价的是主观分值(MOS)与非线性回归后的客观分值的相关性,在计算PLCC前,需对客观分数和主观分数进行非线性回归操作(非线性拟合),建立客观分值与主观分值的非线性映射。
_第121张图片](http://img.e-com-net.com/image/info8/a3cbce9c2c474af298a1eaa0d9d614c9.jpg)
由公式可知,Pearson 相关系数是用协方差除以两个变量的标准差得到的,虽然协方差能反映两个随机变量的相关程度(协方差大于0的时候表示两者正相关,小于0的时候表示两者负相关),但其数值上受量纲的影响很大,不能简单地从协方差的数值大小给出变量相关程度的判断。为了消除这种量纲的影响,于是就有了相关系数的概念。
从功能上来说,其实协方差(Covariance)就足以刻画两个变量的相关关系。解释参见:协方差的意义
但是协方差是带有“单位”的,它和X , Y 的数值有关,假如X 的数值量级整体都远远大于Y ,那么就会使得计算出来的协方差很大,它的值是不可比较的,并不能统一地度量。所以我们需要将其无量纲化(单位化),以消除数值量级差异的影响,于是就引入了皮尔逊相关系数,其在协方差的基础上除以各自的标准差,这样就消除了单位,使得计算出来的值介于-1和1之间,相互之间是可比较的,不用受单位的影响。
KROCC肯德尔等级相关系数
肯德尔等级相关系数(Kendall rank-order correlation coefficient,KROCC),在一些文献中写作 “肯德尔秩相关系数” ,与SROCC一样用来衡量 IQA 模型预测结果的单调性。计算式如式4,其中N 表示样本数量,Nc 是数据集中的一致对的个数(也叫作 “和谐对” ,指变量大小顺序相同的两个样本观测值,即 x 等级高低顺序与 y 等级高低顺序相同,否则称为 “不和谐” 或 “不一致” ),Nd 是数据集中的不一致对个数。两个数据序列中任何一对数据(xi, yi)和 (xj , yj ),当 xi > xj 且 yi > yj 或 xi < xj 且 yi < yj ,则数据对一致(高低顺序一致);当 xi > xj 且 yi < yj 或 xi < xj 且 yi > yj , 则数据对不一致(高低顺序不一致);当 xi = xj 或 yi = yj , 则既不是一致的,也不是不一致的。
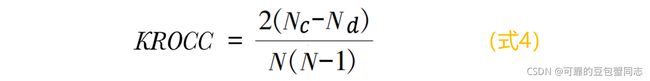
KROCC的数值越大, 说明两个信号数据之间的相关性越好,值越小说明相关性越差。
_第122张图片](http://img.e-com-net.com/image/info8/a3313f6e6faf4dec876c0d87bf5f64e7.jpg)
RMSE均方根误差
均方根误差 (root mean square error,RMSE)用于评估 IQA 模型预测的一致性, 其实他就是MSE(均方误差)的平方根。计算式如式5,si 和 pi 分别表示第 i 幅图像的主观质量分数(MOS值)和客观质量分数(算法预测得分),衡量两组数据之间的绝对误差。
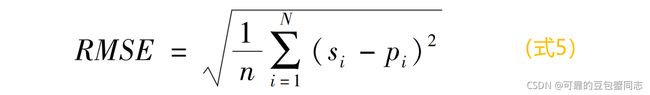
均方根误差越接近于 0,表明算法的性能越好。均方根误差用来比较算法预测得分与人眼主观打分之间的绝对误差,不同类型的质量指标取值范围可能不同,许多算法MOS输出值在 [0, 100] 区间,但也有部分MOS值取 [0, 9] 或其它,所以在计算RMSE前需要先进行归一化。
算法场景设计题:运动模糊图像清晰度评价指标设计
- 灰度差,求梯度
运动模糊图像清晰度评价函数的研究
_第123张图片](http://img.e-com-net.com/image/info8/7399a1433fc848d8909fde40523d865e.jpg)
_第124张图片](http://img.e-com-net.com/image/info8/06daad84c5874afaa25734a6df3d14d7.jpg)
- 梯度结构相似度
无参考图像的清晰度评价方法及实现源码
_第125张图片](http://img.e-com-net.com/image/info8/ecec4c8799d84b22ae5274d04bf69ea8.jpg)
- Reblur 二次模糊
模糊图像检测-无参考图像的清晰度评价
如果一幅图像已经模糊了,那么再对它进行一次模糊处理,高频分量变化不大;但如果原图是清楚的,对它进行一次模糊处理,则高频分量变化会非常大。因此可以通过对待评测图像进行一次高斯模糊处理,得到该图像的退化图像,然后再比较原图像和退化图像相邻像素值的变化情况,根据变化的大小确定清晰度值的高低,计算结果越小表明图像越清晰,反之越模糊。这种思路可称作基于二次模糊的清晰度算法,其算法简化流程如下图:
_第126张图片](http://img.e-com-net.com/image/info8/94bdba2549834e78a2e7fb55fd1d5d6b.jpg)
算法场景设计题:有一片天空和湖水,天上有云,湖里有倒影,请问怎么设计一个算法可以去除天空和水里的云
模型训练
Batch Norm
_第127张图片](http://img.e-com-net.com/image/info8/593ae73b67fe4e3bb1b0933a3a86d8c5.jpg)
再乘上另外一个向量γ ,做 element wise 的相乘。而 γ 和 β 可以想成是 network 的参数,它们是另外再被learn出来的。
为什么要有这一步?如果进行 normalization 以后,均值的平均就一定是 0,这样会给 network 带来一些限制,也许这个限制会带来一些负面的影响,所以我们把 γ 和 β加进去,从而 network 的 hidden layer(隐藏层) 的 output 的平均值不是 0 ,这样network就会learn γ 和 β,来调整输出的分布。
那么为什么要添加γ 和 β?你实际上在训练的时候 γ 和 β 的初始值:
- γ 的初始值都设为1,所以γ一开始其实是一个里面的值都是 1 的向量。
- β的初始值为元素全部都是 0 的向量
所以 network 在一开始训练的时候,每一个 dimension 的分布是比较接近的,也许训练到后面时,已经训练足够长的一段时间,并且已经找到一个比较好的 error surface。训练到一个比较好的误差曲面以后,那再把γ 和 β慢慢地加进去往往对你的训练是有帮助的。
Batch Norm 为什么有效?/为什么要做Batch Norm
- 第一层:特征缩放
在数据预处理阶段,有一种很常见的技术叫做标准化(zero-centered),它对于数据的每一个特征作归一化。优点:1.消除不同特征间量纲和尺度的差异,使得每个特征被同等看待 2. 加快收敛速度 3. 特征取值的“序”不会发生变化,将所有的特征放在一个标准下处理,在距离计算(相似度估计)上存在优势,可能会使其更精确。
我们从特征缩放的角度来理解批标准化,那么就是在模型的每一层做特征缩放,又尽可能的保留了信息,类比标准化的特征更容易被训练,所以添加BN的深度学习模型也就更容易被优化。
这是绝大部分同学理解的BN,但是,如果只是按照这样理解,我们只需要在数据传入的第一层做特征缩放就可以了,为什么需要每一层都需要做呢?
- 第二层:Covariate Shift协变量偏移和Internal Covariate Shift内部协变量偏移
首先来说说“Internal Covariate Shift”。文章的title除了BN这样一个关键词,还有一个便是“ICS”。大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如,transfer learning/domain adaptation等。
(注:
)
的确,对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了covariate shift的定义。由于是对层间信号的分析,也即是“internal”的来由。(训练深度网络的时候经常发生训练困难的问题,因为,每一次参数迭代更新后,上一层网络的输出数据经过这一层网络计算后,数据的分布会发生变化,为下一层网络的学习带来困难(神经网络本来就是要学习数据的分布,要是分布一直在变,学习就很难了)
所以我们在很多层都会做这样的标准化操作,为的就是尽量减弱internal covariate shift的带来的影响(所谓的标准化就是减小分布差异的一种方式)。
注:也有研究认为,BN效果好是因为BN的存在会引入mini-batch内其他样本的信息,就会导致预测一个独立样本时,其他样本信息相当于正则项,使得loss曲面变得更加平滑,更容易找到最优解。相当于一次独立样本预测可以看多个样本,学到的特征泛化性更强,更加general。
- 第三层:避免梯度消失或者梯度爆炸
BN就是通过对每一层的输出规范为均值和方差一致的方法,消除了权重参数放大缩小带来的影响,进而解决梯度消失和爆炸的问题
BN在训练时候,会把每一层的Feature值约束到均值为0,方差为1,这样每一层的数据分布都会一样,在二维等值线上的表现就是圆形,能加快梯度下降法的收敛速度,而且,数据被约束到均值为0 ,方差为1,相当于把数据从饱和区约束到了非饱和区,这样求得的梯度值会更大,加速收敛,也避免了梯度消失和梯度爆炸问题
注:batchnorm降低了数据之间的绝对差异,有一个去相关的性质,更多的考虑相对差异性,因此在分类任务上具有更好的效果。韩国团队在2017NTIRE图像超分辨率中取得了top1的成绩,主要原因竟是去掉了网络中的batchnorm层,由此可见,BN并不是适用于所有任务的,在image-to-image这样的任务中,尤其是超分辨率上,图像的绝对差异显得尤为重要,所以batchnorm的scale并不适合。
Batch Norm 可以防止过拟合吗?
过拟合的原因,就是使用了对问题而言过于复杂的表述,所以缓解过拟合的基本方法就是降低对问题表述的复杂度。
BN的核心思想不是为了防止梯度消失或者防止过拟合,其核心是通过对系统参数搜索空间进行约束来增加系统鲁棒性,这种约束压缩了搜索空间,约束也改善了系统的结构合理性,这会带来一系列的性能改善,比如加速收敛,保证梯度,缓解过拟合等。参考
在训练中,BN的使用使得一个mini-batch中的所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果。就是一个batch数据中每张图片对应的输出都受到一个batch所有数据影响,这样相当于一个间接的数据增强,达到防止过拟合作用.
Batch Norm 训练和测试的区别
每次只输入一张图片,这怎么计算批量的均值和方差,于是,就有了代码中下面两行,在训练的时候实现计算好mean、 var,测试的时候直接拿来用就可以了,不用计算均值和方差。
_第128张图片](http://img.e-com-net.com/image/info8/a92e181443ad4b6d9d4915bf6522e1c8.jpg)
Batch Normalization 在 testing 的时候,你并不需要做什麼特别的处理,PyTorch 帮你处理好了:每一个 batch 计算出来的μ和σ,都会拿出来算 moving average(滑动平均/移动平均)
每一次取一个 batch 的时候,就会算一个 μ1;取第二个 batch 出来的时候,就算个 μ2;一直到取第 t 个 batch 出来的时候,就算一个μt。接下来会算一个 moving average。
介绍跨卡同步BN
SyncBN及其pyTorch实现
参考链接
- BN
_第129张图片](http://img.e-com-net.com/image/info8/792c4b503f674bb893955e28edfa81e5.jpg)
2. 什么是SyncBN?
_第130张图片](http://img.e-com-net.com/image/info8/f8b830070f954d24988c924d7565a6bd.jpg)
- 原理
_第131张图片](http://img.e-com-net.com/image/info8/d26ba8675f044f4fbff3ff39c0b2ce26.jpg)
- SyncBN与DDP的关系
一句话总结,当前PyTorch SyncBN只在DDP单进程单卡模式中支持。SyncBN用到 all_gather这个分布式计算接口,而使用这个接口需要先初始化DDP环境。
- 怎么用SyncBN?
_第132张图片](http://img.e-com-net.com/image/info8/6ec879fb0b264c0f9e9ddf2e438b9b40.jpg)
@classmethod
def convert_sync_batchnorm(cls, module, process_group=None):
r"""Helper function to convert all :attr:`BatchNorm*D` layers in the model to
:class:`torch.nn.SyncBatchNorm` layers.
"""
module_output = module
if isinstance(module, torch.nn.modules.batchnorm._BatchNorm):
module_output = torch.nn.SyncBatchNorm(module.num_features,
module.eps, module.momentum,
module.affine,
module.track_running_stats,
process_group)
if module.affine:
with torch.no_grad():
module_output.weight = module.weight
module_output.bias = module.bias
module_output.running_mean = module.running_mean
module_output.running_var = module.running_var
module_output.num_batches_tracked = module.num_batches_tracked
for name, child in module.named_children():
module_output.add_module(name, cls.convert_sync_batchnorm(child, process_group))
del module
return module_output
介绍BN及其变体
_第133张图片](http://img.e-com-net.com/image/info8/2c71fe6823be4a7ca21c7945f0e5f2b7.jpg)
_第134张图片](http://img.e-com-net.com/image/info8/e78b4df181404a09aed9fa99bcaf545b.jpg)
样本不平衡问题
样本不平衡的根本影响
举个例子,在广告CTR预估场景中,正负样本的占比可以达到1:500,点击的正样本是少数类,没点击的负样本为多数类。如果直接拿这个比例去训练模型的话,很容易学出一个把所有样本都预测为负的模型,因为喂进去学习的样本大多都是负样本。这种情况下,损失会很低,准确率一般都会很高,比如0.98,但是F1会很低,比如0.01。你可以理解为,模型最终学习的并不是如何分辨正负,而是学到了“负远比正的多“这样的先验信息,凭着这个信息模型就会把所有的样本都判定为负。
** 所有,样本不均衡带来的影响就是模型会学习到训练空间中样本比例的差距,或差距悬殊这种先验信息,以致于实际预测时就会对多数类别有侧重。**这样就背离了模型学习去分辨好坏的初衷了。
总结一下也就是,我们通过解决样本不均衡,可以减少模型学习样本比例的先验信息,以获得能学习到辨别好坏本质特征的模型。
判断解决不均衡的必要性
_第135张图片](http://img.e-com-net.com/image/info8/b4d9226e445a45c28400942ec45276d1.jpg)
样本不均衡解决方法
基本上,在学习任务有些难度的前提下,不均衡解决方法可以归结为:通过某种方法使得不同类别的样本对于模型学习中的Loss(或梯度)贡献是比较均衡的。以消除模型对不同类别的偏向性,学习到更为本质的特征。本文从数据样本、模型算法、目标(损失)函数、评估指标等方面,对个中的解决方法进行探讨。(本文以正样本为少数类、负样本为多数类进行阐述。)
1. 数据层面
1.1. 欠采样、过采样
- 如果随机的复制多分正样本进行过采样,那么必然会导致过拟合,因为训练数据中的正样本会反复出现。这种做法不建议。
- 在负样本空间中,随机的不放回的丢掉一些样本。因为欠采样会丢掉信息,所以可以通过Ensemble、Boosting的思想来进行欠采样。
- 在计算性能足够下,可以考虑数据的分布信息(通常是基于距离的邻域关系)的采样方法,如ENN、NearMiss等。
- 不论是过采样还是欠采样,**都会引入噪声,导致过拟合,**可以通过类似Pu-Learning半监督的思路选择增强数据的较优子集,以提高模型的泛化能力。
1.2. 数据增强
数据增强是指从原始数据中加工出更多的数据表示,提高原数据的数量和质量,从而提高模型的学习效果。
基于样本变换的数据增强
-
单样本增强:主要用于图像,比如几何操作、颜色变换、随机查出、剪切旋转等等,可参见imgaug开源库。
_第136张图片](http://img.e-com-net.com/image/info8/85121cfa3ff24422ba745d78e22f5d64.jpg)
-
多样本增强:是指通过组合及转换多个样本的方式,比如刚刚提到的smote,还有SamplePairing、Mixup等方法在特征空间内构造已知样本的邻域值样本。
_第137张图片](http://img.e-com-net.com/image/info8/73abda6904e547778163a7d9ddcd0a11.jpg)
基于深度学习的数据增强
生成模型,如变分自编码网络(VAE)和生成生成对抗网络(GAN),其生成样本的方法也可以用于数据增强,这种基于网络合成的方法相比于传统的数据增强技术虽然过程复杂,但是生成的样本更加多样。
_第138张图片](http://img.e-com-net.com/image/info8/f7f9186e437d4523a312265d19f40286.jpg)
2. 损失函数层面
class weight
class weight可以为不同类别的样本提供不同的权重(少数类有更高的权重),从而模型可以平衡各类别的学习。如下图通过为少数类做更高的权重,以避免决策偏重多数类的现象(类别权重除了设定为balanced,还可以作为一个超参搜索。
Focal loss:
Focal loss的核心思想是在交叉熵损失函数(CE)的基础上增加了类别的不同权重以及困难(高损失)样本的权重(如下公式),以改善模型学习效果。
样本不均衡问题,其中包括两个方面:
- 解决样本的类别不平衡问题
- 解决简单/困难样本不平衡问题
为了解决(1)解决样本的类别不平衡问题和(2)解决简单/困难样本不平衡问题,作者提出一种新的损失函数:focal loss。这个损失函数是在标准交叉熵损失基础上改进得到:
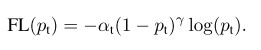
该focal loss函数曲线为:
_第139张图片](http://img.e-com-net.com/image/info8/eb7af470bd2f45d683407cd87157397a.jpg)
其中,(-log(p_t)) 为初始交叉熵损失函数,(\alpha) 为类别间(0-1二分类)的权重参数,((1-p_t)^\gamma) 为简单/困难样本调节因子(modulating factor),而(\gamma) 则聚焦参数(focusing parameter)。
1、形成过程:
(1)初始二分类的交叉熵(Cross Emtropy, CE)函数:
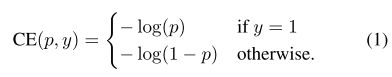
在上面的(y\in {\pm1}) 为指定的ground-truth类别,(p \in [0, 1]) 是模型对带有 (y=1) 标签类别的概率估计。为了方便,我们将(p_t)定义为:
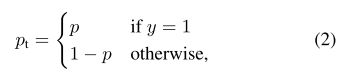
和重写的(CE(p, y)):
![]()
(2)平衡交叉熵(Balanced Cross Entropy):
一个普遍解决类别不平衡的方法是增加权重参数(\alpha \in [0 ,1]),当$ y=1 (类的权重为)\alpha$ ,(y=-1) 类的权重为(1-\alpha) 。在实验中,(\alpha) 被设成逆类别频率(inverse class frequence),(\alpha_t)定义与(p_t)一样:
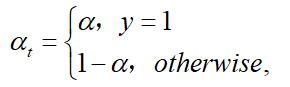
因此,(\alpha-balanced) 的CE损失函数为:
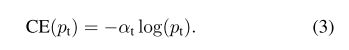
(3)聚焦损失(Focal Loss):
尽管(\alpha)能平衡positive/negative的重要性,但是无法区分简单easy/困难hard样本。为此,对于简单的样本增加一个小的权重(down-weighted),让损失函数聚焦在困难样本的训练。
因此,在交叉熵损失函数增加调节因子((1-p_t)^\gamma) ,和可调节聚参数(\gamma \geq 0)。所以损失函数变成:
![]()
当(p_t\rightarrow0)时,同时调节因子也 ((1-p_t)^\gamma\rightarrow0) ,因此简单样本的权重越小。直观地讲,调节因子减少了简单示例的loss贡献,并扩展了样本接收低loss的范围。 例如,在γ= 2的情况下,与CE相比,分类为pt = 0.9的示例的损失将降低100倍,而对于pt≈0.968的示例,其损失将降低1000倍。 这反过来增加了纠正错误分类示例的重要性(对于pt≤0.5和γ= 2,其损失最多缩小4倍)。
(4)最终的损失函数Focal Loss形式:

根据论文作者实验,(\alpha=0.25) 和 (\gamma=2) 效果最好
实现代码:
def focal_loss(y_true, y_pred):
alpha, gamma = 0.25, 2
y_pred = K.clip(y_pred, 1e-8, 1 - 1e-8)
return - alpha * y_true * K.log(y_pred) * (1 - y_pred)**gamma\
- (1 - alpha) * (1 - y_true) * K.log(1 - y_pred) * y_pred**gamma
3. 模型层面
模型方面主要是选择一些对不均衡比较不敏感的模型,比如,对比逻辑回归模型(lr学习的是全量训练样本的最小损失,自然会比较偏向去减少多数类样本造成的损失),决策树在不平衡数据上面表现相对好一些,树模型是按照增益递归地划分数据(如下图),划分过程考虑的是局部的增益,全局样本是不均衡,局部空间就不一定,所以比较不敏感一些(但还是会有偏向性)。
_第140张图片](http://img.e-com-net.com/image/info8/96281300513542d189d278d4a6bc6bb7.jpg)
解决不均衡问题,更为优秀的是基于采样+集成树模型等方法,可以在类别不均衡数据上表现良好。
_第141张图片](http://img.e-com-net.com/image/info8/06a813d1ec90449a897310584532cf0e.jpg)
_第142张图片](http://img.e-com-net.com/image/info8/bcf077aa9e8b46ef91861c503c49e2e8.jpg)
4. 决策及评估指标
_第143张图片](http://img.e-com-net.com/image/info8/e788aab4e30b46d9a59d52c8d64017ab.jpg)
_第144张图片](http://img.e-com-net.com/image/info8/47470753f599421eb4baad1daff80ced.jpg)
优化器
随机梯度下降SGD
_第145张图片](http://img.e-com-net.com/image/info8/a75fe46d45724ef29d89a4d6d340733a.jpg)
_第146张图片](http://img.e-com-net.com/image/info8/0a303bf936674d9b8fe365a271829a54.jpg)
AdaGrad(自适应学习率算法)
SGD系列的都没有用到二阶动量。二阶动量的出现,才意味着“自适应学习率”优化算法时代的到来。
SGD及其变种以同样的学习率更新每个参数,但深度神经网络往往包含大量的参数,这些参数并不是总会用得到(想想大规模的embedding)。对于经常更新的参数,我们已经积累了大量关于它的知识,不希望被单个样本影响太大,希望学习速率慢一些;对于偶尔更新的参数,我们了解的信息太少,希望能从每个偶然出现的样本身上多学一些,即学习速率大一些。
怎么样去度量历史更新频率呢?
那就是二阶动量——该维度上,记录到目前为止所有梯度值的平方和:

_第147张图片](http://img.e-com-net.com/image/info8/5c0c92d191764c329e5f8e611dedaa78.jpg)
_第148张图片](http://img.e-com-net.com/image/info8/ceef9959d5c94f7aa01a856e9a82e1c3.jpg)
RMSProp
由于AdaGrad单调递减的学习率变化过于激进,考虑一个改变二阶动量计算方法的策略:不累积全部历史梯度,而只关注过去一段时间窗口的下降梯度。这也就是AdaDelta名称中Delta的来历。
补充:
刚才那个版本,就算是同一个参数,它需要的learning rate,也会随著时间而改变, 我们刚才的假设,好像是同一个参数,它的gradient的大小,就会固定是差不多的值,但事实上并不一定是这个样子的
举例来说我们来看,这个新月形的error surface
_第149张图片](http://img.e-com-net.com/image/info8/4e6d807b49774390a09b60c3cb03d31a.jpg)
如果我们考虑横轴的话,考虑左右横的水平线的方向的话,你会发现说,在绿色箭头这个地方坡度比较陡峭,所以我们需要比较小的learning rate,
_第150张图片](http://img.e-com-net.com/image/info8/206794167d3142d18223996e4a452e3e.jpg)
但是走到了中间这一段,到了红色箭头的时候呢,坡度又变得平滑了起来,平滑了起来就需要比较大的learning rate,所以就算是同一个参数同一个方向,我们也期待说,learning rate是可以动态的调整的,于是就有了一个新的招数,这个招数叫做RMS Prop
_第151张图片](http://img.e-com-net.com/image/info8/cd22a050948a4de3ad20477324b0988a.jpg)
Adam
Adam就是RMS Prop加上Momentum
什麼是learning rate的scheduling呢
_第152张图片](http://img.e-com-net.com/image/info8/0ad512ca937743979fb6840752d83cd3.jpg)
我们刚才这边还有一项η,这个η是一个固定的值,learning rate scheduling的意思就是说,我们不要把η当一个常数,我们把它跟时间有关
最常见的策略叫做Learning Rate Decay,也就是说,随著时间的不断地进行,随著参数不断的update,我们这个η让它越来越小
那这个也就合理了,因為一开始我们距离终点很远,随著参数不断update,我们距离终点越来越近,所以我们把learning rate减小,让我们参数的更新踩了一个煞车,让我们参数的更新能够慢慢地慢下来,所以刚才那个状况,如果加上Learning Rate Decay有办法解决
_第153张图片](http://img.e-com-net.com/image/info8/c31798c15b154438a4ae672457a83510.jpg)
刚才那个状况,如果加上Learning Rate Decay的话,我们就可以很平顺的走到终点,因為在这个地方,这个η已经变得非常的小了,虽然说它本来想要左右乱喷,但是因為乘上这个非常小的η,就停下来了 就可以慢慢地走到终点,那除了Learning Rate Decay以外,还有另外一个经典,常用的Learning Rate Scheduling的方式,叫做Warm Up
_第154张图片](http://img.e-com-net.com/image/info8/abf9f8abf29f4eb7a82285262bc2be62.jpg)
Warm Up这个方法,听起来有点匪夷所思,这Warm Up的方法是让learning rate,要先变大后变小,你会问说 变大要变到多大呢,变大速度要多快呢 ,小速度要多快呢,**这个也是hyperparameter,**你要自己用手调的,但是大方向的大策略就是,learning rate要先变大后变小,那这个方法听起来很神奇,就是一个黑科技这样,这个黑科技出现在,很多远古时代的论文裡面
所以这是一个解释,為什麼我们需要warm up的可能性,那如果你想要学更多,有关warm up的东西的话,你其实可以看一篇paper,它是Adam的进阶版叫做RAdam,裡面对warm up这件事情,有更多的理解
torch.optim.Adam算法里面参数的含义
if global_config["optimizer"] == "SGD":
optimizer = torch.optim.SGD(
parameters,
lr=global_config["optimizer_learning_rate"],
momentum=global_config["optimizer_momentum"],
weight_decay=global_config["optimizer_weight_decay"],
)
elif global_config["optimizer"] == "Adam":
optimizer = torch.optim.Adam(parameters,
lr=global_config["optimizer_learning_rate"],
weight_decay=global_config["optimizer_weight_decay"])
optimizer_learning_rate=0.0001,
optimizer_learning_rate_decay_multistep=0.1, # decay rate
optimizer_learning_rate_decay_lambda=0.85, # decay rate
optimizer_weight_decay=0.01, # 0.025
scheduler_type="multistep", # ["multistep", "lambda"]
optimizer_cosine_lr=False,
optimizer_warmup_ratio=0.0, # period of linear increase for lr scheduler
optimizer_decay_at_epochs=[14, 18], # at which epochs to decay lr
optimizer_momentum=0.9,
常用激活函数
神经网络中的常用激活函数总结
Transformer
除以dk的作用
_第155张图片](http://img.e-com-net.com/image/info8/29bb6187038f45598bc8c3fc49a2d32b.jpg)
从图可以看出,自注意力机制的核心过程就是通过Q和K计算得到注意力权重;然后再作用于V得到整个权重和输出。具体的,对于输入Q、K和V来说,其输出向量的计算公式为:
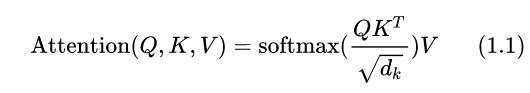
_第156张图片](http://img.e-com-net.com/image/info8/4a2321f52fd046a085ce6c5a1bf8e8e6.jpg)
补充1:
scale dot-product 原因,我们之所以要除以sqrt(dk),为了防止softmax函数的梯度消失。
原因:dk 比较大时 (2 个向量的长度比较长的时候),点积的值会比较大,or 会比较小。
- 当你的值比较大的时候,相对的差距会变大,导致最大值 softmax会更加靠近于1,剩下那些值就会更加靠近于0。值就会更加向两端靠拢,算梯度的时候,梯度比较小。softmax会让大的数据更大,小的更小。
因为 softmax 最后的结果是希望 softmax 的预测值,置信的地方尽量靠近,不置信的地方尽量靠近零,以保证收敛差不多了。这时候梯度就会变得比较小,那就会跑不动。
在 trasformer 里面一般用的 dk 比较大 (本文 512),所以除以 sqrt(dk) 是一个不错的选择。
补充2:
_第157张图片](http://img.e-com-net.com/image/info8/222566ea3b734c5391d6b26c0f3c8357.jpg)
使用多头注意力的意义
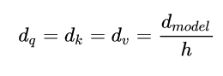
- 类似于CNN多个卷积核,不同注意力学习关注不同的东西。可以类比CNN中同时使用多个滤波器的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息。

_第158张图片](http://img.e-com-net.com/image/info8/7fe235ed9d88406fa0c1c972338c5834.jpg)
_第159张图片](http://img.e-com-net.com/image/info8/c0ad510bae85465086677340bba86681.jpg)

可以看到左边侧重于邻近单词的attention,右边侧重于稍远一点单词的attention。沿用上面英雄的例子的话可以理解成,每个英雄的技能可以分解成8个不同的子技能。
_第160张图片](http://img.e-com-net.com/image/info8/5a5173035bc6476ab224bb99dc9afe43.jpg)
- 计算量和单个head差不多。
为什么在进行多头注意力的时候需要对每个head进行降维?
将原有的高维空间转化为多个低维空间并再最后进行拼接,形成同样维度的输出,借此丰富特性信息,降低了计算量
Transformer的非线性来自于哪里?
_第161张图片](http://img.e-com-net.com/image/info8/2bd8658cd00c4e9ea4cd9197a845bca3.jpg)
FFN的gelu激活函数和self-attention,注意self-attention是非线性的(因为有相乘和softmax)。
Transformer相比RNN/LSTM有什么优势
_第162张图片](http://img.e-com-net.com/image/info8/dc8333a159b84c61a2aaea966365fe1a.jpg)
Transformer中为何会有Queries、Keys和Values矩阵,只设置Values矩阵本身来求Attention不是更简单吗
(1)“只设置Values矩阵本身来求Attention不是更简单吗”,这样的确没啥问题,Non-local中的自注意力实现就是用了两个Value矩阵的点积(准确的说是就是value向量之间的点积),形如
![]()
但是,要知道Transformer为了支持多模态应用,是允许Q、K和V不同源的,尤其是比如Q、K可以是文本特征,而V是图像特征。Transformer更加灵活一些。
(2)这个注意力层有三个输入,分别表示的是key、value、query。这里一根线复制成三根线表示同样一个东西,既作为key,也作为value和query,这个东西叫做自注意力机制,就是说key、value和query其实是一个东西,就是他自己本身 。当然也可以不同,参考
Self-Attention 的时间复杂度是怎么计算的?
_第163张图片](http://img.e-com-net.com/image/info8/74903d2873454c58abcce9f963f185c2.jpg)
_第164张图片](http://img.e-com-net.com/image/info8/615977fa96fd4355a197b042bf6cf3f1.jpg)
为什么FFN有两层,先升维再降维?
Self-Attention模型的作用是提取语义级别的信息(不存在长距离依赖),而FFNN是在各个时序上对特征进行非线性变换,提高网络表达能力。
FFNN有两层,是将attention层输出先扩维4倍再降维。为什么这么做?神经网络中线性连接可以写成![]()
。其中三者维度分别是m×1、m×n、n×1。
- m>n:升维,将特征进行各种类型的特征组合,提高模型分辨能力
- m
所以一般神经网络都是先做宽再做窄。
注意力机制是为了解决什么问题而提出来的?
-
注意力机制(Attention Mechanism)是在计算能力有限的情况下,将计算资源分配给更重要的任务,同时解决信息超载问题的一种资源分配方案
-
在神经网络学习中,一般而言模型的参数越多则模型的表达能力越强,模型所存储的信息量也越大,但这会带来信息过载的问题。那么通过引入注意力机制,在众多的输入信息中聚焦于对当前任务更为关键的信息,降低对其他信息的关注度,甚至过滤掉无关信息,就可以解决信息过载问题,并提高任务处理的效率和准确性。
-
这就**类似于人类的视觉注意力机制,**通过扫描全局图像,获取需要重点关注的目标区域,而后对这一区域投入更多的注意力资源,获取更多与目标有关的细节信息,而忽视其他无关信息。通过这种机制可以利用有限的注意力资源从大量信息中快速筛选出高价值的信息。
Transformer的位置信息和bert位置信息有什么不一样

为什么transformer没用position embedding 而是position encoding:主要是transformer没有bert数据量大 encoding可能效果和embedding差不多
简单介绍一下Transformer的位置编码?有什么意义和优缺点?
因为self-attention是位置无关的,无论句子的顺序是什么样的,通过self-attention计算的token的hidden embedding都是一样的,这显然不符合人类的思维(举例,分类)。因此要有一个办法能够在模型中表达出一个token的位置信息,transformer使用了固定的positional encoding 来表示token在句子中的绝对位置信息。
Transformer 中的 positional embedding
这种sines和cosines的组合为什么能够表示位置/顺序?
假设现在我们想用二进制来表示数字,我们可以观察到不同位置之间的变化率,最后一位在0和1上依次交替,第二低位在每两个数字上交替,以此类推。
_第165张图片](http://img.e-com-net.com/image/info8/481124cd836c4b85a391d169c4b65dad.jpg)
但是用二进制表示数字在浮点数空间非常浪费空间,所以可以用它们的对应浮点函数 - 正弦函数。
下图展示了一个最多50个单词的句子中的每个单词的位置编码,维度是128。每一行都表示一个位置编码向量。对比上面的二进制数字表示,(每一个数字的二进制对应一个位置编码向量):横向看,降低它们的频率,从红色的的位变为橙色的位;纵向来看,左侧上下变化较大,越向右上下变化差越小。所以实际上,正弦函数等效于二进制表示。
_第166张图片](http://img.e-com-net.com/image/info8/8360f18bb447470b8cf96a7d0e843ab5.jpg)
你还了解哪些关于位置编码的技术,各自的优缺点是什么?
Encoder端和Decoder端是如何进行交互的?
Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?
Transformer的并行化提现在哪个地方?
Transformer的并行化主要体现在self-attention模块,在Encoder端Transformer可以并行处理整个序列,并得到整个输入序列经过Encoder端的输出,但是rnn只能从前到后的执行
Decoder端可以做并行化吗?
训练的时候可以,但是交互的时候不可以
简单讲一下Transformer中的残差结构以及意义。
encoder和decoder的self-attention层和ffn层都有残差连接。反向传播的时候不会造成梯度消失。
你对attention机制的理解是什么?attention机制的优势和劣势分别在哪里?
参考
对attention机制的理解
例如人的视觉在处理一张图片时,会通过快速扫描全局图像,获得需要重点关注的目标区域,也就是注意力焦点。然后对这一区域投入更多的注意力资源,以获得更多所需要关注的目标的细节信息,并抑制其它无用信息。
attention机制的优势
其最大的优势就是能一步到位的考虑全局联系和局部联系,且能并行化计算,这在大数据的环境下尤为重要。
相比于传统的 RNN 和 CNN,attention 机制具有如下优点:
-
一步到位的全局联系捕捉,且关注了元素的局部联系;attention 函数在计算 attention value 时,是进行序列的每一个元素和其它元素的对比,在这个过程中每一个元素间的距离都是一;而在时间序列 RNNs 中,元素的值是通过一步步递推得到的长期依赖关系获取的,而越长的序列捕捉长期依赖关系的能力就会越弱。优于RNN实现过程中的一步步递推的长期依赖关系。
-
并行计算减少模型训练时间;Attention 机制每一步的计算都不依赖于上一步的计算结果,因此可以并行处理。
-
相比于 CNN、RNN ,其复杂度更小,参数也更少。所以对算力的要求也就更小。
attention机制的劣势
-
需要额外的位置编码
-
需要的数据量大。因为注意力机制是抓重点信息,忽略不重要的信息,所以数据少的时候,注意力机制效果不如bilstm,现在我们企业都用注意力机制,因为企业数据都是十万百万级的数据量,用注意力机制就很好。还有传统的lstm,bilstm序列短的时候效果也比注意力机制好。所以注意力机制诞生的原因就是面向现在大数据的时代,企业里面动不动就是百万数据,超长序列,用传统的递归神经网络计算费时还不能并行计算,人工智能很多企业比如极视角现在全换注意力机制了
卷积神经网络
怎么使⽤⼩卷积核代替⼤卷积核
_第167张图片](http://img.e-com-net.com/image/info8/6c207c1e557f4195928664f0ce65f21d.jpg)
_第168张图片](http://img.e-com-net.com/image/info8/b79082accc014125aaed814330bce340.jpg)
大卷积核和小卷积核比较
-
首先只有在1*1卷积核之上大小的卷积核才有感受野的作用。
-
卷积核大了感受野大,可以审视更为宽广区域的feature Map,所获得的全局特征越好。虽然很多情况下可以由几个小的卷积核代替(例如一个77的卷积核可以由3个33的卷积核代替),但是虽说网络增加了深度有很多优点,但是也会增加梯度消失的风险。
-
反过来说连续的小卷积核代替大卷积核是现在比较常用的做法,优点很多,比如深度增加带来的非线性激活函数多了,语义表达强了,计算量也会变少,参数量也同样变少,梯度消失的问题因为BN等技术出现得到了很好的优化。另外深度增加语义表达能力增加了,在一些情况下还容易出现过拟合,有时候还不如浅层模型效果好,防止过拟合的方法也出现了很多,也很好解决了这些问题
小卷积核和大卷积核的应用场景
-
对于分割任务而言,上下文信息的利用情况对于分割的效果是有明显影响的。这里我们就具体谈谈这个影响的原因。
-
通常来讲,我们判断一个东西的类别时,除了直接观察其外观,有时候还会辅助其出现的环境。比如汽车通常出现在道路上、船通常在水面、飞机通常在天上等。忽略了这些直接做判断,有时候就会造成歧义。比如下图中,在水面上的船由于其外观,就被FCN算法判断成汽车了。

除此之外,由于金字塔结构并行考虑了多个感受野下的目标特征,从而对于尺寸较大或尺寸过小的目标有更好的识别效果。可见,同时考虑不同感受野下的上下文信息是十分必要的。
另外,参考链接CVPR 2022 | RepLKNet:超大卷积核,大到31x31,越大越暴力,涨点又高效!
-
复兴被“错杀”的设计元素,为大kernel正名。在历史上,AlexNet曾经用过11x11卷积,但在VGG出现后,大kernel逐渐被淘汰了,这标志着从浅而kernel大到深而kernel小的模型设计范式的转变。这一转变的原因包括大家发现大kernel的效率差(卷积的参数量和计算量与kernel size的平方成正比)、加大kernel size反而精度变差等。但是时代变了,在历史上不work的大kernel,在现代技术的加持下能不能work呢?
-
克服传统的深层小kernel的CNN的固有缺陷。我们曾经相信大kernel可以用若干小kernel来替换,比如一个7x7可以换成三个3x3,这样速度更快(3x3x3< 1x7x7),效果更好(更深,非线性更多)。有的同学会想到,虽然深层小kernel的堆叠容易产生优化问题,但这个问题已经被ResNet解决了(ResNet-152有50层3x3卷积),那么这种做法还有什么缺陷呢?——ResNet解决这个问题的代价是,模型即便理论上的最大感受野很大,实质上的有效深度其实并不深(参考文献2),所以有效感受野并不大。这也可能是传统CNN虽然在ImageNet上跟Transformer差不多,但在下游任务上普遍不如Transformer的原因。也就是说,ResNet实质上帮助我们回避了“深层模型难以优化”的问题,而并没有真正解决它。既然深而kernel小的模型有这样的本质问题,浅而kernel大的设计范式效果会如何呢?
-
理解Transformer之所以work的原因。已知Transformer性能拔群,特别是在检测、分割等下游任务上。Transformer的基本组件是self-attention,而self-attention的实质是在全局尺度或较大的窗口内进行Query-Key-Value运算。那么Transformer性能强悍的原因是什么,是Query-Key-Value的设计形式吗?我们猜测,会不会“全局尺度或较大的窗口”才是关键?对应到CNN中,这就需要用超大卷积核来验证。
简述分组卷积及其应用场景
_第169张图片](http://img.e-com-net.com/image/info8/9e96b337cfa64512b905766d8e7d9500.jpg)
自监督学习
自监督和无监督学习的区别
什么是对比学习
Metrics learning + self-supervised learning
对比学习 = 度量学习 + 自监督学习
_第170张图片](http://img.e-com-net.com/image/info8/e8fd80e215004926a7e1476b6cc57a00.png)
首先对比学习通常是在自监督的设定下进行表征学习,也就是不依赖标注数据获得一个编码器(Encoder),大致的环节如下:
1 通过一些方式构造人工正样本对(通过对一张图片进行两次不同的数据增强来构造正样本对)
2 在一个Batch内构造负样本对
3 设计一个loss,拉近正样本对表征(Embedding)间的距离,扩大负样本对表征间的距离
对比学习在解决什么问题?
关键词: 泛化能力强的表征 数据稀疏
-
如何学习泛化能力足够强大的 representation
有监督学习的缺点:泛化能力、过拟合
-
解决数据稀疏的问题
如何更好的利用没有label的数据
未打标的数据远远多于打标的数据,不用简直太浪费了,但是要打标又是一个耗时耗力耗钱的事儿
为什么现有的方法解决不了这个问题?
-
有监督学习天然所带来的问题:泛化能力、过拟合、对抗攻击等等
-
有监督学习本身就无法使用无标签的数据
常见的对比学习方法(三种对比学习机制的比较)
无监督学习训练编码器执行字典查询的任务,可以归纳成三种架构:
-
memory bank(关注字典的大小,而牺牲一些一致性)
memory bank把整个数据集的特征都存到了一起,这样的话每次模型训练的时候,只需要从memory bank中随机抽样很多的key出来当作字典就可以了。但是memory bank的做法在特征一致性上就处理的不是很好,因为每次只能更新一个batchsize那么多的key,这里也就有一个问题:因为这里的特征都是在不同时刻的编码器得到的,而且这些编码器都是通过梯度回传来进行快速更新的,这也就意味着这里得到的特征都缺乏一致性。 -
端到端
q和k的编码器都是可以通过梯度回传来更新模型参数的,特征也高度一致了,但是它的局限性就在于字典的大小,因为在端到端的学习框架中,字典的大小和mini-batch size的大小是等价的。 -
使用动量的思想去更新编码器
队列的形式当然可以使这个字典变得更大,但是也因为使用了非常大的字典,也就是非常长的队列,就导致没办法给队列中所有的元素进行梯度回传了,也就是说,key的编码器无法通过反向传播的方式去更新它的参数
提出了动量更新的方式来解决这个问题,query编码器,是通过梯度反向回传来更新它的模型参数的;θk除了刚开始是用θq初始化以外,后面的更新大部分主要是靠自己,一小部分通过query编码器的参数,θk的更新就非常缓慢了,可以保证这个队列里所有的key是相对一致的。
1. memory bank
2018CVPR提出了个体判别任务以及memory bank
个体判别任务:
本文的方法是受到有监督学习结果的启发,如果将一张豹子的图片喂给一个已经用有监督学习方式训练好的分类器,会发现他给出来的分类结果排名前几的全都是跟豹子相关的,有猎豹、雪豹,总之从图片来看这些物体都是长非常相近的;而排名靠后的那些判断往往是跟豹子一点关系都没有的类别(比如汽车)
可以吧个体判别任务看成一个字典查询的问题
memory bank
根据个体判别这个任务,正样本就是这个图片本身(可能经过一些数据增强),负样本就是数据集里所有其它的图片
做对比学习,大量的负样本特征到底应该存在哪呢?本文用了 memory bank 的形式:就是说把所有图片的特征全都存到memory bank 里,也就是一个字典(ImageNet数据集有128万的图片,也就是说memory bank里要存128万行,也就意味着每个特征的维度不能太高,否则存储代价太大了,本文用的是128维)
2. 端到端
我们的数据来源可以分为三个部分:全参考数据集(自身带有失真类型和失真程度信息),无参考的图像质量和美学数据集,从优酷视频抽帧出来的数据集。
3. 动量
自监督学习的定义
- 自监督学习属于无监督学习,模型直接从无标签数据中自行学习一个特征提取器,无需标注数据;
- 自监督学习与传统的无监督学习的不同点是:它利用无标签数据本身,构造一个辅助的任务,针对这个辅助任务,可以从数据本身中得到标签。然后有监督的训练网络。
- 自监督学习的目的就是利用无标签数据训练出来一个feature提取器(一个CNN网络)从而能够对下游任务的训练有所帮助。
总的来说就是:
自监督学习主要是利用辅助任务(pretext)从大规模的无标签数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。
半监督与自监督
1、半监督学习(Semi-supervised Learning):是指从大量的未标记数据以及部分标记数据中学习预测模型的机器学习方法。例如:用有标签的数据训练一个分类器,然后用这个分类器对无标签数据进行分类,这样就会产生伪标签或软标签,挑选你认为分类正确的无标签样本用来训练分类器。半监督学习方法:简单自训练等
2、自监督学习(Self-supervised Learning):是指直接从大规模的无监督数据中挖掘自身监督信息来进行监督学习和训练的一种机器学习方法(可以看成是无监督学习的一种特殊情况),自监督学习需要标签,不过这个标签不来自于人工标注,而是来自于数据本身。
自监督学习如何评价性能?
自监督学习性能的高低,主要通过模型学出来的feature的质量来评价。feature质量的高低,主要是通过迁移学习的方式,把feature用到其它下游视觉任务中(分类、分割、物体检测…),然后通过视觉任务的结果的好坏来评价。目前没有统一的、标准的评价方式。
自动编码器与自监督学习
- 无监督学习中被广泛采用的方式是自动编码器(autoencoder)。编码器将输入的样本映射到隐层向量,解码器将这个隐层向量映射回样本空间。我们期待网络的输入和输出可以保持一致(理想情况,无损重构),同时隐层向量的维度大大小于输入样本的维度,以此达到了降维的目的,利用学习到的隐层向量再进行聚类等任务时将更加的简单高效。对于如何学习隐层向量的研究,可以称之为表征学习(Representation Learning)。
- 但这种简单的编码-解码结构仍然存在很多问题,基于像素的重构损失通常假设每个像素之间都是独立的,从而降低了它们对相关性或复杂结构进行建模的能力。尤其使用 L1 或 L2 损失来衡量输入和输出之间的差距其实是不存在语义信息的,而过分的关注像素级别的细节而忽略了更为重要的语义特征。对于自编码器,可能仅仅是做了维度的降低而已,我们希望学习的目的不仅仅是维度更低,还可以包含更多的语义特征,让模型懂的输入究竟是什么,从而帮助下游任务。而自监督学习最主要的目的就是学习到更丰富的语义表征。
为什么自监督学习能学到新信息 ?
1. 利用了自然界存在的先验信息。
物体的类别和颜色之间存在关联;物体类别和形状纹理之间的关联;物体默认朝向和类别之间的关联;运动学属性;
_第171张图片](http://img.e-com-net.com/image/info8/db957bc6a5194d339cbbb7076f023ddd.jpg)
2. 连贯性
图像具有空间连贯性;视频具有时间连贯性;
_第172张图片](http://img.e-com-net.com/image/info8/75c4045e5b24446bb3401bff28ae221a.jpg)
图五,利用数据空间、时间连贯性的自监督任务
3. 数据内部结构
目前很火的基于contrastive learning的方法,包括NPID, MoCo, SimCLR等,我们可以将它们统一为instance discrimination [6]任务。如下图,这类任务通常对图片做各种变换,然后优化目标是同一张图片的不同变换在特征空间中尽量接近,不同图片在特征空间中尽量远离。
_第173张图片](http://img.e-com-net.com/image/info8/adc87b9430df49379ab781fa9ea1d41a.jpg)
最终优化发现,同一类别的图片(例如马)居然聚合在一起了;但是我们并没有给它类别标签;
_第174张图片](http://img.e-com-net.com/image/info8/c16bb202ee254b79abdd06c2539da996.jpg)
也就是说,虽然我们在解决instance discrimination的过程中并没有用的物体的类别标签,但是在优化后的特征空间中,同类的物体还是相对能够靠拢。这就证明了,数据之间是具有结构性和关联性的。
设计一个自监督学习任务还需要考虑什么?
- 捷径(shortcuts)
以 jigsaw puzzles 为例,如下图,如果我们让划分的 patch 之间紧密挨着,那么神经网络只需要判断 patch 的边缘是否具有连续性,就可以判断 patch 的相对位置,而不需要学到高级的物体语义信息。这就是一种捷径,我们在设计任务的过程中需要避免这样的捷径。
_第175张图片](http://img.e-com-net.com/image/info8/26224a85c28a4ad2a9de0b29e50cf353.jpg)
图8,解决jigsaw puzzles时,patch之间不能紧密挨着
对于这种捷径,处理的方式也很简单,我们只需要让patch之间产生一些随机的间隔就行,如下图。
_第176张图片](http://img.e-com-net.com/image/info8/30580c5a286247c9b10eeac37eb0a58b.jpg)
图9,让patch之间产生随机间隔
Solving jigsaw puzzles的其他捷径还包括色差、彗差、畸变、暗角等可以指示patch在图像中的相对位置的信息。解决方案除了想办法消除这些畸变外,还可以让patch尽量靠近图像中心。
_第177张图片](http://img.e-com-net.com/image/info8/3ab02511ab5b45df9873b5512c2f40d1.jpg)
图10,色差、彗差、畸变、暗角等可利用的捷径
- 歧义性(Ambiguity)
大多数利用先验来设计的自监督任务都会面临歧义性问题。
例如 colorization 中,一种物体的颜色可能是多种多样的,那么从灰度图恢复颜色这个过程就具有 ambiguity ;再例如在 rotation prediction 中,有的物体并没有一个通常的朝向(例如俯拍放在桌上的圆盘子)。
有不少已有工作在专门解决特定任务的歧义性问题,例如 CVPR 2019 的 Self-Supervised Representation Learning by Rotation Feature Decoupling。
另外就是设计低熵的先验,因为低熵的先验也具有较低的歧义性。
- 任务难度
_第178张图片](http://img.e-com-net.com/image/info8/c8d32c41480c47d996cdd50c3a740e43.jpg)
图11,solving jigsaw puzzles中的不同难度
神经网络就像一个小孩,如果给他太简单的任务,他学不到有用的知识,如果给他太难的任务,他可能直接就放弃了。设计合理的难度也是一个需要考虑的方面。
自监督学习性能的可能提升角度
- 扩展数据集。主要研究的问题是:训练自监督学习模型的数据集的大小,跟性能是否有某种关系?能否通过增大数据集来提升性能?
- 扩展模型复杂度。自监督学习,本质上是要训练出来一个feature提取器(一个CNN网络)。这个CNN网络的复杂度,跟性能是否有某种关系?能否通过增大网络复杂度来提升性能?(比如ResNet50比AlexNet复杂,用ResNet50,效果比AlexNet好吗?)
- 扩展辅助任务的难度。自监督学习的核心,是用一个辅助任务(pretext task)来自动为数据生成标签。这个辅助任务的难度,跟性能是否有某种关系?能否通过增大辅助任务的难度来提升性能?(比如拼图这个辅助任务,把图片分割成2x2个patch,还是4x4个patch?4x4个patch的难度更大)
循环神经网络
Dropout为什么可以缓解过拟合问题?
1.相当于bagging 2. 对每层中的每个元素进行扰动,相当于无偏差的加入噪声,和数据噪声类似,是一种正则化方法。
_第179张图片](http://img.e-com-net.com/image/info8/6a6aeced3716412ab8ddbf9734de3b9c.jpg)
RNN与LSTM区别
_第180张图片](http://img.e-com-net.com/image/info8/4d9a592bd1914db9a0c1a9a7236fc4a8.jpg)
RNN与LSTM区别
- LSTM通过输入门、遗忘门、输出门引入sigmoid函数并结合tanh函数,添加求和操作,减少梯度消失和梯度爆炸的可能性。
- RNN只能够处理短期依赖问题;LSTM既能够处理短期依赖问题,又能够处理长期依赖问题。**RNN没有细胞状态;LSTM通过细胞状态记忆信息。**之前重要的信息也能够保存下来。
GRU网络对LSTM网络的改进
GRU网络对LSTM网络的改进有两个方面:
1、将遗忘门和输入门合并为一个门:更新门,此外另一门叫做重置门。
2、不引入额外的内部状态c,直接在当前状态ht和历史状态ht-1之间引入线性依赖关系。
LSTM:
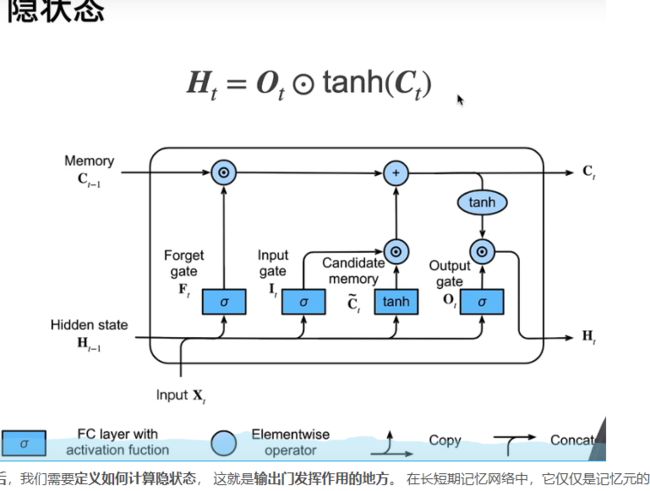
GRU:
_第181张图片](http://img.e-com-net.com/image/info8/7ebc22e737c9490fa564f341a5bbaffa.jpg)