Catlike Coding Unity教程系列 中文翻译 Basics篇(四)Measuring Performance
测试性能
毫秒和每秒显示的帧数
原文地址:https://catlikecoding.com/unity/tutorials/basics/measuring-performance/
使用游戏窗口统计,帧调试器和分析器。
比较动态批处理、GPU实例化和SRP批处理。
显示帧速率计数器。
自动循环遍历函数。
函数之间的平滑过渡。
这是关于学习使用Unity的basics系列的第四个教程。这是对测试性能的介绍。我们还将向函数库添加变形函数的功能。
本教程使用Unity 2020.3.6f1制作。

1. 分析Unity
Unity不断渲染新的帧。为了让任何移动的东西看起来流畅,它必须做到足够快,这样我们才能将图像序列感知为连续的运动。通常情况下,30帧每秒(FPS)是最低目标,而60帧每秒则是理想的。这些数字经常出现是因为许多设备的显示刷新率为60赫兹。如果不关闭垂直同步,就无法以更快的速度绘制帧,这会导致图像撕裂。如果不能达到一致的60FPS,那么下一个最佳的速率是30FPS,即每两次画面显示就刷新一次。再低一点便是15FPS,这对于流畅的运动来说是不够的。
其他常见的显示器刷新率是多少? 75Hz、85Hz和144Hz在桌面显示器中也很常见。竞争游戏场景的刷新率甚至更高。所以如果你的应用能够稳定地达到85FPS,
那么它便能够在所有显示器上很好地进行垂直同步。如果它只能达到60FPS,那么75Hz的显示器刷新率会降至一半的到37.5FPS,85Hz将减半至42.5FPS, 144Hz的降至三分之一到48FPS。但这是假设性能不变的。实际上,帧率可能在刷新率的倍数之间波动。
是否能达到目标帧速率取决于处理单个帧所花费的时间。为了达到60FPS,我们必须在16.67毫秒内更新和渲染每帧。30FPS的时间预算是它的两倍,也就是33.33毫秒/帧。
当我们的图形运行时,我们可以通过简单的观察得到它的运动是平滑程度,但这是一个非常不精确的方法来衡量它的性能。如果运动看起来很流畅,那么它可能超过30FPS,如果它看起来很不流畅,那么它可能少于30FPS。由于不稳定的表现,它也可能一会儿平稳,一会儿就断断续续了。这可能是我们的应用程序的变化,但也可能是在同一设备上运行的其他应用程序导致的。Unity编辑器也可能有不一致的性能,这取决于它所做的事情。如果我们勉强达到60FPS,那么我们可能会在30FPS和60FPS之间快速来回切换,尽管平均FPS较高,但这会让人感到不舒服。因此,为了更好地了解发生了什么,我们必须更精确地测量表现性能。Unity有一些工具可以帮助我们做到这一点。
1.1 游戏窗口的统计数据
游戏窗口有一个Statistics叠加面板,可以通过Stats工具栏按钮激活。它显示最后渲染帧的测量值。它不能告诉我们太多,但它是我们可以用来了解发生了什么的最简单的工具。而在编辑模式下,游戏窗口通常只会偶尔更新。在播放模式下,它会刷新每一帧。
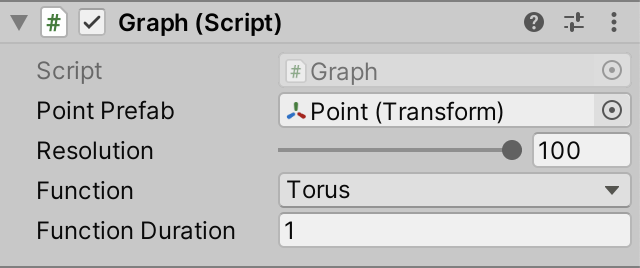
下面的统计数据是关于我们使用torus函数和分辨率为100的图形,使用默认内置渲染管道,从现在开始我将称其为BRP。我在游戏窗口打开垂直同步,所以刷新率与60赫兹显示同步。
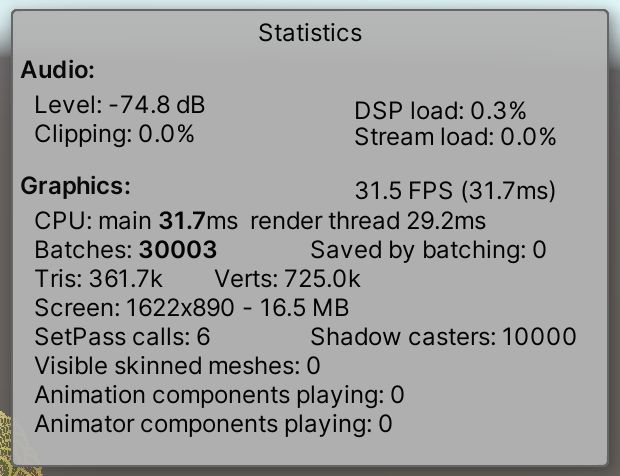
统计数据显示,在这一帧中,CPU主线程花费了31.7ms,渲染线程花费了29.2ms。你可能会得到不同的结果,这取决于你的硬件和游戏窗口屏幕大小。在我的例子中,它显示整个帧需要60.9ms来渲染,但统计面板显示31.5FPS,与CPU时间相匹配。FPS指示器似乎花费了最糟糕的时间,并且假设它与帧速率匹配。这是一种过度简化,只考虑了CPU方面,而忽略了GPU和显示。实际的帧率可能更低。
什么是线程? 在Unity应用程序中,线程是一个子进程。可以有多个线程同时并行运行。统计数据显示了Unity的主线程和渲染线程在最后一帧中运行了多长时间。
除了运行时间和FPS,统计面板还显示了渲染的各种细节。总共有30,003批次,显然通过分批处理没有节省任何批次。这些是发送给GPU的绘制命令。我们的图包含了10,000个点,所以每个点都被渲染了三次。一次用于深度测试,一次用于阴影投射(也分别列出),还有一次用于渲染最终的立方体。其他三个批处理用于额外的工作,如天空框和阴影处理,它们独立于我们的图。还有6个set-pass calls,这可以被认为是GPU重新配置以不同的方式渲染,比如使用不同的材料。
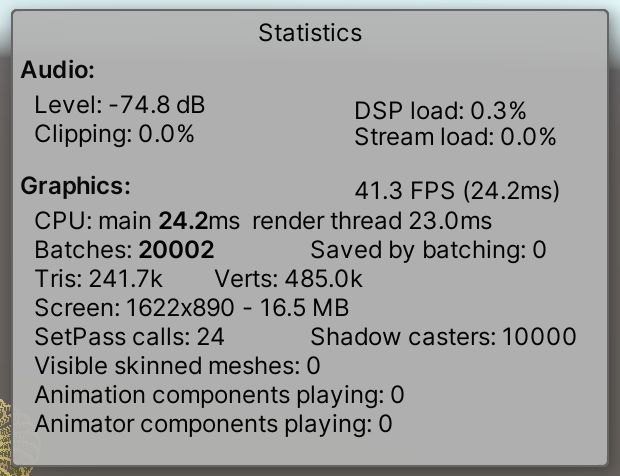
如果我们使用URP代替,统计数据是不同的。它渲染得更快。原因很简单:只有20,002批次,比BRP少10,001批次。这是因为URP不使用单独的深度测试来进行定向阴影。它确实有更多的set-pass调用,但这似乎不是问题。
虽然通过批处理保存的报告没有批处理,URP默认使用SRP批处理,但统计面板不理解它。SRP批处理程序不会消除单独的绘制命令,但可以使它们更有效。为了说明这一点,选择我们的URP资产,并在其检查器底部的Advanced部分下禁用SRP Batcher。确保Dynamic Batching也被禁用。
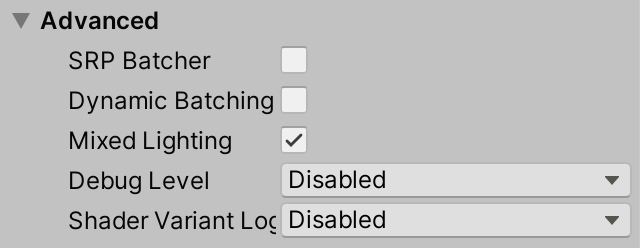
禁用SRP批处理程序后,URP性能更差。

1.2 动态批处理
除了SRP批处理器,URP还有另一个用于动态批处理的开关。这是一个老的技术,动态地将小的网格组合成一个大的网格,然后进行渲染。为URP启用它可以将批次减少到10,024,统计面板表明取消了9,978次绘制。
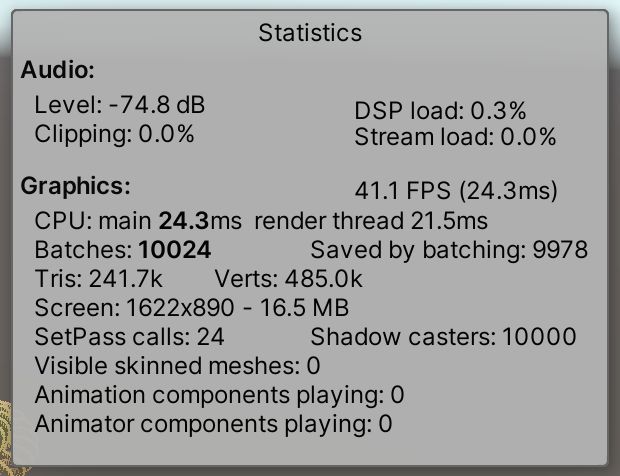
在我的例子中,SRP批处理器和动态批处理具有相当的性能,因为我们的图中点的立方体网格是动态批处理的理想候选。
SRP批次不适用于BRP,但我们可以为其启用动态批处理。在这种情况下,我们可以在Player项目设置的Other Settings部分找到切换,在我们将颜色空间设置为线性的地方的下面一点。只有在没有使用可脚本化的渲染管道设置时才可见。
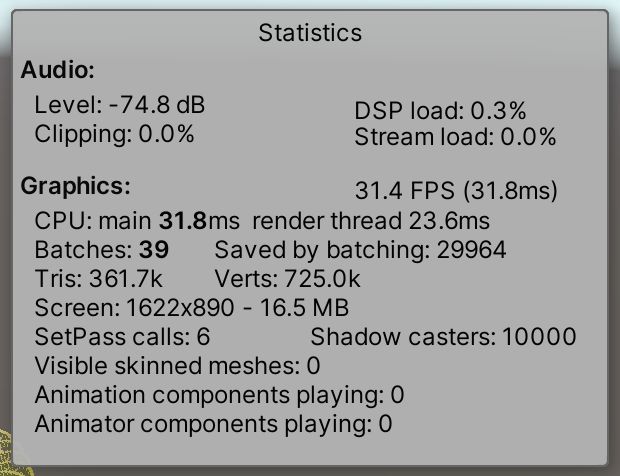
动态批处理对BRP更有效,消除29,964个批次,将其减少到只有39个,但它似乎没有多大帮助。
1.3 GPU实例化
另一种提高渲染性能的方法是启用GPU实例化。这使得使用一个绘制命令告诉GPU用相同材质绘制一个网格的多个实例成为可能,提供一个转换矩阵阵列和其他可选的实例数据。在这种情况下,我们必须启用每个材料。我们有一个Enable GPU Instancing开关。

URP更喜欢SRP批处理程序而不是GPU实例化,所以为了使它在我们的点上工作,SRP批处理程序必须被禁用。然后我们可以看到,批处理的数量减少到只有46个,比动态批处理好得多。稍后我们将发现造成这种差异的原因。
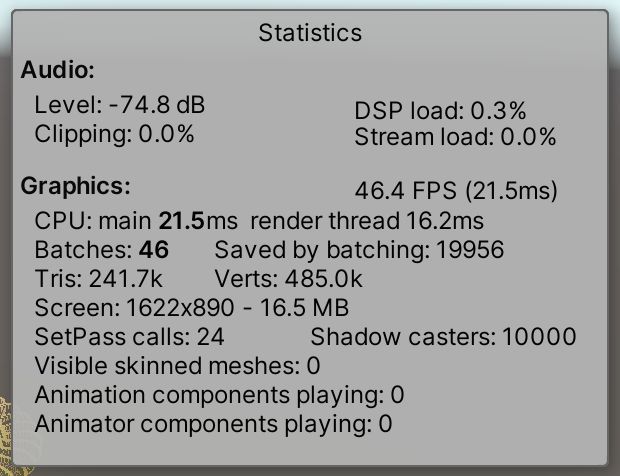
我们可以从这些数据中得出结论:对于URP来说,GPU实例化是最好的,其次是动态批处理,然后是SRP批处理。但是差别很小,所以它们在我们的图中是等价的。唯一明确的结论是应该使用GPU实例化或SRP批处理。
与动态批处理相比,BRP的GPU实例化的批处理数量更多,但帧率略高。
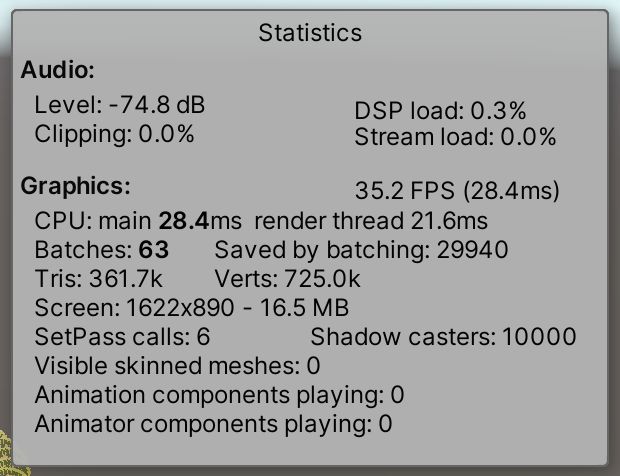
1.4 帧调试器
统计面板可以告诉我们使用动态批处理与使用GPU实例是不同的,但没有告诉我们为什么。为了更好地理解发生了什么,我们可以使用通过Window / Analysis / Frame Debugger打开的帧调试器。当通过工具栏按钮启用时,它会显示发送给GPU的游戏窗口最后一帧的所有绘制命令列表,在分析样本下分组。该列表显示在其左侧。在其右侧显示了一个特定的选定绘制命令的详细信息。此外,游戏窗口会显示进度绘制状态,直到选中命令后才会显示。
为什么我的电脑突然变热了? Unity使用了一个需要反复渲染相同帧的技巧来显示绘制帧的中间状态。只要帧调试器处于活动状态,它就会执行此操作。确保在不需要帧调试器时禁用它。
在我们的例子中,我们必须处于播放模式,因为这是我们绘制图形的时候。启用帧调试器将暂停播放模式,这允许我们检查绘制命令的层次结构。让我们首先为BRP做这个,不使用动态批处理或GPU实例化。
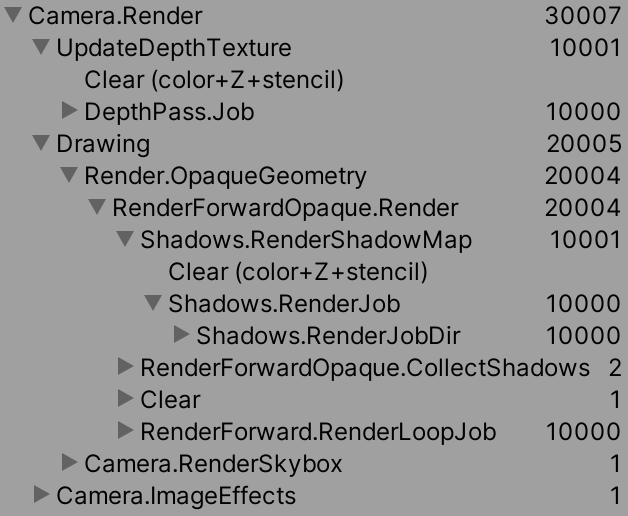
我们看到总共有30,007个绘制调用,比统计面板报告的要多,因为还有一些命令没有被算作批处理,比如清除目标缓冲区。我们的点的30,000的绘制作为*Draw Mesh Point(Clone)*被单独列出来, DepthPass.Job,Shadows.RenderDirJob和 RenderForward.RenderLoopJob下面。
如果我们再次尝试启用动态批处理,命令结构保持不变,除了每组10,000个Draw被减少到12个Draw Dynamic 调用。就CPU-GPU通信开销而言,这是一个显著的改进。

如果我们使用GPU实例化,那么每个组将减少到20个Draw Mesh (Instanced) Point(Clone)。这又是一个很大的改进,但是方法不同。

我们可以看到URP也发生了同样的情况,但是命令层次结构不同。在这种情况下,点被绘制了两次,第一次在Shadows.Draw,在RenderLoop.Draw下再次绘制。一个显著的区别是动态批处理似乎不适用于阴影映射,这解释了为什么它对URP不太有效。我们最终得到了22个批次,而不是只有12个批次,这表明URP材质比标准BRP材质依赖更多的网格顶点数据,因此在单个批次中适合的点更少。与动态批处理不同的是,GPU实例化确实适用于阴影,所以它在这种情况下是优越的。


最后,启用SRP批处理后,绘制10,000个点将被列为11个SRP批处理命令,但请记住,这些仍然是单独的绘制调用,只是非常有效的调用。

1.5 一个额外的光
到目前为止,我们得到的结果是有一个单一的方向光的图,和我们使用的其他项目设置。让我们看看当我们在场景中添加第二个光源时会发生什么,通过GameObject / light / point light添加一个点光源。设置它的位置为零,并确保它不会投射阴影,这是它的默认行为。BRP支持点光源的阴影,但URP仍然不支持。

带有额外的光的BRP现在用额外的时间绘制所有的点。帧调试器显示了RenderForward.RenderLoopJob渲染比以前多一倍。更糟糕的是,动态批处理现在只适用于深度和阴影通道,而不是前向通道。


这是因为BRP在每一束光中绘制一个对象。它有一个主要的通道,和一个单一的方向光一起工作,然后在它上面渲染额外的通道。这是因为它是一个老式的前添加渲染管道。动态批处理不能处理这些不同的管道,所以不被使用。
GPU实例化也是如此,只不过它仍然适用于主通道。只有额外通过的光不会从中受益。

第二个光源似乎对URP没有影响,因为它是一个现代正向渲染器,在一个通道中应用所有的光源。所以命令列表保持不变,即使GPU每次绘制需要执行更多的光照计算。
这些结论是针对一个影响所有点的额外光。如果你添加更多的光源并移动它们,这样不同的点就会受到不同光源的影响,事情就会变得更加复杂,在使用GPU实例化时批次就会被分割。对于一个简单的场景是正确的,但对于一个复杂的场景可能就不正确了。
延期渲染呢? BRP和HDRP有前向和延迟渲染模式,URP目前没有。延迟渲染的想法是,对象只绘制一次,这将它们的可见表面属性存储在GPU缓冲区中。在此之后,一个或多个灯光只在可见的物体应用灯光。与前向渲染相比,它有优点也有缺点,但我们不会在本教程系列中介绍它。
1.6 分析工具
为了更好地了解CPU方面发生了什么,我们可以打开分析器窗口。关闭点光源,通过Window / Analysis / Profiler打开窗口。它会在播放模式下记录性能数据并存储以备后续检查。
分析器分为两部分。它的顶部包含显示各种性能图的模块列表。最上面的是CPU使用率,这是我们要关注的。选择了该模块后,窗口的底部显示了我们可以在图中选择的帧的详细分解。
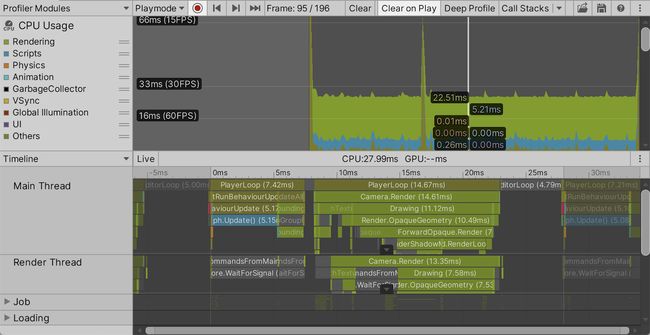
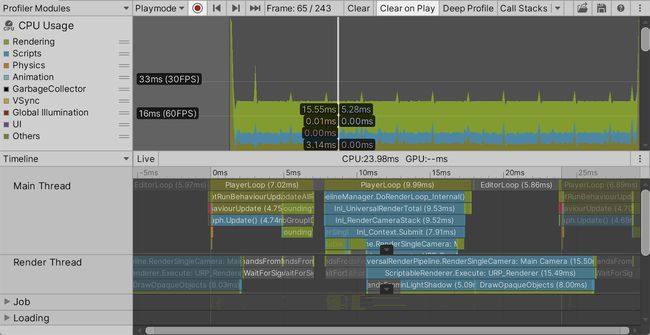
CPU使用情况的默认底部视图是时间轴。它可以直观地显示在一帧画面中所花费的时间。它表明,每一帧都从PlayerLoop开始,它花了大部分时间调用RunBehaviourUpdate。再往下两步,我们可以看到它主要是对我们的Graph.Update方法的调用。您可以选择一个时间线块,以毫秒为单位查看它的全名和持续时间。
在最初的PlayerLoop片段之后是一个简短的EditorLoop部分,之后是另一个PlayerLoop,用于帧的渲染部分,这部分中CPU告诉GPU要做什么。工作在主线程、呈现线程和一些工作线程之间被分割,但BRP和URP的具体方法不同。这些线程并行运行,但当一个线程必须等待另一个线程的结果时,也有同步点。
在呈现部分之后——如果使用了URP,则呈现线程仍处于繁忙状态——出现了另一个EditorLoop,在此之后开始下一帧。线程也可以跨越帧的边界。这是因为Unity可以在渲染线程完成之前在主线程上启动下一帧的更新循环,利用并行性。我们之后将在下一节讨论这个问题。
如果你对线程的确切时间不感兴趣,那么你可以通过左侧的下拉列表将Timeline视图替换为Hierarchy视图。该层次结构将相同的数据显示在单个可排序列表中。这个视图使我们更容易看到什么花费了最长的时间以及在哪里进行了内存分配。

1.7 分析构建
分析器让我们清楚地看到编辑器给我们的应用程序增加了很多开销。因此,当应用程序独立运行时,分析它会更有用。为此,我们必须构建我们的应用程序,专门用于调试。我们可以在Build Settings 窗口,通过File / Build Settings… 配置我们的应用程序是如何构建的,如果你还没有配置它,Scenes in Build部分是空的。这很好,因为当前打开的场景将默认使用。
你可以选择您的目标平台,当前使用的机器的平台是最方便的。然后启用Development Build 和 Autoconnect Profiler 选项。

要最终创建独立的应用程序(通常称为构建),请按Build按钮,或者Build and Run在构建过程完成后立即打开应用程序。你还可以通过File / Build and Run或指定的快捷方式触发另一个构建。
构建过程需要多长时间?
第一个构建花费的时间最长,使用URP时可能会忙上几分钟。在此之后,如果可能的话,Unity将重用之前生成的构建数据,显著加快构建过程。此外,项目越大,花费的时间越长。
一旦构建能够独立运行,便需要在一段时间后退出并切换回Unity。分析器现在应该包含关于它如何执行的信息。这并不总是发生在第一次构建之后,如果是这样,就再试一次。还要记住的是,当附加到一个构建时,分析器不会清除旧数据,即使Clear on Play是启用的,所以如果你只运行了几秒钟的应用程序,请确保你正在查看相关的帧。
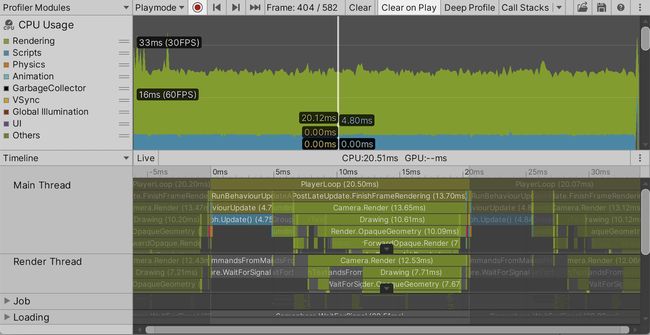
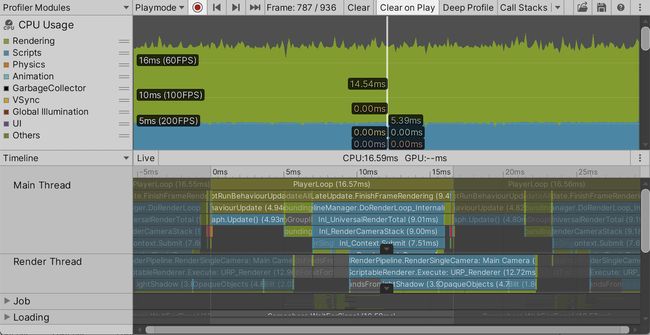
因为没有编辑器开销,所以构建应该比Unity编辑器中的播放模式表现得更好。分析器将不再显示编辑器循环部分。
2. 显示帧率
我们并不总是需要详细的分析信息,粗略地显示帧率通常就足够了。此外,我们或其他人可能在没有Unity编辑器的情况下运行我们的应用程序。对于这些情况,我们能做的就是在应用程序中的一个小覆盖面板中测量并显示帧数。这种功能在默认情况下是不可用的,所以我们将自己创建它。
2.1 UI面板
可以用Unity的游戏UI创建一个小的覆盖面板。我们还将使用TextMeshPro创建文本来显示帧率。TextMeshPro是一个单独的包,包含高级文本显示功能,优于默认的UI文本组件。如果你没有安装它的包,就通过包管理器添加它。这也会自动安装Unity UI包,因为TextMeshPro依赖于它。
为什么不使用UI Toolkit? UI Toolkit目前只适用于编辑器UI。有一个运行时使用的包,但它仍作用于预览中,所以我不会使用它。
一旦UI包成为项目的一部分,就可以通过GameObject / UI / panel创建一个面板。这将创建一个覆盖整个UI画布的半透明面板。画布与游戏窗口大小匹配,但在场景窗口中要大得多。通过场景窗口工具栏启用2D模式,然后缩小,最容易看到它。
每个UI都有一个画布根对象,当我们添加一个面板时,它会自动创建。面板是画布的子元素。还创建了EventSystem游戏对象,它负责处理UI输入事件。我们不会使用那些,所以可以忽略甚至删除它。

画布有一个缩放器组件,可用于配置UI的缩放。默认设置假设像素大小不变。如果你使用的是高分辨率或视网膜显示器,那么你就必须提高缩放系数,否则UI将会太小。你还可以尝试其他的缩放模式。
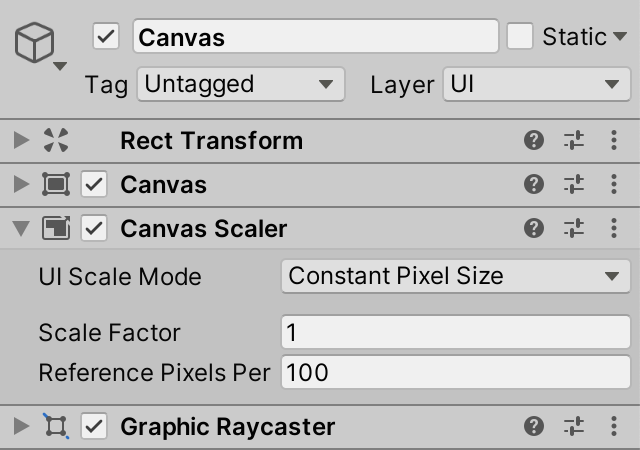
UI游戏对象有一个专门的RectTransform组件,它取代了通常的Transform组件。除了通常的位置,旋转和缩放,它暴露了基于锚的额外属性。锚控制对象相对于父对象的相对位置和调整大小的行为。改变它的最简单的方法是通过点击正方形锚图像打开的弹出窗口。
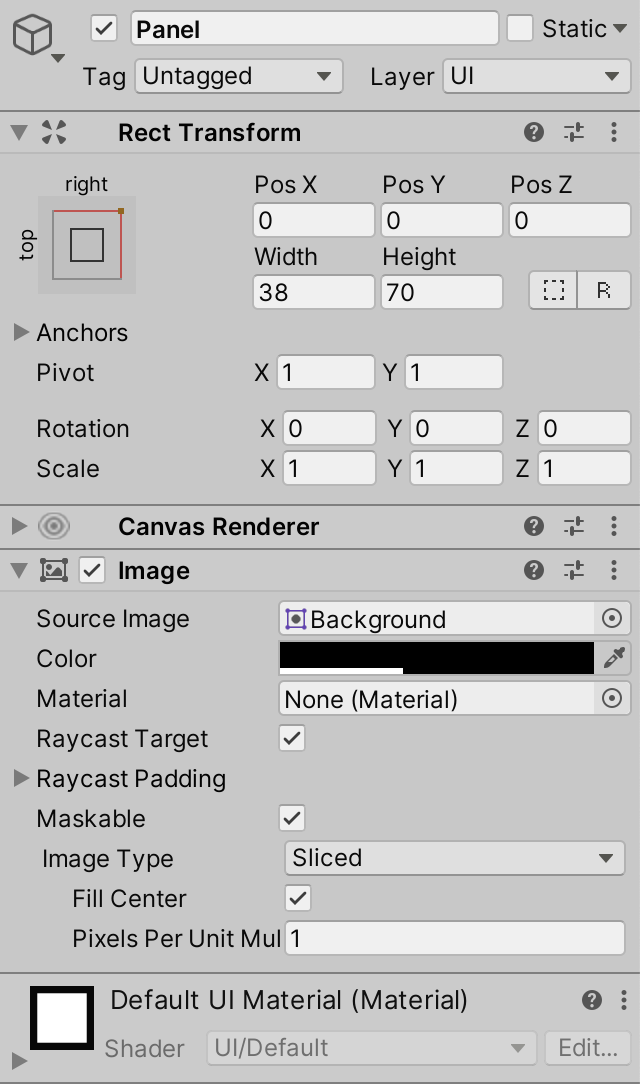
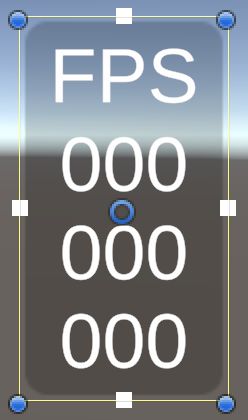
我们将把帧率计数器面板放在窗口的右上方,因此将面板的锚点设置为右上方,pivot XY设置为1。然后设置宽度为38,高度为70,位置为0。之后,将图像组件的颜色设置为黑色,保持其alpha不变。

2.2 文本
通过GameObject / UI / text - TextMeshPro创建一个TextMeshPro UI文本元素。如果这是你第一次创建一个TextMeshPro对象,Import TMP Essentials弹出将显示。按照建议导入Essentials。这将创建一个TextMesh Pro资产文件夹,其中有一些资产,我们不需要直接处理。
创建文本游戏对象后,将其作为面板的子对象,将其锚定在两个维度上的拉伸模式。让它覆盖整个面板,可以通过将左、上、右和下设置为零来完成。也给它一个描述性的名称,如Frame Rate Text.。
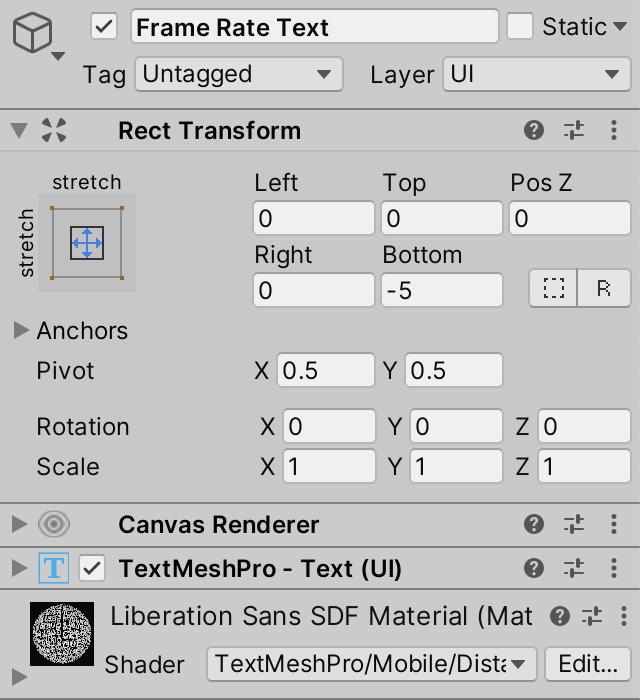
接下来,对TextMeshPro - Text (UI)组件做一些调整。设置字体大小为14,Alignment 对齐到中间。然后用占位符文本填充Text Input区域,具体是FPS后面的3行,每行有3个0。
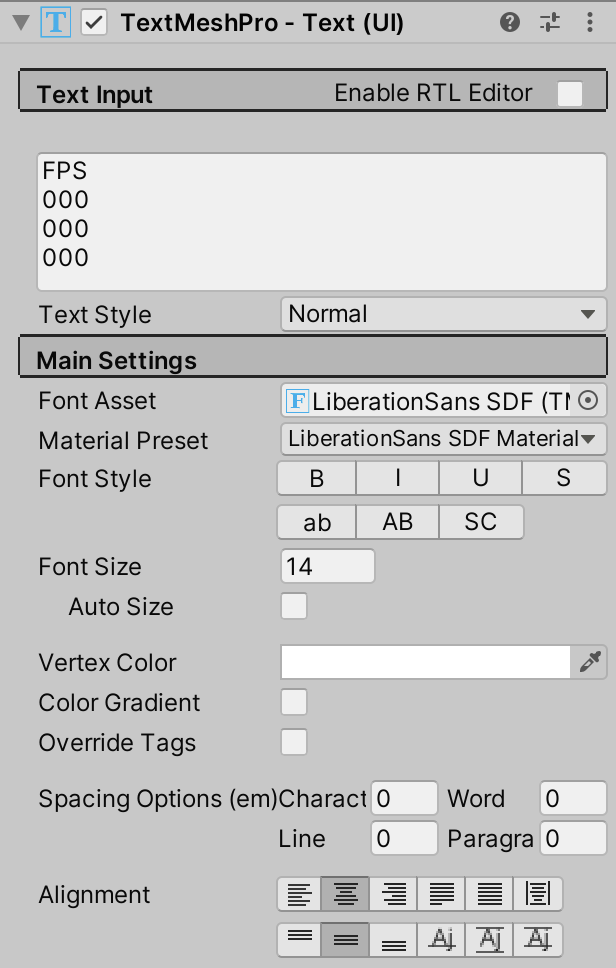
我们现在可以看到我们的帧率计数器是什么样的。这三行零是我们稍后将显示的统计信息的占位符。
2.3 更新显示
要更新计数器,我们需要一个自定义组件。为FrameRateCounter组件创建一个新的C#脚本资产。给它一个可序列化的 TMPro.TextMeshProUGUI字段保存用于显示其数据的文本组件的引用。
using UnityEngine;
using TMPro;
public class FrameRateCounter : MonoBehaviour {
[SerializeField]
TextMeshProUGUI display;
}
将此组件添加到文本对象并连接显示。
为了显示帧速率,我们需要知道前一帧和当前帧之间经过了多少时间。此信息可通过Time.deltaTime获得。然而,这个值受时间尺度,如慢动作、快进或完全停止时间的影响。我们需要利用Time.unscaledDeltaTime代替。在FrameRateCounter中一个新的Update方法开始时检索它。
void Update () {
float frameDuration = Time.unscaledDeltaTime;
}
下一步是调整显示的文本。我们可以通过使用文本字符串参数调用它的SetText方法来实现这一点。让我们首先提供我们已经拥有的相同的占位符文本。字符串写在双引号之间,换行用特殊的\n字符序列。
float frameDuration = Time.unscaledDeltaTime;
display.SetText("FPS\n000\n000\n000");
TextMeshProUGUI有不同的SetText方法,接受额外的float参数。添加帧持续时间作为第二个参数,然后用在花括号中的一个0替换字符串的第一行的三个0。指示应该float参数被插入在字符串中的位置。
display.SetText("FPS\n{0}\n000\n000", frameDuration);
帧持续时间告诉我们经过了多少时间。为了以每秒帧数来表示帧率,我们必须显示它的倒数,即1除以帧持续时间。
display.SetText("FPS\n{0}\n000\n000", 1f / frameDuration);
这将显示一个有意义的值,但它将包含太多的数字,如59.823424。我们可以通过在0后面加上冒号和想要的数字来指示文本四舍五入到小数点后的特定位数。我们会四舍五入到一个整数,所以加零。
display.SetText("FPS\n{0:0}\n000\n000", 1f / frameDuration);
2.4 平均帧率
显示的帧速率最终会快速变化,因为连续帧之间的时间几乎不会完全相同。我们可以通过显示平均帧率而不是仅显示最后一帧的帧率来减少它的不稳定性。我们通过跟踪渲染了多少帧和总持续时间来做到这一点,然后显示帧的数量除以它们的总持续时间。
int frames;
float duration;
void Update () {
float frameDuration = Time.unscaledDeltaTime;
frames += 1;
duration += frameDuration;
display.SetText("FPS\n{0:0}\n000\n000", frames / duration);
}
这将使我们的计数器趋向于一个稳定的平均值,但这个平均值是我们应用程序的整个运行时间。因为我们想要最近的信息,我们必须重置和重新开始,采样一个新的平均值。我们可以通过添加一个可序列化的采样时长字段(默认设置为1秒)来实现此配置。给它一个合理的范围,比如0.1-2。持续时间越短,我们得到的结果越精确,但它将更难读取,因为它变化得越快。
[SerializeField]
TextMeshProUGUI display;
[SerializeField, Range(0.1f, 2f)]
float sampleDuration = 1f;

从现在开始,我们将只在累计持续时间等于或超过配置的采样时间时调整显示。我们可以使用>=操作符来检查。更新显示后,将累计帧和持续时间设置为零。
void Update () {
float frameDuration = Time.unscaledDeltaTime;
frames += 1;
duration += frameDuration;
if (duration >= sampleDuration) {
display.SetText("FPS\n{0:0}\n000\n000", frames / duration);
frames = 0;
duration = 0f;
}
}
2.5 最好与最坏
平均帧率波动是因为我们的应用程序的性能不是恒定的。它有时会变慢,要么是因为它暂时有更多的工作要做,要么是因为在同一台机器上运行的其他进程挡住了它的路。为了了解这些波动有多大,我们还将记录和显示在采样期间发生的最佳和最差帧持续时间。默认设置最佳持续时间为float.MaxValue,这是最佳持续时间的最坏的可能。
float duration, bestDuration = float.MaxValue, worstDuration;
每次更新检查当前帧的持续时间是否小于到目前为止的最佳持续时间。如果是这样,那就把它作为新的最佳持续时间。同时检查当前帧持续时间是否大于到目前为止最坏的持续时间。如果是这样的话,让它成为新的最差的持续时间。
void Update () {
float frameDuration = Time.unscaledDeltaTime;
frames += 1;
duration += frameDuration;
if (frameDuration < bestDuration) {
bestDuration = frameDuration;
}
if (frameDuration > worstDuration) {
worstDuration = frameDuration;
}
…
}
现在我们将最好的帧率放在第一行,平均的放在第二行,最差的放在最后一行。为此,我们可以向SetText添加两个参数,并向字符串添加更多占位符。它们是索引,所以第一个数字用0表示,第二个数字用1表示,第三个数字用2表示。之后还要重置最佳和最差的持续时间。
if (duration >= sampleDuration) {
display.SetText(
"FPS\n{0:0}\n{1:0}\n{2:0}",
1f / bestDuration,
frames / duration,
1f / worstDuration
);
frames = 0;
duration = 0f;
bestDuration = float.MaxValue;
worstDuration = 0f;
}
注意,即使启用垂直同步,最佳帧率也可能超过显示刷新速率。同样地,最糟糕的帧率也不一定是显示刷新率的倍数。这是可能的,因为我们没有测量显示帧之间的持续时间。我们正在测量Unity帧之间的持续时间,这是更新循环的迭代。Unity的Update循环与显示不完全同步。当分析器显示下一帧的playerloop开始时,而当前帧的渲染线程仍然很忙时,我们已经看到了一些暗示。在渲染线程完成后,GPU仍然有一些工作要做,在这之后,它仍然需要一段时间才能显示刷新。所以我们显示的FPS并不是真正的帧率,而是Unity告诉我们的。理想情况下,这两个是相同的,但要正确实现这一点很复杂。有一篇关于Unity如何在这方面进行改进的博客文章,但这并不是完整的方案。
2.6 帧持续时间
帧/秒是衡量感知性能的一个很好的单位,但当试图达到目标帧速率时,显示帧持续时间更有用。例如,当试图在移动设备上实现稳定的60FPS时,每毫秒都很重要。所以让我们添加一个显示模式配置选项到我们的帧率计数器。
在FrameRateCounter中定义FPS和MS的DisplayMode枚举,然后添加该类型的可序列化字段,默认设置为FPS。
[SerializeField]
TextMeshProUGUI display;
public enum DisplayMode { FPS, MS }
[SerializeField]
DisplayMode displayMode = DisplayMode.FPS;
然后,当我们在Update中刷新显示时,检查模式是否设置为FPS。如果是这样的话,做我们已经在做的事情。否则将FPS头替换为MS,并使用相反的参数。将它们乘以1000也可以将秒转换为毫秒。
if (duration >= sampleDuration) {
if (displayMode == DisplayMode.FPS) {
display.SetText(
"FPS\n{0:0}\n{1:0}\n{2:0}",
1f / bestDuration,
frames / duration,
1f / worstDuration
);
}
else {
display.SetText(
"MS\n{0:0}\n{1:0}\n{2:0}",
1000f * bestDuration,
1000f * duration / frames,
1000f * worstDuration
);
}
frames = 0;
duration = 0f;
bestDuration = float.MaxValue;
worstDuration = 0f;
}
帧的持续时间通常以十分之一毫秒来衡量。我们可以通过将四舍五入的数字从0增加到1来提高显示的精度。
display.SetText(
"MS\n{0:1}\n{1:1}\n{2:1}",
1000f * bestDuration,
1000f * duration / frames,
1000f * worstDuration
);

2.7 内存分配
我们的帧率计数器已经完成,但在继续之前,让我们检查一下它对性能的影响。显示UI需要每帧更多的绘制调用,但这并没有太大影响。在播放模式下使用分析器,然后搜索一个我们更新文本的帧。事实证明,这并不花费太多时间,但它确实分配了内存。最容易的方式是通过按GC Alloc列排序,层次结构视图检测的。

文本字符串是对象。当我们通过SetText创建一个新的字符串对象时,会产生一个新的字符串对象,它负责分配106字节。Unity的UI刷新将这一数据增加到4.5 kb。虽然这并不多,但它会在某些时候触发内存垃圾收集进程,从而导致不必要的帧持续时间的猛增。
注意临时对象的内存分配并尽可能消除重复出现的对象是很重要的。幸运的是,因为各种原因SetText和Unity的UI更新只在编辑器中执行这些内存分配,比如更新文本输入字段。如果我们分析一个构建,那么我们将发现一些初始分配,但随后就没有更多了。因此,对构建进行分析是至关重要的。分析编辑器的播放模式只适合第一印象。
3. 自动切换函数
现在我们知道了如何分析我们的应用程序,我们可以在显示不同函数时比较它的性能。如果一个函数需要更多的计算,那么CPU就需要做更多的工作,这样就会降低帧率。而对于GPU来说,如何计算点并不重要。如果分辨率相同,GPU就必须做同样多的工作。
最大的区别是Wave函数和Torus函数。我们可以通过分析器比较它们的CPU使用情况。我们可以比较配置了不同函数的两个单独的运行,或者在播放模式下分析并在播放过程中切换函数。
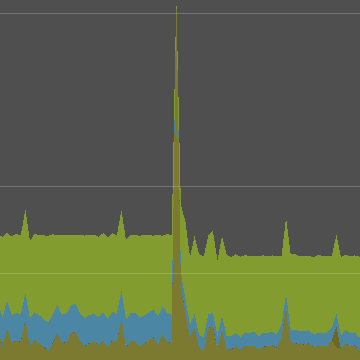
CPU图显示,从Torus转换为Wav后,负载确实下降了。当切换发生时,还会出现一个巨大的帧持续时间的长峰。这是因为当通过编辑器进行更改时,播放模式会暂时暂停。由于取消选择和编辑器焦点的改变,一些较小的峰值随后也发生了。
峰值会在Other类别下消失。可以通过切换左侧的类别标签来过滤CPU图,以便我们只看到相关数据。禁用Other类别后,计算量的变化更加明显。
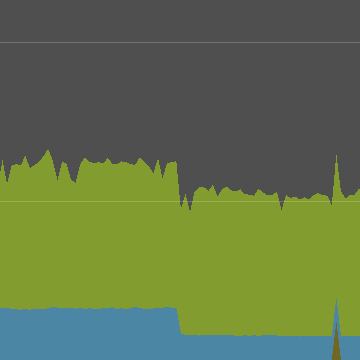
剩下的小尖峰是什么? 这就是刚刚激活的垃圾收集器。
由于暂停,通过检查器切换函数对于分析来说是很笨拙的。更糟糕的是,我们必须创建一个新的构建来分析不同的函数。我们可以通过添加功能来改进这一点:除了通过检查器,还可以通过自动或用户输入来切换函数到我们的图形。我们将在本教程中选择第一个选项。
3.1 遍历函数
我们会自动遍历所有函数。每个函数将显示一个固定的持续时间,之后将显示下一个。要使函数持续时间可配置,为Graph添加一个可序列化字段,默认值为1秒。还可以通过赋予Min属性将其最小值设置为0。持续时间为0的结果是每一帧切换到一个不同的函数。
[SerializeField]
FunctionLibrary.FunctionName function = default;
[SerializeField, Min(0f)]
float functionDuration = 1f;
从现在开始,我们需要跟踪当前函数已经运行了多长时间,并在需要时切换到下一个函数。这将使Update方法复杂化。它的当前代码只处理当前函数的更新,所以让我们将它移动到一个单独的UpdateFunction方法,并让Update调用它。这样可以保持代码的组织性。
void Update () {
UpdateFunction();
}
void UpdateFunction () {
FunctionLibrary.Function f = FunctionLibrary.GetFunction(function);
float time = Time.time;
float step = 2f / resolution;
float v = 0.5f * step - 1f;
for (int i = 0, x = 0, z = 0; i < points.Length; i++, x++) { … }
}
现在添加一个持续时间字段,并在Update开始时将其增加(可能是可伸缩的)增量时间。如果持续时间等于或超过配置的持续时间,则将其重置为零。之后是UpdateFunction的调用。
Transform[] points;
float duration;
…
void Update () {
duration += Time.deltaTime;
if (duration >= functionDuration) {
duration = 0f;
}
UpdateFunction();
}
我们很可能永远都不能精确达到函数持续时间,我们会稍微超出它一点。我们可以忽略这一点,但为了与函数切换的异常时间保持合理的同步,我们应该从下一个功能的持续时间中扣除额外的时间。我们通过从当前持续时间中减去所需的持续时间而不是将其设置为0来实现这一点。
if (duration >= functionDuration) {
duration -= functionDuration;
}
为了遍历函数,我们将在FunctionLibrary中添加GetNextFunctionName方法,该方法接受一个FunctionName并返回下一个FunctionName。因为枚举是整数,我们可以给它的形参加1然后返回。
public static FunctionName GetNextFunctionName (FunctionName name) {
return name + 1;
}
但是我们也必须返回到第一个函数,而不是经过最后一个函数,否则我们将以无效的名称结束。因此,只有当提供的名称小于torus时,我们才能增加它。否则我们返回第一个函数,也就是Wave。我们可以使用if-else块来实现这一点,每个if-else块都返回适当的结果。
if (name < FunctionName.Torus) {
return name + 1;
}
else {
return FunctionName.Wave;
}
我们可以通过将函数名(作为int类型)与函数数组的长度减1(与最后一个函数的索引匹配)进行比较,使该方法不用处理具体的函数名。如果在末尾,也可以返回0,也就是第一个下标。这种方法的优点是,如果以后要更改函数名,就不必调整方法。
if ((int)name < functions.Length - 1) {
return name + 1;
}
else {
return 0;
}
还可以使用?:三元条件操作符将方法体简化为单个表达式。它是一个if-then-else表达式,带有?和:分离它的各个部分。两个选项必须产生相同类型的值。
public static FunctionName GetNextFunctionName (FunctionName name) {
return (int)name < functions.Length - 1 ? name + 1 : 0;
}
使用新的Graph.Update方法。在适当的时候切换到下一个函数。
if (duration >= functionDuration) {
duration -= functionDuration;
function = FunctionLibrary.GetNextFunctionName(function);
}
我们现在可以通过分析一个构建来依次查看所有函数的性能。
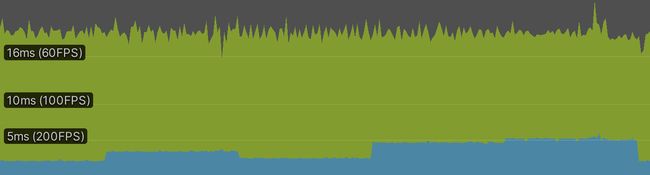
在我的例子中,所有函数的帧率都是相同的,因为它从未低于60FPS。通过等待垂直同步来消除差异。分析一个支持垂直同步的构建可以使差异更加明显。或者,只在分析器中显示脚本。

事实证明Wave是最快的,其次是Ripple,然后是Multi Wave,然后是Sphere,而Torus是最慢的。这符合我们所期望的。
垂直同步不应该在分析器中单独显示为黄色吗? 应该是这样,但这不会发生在我的Unity 2020中。它与渲染相结合。
3.2 随机函数
让我们通过添加一个选项来随机切换函数,而不是按照固定的顺序循环,让我们的图表变得更有趣一些。在FunctionLibrary中添加一个GetRandomFunctionName方法来支持这个功能。它可以通过调用 Random.Range,用0和函数的数组长度作为参数,来选择一个随机索引。所选索引是有效的,因为这是方法的整数版本,所提供的范围是包含-排他的。
public static FunctionName GetRandomFunctionName () {
var choice = (FunctionName)Random.Range(0, functions.Length);
return choice;
}
我们可以更进一步,确保不会连续两次得到相同的函数。通过将新方法重命名为GetRandomFunctionNameOtherThan并添加一个函数名参数来实现这一点。增加Random.Range的第一个参数为1,所以索引0不会随机选择。然后检查这个选择是否等于要避免的名字。如果是,则返回第一个名称,否则返回选中的名称。因此,我们用零代替不允许的指数,而不引入选择偏差。
public static FunctionName GetRandomFunctionNameOtherThan (FunctionName name) {
var choice = (FunctionName)Random.Range(1, functions.Length);
return choice == name ? 0 : choice;
}
回到Graph,为转换模式添加一个配置选项,可以是循环模式,也可以是随机模式。同样使用自定义枚举字段执行此操作。
[SerializeField]
FunctionLibrary.FunctionName function;
public enum TransitionMode { Cycle, Random }
[SerializeField]
TransitionMode transitionMode;
在选择下一个函数时,检查转换模式是否设置为cycle。如果这样调用GetNextFunctionName,否则调用GetRandomFunctionName。由于这使选择下一个函数变得复杂,让我们把这段代码也放在一个单独的方法中,保持Update的简洁。

3.3 在函数之间插值
我们通过使函数之间的转换更有趣来结束本教程。我们将平滑地改变我们的图形到下一个,而不是突然切换到另一个函数。这对于性能分析也很有趣,因为它需要在转换期间同时计算两个函数。
首先添加一个Morph函数到FunctionLibrary,它将负责转换。给它与函数方法相同的参数,加上两个function参数和一个float参数来控制变形进度。
public static Vector3 Morph (
float u, float v, float t, Function from, Function to, float progress
) {}
我们使用的是Function形参而不是FunctionName形参,因为通过这种方式,Graph可以在每次更新时通过名称检索函数,这样我们就不必在每个点上两次访问函数数组。
为什么每次更新Graph时检索函数? 我们也可以将函数存储在Graph的字段中,而不是每次更新都得到它们。我们不这样做是因为Function类型的字段值不能在热加载时存活,而FunctionName字段可以。而且,每次更新检索一两个函数对性能没有明显影响。但是每次更新都这样做会带来很多不必要的额外工作。
Unity的UnityEvent类型是可序列化的,所以我们可以使用它们来代替,但它们增加了更多我们不需要的开销和功能。它们通常用于将方法挂钩到UI事件。
progress是一个0-1的值,我们将使用它从提供的第一个函数插值到第二个函数。我们可以使用Vector3.Lerp函数对此进行处理,将函数的结果和progress传递给它。
public static Vector3 Morph (
float u, float v, float t, Function from, Function to, float progress
) {
return Vector3.Lerp(from(u, v, t), to(u, v, t), progress);
}
Lerp是线性插值的简写。它将在函数之间产生一个直线的匀速转换。我们可以通过放慢开始和结束附近的进程让它看起来更平滑。这是通过用0、1和progress作为参数,调用Mathf.Smoothstep替换原始的progress。它适用于 3 x 2 − 2 x 3 3x^2-2x^3 3x2−2x3函数,俗称Smoothstep。Smoothstep的前两个参数是这个函数的偏移量和比例,我们不需要它,所以使用0和1。
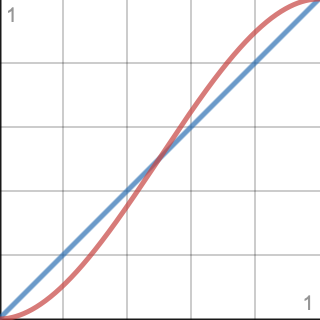
return Vector3.Lerp(from(u, v, t), to(u, v, t), SmoothStep(0f, 1f, progress));
Lerp方法将其第三个参数固定在0-1范围内。Smoothstep方法也可以做到这一点。我们将后者配置为输出0-1值,因此不需要Lerp的额外限制。对于这种情况,还有一种替代的LerpUnclamped方法,所以让我们使用那个方法。
return Vector3.LerpUnclamped(
from(u, v, t), to(u, v, t), SmoothStep(0f, 1f, progress)
);
3.4 过渡变换
函数之间的过渡时期需要一个持续时间,因此为其添加一个配置选项到Graph,其最小值和默认值与函数持续时间相同。
[SerializeField, Min(0f)]
float functionDuration = 1f, transitionDuration = 1f;
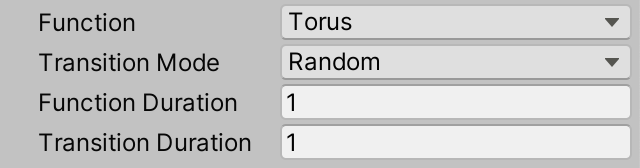
我们的图现在可以有两种模式,可以是过渡模式或不是过渡模式。我们将使用一个布尔字段来跟踪这一点,它具有bool类型。我们还需要跟踪正在进行转换的函数的名称。
float duration;
bool transitioning;
FunctionLibrary.FunctionName transitionFunction;
UpdateFunction方法用于显示单个函数。复制它并将新的命名为UpdateFunctionTransition。更改它,使它同时获得两个函数并计算进度,即当前持续时间除以过渡持续时间。然后让它调用Morph而不是循环中的单个函数。
void UpdateFunctionTransition () {
FunctionLibrary.Function
from = FunctionLibrary.GetFunction(transitionFunction),
to = FunctionLibrary.GetFunction(function);
float progress = duration / transitionDuration;
float time = Time.time;
float step = 2f / resolution;
float v = 0.5f * step - 1f;
for (int i = 0, x = 0, z = 0; i < points.Length; i++, x++) {
…
points[i].localPosition = FunctionLibrary.Morph(
u, v, time, from, to, progress
);
}
}
在最后Update检查我们是否正在过渡。如果是这样,调用UpdateFunctionTransition,否则调用UpdateFuction。
void Update () {
duration += Time.deltaTime;
if (duration >= functionDuration) {
duration -= functionDuration;
PickNextFunction();
}
if (transitioning) {
UpdateFunctionTransition();
}
else {
UpdateFunction();
}
}
一旦持续时间超过函数持续时间,我们就进入下一个。在选择下一个函数之前,表明我们正在进行转换,并使转换函数等于当前函数。
if (duration >= functionDuration) {
duration -= functionDuration;
transitioning = true;
transitionFunction = function;
PickNextFunction();
}
但如果我们已经在过渡了我们就得做点别的。首先检查我们是否在过渡。只有在情况不是这样的情况下,我们才需要检查是否超出了函数持续时间。
duration += Time.deltaTime;
if (transitioning) {}
else if (duration >= functionDuration) {
duration -= functionDuration;
transitioning = true;
transitionFunction = function;
PickNextFunction();
}
如果我们正在过渡,那么我们必须检查是否超出了过渡持续时间。如果是,则从当前持续时间中扣除过渡持续时间,然后切换回单一功能模式。
if (transitioning) {
if (duration >= transitionDuration) {
duration -= transitionDuration;
transitioning = false;
}
}
else if (duration >= functionDuration) { … }
如果我们现在分析,我们可以看到确实在过渡中 Graph.Update 需要更长的时间。具体需要多长时间取决于混合的功能。

需要重复的是,您得到的分析结果取决于您的硬件,并且可能与我在本教程中展示的示例有很大不同。当你开发自己的应用程序时,决定你支持的最低硬件规格并测试它们。您的开发机器只用于初步测试。如果你的目标是多个平台或硬件规格,那么你就需要多个测试设备。
下一个教程是计算着色器。