Transformer 总结(self-attention, multi-head attention)
《Attention Is All You Need》:[1706.03762] Attention Is All You Need (arxiv.org)
注:本文只是个人简单的概括知识点以便于本人日后查看,详细请参考:http://t.csdn.cn/dz2TH
Transformer
优点:
改进了RNN训练慢的缺点,利用self-attention机制实现快速并行。
可以增加到非常深的深度,充分发掘DNN模型的特性,提升模型准确率。
整体框架图:

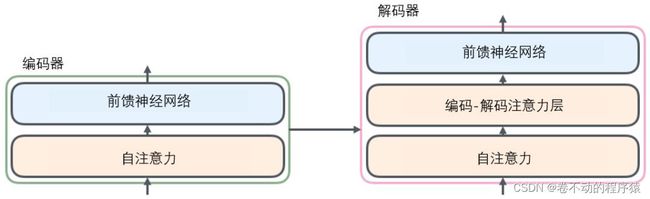
所有的编码器在结构上都是相同的,但它们没有共享参数。解码器中还有一个注意力层,用来关注输入句子的相关部分(和seq2seq模型的注意力作用相似)。
编码器流程:
1、输入首先会经过一个自注意力(self-attention)层。
这层帮助编码器在对每个单词编码时关注输入句子的其他单词。
2、自注意力层的输出会传递到前馈(feed-forward)神经网络中。
每个位置的单词对应的前馈神经网络都完全一样(译注:另一种解读就是一层窗口为一个单词的一维卷积神经网络)。
自注意力
查询向量(Query)、键向量(Key)、值向量(Value)。
计算步骤:
1、生成三个向量QKV
对于每个输入Xi,通过词嵌入与三个权重矩阵相乘创建三个向量:一个查询向量、一个键向量和一个值向量。
2、计算得分
为每个输入Xi计算自注意力向量,利用其它输入X对当前Xi打分,这些分数决定了在编码Xi的过程中有多重视输入的其它部分。
3、稳定梯度
将分数除以8(默认值),8是论文中使用的键向量的维数64的平方根,这会让梯度更稳定,也可以使用其它值。
4、归一化
通过softmax传递结果,其作用是使所有X的分数归一化,得到的分数都是正值且和为1。
5、每个值向量乘以softmax分数
为之后将它们求和做准备,达到关注语义上的相关,并弱化其不相关(乘以非常小的小数)。
6、对加权值向量求和
含义:在编码某个Xi时,将所有其它X的表示(值向量)进行加权求和,其权重是通过Xi的表示(键向量)与被编码Xi表示(查询向量)的点积并通过softmax得到。即得到自注意力层在该位置的输出。
利用输入生成三个向量QKV

自注意力计算

多头注意力
多头注意力(multi-head attention)机制进一步完善了自注意力层。
优点:
1、扩展了模型专注于不同位置的能力。
在上面的结构中,虽然每个编码都在z1中有或多或少的体现,但是它可能被实际的单词本身所支配。如果我们翻译一个句子,比如“The animal didn’t cross the street because it was too tired”,我们会想知道“it”指的是哪个词,这时模型的“多头”注意机制会起到作用。
2、给出了注意力层的多个“表示子空间”(representation subspaces)。
对于“多头”注意机制,有多个查询/键/值权重矩阵集(Transformer使用八个注意力头,因此对于每个编码器/解码器有八个矩阵集合)。这些集合中的每一个都是随机初始化的,在训练之后,每个集合都被用来将输入词嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
挑战与方法:
与上述相同的自注意力计算,只需八次不同的权重矩阵运算就会得到八个不同的Z矩阵。但是,前馈层不需要8个矩阵,它只需要一个矩阵(由每一个单词的表示向量组成)。所以需要把这八个矩阵压缩成一个矩阵,可以直接把这些矩阵拼接在一起,然后用一个附加的权重矩阵WO与它们相乘。

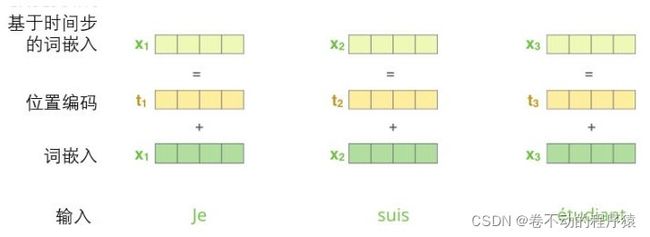
位置编码
使用位置编码表示序列的顺序。
Transformer为每个输入的Xi嵌入添加了一个向量。有助于确定每个单词的位置,或序列中不同单词之间的距离。将位置向量添加到Xi嵌入中使得它们在运算中,能够更好地表达词与词之间的距离。
每一行对应一个词向量的位置编码,即第一行对应着输入序列的第一个词。每行包含512个值,每个值介于1和-1之间。
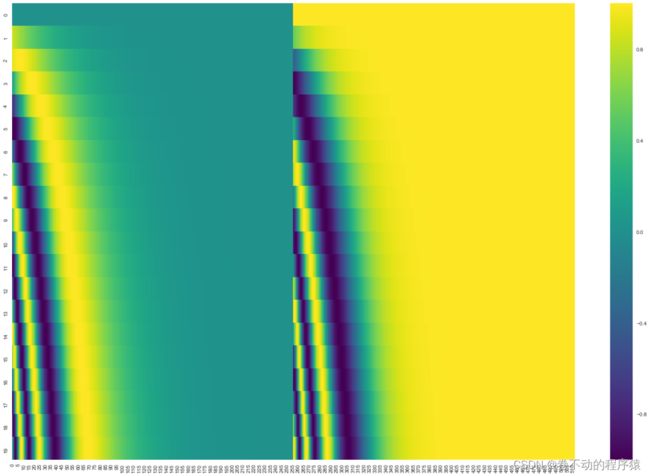
20字(行)的位置编码实例,词嵌入大小为512(列)。你可以看到它从中间分裂成两半。左半部分的值由一个函数(正弦)生成,右半部分由另一个函数(余弦)生成。将它们拼在一起得到每一个位置编码向量。
这种方法的优点:能够扩展到未知的序列长度。
残差
在每个编码器中的每个子层(自注意力、前馈网络)的周围都有一个残差连接,并且都跟随着一个“层-归一化”步骤。
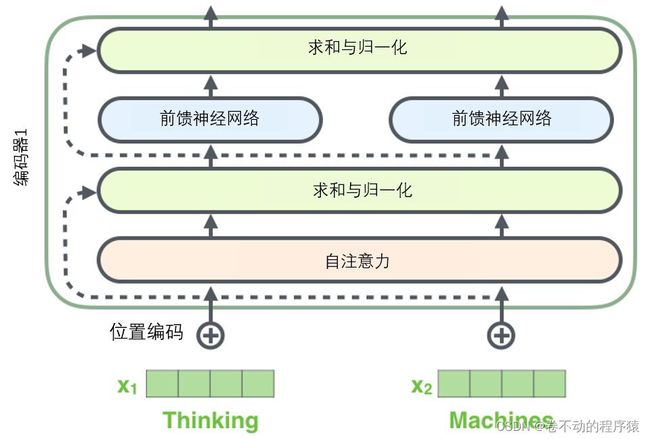
层-归一化步骤:https://arxiv.org/abs/1607.06450