Pytorch 多GPU训练
Pytorch 多GPU训练
- 介绍
- 使用
-
-
- 1.1 torch.nn.DataParallel
- 1.2 torch.nn.parallel.DistributedDataParallel
-
介绍
Pytorch 的分布式训练主要是使用torch.distributed来实现的,它主要由三个组件构成:
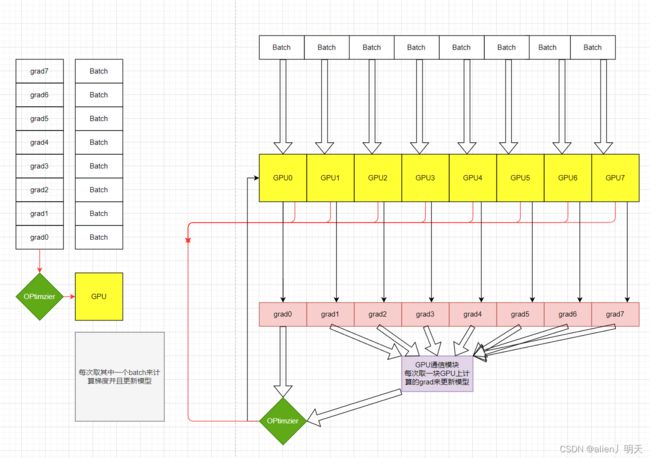
1.Distributed Data-Parallel Training(DDP):它是一个single-program和multi-process。使用DDP组件的时候,模型被复制到每一个进程也就是GPU里面,每个model都会被送入同样大小batch_size的不同样本进行训练,每个model都会计算出一个grad,然后每个model计算好的grad和其他的GPU进行通信然后进行同步更新model参数,以此来加快模型训练速度。
2.RPC-Based Distributed Training(RPC):支持一些无法并行化训练数据的范式,例如分布式管道范式、参数服务器范式(参数和训练器不在同一个服务器上)、结合DDP的其他训练范式。
3.Collection Communication(c10d):支持在一个组里面跨进程的传送张量,它提供了collective通信APIs和P2P通信APIs,DDP模式和RPC模式就是建立在c10d的基础上,DDP采用的是collective communication,RPC采用P2P communication, 一般情况下很少使用这个API,因为DDP和RPC已经足以在很多场景下使用。
计算 distributed parameter averaging,参数平均的时候可能会用到这个API.
**Data Parallel Training**:
单机单卡直接训练
单机多卡可以使用torch.nn.DataParallel和torch.nn.parallel.DistributedDataParallel来进行训练,其中DistributedDataParallel可以提供一定程度的加速
多机多卡 DistributedDataParallel and the launching script
built-in backends : 内置后端
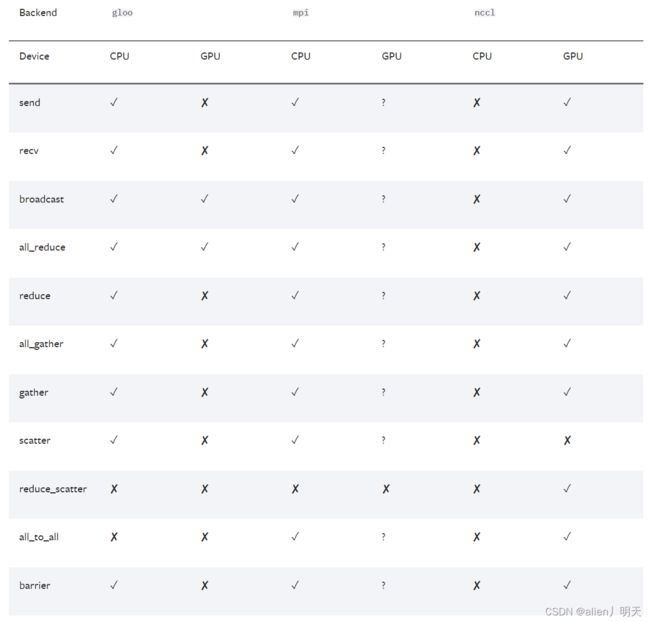
1 NCCL: distributed GPU training
2 Gloo: distributed CPU training
使用
单机多GPU可以使用torch.nn.DataParallel接口或者torch.nn.parallel.DistributedDataParallel接口(DDP),官方推荐使用第二个,多机多卡的情况下只能使用DDP。
.DistributedDataParallel和DataParallel之间的区别是:
DistributedDataParallel使用多进程multiprocessing,即为每个GPU创建一个进程,而DataParallel使用的是多线程。DDP通过使用multiprocessing,每个GPU都有专门的进程,这就避免了python解释器的GIL导致的性能开销。如果使用DDP,可以使用torch.distributed.launch来启动程序。
DDP的上层调用是通过dispatch.py实现的,即dispatch.py是DDP的python入口,它实现了调用C++库forward的nn.parallel.DistributedDataParallel模块的初始化和功能。
1.1 torch.nn.DataParallel
net = torch.nn.DataParallel(model, device_ids=[0,1,2])
output = net(input_var)
device_ids中的第一个GPU(即device_ids[0])和model.cuda()或torch.cuda.set_device()中的第一个GPU序号应保持一致,否则会报错。此外如果两者的第一个GPU序号都不是0,
model=torch.nn.DataParallel(model,device_ids=[2,3])
model.cuda(2)
那么程序可以在GPU2和GPU3上正常运行,但是还会占用GPU0的一部分显存(大约500M左右),这是由于pytorch本身的bug导致的。
使用的时候直接指定CUDA_VISIBLE_DEVICES,通过调整可见显卡的顺序指定加载模型对应的GPU,不要使用torch.cuda.set_device(),不要给.cuda()赋值,不要给torch.nn.DataParallel中的device_ids赋值。比如想在GPU1,2,3中运行,其中GPU2是存放模型的显卡,那么直接设置
CUDA_VISIBLE_DEVICES=2,1,3
Pytorch管方的github提供了examples仓库:[examples](https://github.com/pytorch/examples)可以有很多例子进行学习
1.2 torch.nn.parallel.DistributedDataParallel
我们以Pytorch官方github给的resnet的代码为例进行理解:
- 分布式训练的第一步是需要设置分布式进程组,设置多机通信后端、本机IP端口号,节点总数、本机编号等信息。
import torch.distributed as dist
dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url,world_size=args.world_size, rank=args.rank)
##将分布式参数传递到dist.init_process_group
#确认是否初始化完成
torch.distributed.is_initialized()
一些常用的torch.distributed的功能函数:
torch.distributed.get_backend() #Returns the backend of the given process group
#Returns the rank of the current process in the provided group
torch.distributed.get_rank()
#Returns the number of processes in the current process group
torch.distributed.get_world_size
parser.add_argument('--world-size', default=-1, type=int,
help='number of nodes for distributed training')
parser.add_argument('--rank', default=-1, type=int,
help='node rank for distributed training')
parser.add_argument('--dist-url', default='tcp://224.66.41.62:23456', type=str,
help='url used to set up distributed training')
parser.add_argument('--dist-backend', default='nccl', type=str,
help='distributed backend')
parser.add_argument('--seed', default=None, type=int,
help='seed for initializing training. ')
parser.add_argument('--gpu', default=None, type=int,
help='GPU id to use.')
parser.add_argument('--multiprocessing-distributed', action='store_true',
help='Use multi-processing distributed training to launch '
'N processes per node, which has N GPUs. This is the '
'fastest way to use PyTorch for either single node or '
'multi node data parallel training')
"""
--world-size:分布式训练的节点数,即机器节点总数
--rank:分布式训练机器节点的编号[0,1,2,3,.....n-1]
--dist-url:default='tcp://224.66.41.62:23456' 本机的IP和端口号,
--dist-backend:多机通信后端,默认使用ncll
--multiprocessing-distributed:是否开启多进程模式(单机,多机都可以开启)
"""
2.分布式进程组初始化完成之后需要将模型进行DDP包装,
##实例化一个多机model
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])
- 数据切分和DataLoader
准备好模型后,需要准备好分布式训练所需要的数据集,在分布式训练任务中(数据并行)多机的DataLoader和普通的dataloader是有区别的,多机需要使用DistributedSampler包装后再通过torch.utils.data.DataLoader实例化成Dataloader。
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]))
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=(train_sampler is None),
num_workers=args.workers, pin_memory=True, sampler=train_sampler)