深度学习常见优化算法,图解AdaGrad、RMSProp,Adam
1. AdaGrad
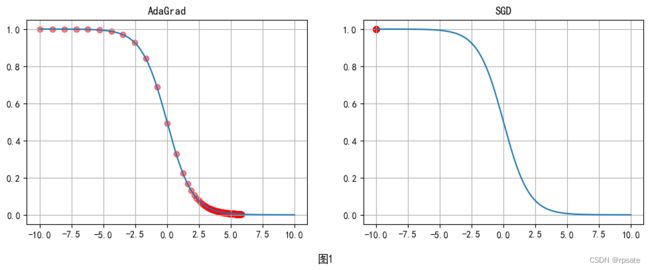
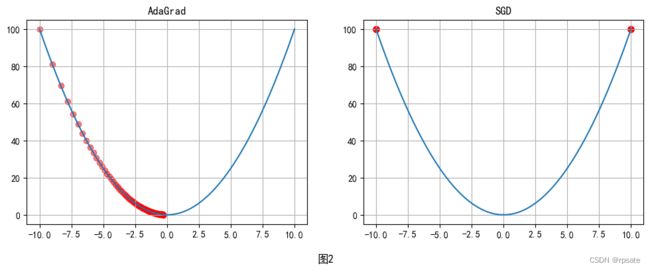
AdaGrad算法是梯度下降法的改进算法,其优点是可以自适应学习率。该优化算法在较为平缓处学习速率大,有比较高的学习效率,在陡峭处学习率小,在一定程度上可以避免越过极小值点。在SDG优化算法中不能自适应学习率,如图1所示,在函数的初始位置比较平缓,利用AdaGrad优化算法可以很快的到达较优点,而SGD几乎没有移动。如图2所示,初始位置比较陡峭,AdaGrad优化算法会自动调整学习率,然后顺利的到达最优点,而SGD在学习率比较大的情况下会在斜坡两边来回摆动。AdaGrad的公式如下:
σ t = 1 t + 1 ∑ i = 0 t ( g i ) 2 \sigma^t=\sqrt{\frac{1}{t+1}\sum^{t}_{i = 0}{(g_i)^2}} σt=t+11i=0∑t(gi)2
θ t + 1 = θ t − η σ t + ψ g t \theta^{t+1}=\theta^t-\frac{\eta}{\sigma^t+\psi}g^t θt+1=θt−σt+ψηgt 其中 g i g_i gi代表函数第 i i i次迭代的梯度, σ t \sigma^t σt就是前面所有梯度的均值平方根。 η \eta η是常数,一般取 1 0 − 7 10^{-7} 10−7,这是为了避免公式中分母为存在等于0的情况。 η \eta η为常数,表示学习率。
演示代码见文章末尾附录部分
2. RMSProp
AdaGrad算法虽然解决了学习率无法根据当前梯度自动调整的问题,但是过于依赖之前的梯度,在梯度突然变化无法快速响应。RMSProp算法为了解决这一问题,在AdaGrad的基础上添加了衰减速率参数。也就是说在当前梯度与之前梯度之间添加了权重,如果当前梯度的权重较大,那么响应速度也就更快。RMSProp公式如下:
σ t = α ( 1 t ∑ i = 0 t − 1 ( g i ) 2 ) + ( 1 − α ) ( g t ) 2 \sigma_t=\sqrt{\alpha(\frac{1}{t}\sum^{t-1}_{i = 0}{(g_i)^2})+(1-\alpha)(g^t)^2} σt=α(t1i=0∑t−1(gi)2)+(1−α)(gt)2
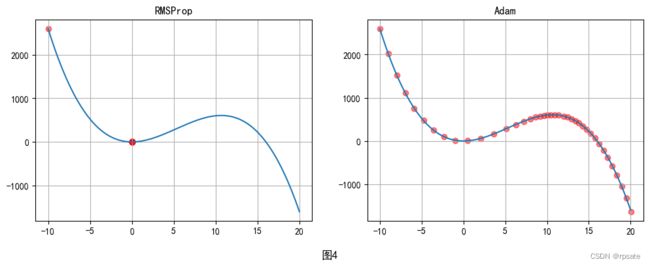
θ t + 1 = θ t − η σ t + ψ g t \theta_{t+1}=\theta_t-\frac{\eta}{\sigma_t+\psi}g^t θt+1=θt−σt+ψηgt 公式中 α \alpha α越大,那么受到之前梯度的影响就越大,AdaGrad算法和RMSProp算法比较如图3所示:

3. Adam
Adam优化算法是在RMSProp的基础上增加了动量。有时候通过RMSProp优化算法得到的值不是最优解,有可能是局部最优解,引入动量的概念时,求最小值就像一个球从高处落下,落到局部最低点时会继续向前探索,有可能得到更小的值,如下图4所示,Adam的公式如下:
m t = β ⋅ m t − 1 + ( 1 − β ) g t − 1 m_t=\beta·m_{t-1}+(1-\beta)g^{t-1} mt=β⋅mt−1+(1−β)gt−1
σ t = α ( 1 t ∑ i = 0 t − 1 ( g i ) 2 ) + ( 1 − α ) ( g t ) 2 \sigma_t=\sqrt{\alpha(\frac{1}{t}\sum^{t-1}_{i = 0}{(g_i)^2})+(1-\alpha)(g^t)^2} σt=α(t1i=0∑t−1(gi)2)+(1−α)(gt)2
θ t = θ t − 1 + η σ t + ψ m t \theta_t=\theta_{t-1}+\frac{\eta}{\sigma_t+\psi}m_t θt=θt−1+σt+ψηmt 其中 m t m_t mt表示第t次迭代时的动量,同时在上一次动量和本次梯度之间加了一个权重系数 β \beta β,当 β \beta β越大,收到上一次动量的影响就越大。
torch.optim.Adam
Adam函数的常用参数如下:
-
params (iterable) – 需要优化的参数,参数类型为迭代器或字典。
-
lr (float, optional) – 学习率 (默认值: 1e-3)
-
betas (Tuple[float, float], optional) – 权重值,分别代表上面公式中的 α \alpha α和 β \beta β (默认值: (0.9, 0.999))
参考文献
[1] 深度学习常见的优化算法
[2] Adam 算法
[3] torch 官方文档
附录
图1代码
import torch
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 初始化变量
adaGrad_x = torch.tensor(-10., requires_grad=True)
sgd_x = torch.tensor(-10., requires_grad=True)
adaGrad_optimizer = torch.optim.Adagrad([adaGrad_x], lr=1)
sgd_optimizer = torch.optim.SGD([sgd_x], lr=1)
# 200次迭代优化
adaGrad_x_record, adaGrad_y_record = [], []
sgd_x_record, sgd_y_record = [], []
for i in range(200):
# AdaGrad
adaGrad_y = 1/(1 + torch.exp(adaGrad_x))
adaGrad_x_record.append(adaGrad_x.detach().item())
adaGrad_y_record.append(adaGrad_y.detach().item())
adaGrad_optimizer.zero_grad()
adaGrad_y.backward()
adaGrad_optimizer.step()
# SGD
sgd_y = 1/(1 + torch.exp(sgd_x))
sgd_x_record.append(sgd_x.detach().item())
sgd_y_record.append(sgd_y.detach().item())
sgd_optimizer.zero_grad()
sgd_y.backward()
sgd_optimizer.step()
# y = 1/(1+e^x)
a = torch.linspace(-10, 10, 1000)
b = 1/(1 + torch.exp(a))
# 创建画布
plt.figure(figsize=(12, 4))
# AdaGrad
plt.subplot(1, 2, 1)
plt.plot(a, b)
plt.scatter(adaGrad_x_record, adaGrad_y_record, c='r', alpha=0.5)
plt.title('AdaGrad')
plt.grid()
# SGD
plt.subplot(1, 2, 2)
plt.plot(a, b)
plt.scatter(sgd_x_record, sgd_y_record , c='r', alpha=0.5)
plt.title('SGD')
plt.grid()
# 显示图片
plt.suptitle('图1', y=0)
plt.show()
图2代码
import torch
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
adaGrad_x = torch.tensor(-10., requires_grad=True)
sgd_x = torch.tensor(-10., requires_grad=True)
adaGrad_optimizer = torch.optim.Adagrad([adaGrad_x], lr=1)
sgd_optimizer = torch.optim.SGD([sgd_x], lr=1)
# 100次迭代优化
adaGrad_x_record, adaGrad_y_record = [], []
sgd_x_record, sgd_y_record = [], []
for i in range(100):
# AdaGrad
adaGrad_y = adaGrad_x ** 2
adaGrad_x_record.append(adaGrad_x.detach().item())
adaGrad_y_record.append(adaGrad_y.detach().item())
adaGrad_optimizer.zero_grad()
adaGrad_y.backward()
adaGrad_optimizer.step()
# SGD
sgd_y = sgd_x ** 2
sgd_x_record.append(sgd_x.detach().item())
sgd_y_record.append(sgd_y.detach().item())
sgd_optimizer.zero_grad()
sgd_y.backward()
sgd_optimizer.step()
# y = x^2
a = torch.linspace(-10, 10, 1000)
b = a ** 2
# 创建画布
plt.figure(figsize=(12, 4))
# AdaGrad
plt.subplot(1, 2, 1)
plt.plot(a, b)
plt.scatter(adaGrad_x_record, adaGrad_y_record, c='r', alpha=0.5)
plt.title('AdaGrad')
plt.grid()
# SGD
plt.subplot(1, 2, 2)
plt.plot(a, b)
plt.scatter(sgd_x_record, sgd_y_record , c='r', alpha=0.5)
plt.title('SGD')
plt.grid()
# 显示图片
plt.suptitle('图2', y=0)
plt.show()
图3代码
import torch
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 初始化变量
adaGrad_x = torch.tensor(-20., requires_grad=True)
rmsProp_x = torch.tensor(-20., requires_grad=True)
adaGrad_optimizer = torch.optim.Adagrad([adaGrad_x], lr=1)
rmsProp_optimizer = torch.optim.RMSprop([rmsProp_x], lr=1)
# 200次迭代优化
adaGrad_x_record, adaGrad_y_record = [], []
rmsProp_x_record, rmsProp_y_record = [], []
for i in range(200):
# AdaGrad
adaGrad_y = 1/(1 + torch.exp(adaGrad_x))
adaGrad_x_record.append(adaGrad_x.detach().item())
adaGrad_y_record.append(adaGrad_y.detach().item())
adaGrad_optimizer.zero_grad()
adaGrad_y.backward()
adaGrad_optimizer.step()
# RMSProp
rmsProp_y = 1/(1 + torch.exp(rmsProp_x))
rmsProp_x_record.append(rmsProp_x.detach().item())
rmsProp_y_record.append(rmsProp_y.detach().item())
rmsProp_optimizer.zero_grad()
rmsProp_y.backward()
rmsProp_optimizer.step()
# y = 1/(1+e^x)
a = torch.linspace(-20, 20, 1000)
b = 1/(1 + torch.exp(a))
# 创建画布
plt.figure(figsize=(12, 4))
# AdaGrad
plt.subplot(1, 2, 1)
plt.plot(a, b)
plt.scatter(adaGrad_x_record, adaGrad_y_record, c='r', alpha=0.5)
plt.title('AdaGrad')
plt.grid()
# RMSProp
plt.subplot(1, 2, 2)
plt.plot(a, b)
plt.scatter(rmsProp_x_record, rmsProp_y_record , c='r', alpha=0.5)
plt.title('RMSProp')
plt.grid()
# 显示图片
plt.suptitle('图3', y=0)
plt.show()
图4代码
import torch
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 初始化变量
rmsProp_x = torch.tensor(-10., requires_grad=True)
adam_x = torch.tensor(-10., requires_grad=True)
rmsProp_optimizer = torch.optim.RMSprop([rmsProp_x], lr=1)
adam_optimizer = torch.optim.Adam([adam_x], lr=1, betas=(0.9, 0.61))
# 40次迭代优化
rmsProp_x_record, rmsProp_y_record = [], []
adam_x_record, adam_y_record = [], []
for i in range(40):
# RMSProp
rmsProp_y = 16 * rmsProp_x ** 2 - rmsProp_x ** 3
rmsProp_x_record.append(rmsProp_x.detach().item())
rmsProp_y_record.append(rmsProp_y.detach().item())
rmsProp_optimizer.zero_grad()
rmsProp_y.backward()
rmsProp_optimizer.step()
# Adam
adam_y = 16 * adam_x ** 2 - adam_x ** 3
adam_x_record.append(adam_x.detach().item())
adam_y_record.append(adam_y.detach().item())
adam_optimizer.zero_grad()
adam_y.backward()
adam_optimizer.step()
# y = 16*x^2-x^3
a = torch.linspace(-10., 20., 1000)
b = 16 * a ** 2 - a ** 3
# 创建画布
plt.figure(figsize=(12, 4))
# RMSProp
plt.subplot(1, 2, 1)
plt.plot(a, b)
plt.scatter(rmsProp_x_record, rmsProp_y_record, c='r', alpha=0.5)
plt.title('RMSProp')
plt.grid()
# Adam
plt.subplot(1, 2, 2)
plt.plot(a, b)
plt.scatter(adam_x_record, adam_y_record , c='r', alpha=0.5)
plt.title('Adam')
plt.grid()
# 显示图片
plt.suptitle('图4', y=0)
plt.show()