在envi做随机森林_异常检测怎么做,试试孤立随机森林算法(附代码)

异常检测看似是机器学习中一个有些难度的问题,但采用合适的算法也可以很好解决。本文介绍了孤立森林(isolation forest)算法,通过介绍原理和代码教你揪出数据集中的那些异常值。
选自blog.paperspace,作者:Dhiraj K,机器之心编译,参与:李诗萌、一鸣。

从银行欺诈到预防性的机器维护,异常检测是机器学习中非常有效且普遍的应用。在该任务中,孤立森林算法是简单而有效的选择。
本文内容包括:
- 介绍异常检测;
- 异常检测的用例;
- 孤立森林是什么;
- 用孤立森林进行异常检测;
- 用 Python 实现。
异常检测简介
离群值是在给定数据集中,与其他数据点显著不同的数据点。
异常检测是找出数据中离群值(和大多数数据点显著不同的数据点)的过程。
真实世界中的大型数据集的模式可能非常复杂,很难通过查看数据就发现其模式。这就是为什么异常检测的研究是机器学习中极其重要的应用。
本文要用孤立森林实现异常检测。我们有一个简单的工资数据集,其中一些工资是异常的。目标是要找到这些异常值。可以想象成,公司中的一些雇员挣了一大笔不同寻常的巨额收入,这可能意味着存在不道德的行为。
在继续实现之前,先讨论一些异常检测的用例。
异常检测用例
异常检测在业界中应用广泛。下面介绍一场常见的用例:
银行:发现不正常的高额存款。每个账户持有人通常都有固定的存款模式。如果这个模式出现了异常值,那么银行就要检测并分析这种异常(比如洗钱)。
金融:发现欺诈性购买的模式。每个人通常都有固定的购买模式。如果这种模式出现了异常值,银行需要检测出这种异常,从而分析其潜在的欺诈行为。
卫生保健:检测欺诈性保险的索赔和付款。
制造业:可以监测机器的异常行为,从而控制成本。许多公司持续监视着机器的输入和输出参数。众所周知,在出现故障之前,机器的输入或输出参数会有异常。从预防性维护的角度出发,需要对机器进行持续监控。
网络:检测网络入侵。任何对外开放的网络都面临这样的威胁。监控网络中的异常活动,可以及早防止入侵。
接着了解一下机器学习中的孤立森林算法。
什么是孤立森林
孤立森林是用于异常检测的机器学习算法。这是一种无监督学习算法,通过隔离数据中的离群值识别异常。
孤立森林是基于决策树的算法。从给定的特征集合中随机选择特征,然后在特征的最大值和最小值间随机选择一个分割值,来隔离离群值。这种特征的随机划分会使异常数据点在树中生成的路径更短,从而将它们和其他数据分开。
一般而言,异常检测的第一步是构造「正常」内容,然后报告任何不能视为正常的异常内容。但孤立森林算法不同于这一原理,首先它不会定义「正常」行为,而且也没有计算基于点的距离。
一如其名,孤立森林不通过显式地隔离异常,它隔离了数据集中的异常点。
孤立森林的原理是:异常值是少量且不同的观测值,因此更易于识别。孤立森林集成了孤立树,在给定的数据点中隔离异常值。
孤立森林通过随机选择特征,然后随机选择特征的分割值,递归地生成数据集的分区。和数据集中「正常」的点相比,要隔离的异常值所需的随机分区更少,因此异常值是树中路径更短的点,路径长度是从根节点经过的边数。
用孤立森林,不仅可以更快地检测异常,还需要更少的内存。
孤立森林隔离数据点中的异常值,而不是分析正常的数据点。和其他正常的数据点相比,异常数据点的树路径更短,因此在孤立森林中的树不需要太大的深度,所以可以用更小的 max_depth 值,从而降低内存需求。
这一算法也适用于小数据集。
接着我们对数据做一些探索性分析,以了解给定数据的相关信息。
探索性数据分析
先导入所需的库。导入 numpy、pandas、seaborn 和 matplotlib。此外还要从 sklearn.ensemble 中导入孤立森林(IsolationForest)。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest导入库后,要将 csv 数据读取为 padas 数据框,检查前十行数据。
本文所用数据是不同职业的人的年薪(美元)。数据中有一些异常值(比如工资太高或太低),目标是检测这些异常值。
df = pd.read_csv('salary.csv')
df.head(10)
为了更好地了解数据,将工资数据绘制成小提琴图,如下图所示。小提琴图是一种绘制数值数据的方法。
通常,小提琴图包含箱图中所有数据——中位数的标记和四分位距的框或标记,如果样本数量不太大,图中可能还包括所有样本点。
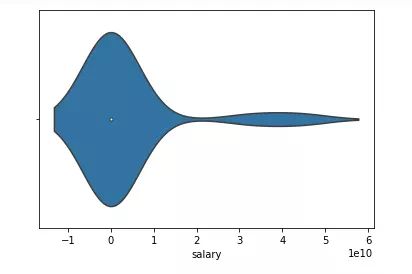
为了更好地了解离群值,可能还会查看箱图。箱图一般也称为箱线图。箱图中的箱子显示了数据集的四分位数,线表示剩余的分布。线不表示确定为离群值的点。
我们通过 interquartile range, 的函数检测离群值。在统计数据中,interquartile range,(也称为 midspread 或 middle 50%)是度量统计学分散度的指标,等于第 75% 个数和第 25% 个数的差。

完成数据的探索性分析后,就可以定义并拟合模型了。
定义及拟合模型
我们要创建一个模型变量,并实例化 IsolationForest(孤立森林)类。将这四个参数的值传递到孤立森林方法中,如下所示。
- 评估器数量:n_estimators 表示集成的基评估器或树的数量,即孤立森林中树的数量。这是一个可调的整数参数,默认值是 100;
- 最大样本:max_samples 是训练每个基评估器的样本的数量。如果 max_samples 比样本量更大,那么会用所用样本训练所有树。max_samples 的默认值是『auto』。如果值为『auto』的话,那么 max_samples=min(256, n_samples);
- 数据污染问题:算法对这个参数非常敏感,它指的是数据集中离群值的期望比例,根据样本得分拟合定义阈值时使用。默认值是『auto』。如果取『auto』值,则根据孤立森林的原始论文定义阈值;
- 最大特征:所有基评估器都不是用数据集中所有特征训练的。这是从所有特征中提出的、用于训练每个基评估器或树的特征数量。该参数的默认值是 1。
model=IsolationForest(n_estimators=50, max_samples='auto', contamination=float(0.1),max_features=1.0)
model.fit(df[['salary']])
数据训练模型了,这是用 fit() 方法实现的。这个方法要传入一个参数——使用的数据(在本例中,是数据集中的工资列)。
正确训练模型后,将会输出孤立森林实例(如图所示)。现在可以添加分数和数据集的异常列了。
添加分数和异常列
在定义和拟合完模型后,找到分数和异常列。对训练后的模型调用 decision_function(),并传入工资作为参数,找出分数列的值。
类似的,可以对训练后的模型调用 predict() 函数,并传入工资作为参数,找到异常列的值。
将这两列添加到数据框 df 中。添加完这两列后,查看数据框。如我们所料,数据框现在有三列:工资、分数和异常值。分数列中的负值和异常列中的 -1 表示出现异常。异常列中的 1 表示正常数据。
这个算法给训练集中的每个数据点都分配了异常分数。可以定义阈值,根据异常分数,如果分数高于预定义的阈值,就可以将这个数据点标记为异常。
df['scores']=model.decision_function(df[['salary']])
df['anomaly']=model.predict(df[['salary']])
df.head(20)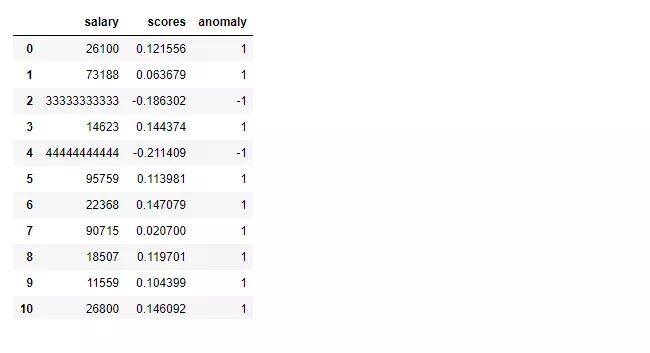
打印异常
为了打印数据中预测得到的异常,在添加分数列和异常列后要分析数据。如前文所述,预测的异常在预测列中的值为 -1,分数为负数。根据这一信息,将预测的异常(本例中是两个数据点)打印如下。
anomaly=df.loc[df['anomaly']==-1]
anomaly_index=list(anomaly.index)
print(anomaly)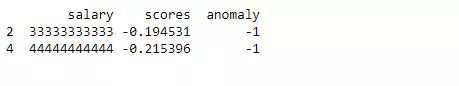
注意,这样不仅能打印异常值,还能打印异常值在数据集中的索引,这对于进一步处理是很有用的。
评估模型
为了评估模型,将阈值设置为工资>99999 的为离群值。用以下代码找出数据中存在的离群值:
outliers_counter = len(df[df['salary'] > 99999])
outliers_counter计算模型找到的离群值数量除以数据中的离群值数量,得到模型的准确率。
print("Accuracy percentage:", 100*list(df['anomaly']).count(-1)/(outliers_counter))准确率:100%
尾注
本教程内容包括:什么是离群值以及如何用孤立森林算法检测离群值。还讨论了针对该问题的不同的探索性数据分析图,比如小提琴图和箱图。
最终我们实现了孤立森林算法,并打印出了数据中真正的离群值。希望你喜欢这篇文章,并希望这篇文章能在未来的项目中帮到你。