计算机视觉——目标检测入门级综述
计算机视觉——目标检测
- 背景与动机
-
- 目标检测任务
- 深度学习发展历程
- 目标检测发展历程
- 卷积神经网络
-
- 输入层
- 卷积层
- 池化层
- 全连接层
- 卷积神经网络经典模型
- 目标检测经典算法
-
- R-CNN(CVPR2014)
-
- 1、获得候选区域
- 2、特征提取
- 3、SVM分类
- 4、剔除重叠框(非极大值抑制)
- 5、精准定位
- 结果
- 不足
- SPP-NET(ECCV 2014)
-
- 改进1:全图一次CNN
- 改进2:空间金字塔池化层
- 结果
- 不足
- Fast R-CNN(ICCV 2015)
-
- 主要结构
- 结果
- Faster R-CNN(NIPS 2015)
-
- 主要结构
- 创新点
- 结果
- R-FCN(CVPR 2016)
-
- 主要结构
- 结果
- 优点
- FPN (CVPR2017)
-
- 主要改进
- 优点
- Mask R-CNN (CVPR2017)
-
- 主要结构
- 结果
- 现状与发展
-
- 2017-2018
- 2018-2019
背景与动机
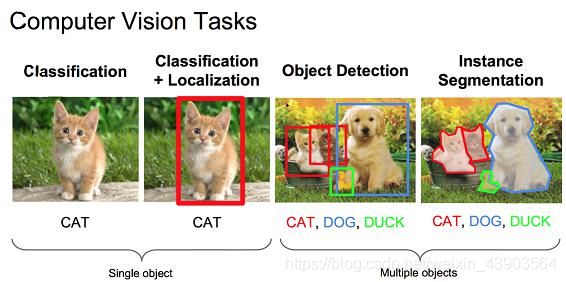
目标检测任务
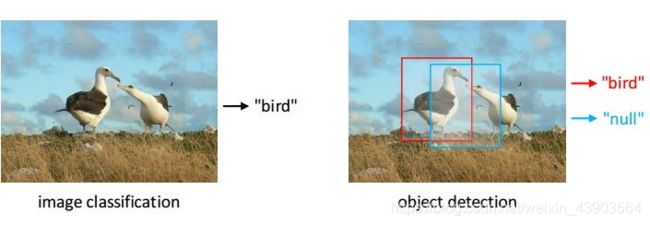
首先理解什么是目标检测任务,它与图片分类有何区别?

理解目标检测算法就要先明确它的输入和输出:
输入:原始图片
输出:是什么?(类别)在哪里?(位置)
与图片识别(分类)的区别在于,目标检测任务还要将物体具体的位置标出。如上图,不同颜色的框内标记着检测出的不同类型的物体,有自行车、人汽车、摩托车、信号灯等。每一个框都有一个标签,里面标注了物体的类别,以及该物体为此类别的置信度/概率。
深度学习发展历程
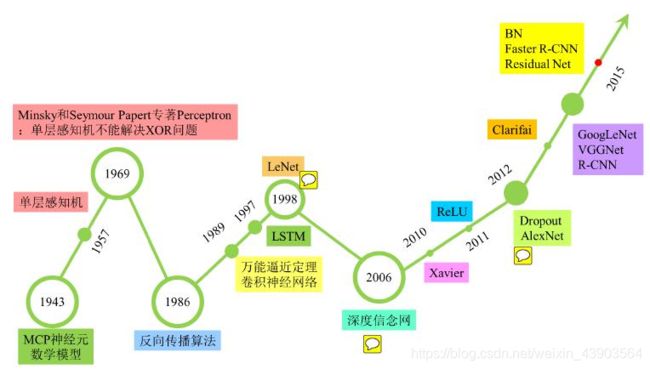

目前使用深度学习对图片进行处理已经非常成熟,准确率已接近人类的认知水平。
目标检测发展历程
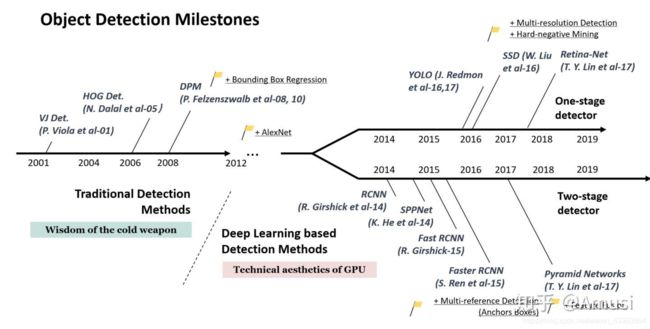
2012年,AlexNet网络提出,是卷积神经网络发展也是深度学习发展的分水岭。2014年,深度学习正式用于目标检测任务。
卷积神经网络
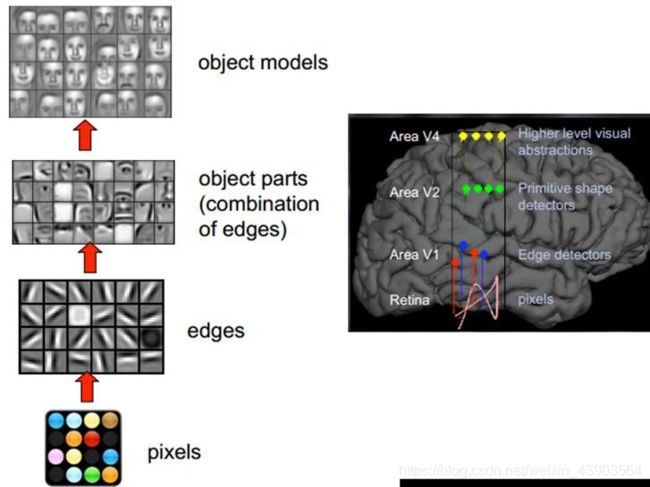
卷积神经网络是人类视觉原理的一种体现,即可视皮层是分级的。主要过程为:
视网膜输入原始信号->摄入像素
大脑皮层初步处理->边缘和方向
抽象->形状
进一步抽象->物体

最早的卷积神经网络是YannLeCun提出的LeNet,应用于手写数字识别。主要包含:输入层、卷积层、池化层、全连接层。
输入层
在全连接神经网络中,输入时由图片像素组成的一个向量。
在卷积网络中输入的是一个图片的矩阵形式,它保留了图片的空间结构信息。

卷积层
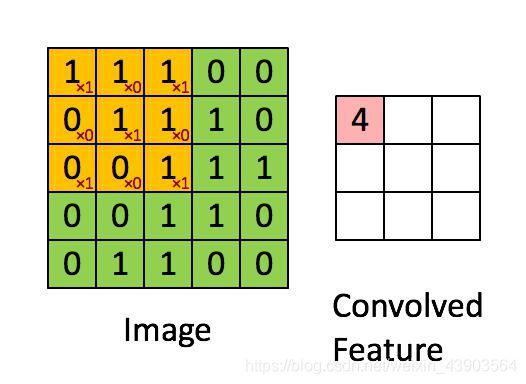
卷积层是卷积网络的核心组件,其主要作用是从输入中提取特征。
特点:权值共享、局部连接。

池化层
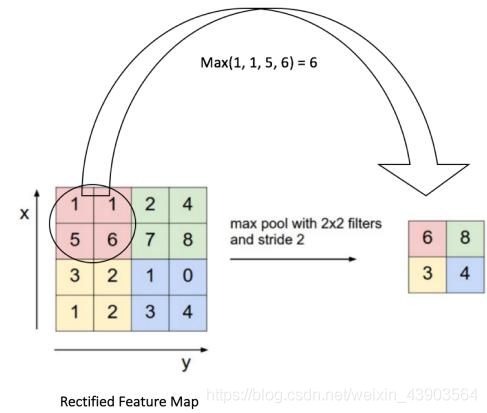
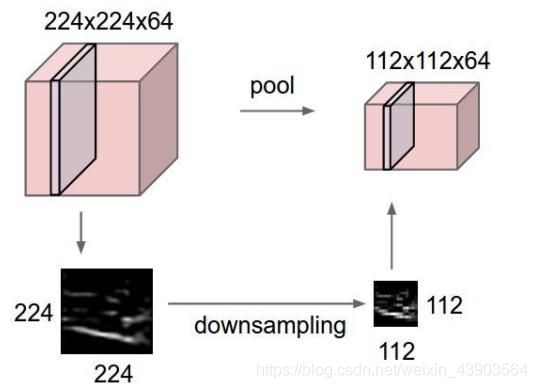
用于降低特征图的维度。
保留最重要的信息,减少了噪声,防止过拟合。
使网络具有一定的平移不变性(图像中的目标不管被移动到图片的哪个位置,得到的标签应该是相同的)。
常见的池化有最大池化和平均池化,池化对应图像的下采样。
全连接层
最初的CNN使用全连接层,用于整合前面学习到的特征,通过非线性组合得到更高级的特征,即从隐层特征空间映射到样本标记空间。
但是全连接层存在问题,就是要求输入的特征图尺度必须固定。因为全连接层部分的参数是神经元对于所有输入的连接权重,若输入尺寸不固定,全连接层参数的个数则无法固定。
卷积神经网络经典模型
开山之作:LeNet-1998

王者归来:AlexNet-2012
稳步前行:ZFNet-2013
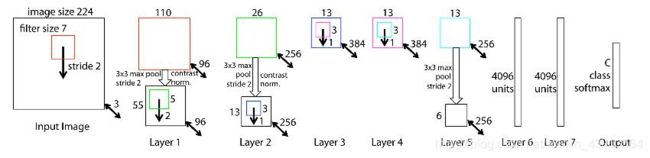
越走越深:VGGNet-2014
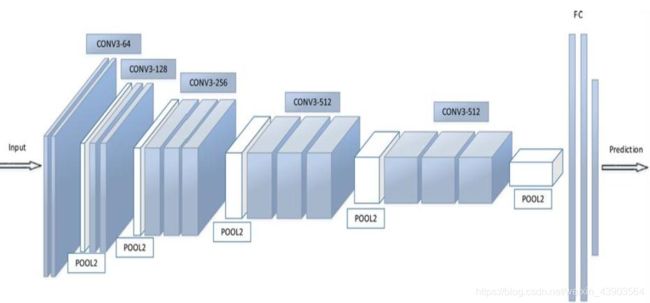
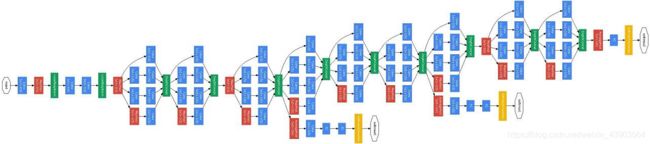
大浪推手:GoogLeNet-2014
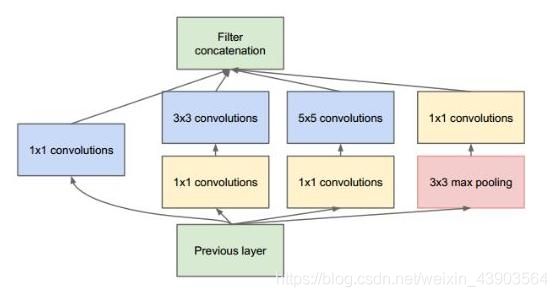
闪光点:
1、引入Inception结构;
2、中间层的辅助LOSS单元;
3、后面的全连接层全部替换为简单的全局平均pooling。
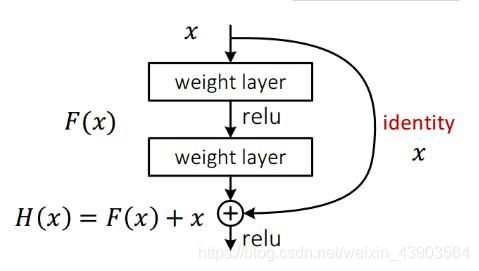
里程碑式创新:ResNet-2015

闪光点:
1、层数非常深,已经超过百层。
2、引入残差单元(如下图)来解决退化问题。
继往开来:DenseNet-2016
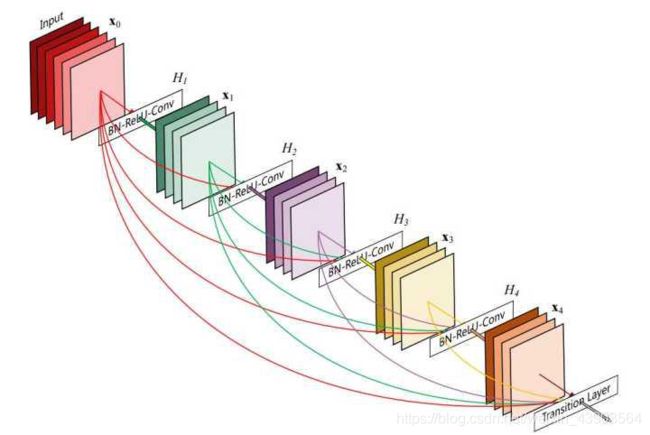
闪光点:
密集连接,缓解梯度消失问题,加强特征传播,鼓励特征复用,极大的减少了参数量。
目标检测经典算法

目标检测在发展上分为两类,一类是双阶段,一类是单阶段。区别在于双阶段是先划分区域再进行目标检测,即先定位再分类,单阶段为同时进行。
准备知识:
目标检测与图片分类区别:目标检测=对图片内所有物体分类+定位
性能指标:mAP——物体类别和位置的平均精度
数据集:
检测(PASCAL VOC 2007):一万张图像,20种类别。
检测(MS COCO 2014):二十万张图像,80种类别。
识别(ImageNet ILSVC 2012):一千万张图像,1000种类别。
IOU:定义了两个bounding box的重叠度。
矩形框A、B的一个重合度IOU计算公式为(定位精度评价公式):IOU=(A∩B)/(A∪B)。

R-CNN(CVPR2014)
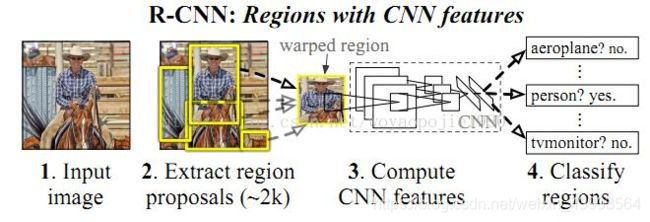
1、利用selective search(一个已有的算法)得到若干候选区域(2012 IJCV)。
2、对每个候选区域(2k个,由于使用AlexNet,有全连接层,需要放缩变换)分别使用CNN提取特征(存到硬盘)。
3、对每个候选区域提取的特征向量使用SVM进行分类(二分类,是和否)。
4、非极大值抑制,提出重叠框。
5、精准定位(回归器)。
具体步骤如下:
1、获得候选区域
传统方法:窗口滑动,改变尺寸大小,对每个小方格判断是不是物体。
selective search:
①通过简单的区域划分算法,将图片划分成很多小区域(过分割)。
②通过相似度和区域大小不断的聚合相邻小区域,重复直到整张图像合并成一个区域。
③多样化后处理。
④输出所有曾经存在过的区域,所谓候选区域。
注:相似度计算=颜色相似度,纹理相似度,大小相似度,吻合相似度

2、特征提取

输入:2000个候选区域
架构: 5个卷积层和2个全连接层的AlexNet
输出:4096维的特征向量(针对每一个候选区域)
存在全连接层,所以要固定输入大小的尺寸,由于候选区域是大小不同的矩形,所以在输入网络之前需要做一次放缩变换。
3、SVM分类
分类:单独训练SVM分类器,得到一个2000×21维的矩阵。
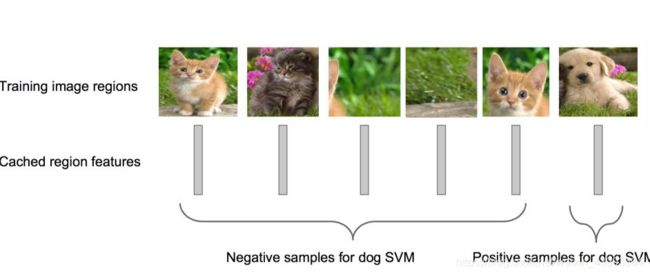
4、剔除重叠框(非极大值抑制)

① 对2000×21维矩阵中每列按从大到小进行排序;
② 从每列最大的得分建议框开始,分别与该列后面的得分建议框进行IoU计算,若IoU>阈值,则剔除得分较小的建议框 ,否则认为图像中存在多个同一类物体;
③ 从每列次大的得分建议框开始,重复步骤②;
④ 重复步骤③直到遍历完该列所有建议框;
⑤ 遍历完2000×21维矩阵所有列,即所有物体种类都做一 遍非极大值抑制;
⑥ 最后剔除各个类别中剩余建议框得分少于该类别阈值的建议框。
5、精准定位

图上的黄色框即为非极大值抑制的结果,绿色框是ground truth。
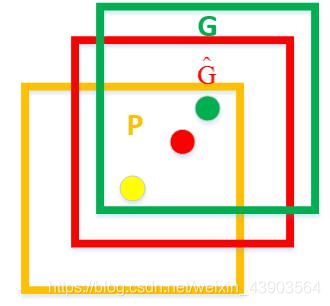
黄色框口P表示Region Proposal
绿色窗口G表示Ground Truth
红色窗口Ĝ表示Region Proposal进行回归后的预测窗口
采用回归器是为了对建议框进行校正,使得校正后的Region Proposal与Ground Truth更接近 , 以提高最终的检测精度。论文中采用bounding-box回归使mAP提高了3~4%。
结果
1、PASCAL VOC 2010 53.7%的mAP;
2、PASCAL VOC 2012 53.3%的mAP;
3、计算Region Proposals和features平均所花时间:13s/image on a GPU; 53s/image on a CPU。
不足
1、多阶段,处理一张图片慢,占用大量内存
2、需要对图片进行缩放裁剪,易失真
SPP-NET(ECCV 2014)
动机:针对R-CNN的两个不足进行改进。
改进1:全图一次CNN
对全图进行一次CNN,而不是采用局部多次CNN。
SPPNet通过可视化Conv5层特征图,发现卷积特征其实保存了空间位置信息,并且每一个卷积核负责提取不同的特征,比如下图175、55卷积核的特征,其中175负责提取窗口特征,55负责提取圆形的类似于车轮的特征。(feature maps与原图存在映射关系)
spp-net仅对全图进行一次特征提取,通过映射关系来找到特征图上对应的每个候选区域框的特征向量。与R-CNN对比如下: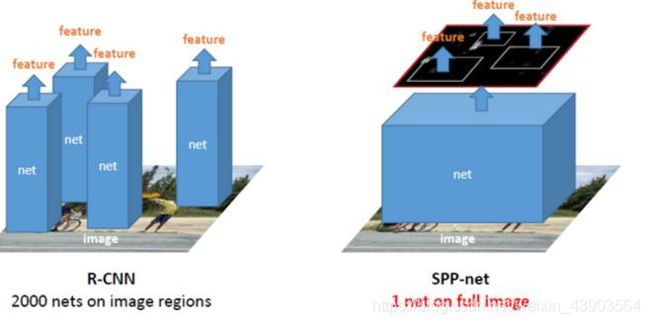
改进2:空间金字塔池化层
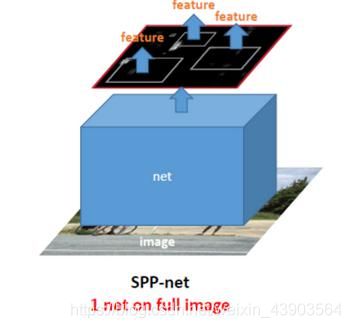
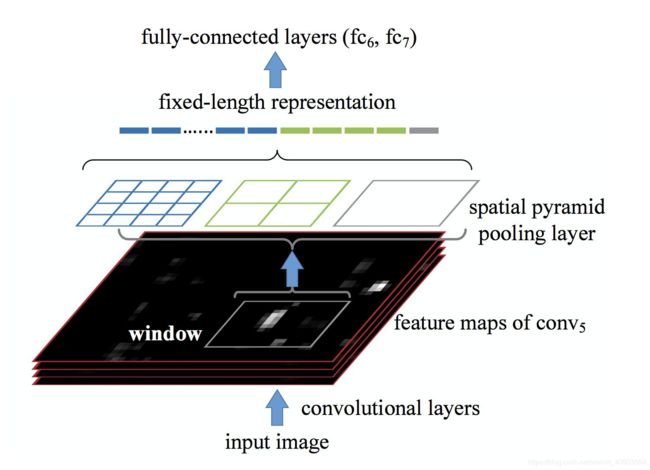
解决R-CNN的问题:
①一次cnn操作,共享计算,减少时间(ZFNet)。
②可以向cnn输入任意尺度图片,同时输出大小始终是固定的。
③实现多尺度提取特征
ss得到候选区域->一次特征提取->svm分类器->边框回归
结果
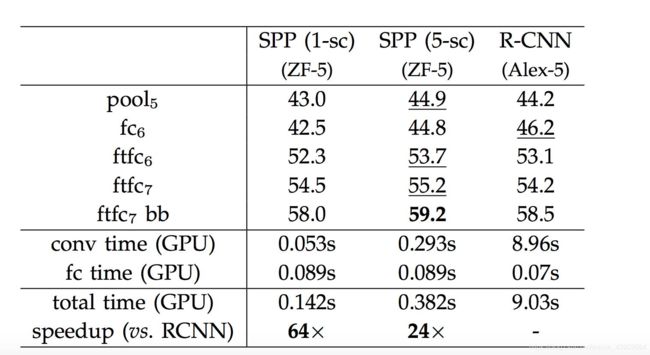
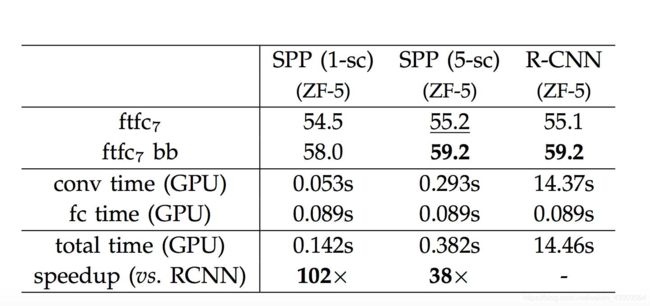
准确率从58.5提高到了59.2,没有太大提高,但是速度快了24x。
不足
多阶段,特征也要存储在硬盘中,需要巨大存储空间。
Fast R-CNN(ICCV 2015)
主要结构
通过多任务损失函数解决训练多阶段问题 :
1、通过ss得到候选区域。
2、一次卷积操作得到各候选区域的特征向量,再通过 ROI pooling 层(金字塔池化层)得到固定长度输出到全连接层,经过全连接层,直接分为两路执行多目标训练,一路是分类(softmax),另一路边框回归(regressor)。 实际上就是将分类和回归归为同一阶段。
让人们看到了Region Proposal+CNN这一框架实时检测的希望

多任务损失函数: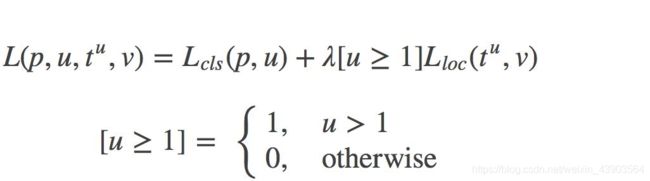
分类:
定位:

结果
精度:
速度:
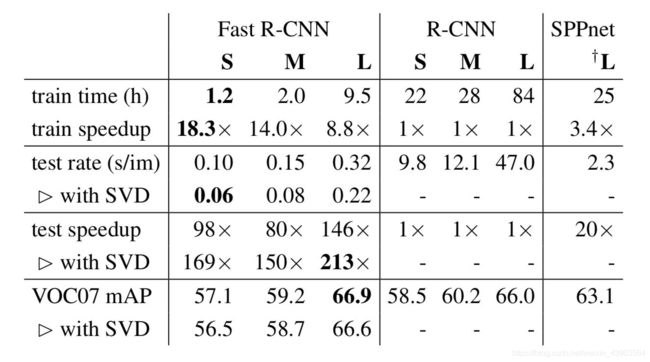
可见精度还是提高很多的。
Faster R-CNN(NIPS 2015)
动机:继Fast R-CNN后,在CPU上实现的Region Proposal的算法Selective Search成了物体检测速度提升上的最大瓶颈。region proposal需要2-3s,分类只需要0.32s,无法满足实时应用。
主要结构
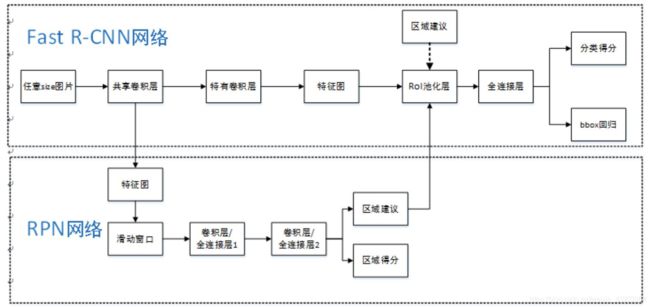
Faster R-CNN=RPN+Fast R-CNN
创新点
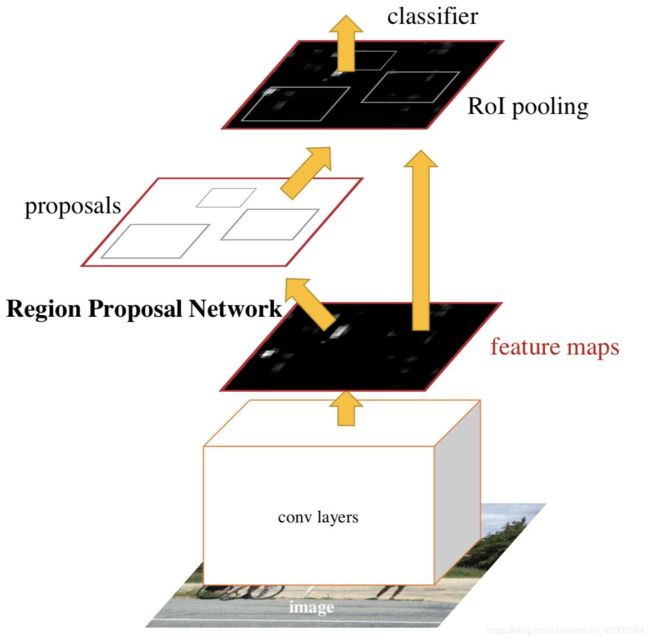
1、设计Region Proposal Network (RPN),利用CNN卷积操作后 的特征图生成候选框,代替了 Selective Search方法,速度上提 升明显(10ms)。
2、训练RPN与Fast R-CNN共享卷积层,大幅提高网络的检测速度。 实现了端到端的检测。
从候选区域的产生->分类->定位都在一个系统下完成, 实现端到端实时检测。
RPN具体做法如下:
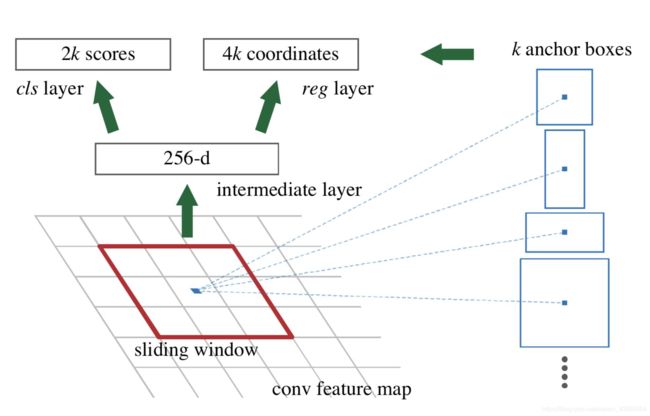
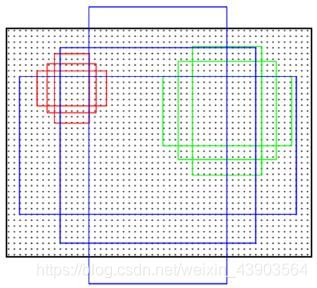
使用滑动窗口,对一个像素点给予9个anchor box,例如面积为{1282,2562,5122},比例分别为 {1:1,1:2,2:1}的9个anchor box。使用全卷积神经网络训练,对框内是否有物体进行评分,最终得出候选框。
结果
检测时间:
①Fast R-cnn :区域建议2-3s 检测320ms
② Faster R-cnn:198ms
检测精度(map):
① Fast R-cnn:在VGG网络准确率达70%
② Faster R-cnn :在VGG网络准确率达78.8%
之后提出的新模型分别针对不同方面进行了改进。
R-FCN(CVPR 2016)
该模型针对感兴趣局域的分类过程进行完善。
基础网络:ResNet
动机:目标检测不仅需要检测还需要定位,当网络层数越来越深时,优点是可以增加语义信息,使分类更加准确,缺点是会丢失位置信息,定位精度下降。那么该如何利用好分类网络性能,解决这一矛盾?R-FCN提出了Position-sensitive score maps来解决这一问题。
主要结构

1、RPN网络提取ROI(感兴趣区域)
2、KK(C+1)维的位置敏感得分映射-> 位置敏感的ROI Pooling->类别信息
3、KK4维的位置敏感得分映射-> 位置敏感的ROI Pooling->位置信息
锁定物体:
偏离物体:

结果
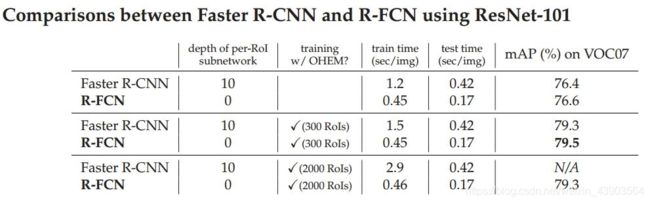
优点
1、节约计算:取消全连接层,卷积层全部共享。
2、位置敏感。
FPN (CVPR2017)
针对更精确的RPN进行改进。
主要改进
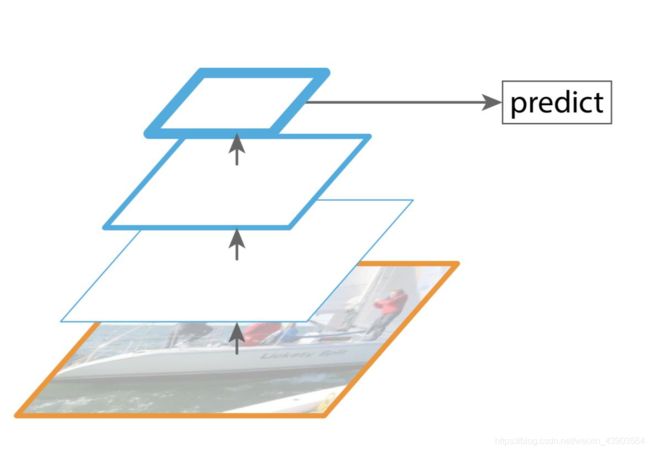
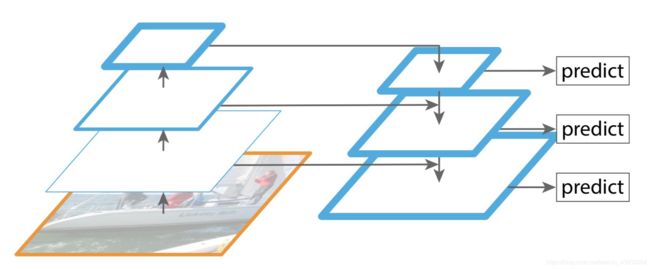
FPN的主要改进是:兼顾低层&高层特征,顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的。
自底向上:CNN前向传播
自顶向下:上采样
横向连接:将上采样的结果和自底向上生成的相同大小的feature map进行融合
优点
小物体检测提升明显
Mask R-CNN (CVPR2017)
针对ROI分类进行完善。
主要结构
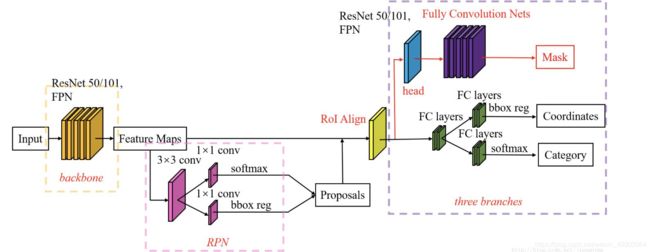
Mask R-CNN=Faster R-CNN+FPN+FCN,将图像分类、检测和分割合为一体。
结果
实例分割:(对分割也有提升)
目标检测:

现状与发展
2017-2018
►小物体检测
Feature Pyramid Networks for Object Detection (CVPR 2017 )
Beyond Skip Connections Top Down Modulation for Object Detection(CVPR 2017)
►不规则形状物体的检测
Deformable Convolutional Networks(ICCV 2017 )
►解决正负样本不均衡的问题
Focal Loss for Dense Object Detection(ICCV 2017)
Chained Cascade Network for Object Detection(ICCV 2017)
►被遮挡物体检测
Soft-NMS – Improving Object Detection With One Line of Code(ICCV 2017)
►关注物体之间关联性信息
Relation Networks for Object Detection(CVPR 2018)
►创新网络结构
DetNet: A Backbone network for Object Detection(ECCV2018)
RefineDet:Single-Shot Refinement Neural Network for Object Detection(CVPR 2018)
Pelee: A Real-Time Object Detection System on Mobile Devices(CVPR 2018)
CornerNet: Detecting Objects as Paired Keypoints(ECCV2018)
2018-2019
► 样本不平衡问题
Is Sampling Heuristics Necessary in Training Deep Object Detectors?(2019 arXiv)
ResObj:Residual Objectness for Imbalance Reduction(2019 arXiv )
DR Loss: Improving Object Detection by Distributional Ranking (2019 ICCV)
GHM:Gradient Harmonized Single-stage Detector(2019 AAAI)
► 多尺度问题(样本选择和FPN特征选择)
FSAF:Feature Selective Anchor-Free Module for Single-Shot Object Detection(CVPR 2019)
SAPD:Soft Anchor-Point Object Detection(CVPR 2020)
► 基于模型搜索(NAS)
NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection(2019 CVPR)
EfficientDet: Scalable and Efficient Object Detection(2019)
SM-NAS: Structural-to-Modular Neural Architecture Search for Object Detection (AAAI 2020)
NAS-FCOS: Fast Neural Architecture Search for Object Detectio(2019)
► 轻量实时
ThunderNet: Towards Real-time Generic Object Detection(2019 ICCV)