中科大的AI图像/视频编解码综述
【前言】
长论文ptsd犯病了,这次是一篇35页的AI编解码器的综述,犯病了犯病了。
首先还是保命时刻,以下解读与见解均为我的个人理解,要是我有哪里曲解了,造成了不必要的麻烦,可以联系我删除文章,也可以在评论区留言,我进行修改。也欢迎大家在评论区进行交流,要是有什么有意思的paper也可以留言,我抽空看一下也可以写一些。正文内容中的“作者”二字,均是指paper的作者,我的个人观点会显式的“我”注明。而文中的图基本都是从paper上cv过来的,我也没本事重做这么多的图,况且作者的图弄得还挺好看的。
【Paper基本信息】
题目:Deep Learning-Based Video Coding: A Review and a Case Study
作者:Dong Liu, Yue Li, Jianping Lin, Houqiang Li, Feng Wu, 是来自中科大的团队
链接:Deep Learning-Based Video Coding: A Review and a Case Studydoi.org
总结:回顾了使用深度学习进行图像/视频编解码的代表性工作。
PS: 黑话表(看不懂的缩写可以自行对照)
Paper具体内容
【Introduction】
1. 图像/视频编码
编码这个不细说了,大家用过电脑都知道是怎么回事。这里主要说一下,压缩不能确保能从比特流中完美重建图像/视频,因此分为无损和有损压缩两种。对于自然图像/视频,无损压缩的压缩效率太低了,不值当,所以基本都用的有损压缩。而有损的图像/视频编码方案,一般从两个方面来进行评估:
- 压缩效率,通常用位数(编码率)来衡量,是越少越少
- 损失,通常通过重建图像/视频跟原始的图像/视频相比的质量来衡量,是越高越好
国际标准化组织中,ISO/IEC有两个专家组,JPEG和MPEG,ITUT则有自己的专家组VCEG。现在比较主流、著名的标准都是他们发布的,例如:JPEG、JPEG 2000、H.262(MPEG-2 Part 2)、H.264(MPEG-4 Part 10或AVC)、H.265(MPEG-H Part 2或HEVC),现在主流的是13年发布的H.265/HEVC。
但是随着视频技术的进步,超高清视频的普及,迫切的需要进一步提高压缩效率,来适应有限的存储和有限的带宽。所以在HEVC后,JPEG跟MPEG组成了联合专家组JVET来探索先进的视频编码技术。他们提出了一种叫做VVC的标准,用作HEVC的继任者。跟HEVC相比,VVC可以在质量相同的情况下,节省大于50%的比特来提高压缩效率,但是代价是以乘法编解码的复杂度来实现的。
2. 深度学习的图像/视频编码
CNN的背景啥的就不说了,说跟编解码有关的,其实从上世纪八九十年代就已经有研究人员研究用人工神经网络对图像/视频编码了,但那时候深度学习都还没火,英伟达的核弹都还没出生,怎么可能搞得起来。至少都得到了15年才开始蓬勃发展起来。因此作者的这篇paper主要就是回顾了2018年底之前的基于深度学习的图像/视频编码报告,并展示了他们的一个深度学习视频编码(DLVC)的研究例子。(PS:这篇综述统计的不是太新,但是对于入门了解这个领域来说我觉得够使了)
3. 前置知识
这里要提前说明一下,作者考虑的是自然图像/视频的编码方法,不考虑其它类型的(例如生物医学、遥感)图像/视频。
一般来说,几乎所有的自然图像/视频都是数字格式的
灰度图像,可以表示成![]() ,其中
,其中 和
和 分别是图像的行数(高)和列数(宽),
分别是图像的行数(高)和列数(宽),![]() 则是单个图像像素的定义域,比如说
则是单个图像像素的定义域,比如说![]() ,这里
,这里![]() ,因此像素值可以用8比特的整数来表示。因此未压缩的数字图像每像素有8比特,那么压缩后的比特数肯定就是更少的了。
,因此像素值可以用8比特的整数来表示。因此未压缩的数字图像每像素有8比特,那么压缩后的比特数肯定就是更少的了。
彩色图像,一般彩色的图会分开成多个通道来记录颜色信息,例如RGB色彩空间,彩色图像可以表示成![]() ,其中3对应着红绿蓝三个通道。但是因为人的颜色对亮度比对色度更敏感,所以YCbCr(YUV)色彩空间用的比RGB要多,而且U和V通道可以被下采样进行压缩。在YUV420颜色格式中,彩色图像可以表示成
,其中3对应着红绿蓝三个通道。但是因为人的颜色对亮度比对色度更敏感,所以YCbCr(YUV)色彩空间用的比RGB要多,而且U和V通道可以被下采样进行压缩。在YUV420颜色格式中,彩色图像可以表示成![]() 。
。
彩色视频,由多个彩色图像组成,称为帧。用以记录不同时间戳的场景。例如在YUV420颜色格式中,彩色视频可以表示成![]() ,其中T是帧数,
,其中T是帧数,![]() ,假设
,假设![]() ,
,![]() ,
,![]() ,视频帧率是50fps,那么未压缩的视频数据速率就是
,视频帧率是50fps,那么未压缩的视频数据速率就是![]() ,这个很明显太大了,这个视频要经过数百甚至是数千倍的压缩,才能通过网络进行传输。
,这个很明显太大了,这个视频要经过数百甚至是数千倍的压缩,才能通过网络进行传输。
衡量指标,现有的无损编码方案,可以实现约1.5到3的压缩了,明显不够用,所以需要引入有损编码。损失可以通过原始图像和重建图像之间的差异来衡量。比如可以对灰度图像是用均方误差(MSE):
![]()
因此重建图像和原始图像相比的质量,可以通过峰值信噪比(PSNR)来衡量:
![]()
其中![]() 是
是![]() 中的最大值,比如8位灰度图是255。而对于彩色图像,一般是分别计算Y、U、V通道的PSNR值。而对于视频,则是分别计算不同帧的PSNR值,然后再取平均。当然,也有其他的一些质量指标,比如说结构相似性(SSIM)和多尺度SSIM(MS-SSIM)等。
中的最大值,比如8位灰度图是255。而对于彩色图像,一般是分别计算Y、U、V通道的PSNR值。而对于视频,则是分别计算不同帧的PSNR值,然后再取平均。当然,也有其他的一些质量指标,比如说结构相似性(SSIM)和多尺度SSIM(MS-SSIM)等。
对于无损编码方案,一般比较压缩率,而对于有损编码方案,不仅需要考虑压缩了,还要考虑质量。对于图像/视频的编码方案,还需要考虑编码/解码复杂度、可扩展性、鲁棒性等方面。
【回顾深度网络编码方案】
基于深度网络的编码方法,一般有两种:像素概率建模和auto-encoder,也有把这两者结合的。同样的作者还讨论了深度编码方案和专用编码方案,而又把专用编码方案细分为感知编码和语义编码。
A. 像素概率建模
按照香农信息论,最优的无损编码的最小压缩率是![]() ,
, 是符号
是符号 的概率。现在公认的实现的最好的是算术编码(arithmetic coding),可以做到接近
的概率。现在公认的实现的最好的是算术编码(arithmetic coding),可以做到接近![]() 直到数值的舍入误差。这种编码唯一的问题就是,他需要找到概率,但这个看似简单的问题,对于自然图像/视频来说,一点都不简单,因为图像/视频这些维度太高了。
直到数值的舍入误差。这种编码唯一的问题就是,他需要找到概率,但这个看似简单的问题,对于自然图像/视频来说,一点都不简单,因为图像/视频这些维度太高了。
直接概率预测:一种估算的方法是将图像分解成m×n像素并逐个估计这些像素的概率。在估计一个像素的概率时,利用前面的像素进行预测:
![]()

其中 的条件可以叫做前后文。这里有个问题,就是如果图像很大,那么这个概率就很难估计出来,有一种简单的方法是缩短前后文的范围,假设k是预先选择的常数:
的条件可以叫做前后文。这里有个问题,就是如果图像很大,那么这个概率就很难估计出来,有一种简单的方法是缩短前后文的范围,假设k是预先选择的常数:
![]()
当然,说好的哪里有预测问题,哪里就会有深度学习,这不,深度学习就来交叉了。通过训练好的网络,在给定前后文![]() 的情况下,预测概率值
的情况下,预测概率值![]() 。其实这种方法早在2000年就被应用于高维数据的压缩方案了,但是用到图像/视频数据上却只是最近几年的事情。近几年的一些研究:
。其实这种方法早在2000年就被应用于高维数据的压缩方案了,但是用到图像/视频数据上却只是最近几年的事情。近几年的一些研究:
-
Hugo,考虑了二值图像的概率估计,也就是
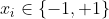 ,这样就可以预测每个像素的概率值
,这样就可以预测每个像素的概率值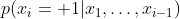 了,并提出了自回归分布估计器(NADE)来做这个预测的工作,每个像素都用一个权值共享的含有一个隐藏层的网络进行处理。
了,并提出了自回归分布估计器(NADE)来做这个预测的工作,每个像素都用一个权值共享的含有一个隐藏层的网络进行处理。 -
Karol,他的工作跟Hugo的工作比较相似,就是给隐藏层加了一个short-cut。
-
Uria,将NADE扩展到实数范围,提出了RNADE,其中的概率
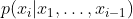 由混合高斯组成,网络需要输出混合高斯模型的一组参数,而不是NADE中的单个值。并且还改进了一下网络,给隐藏层加了归一化避免饱和,并用ReLU替换了Sigmod。甚至还讨论了一下用拉普拉斯算子做混合,而不是高斯算子。
由混合高斯组成,网络需要输出混合高斯模型的一组参数,而不是NADE中的单个值。并且还改进了一下网络,给隐藏层加了归一化避免饱和,并用ReLU替换了Sigmod。甚至还讨论了一下用拉普拉斯算子做混合,而不是高斯算子。 -
Uria,通过使用不同的像素排序和更多的隐藏层,改进了NADE和RANDE。
-
Aaron,使用深度GMM来增强混合高斯模型以改进RNADE。
像素预测网络:可以看到,改进这个像素预测网络,也是一个很火的研究点,一些改进有:
-
Lucas,提出了基于LSTM网络和混合条件高斯尺度模型的混合模型用于概率建模。
-
Aaron,提出了Pixel RNN和Pixel CNN两个网络。对于Pixel RNN,提出了LSTM的两种变体形式:row LSTM和diagonal LSTM,并且Pixel RNN结合了残差,是一个12层的网络。对于Pixel CNN,为了适应前后文的形状,则采用了掩码卷积,是一个15层的网络。他们将像素看作是离散值,并且预测离散值上的多项式分布。
-
Aaron,提出了Pixel CNN的改进型Gated Pixel CNN,以更低的复杂度,达到了Pixel RNN的性能。
-
Tim,提出了Pixel CNN++,相比Pixel CNN有以下改进:使用离散逻辑混合似然而不是256项的多项式分布;用下采样来捕获不同分辨率的结构;引入short-cut加快训练;用dropout做正则化;将RGB组合成一个像素。
-
Xi,提出了Pixel SNAIL,将因果卷积和自注意力相结合。
条件概率预测:前面提到的,其实都是直接的像素概率建模方法,但其实也可以另辟蹊径,做条件概率建模,引入附加条件:
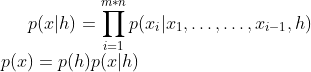
其中的 是附加条件。因此概率建模可以是有条件或者无条件的。
是附加条件。因此概率建模可以是有条件或者无条件的。
-
Aaron,提出由另一个深度网络导出来图像或者高级图像的表示来做附加条件。
-
Alexander,考虑了更多可能的附加条件:原始彩色图像的量化灰度图;多分辨率图像金字塔等。
实际编码方案:
图片编码:
-
Mu Li提出了采用剪枝的卷积网络来预测二进制数据的概率。将大小为m×n的8比特灰度图像转换成m×n×8的二进制立方体,塞到类似Pixel CNN的网络中去处理。这个剪枝后的基于卷积网络的算术编码(TCAE)要优于之前的非深度的无损编码方案,例如TIFF、GIF、PNG、JPEG-LS和JPEG 2000-LS。而在柯达图像数据集中,TCAE可以实现2.00的压缩比。
-
Eza,提出用小波变换域取代像素域,即CNN从相邻子带内的系数预测小波细节系数。
视频编码:
-
Nal,将Pixel CNN推广到视频像素网络(VPN)用于视频的像素概率建模。VPN由用于预测当前帧的前一帧的CNN编码器和用于当前帧内部预测的Pixel CNN解码器组成。CNN编码器在所有层保留输入帧的空间分辨率用以最大化表示能力;并且采用空洞卷积来扩大感受野用以更好的捕捉全局运动;CNN编码器的输出随着时间的推移跟卷积LSTM相结合。Pixel CNN解码器用了掩码卷积并且在离散像素值上用多项式分布进行建模。
这里有一个很有意思的工作,Schiopu等人,通过CNN来预测像素值而不是像素的分布来做无损图像的压缩。将预测值从真实值中减去,产生残差,然后对残差做编码。
B. Auto-Encoder
autoencoder的背景知识也不说了,老经典的东西了。
自动编码器实现了自动学习特征,不再需要手工制作特征,而这也被认为是深度学习中最重要的优势之一。
从自动编码器的概念上,其实就很容易看出来,它似乎就是一个天生的编码好手。但是,传统的自动编码器没有对压缩做过优化,直接用经过训练的自动编码器其实往往效率不高。当我们考虑上压缩的条件时,就会有几个问题了:
-
低维的数据表示要先量化再编码,但是量化这个操作是不可微的,因此网络会很难训练
-
有损编码的目的是要在速度和质量之间得到一个比较好的平衡,因此训练网络的时候需要考虑速度因素,但是速度是一个不好计算跟评估的指标
-
一个真正实用的编解码器,还需要考虑可变的速率、可扩展、编解码速度、互操作等,是一个复杂的问题
(PS:这种需要考虑量化问题的Auto-Encoder的自动编码器,近些年还有一个很火的应用,就是通信的信道状态信息压缩问题,东南大学的金石教授提出的,感兴趣的可以去看看)
现在的基于自动编码器的图像压缩方案,都是用的经典的交换编码策略。就是在编码之前做数据变换。概念图如下所示:
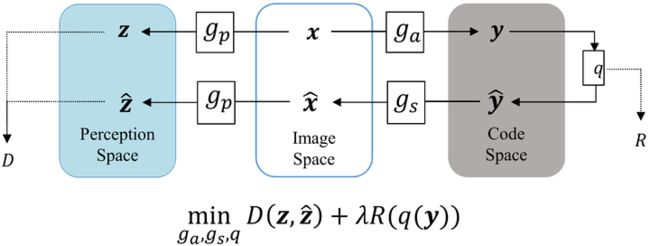
-
原始图像
转换成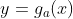 ,然后对
,然后对 做量化和编码。
做量化和编码。 -
解码后的
 逆变换成
逆变换成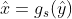 。
。 -
为了兼容速度和质量,可以最小化联合速度失真loss:
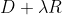 。其中
。其中 通过和
通过和 计算得到,
计算得到, 则是根据量化代码计算得到的,
则是根据量化代码计算得到的, 是拉格朗日常数。
是拉格朗日常数。
可以看出,其实这个追求的就是编解码后图像失真和量化导致的失真尽可能地小。
既然有图像,那么就会有RNN和CNN之争。基于RNN的代表性工作有:
-
Toderici,提出了一个可变速率的图像压缩通用框架。通过二进制量化来生成编码,并且训练的时候不考虑速率,只考虑端到端的由MSE衡量的失真。
-
Toderici,提出了上述框架的改进版,用跟Pixel RNN这样的网络来压缩二进制编码,并且还引入了GRU。他们的算法在柯达数据集上,MS-SSIM的质量指标要比JPEG好。
-
Johnston,提出将隐藏初始值引入RNN,使用SSIM加权loss函数并使用空间自适应比特率来进一步改进基于RNN的算法。同样的,这个算法在柯达数据集上,MS-SSIM的指标要比BPG好。
-
Covell,则是通过SCT(Stop-code Tolerant)训练RNN实现空间自适应比特率。
基于CNN的代表性工作有:
-
Ballé,提出了一个用于率失真(比特率—失真)优化的图像压缩通用框架。使用多元量化来生成整数编码,并且在训练的时候用联合速率-失真loss把速率也考虑上了。为了估计速率,使用随机噪声来训练时候的量化过程,并且使用噪声编码的微分熵来表示速率。网络结构上则用上了GDN(Generalized divisive Normalization)变换。
-
Ballé,提出了上述框架的改进版,使用三个卷积层,每个卷积后做下采样和GDN来实现转换。并且还设计了一种算术编码方法来压缩整数编码。在柯达数据集上,MSE的指标要比JPEG和JPEG 2000都要好。
-
Ballé,受VAE启发,给Auto-Encoder里面加了尺度超先验。用了另一个变换
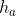 来将转成了
来将转成了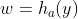 ,对
,对 做量化和编码,并使用另一个逆变换
做量化和编码,并使用另一个逆变换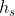 ,将解码后的
,将解码后的 转换为量化后的的ESD(估计标准偏差),在的算术编码阶段使用。这个算法在柯达数据集上,PSNR指标比BPG稍差一点点。
转换为量化后的的ESD(估计标准偏差),在的算术编码阶段使用。这个算法在柯达数据集上,PSNR指标比BPG稍差一点点。
除了搞网络的,还有做编解码中间的不可微量化和算法速率估计的,代表性工作有:
-
Theis,前向的时候按照往常一样量化,后向的时候,直接跳过量化层的BP,还用了一个可微的上边界来替代速率。
-
Dumas,用了一种随机的赢者通吃机制,保留
中绝对值最大的元素,其他就设置为0,然后元素再做统一的量化和压缩。 -
Agustsson,提出了一种从软到硬的矢量量化方案,训练的时候通过退火策略,让软量化逼近硬量化。
-
Li,引入了一个速率估计的重要性图,将图量化成掩码,通过掩码决定每个位置保留多少比特,通过重要性图的和就可以粗略的估计编码的速率。
(PS:看到这里别理解串了,这里的速度,不是NN网络运行的效率的率,而是指编码速率,也就是码率的那个率)
还有做可变速率的,代表性工作有:
-
Toderici,引入尺度参数,针对不同速率微调预训练的自动编码器。
-
Dumas,针对不同速度,提出了一种带有可变量化的独特的学习变换。
-
Cai,针对所有尺度训练并优化出了一个多尺度分解变换,还提供了速率分配算法来确定每个图像块的最佳比例。
-
Zhang,提出了一个跟Toderici不同的可伸缩编码,将图像分解为多个比特平面,并行进行变换和量化,还提出了双向聚合门控单元来减少比特平面之间的相关性。
还有一些用了新网络和新loss的比较潮流的做法:
-
Theis,采用亚像素结构来提高计算效率。
-
Rippel和Bourdev,提出在层间相关对其网络后做金字塔分解,可以实现轻量化的实时运行。并且除了重建loss之外还用了鉴别器loss。
-
Snell,用MS-SSIM替换MSE或者MAE做loss函数来训练自动编码器,因此MS-SSIM可以更好的校准感知的质量。
-
Zhou,给编解码器用了更深的网络,并且在解码器端用了单独的网络做后处理,并且将高斯模型换成了拉普拉斯模型。
-
Cheng,对学习到的特征做PCA,也就是二次变换。
C. 混合图像编码
上面介绍了像素概率建模和自动编码器两种。其中像素概率建模代表的是预测编码,自动编码器代表的是变化编码,这两种编码各有利弊。
-
预测编码的灵活性高,可以为每个像素用不同的预测器。而对变换编码来说,单个像素变换很复杂,但是所有像素都可以用。
-
由于预测编码灵活性高的特点,因此它的压缩率可以做的很高。另外预测编码既可以做有损编码也可以做无损编码,而变换编码一般只拿来做有损编码。
-
预测编码需要编码/解码流水线,像素是一个一个的解码出来的,而变换编码则可以通过一次逆变换解码出所有像素,有利于并行解码。
但其实预测编码跟变换编码并不冲突,甚至还可以结合起来用,做成混合编码。
-
Mentzer,提出了一种实用的无损图像编码方案,在多个级别用自动编码器来学习像素概率建模的条件。
-
Mentzer,将像素概率建模集成到自动编码器中,用以估计编码率和联合训练PixelCNN和自动编码器。
-
Baig,提出了将部分上下文图像块引入可变速率压缩框架,通过从当前块的上下文预测下一个块。
-
Minnen,基于前一个框架,再额外考虑上块之间的速率分配问题。
-
Klopp,对变换后的编码而不是像素或者块应用空间预测器。
-
Minnen,基于前面提到的超先验框架,再引入上下文来进行改进。
-
Li,将上下文自适应熵模型引入超先验中去。
上面的6、7两个工作,在柯达数据集上,PSNR指标都比BPG好,是2018年底为止的最牛的技术水平。
D. 视频编码
跟图像这种简单的编码相比,视频编码有一个最大最大的麻烦,就是帧间冗余。因此帧间预测是视频编码的最重要问题。传统的方法,帧间预测是通过逐块图像的运动估计和运动补偿来实现的。而在这个深度学习时候,就出现了用深度网络做逐像素估计(也就是光流估计)和运动不偿,下面说说这一领域的代表性工作:
-
Chen,看样子是第一个提出用自动编码器做视频编码的。提出将视频帧划分成32×32个块,每个块都有两种模式可选:帧内编码和帧间编码。帧内编码是用一个自动编码器来压缩块,帧间编码则用的是传统的逐块运动估计和补偿,并将残差喂入另一个自动编码器。这两个自动编码器的编码则通过霍夫曼方法做量化和编码。这个最早的工作超级粗糙,不过开端是好的,没法跟H.264相比。
-
Wu,提出了一种图像插值的视频编码方案。关键帧(I帧)用Toderici提出的深度图像编码方案做压缩,其余帧(B帧)则按层次顺序压缩。对于每个B帧,前后两个压缩帧用于插值当前帧,运动信息则用于两个扭曲的压缩帧的运动补偿,然后将这两个扭曲的帧当成辅助信息发给正在处理当前帧的可变速率图像编码方案。这个方案的性能跟H.264差不多。
-
Chen,提出了另一种视频编码方案,也就是Pixel Motion CNN。帧按时间压缩,每个帧分成按照光栅扫描顺序压缩的块。在压缩每一帧之前,通过前两个压缩帧推理当前帧。当一个块被压缩的时候,推理帧连同块的前后文喂到Pixel Motion CNN来生成当前块的预测信号,然后再将预测残差喂到可变速率图像编码方案做压缩。这个方案的性能也跟H.264差不多。
-
Lu,提出了一种端到端的深度视频编码方案。对于每个要压缩的帧,使用光流估计模块获取当前帧与先前压缩帧之间的运动信息。再用训练过的网络做运动补偿来生成当前帧的预测信号。用两个自动编码器对预测残差和运动信息做压缩。整个网络用联合速度-失真loss优化。这个方案效果非常好,有比H.264更高的压缩了,甚至在用MS-SSIM评价指标时,还要优于HEVC(x265)。
-
Rippel,提出了目前为止最复杂的深度视频编码方案。有几个特点:1)只用一个自动编码器同时压缩运动信息和预测残差;2)从前一阵学习并递归更新状态;3)多帧的多光流运动补偿;4)速率控制算法。用MS-SSIM评估的话,性能要优于HEVC的参考软件HM。
截止到18年年底为止,暂时还没有深度视频编码方案在PSNR指标上能比HM好的。
E. 特殊用途编码
大部分的深度编码方案关心的都是信号的保真度,也就是给定速率下想办法令原始图像/视频和重建后的之间的失真最小化。但是有时候我们对保真度又不是特别关心,我们可能关心的是重建的图像/视频的感知自然度或者是在语义分析分析中的功效。这种质量度量就称为感知自然度和语义质量。这种算是特殊用途的编码了。
感知编码:这里用到的主要就是GAN,GAN也不说了,跟Auto-Encoder一样,老经典的东西了。GAN可以生成出感知自然的图像,但是解码器跟GAN的生成器不太一样,解码器还需要考虑解码后图像跟原始图像的相似性,因此这就产生了受控生成的问题,这样的话编码器就可以理解成是在编码比特中提供控制信号的模块。
受到VAE启发:
-
Gregor,提出了用于图像生成德Deep Recurrent Attentive Writer(DRAW),通过用RNN做编码器和解码器来扩展传统的VAE。
-
Gregor,引入了卷积DRAW,它可以将图像转换成一系列从全局的高级到低级的细节特征表示。因此他提出了一种概念性的压缩方案,好处是可以用很低的比特率实现较为合理的图像重建。
现在也可用GAN的鉴别器来评估重构图像的感知自然行。现在有几个工作是用单独loss或者是联合了MSE这些loss的感知质量的深度编码方案:
-
Santurkar,提出了图像和视频的生成压缩方案。对于图像,他们训练了一个标准的GAN,用生成器做解码器,训练编码器来最小化MSE和特征损失。对于视频,用了图像的编码器和解码器,传输的时候只传输几帧,然后通过在解码器端插值来恢复其它的帧。这个做法压缩了非常高。
-
Kim,构建了一个新的视频压缩方案,关键帧用H.264压缩,其它帧则做极限压缩。从下采样的非关键帧中提取边缘信息并传输。在解码器端,先重建关键帧,然后也提取边缘。用边缘做条件并用重建的关键帧来训练GAN。这种做法在低比特率下性能很好。
语义编码:现在也已经有很多工作是关注于保留语义信息和语义质量的深度编码方案了。
-
Agustsson,提出了一种适用于极低比特率的基于GAN的图像压缩方案。结合了自动编码器和GAN,将解码器跟生成器合二为一。语义的标签图可以用作编码器的附加输入和鉴别器的条件。这个方案重建的图像在语义分割上比相同速率下BPG压缩图像的语义分割更准确。
-
Luo,提出了深度语义图像压缩(DeepSIC)的概念。将语义信息合并到编码比特中去。DeepSIC做了两个版本,都是基于自动编码器做的。其中一个版本中,语义信息是在编码器端的特征中提取出来,并编码进比特的。另一个版本的语义信息则是在解码器端从量化的
中提取的。 -
Torfason,研究了从量化特征做语义分析任务而不是从重建图像中做。这样就可以把解码给省掉了。而且这样做的分类和分割精度跟用图像做很接近,能大幅降低计算的复杂度。
-
Zhang,研究了一种同时用于压缩和检索的编码方案。因此编码位不仅仅可以用于重建图像,也可以用来在不解码情况下检索相似的图像。他们用自动编码器将图像压缩成比特,再用分类网络来提取二进制特征。把两个比特数据合起来,再微调特征提取网络来做图像检索。这个方案,在同等速率下,重建的图像要优于JPEG压缩的图像。
-
Akbari,设计了一种可伸缩的编码方案,编码位由三层组成。第一层是无损编码的语义分割图,第二层是原始图像的无损下采样图。训练网络来预测原始图像,预测残差由BPG编码成第三层。在柯达图像集上,PSNR和MS-SSIM的指标都要比BPG要好。
-
Chen和He,用语义度量来代替PSNR来对面部图像做深度编码。loss分为三个部分:MAE、判别器loss、语义loss。语义loss是通过学习变换将原始图像和重建图像投影到紧凑的欧几里德空间中去计算两者之间的欧几里德距离。
F. 小结
现有的深度图像/视频编码方案,可以分为预测、变换和混合编码方案。对视频编码来说,其中结合了预测和变换编码的混合方案可以做到更高的压缩效率。混合编码也是个排列组合问题,一种是先预测,再变换预测残差;另一种是先变换,再逐一预测变换后的比特概率。这个先预测还是先变换的做法,就决定了网络要怎么设计。设计更好的网络是一个比较火的研究热点。从另一个角度看,深度图像/视频编码方案可以针对信号保真度、感知自然度、语义质量进行优化。同样的针对这些不同的优化目标,网络结构也有不同的做法。
【回顾深度工具】

这里我们回顾一下一些用深度网络做传统编码方案中的工具或者是跟传统编码一起使用的代表性工作。
一般来说,传统的视频编码方案都是用的混合编码策略。如上图所示,一个视频序列划分为图片,图片划分为块(最大的块叫CTU),块划分为通道(就是Y、U、V)。图片/块/通道按照预定义的顺序进行压缩,前面压缩的可以用来预测后面的,分别称为图片内(块间)预测、跨通道(通道间)预测和图片间预测。然后在对预测残差做变换、量化、熵编码来获得最终的比特。同样的,诸如块分区和预测模式这些辅助信息也被熵编码进到了比特中去。熵编码步骤用的是概率分布预测。并且由于量化会丢失信息的原因,很有可能会出现伪影,因此还要在预测下一个图片前或者输出之前,滤一下波,来增强重建的图像。另外,为了减少数据量,还可以在压缩前对图片/块/通道先做下采样,再上采样回来。最后就是编码器需要控制不同的模块并将它们组合起来实现编码率、质量和计算速度之前的权衡。因此,编码优化也是编码系统中一个很重要的研究点。
但其实,上面图中那么多的模块,都可以用深度网络来做的。下面根据深度工具在编码中的不同的应用位置来回顾一下深度工具的代表性工作。
A. 图片内预测
图片内预测,是一种在同一图片内的块之间预测的工具。H.264引入了具有多种预定义预测模式的帧内预测,例如DC预测和沿不同方向的推理。编码器则可以为每一个块选择一种预测模式,并将这个预测模型告知解码器。致于这个模式是怎么确定的,也很简单,就是选择率失真最小的模式就得了。而HEVC里面,就更进一步,引入了更多的预测模式。
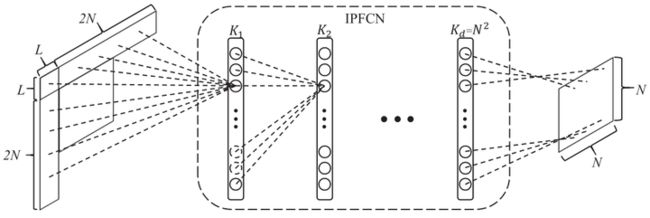
-
Li,提出了如上图所示的用于帧内预测的全连接网络。对于当前的
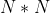 块,使用上方的
块,使用上方的 行和左侧的列,总共
行和左侧的列,总共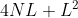 个像素作为前后文。并用纽约图书馆的图像集做训练,原始图像以不同的量化参数进行压缩。还研究了两种不同的策略:第一种是用所有训练数据训练一个模型;第二种是考虑HEVC预测模式,将训练数据分成两组,分别训练两个模型。实验证明两个模型的策略更加适合压缩。这个方案的BD率比HM低3%左右。
个像素作为前后文。并用纽约图书馆的图像集做训练,原始图像以不同的量化参数进行压缩。还研究了两种不同的策略:第一种是用所有训练数据训练一个模型;第二种是考虑HEVC预测模式,将训练数据分成两组,分别训练两个模型。实验证明两个模型的策略更加适合压缩。这个方案的BD率比HM低3%左右。 -
Pfaff,也是用全连接网络做帧内预测,但是用的是多个网络训练为不同的预测模式。他们还提出要额外训练一个网络,输入一样是块的前后文,但是输出是不同模式的预测可能性。他们还提出对于不同的预测模型,要使用不同的变换。这个方案的BD率比具有高级块分区的HM低6%左右。
-
Hu,设计了一个渐进式空间RNN做帧内预测。他们利用RNN的顺序建模能力从上下文到块逐步生成预测。还用了SATD做loss,认为SATD要比率失真loss的相关性更好。
-
Cui,用CNN做帧内预测,或者说是帧内预测优化。用HEVC预测模式生成预测,然后再用CNN优化预测。
B. 图片间预测
帧间预测,是在视频帧之间做预测来去除时间冗余的工具。帧间预测是视频编码的核心(废话,就只有视频才有帧的概念)。传统的视频编码方案,帧间预测主要是通过块级运动估计(ME)和运动补偿(MC)来实现的。给定一个参考帧和一个待编码块,ME在参考帧中找到与待编码块内容最相似的位置,MC在找到的位置检索内容来预测块。现在已经提出了很多各式各样的技术来改进块级ME和MC了,例如有用多个参考帧、双向帧间预测、分数像素ME和MC等等。
受多个参考帧启发,Lin,提出了一种通过预测多个参考帧的帧间预测机制。采用GAN的拉普拉斯金字塔从先前压缩的四帧中推理出一帧。然后这个推理帧又可以作为另一个参考帧来用。这个方案的BD率比HM降低2%左右。
受双向帧间预测启发,Zhao,提出了一种提高预测质量的方法。前面的两个双向预测可以简单的计算两个预测块的线性组合。他们提出用CNN以非线性和数据驱动的方式组合两个预测块。
受分数像素ME和MC启发,在分数像素插值上也有很多工作。因为两帧之间的运动不与政委像素位置对其,所以就要在参考帧的分数位置上生成虚像素。Yan,提出了使用CNN进行半像素插值,提出了一种模糊高分辨率图像的方法,然后从高分辨率图像中采样像素:奇数位置作为整数像素,偶数位置作为半像素。Zhang,提出了另一种方法,将分数插值公式应用到分辨率增强上,对高分辨率图像进行下采样来获得训练数据。Yan,考虑不同的公式,将分数像素ME看成是图片见的回归问题,用视频序列来检索训练数据,依赖分数像素ME来对齐帧,并将参考帧用作整数像素,将当前帧用作分数像素。Yan,进一步研究了分数像素的可逆性问题:如果分数像素可以从整数像素插值出来,那么整数像素也可以从分数像素中插值得到。基于此他们提出了一种无监督方式来训练CNN做分数插值。
还有帧内预测跟帧间预测相结合的方法。不仅基于参考帧生成预测信号,还要基于帧中的前后文来生成。Huo,提出了用CNN来细化帧间预测信号,用待预测块的上下文可以提高预测质量。Wang,同样是CNN来细化帧间预测信号,用帧间预测信号、当前块的前后文和帧间预测块的前后文来作为CNN的输入。
C. 跨通道预测
跨通道预测就是在不同的channel之间做预测。以YUV为例,一般来说Y都是在U、V之前编码的。因此可以根据Y来预测U,根据Y和U来预测V。传统的方法是线性模型(LM),使用线性函数从亮度预测色度,但是又不传输函数的系数,而是通过做线性回归从前后文中估计出来。不过这种简单的线性估计还是太简单了,表达能力不够。
-
Baig和Torresani,研究了图像压缩的着色问题。着色是从亮度预测色度,因为一个亮度可以对应多个色度,所以这是一个ill-posed问题。他们提出了一个树状结构CNN,能在给定一个灰度图像下,产生多个预测。当用于压缩的时候,CNN应用于编码器端,产生最佳的预测信号的分支就可以被编码为解码器的辅助信息。他们将这个方法集成进JPEG中去,经实验这个色度编码要优于JPEG。
-
Li,提出了一种类似LM的预测方法。他们设计了一个由全连接和卷积组成的混合神经网络,全连接包括三个通道用于处理前后文,卷积用于处理当前块的亮度通道。最后融合双重特征来获得最终的预测。这个色度编码方法的BD率比LM降低了2%左右。
D. 概率分布建模
概率估计是熵编码中的关键问题。近些年在这一问题上应用深度学习的工作也不少。
-
Song,提出了一个用CNN来预测基于前后文的帧内预测模式的概率分布。
-
Pfaff,提出了一个用全连接网络来预测基于前后文的帧内预测模式的概率分布,并且如果编码/解码允许多个变换的话,还可以给每一个块都分配一个变换模式。
-
Puri,提出用CNN来预测变换模式的概率分布,这是基于量化变换系数的工作。
-
Ma,考虑了HEVC中量化变换系数的熵编码,特别是DC系数的编码。设计了一个CNN根据块的前后文和块的AC系数来预测块的DC系数的概率分布。
E. 变换
变换是混合视频编码中的重要工具,用来将信号(残差)转换为系数,然后进行量化和编码。最早的视频编码方案,用的是离散余弦变换(DCT),后来被H.264里面的整数预先变换(ICT)取代。后面的HEVC用的也是ICT,但是额外对4×4的亮度块用整数正弦变换。并且还有自适应多次变换和二次变换等。但其实这些都是名字看着唬人,其实都很简单。而后面受到自动编码器的启发,也有很多基于深度的变换方案。
其中,Liu等人,提出了一种基于CNN的方法来实现类似ICT的图像编码变换。由一个CNN和一个全连接层组成,CNN负责对输入块进行预处理,全连接层负责完成变换。其中全连接层用DCT的变换矩阵来初始化,然后跟CNN一起训练,并使用联合速率失真loss来训练网络,速率用量化系数的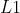 范数来估计得到。并且还进一步研究了非对称的自动编码器。他们的方案比固定的DCT要好,同时非对称自动编码器在压缩效率和编码/解码时间之间能得到比较好的平衡。
范数来估计得到。并且还进一步研究了非对称的自动编码器。他们的方案比固定的DCT要好,同时非对称自动编码器在压缩效率和编码/解码时间之间能得到比较好的平衡。
F. 循环后/循环内滤波
现在用的图像和视频编码方案都是有损编码的。其中,损失一般都是量化造成的,量化步长越大,损失也越大,并可能会产生块、模糊、振铃、色移、闪烁这些伪影的出现。因此就需要滤波,来减少这些伪影,提高重建的图像/视频质量。对图像来说,滤波是后处理问题,而对视频来说,滤波可以在循环内或者循环外来做,具体在哪做则取决于滤波后的帧是否要做后续帧的参考了。HEVC中,有两个环路滤波器,分别是去块(deblocking)滤波(DF)和样本自适应偏移(SAO)。
深度学习的图像/视频编码的大部分工作都是在做环后或者环内滤波。最早的都是在做图像的滤波。
-
Dong,提出了一个用来减少压缩伪影的4层CNN(ARCNN),当质量因子(QF)在10到40之间时,ARCNN在5个经典测试图像上比JPEG的PSNR提高了1dB有多。
-
Li,这个就是堆网络了,堆了20层CNN,效果比ARCNN要好。
-
Cavigelli,用了个有跳层连接的12层CNN,并且测试了40到76的高QF。
-
Wang,用JPEG压缩的先验知识,即8×8块的DCT系数量化,提出了一种基于像素域和变换域的方法。跟ARCNN相比,能有更高的QF和更少的计算时间。
-
Guo和Chao,提出了一个一对多网络,通过感知损失、自然度损失和JPEG损失进行训练。
-
Orobia,通过RNN提出了一种迭代后的滤波方法。
-
Ma,提出了一种用于JPEG2000的后滤波方法,也有显著的QF提高。
后来就开始做视频的环外滤波了,特别是HEVC。
-
Dai,提出了一个4层CNN用于帧内的后滤波。CNN具有可变的滤波器尺寸和残差连接,叫做VRCNN。
-
Wang,用了10层CNN做环外滤波,不过他们的做法是对每一个单独的帧的滤波。
-
Yang,为I帧和P帧应用了不同的CNN模型。
-
Jin,引入辅助信息到解码器来从先前训练的模型集中为每一帧选择一个模型。
-
Yang,将多个相邻帧输入CNN来增强某一帧来在后滤波过程中利用上图片间的相关性。
-
Wang,同样是考虑了图片见的相关性,但是用的是多尺度的卷积LSTM。
-
He,将块分区信息和解码帧一起喂到CNN。
-
Kang,将分区信息喂入CNN的同时还做了个多尺度网络。
-
Ma,将帧内预测信号和解码残差信号喂入CNN。
-
Song,将QP和解码帧喂入CNN。
-
Tsai,这个比较特别,不直接增强解码帧,而是在编码器端计算压缩残差,再训练自动编码器对压缩残差进行编码并发送给解码器端。这种方法在视频游戏流媒体这种视频序列上效果比较好。
环外滤波都是很简单,要想将CNN滤波器集成到环内,就很难了,因为滤波后的帧会作为后续帧的参考,会影响后面的很多工具。
-
Park和Kim,训练了一个3层CNN作为HEVC的环内滤波器。他们为QP范围为20到29和30到39各自分别训练了一个模型。并根据QP值为每一帧选择一个模型。并且在SAO关闭下,在DF之后用CNN。他们想了两种情况来用他们的滤波器:第一种情况是将滤波器用到基于图片顺序计数(POC)的指定帧;第二种情况是滤波器针对每一帧进行测试,如果提高了质量就应用。
-
Meng,用LSTM做环内滤波器,在HEVC的DF和SAO之间用。用解码帧和块分区信息作为输入,用MS-SSIMloss和MAEloss做训练。
-
Zhang,则是提出了一种用于HEVC中SAO之后的环内滤波的残差高速网络(RHCNN)滤波器。分别为I、P、B帧训练不同的RHCNN模型,并将QP分成了几个范围,为每一个范围训练了一个单独的模型。
-
Dai,提出了一种叫做VRCNN-ext的网络,用于HEVC的环内滤波。为I帧和P/B帧设计了不同的策略:基于CNN的滤波器取代I帧的DF和SAO,对于P/B帧,则在DF和SAO之间,带着CTU和CU级别的控制来应用。在CTU级别,每个CTU的一个二进制标志将被发送来控制基于CNN的滤波器是开还是观,如果标志是关,那就是要在CU级别,用二元分类器决定要不要为每个CU开启基于CNN的滤波器。他的这个控制逻辑还挺复杂的,感兴趣的可以去看下原Paper。
-
Wang,提出了一个密集残差网络(DRN),由多个密集残差单元组成,用于HEVC的环内滤波。同样的也为不同的QP训练了不同的模型。
-
Jia,同样是给HEVC做CNN的环内滤波,但他们是在SAO之后做,由帧级和CTU级标志控制。如果帧级标志是关,就省略CTU标志。另外他们还训练了一大堆网络和一个内容分析网络,负责给每个CTU决定要用哪个网络,来节省选择网络消耗的比特位。
G. 下采样和上采样
视频现在的发展就是在不断的提高分辨率,比如说空间分辨率(像素数)、时间分辨率(帧率)、像素值分辨率(位深度)。分辨率的提高,会带来数据量的倍增。当带宽有限的时候,往往就是在编码前降低视频的分辨率,然后解码后再提高视频的分辨率。这种就被叫做基于下采样和上采样的编码策略,可以在空间域、时间域、像素值域或者这些域的混合中实现。而传统的下采样和上采样滤波器都是手动设计的,不过后面深度学习来了,就开始用深度网络来做了。这个工作有两类。
第一类,人类专家设计下采样滤波器,深度网络做上采样滤波器:(其实就是超分问题)
-
Feng,提出了基于双网络的上采样,一个网络用于减少压缩伪影,另一个网络用于上采样。
-
Afonso,提出了联合空间和像素值的下采样,空间下采样用手工设计的滤波器来做,像素值下采样用按位右移来做。编码器端,用SVM决定是否对每一帧做下采样,解码器端,则用CNN将解码后的视频上采样到原始分辨率。
-
Li,跟Afonso的思路一样手工滤波器做空间下采样,CNN做上采样,但是他们提出了一个块自适应分辨率编码(BARC)框架。对于帧内的每个块,考虑两种编码模式:下采样后编码和直接编码。编码器可以为每个块选择一种模式,并将选择的模式发送给解码器。同时在下采样编码模式中,还设计了两个子模式:使用手工制作的简单滤波器做上采样和用CNN进行上采样。子模式也通过信号发送给解码器。
-
Lin,一开始只研究了针对I帧的BARC,后来扩展研究了P和B帧的BARC框架,并构建了一个完整的基于BARC的视频编码方案。但是,他们的下采样是在像素域中做的。
-
Liu,提出了在残差域做下采样。遵循BRAC框架前提下,对帧间预测残差进行下采样,并在考虑预测信号的情况下通过CNN对残差进行上采样。
第二类,这种就是上采样和下采样都用深度网络来做:
-
Jiang,研究了带有两个CNN的压缩框架,第一个CNN做下采样,然后用现有的图像编码器(JPEG、BPG等)做压缩,然后再做解码,第二个CNN对解码的图像再做上采样。这个框架有个缺点,就是不能做端到端训练,因为图像编码/解码器不可微。为了解决这个问题,他们提出了两个网络交叉训练的方法。
-
Zhao,用基于CNN的虚拟编解码器来近似取代编码/解码器的功能。在上采样CNN前插入一个CNN做后处理,因为是全卷积的,所以这个方案可以做端到端训练。
-
Li,训练的时候直接把编码器/解码器去掉,只留下两个CNN,同时考虑到下采样图像会被压缩,就提出了一种新的训练时候用的正则化loss,要求下采样图像跟理想低通和手工滤波器近似的图像相差不大。在联合训练下采样和上采样CNN的时候,这种正则化loss被证明是有效的。
H. 编码优化
上面提到的工具,都是在提高压缩效率,也就是在保持相同PSNR下,尽可能降低比特率。但其实针对不同方面的工具的。这里简单介绍三个编码优化工具:快速编码、速率控制、ROI编码。
快速编码:对于现在最先进的视频编码标准H.264和HEVC,都有一个问题,那就是解码很简单,但是编码超级复杂。因此编码模式非常多,每个块都可以选不同的模式。每个块选定的模式直接通知解码器解码就完事了,因此解码器只要处理给定模式。但是为了找到每个块要用的编码模式,编码器往往需要比较多种可用的模式并选择最佳的模式。如果编码器做模式的穷举搜索,就可以得到最高的压缩效率,但是计算复杂度也会超级高。因此实用的编码器都会用启发式搜索来寻找模式,现在也有用机器学习、深度学习来辅助寻找的。
-
Liu,提出了HEVC帧内编码器的硬件设计,用CNN来辅助决定CU的分区模式。在HEVC帧内编码中,一个CTU递归拆分成CU,形成四叉树结构。CNN根据CU的内容和指定的QP决定是否拆分一个32×32/16×16/8×8CU。实际上这是个二元决策问题。
-
Xu,考虑了HEVC的帧间编码器,提出了一个提前停止的分层CNN(early-terminated hierarchical CNN)和提前停止的分层LSTM分别帮助I帧和P/B帧决定CU分区的模式。
-
Jin,同样考了CU分区的模式决策,但是他弄的是VCC而不是HEVC。因为VCC为CU分区设计了QTBT(Quadtree plus Binary Tree),这个比HEVC的复杂多了。用CNN对32×32CU做五分类,不同的类表示不同的书深度。
-
Xu,研究了从H.264转码成HEVC的CU分区模式决策。用一个分层LSTM,从H.264的编码比特中提取特征来预测CU分区的模式。
-
Song,用了一个基于CNN的方法,在HEVC帧内编码器中进行快速帧内预测模式决策。CNN根据内容和指定的QP为每个8×8/4×4块导出最可能的模式列表,然后通过正常的率失真优化过程在列表里面选一个。
速率控制:带宽有限的情况下,编码器需要生成出不会超过带宽限制的比特。传统的速率控制方法是根据![]() 模型将比特分配给不同的块。每个块都有两个待定参数
模型将比特分配给不同的块。每个块都有两个待定参数 和
和 。以前的做法,参数是用经验公式估计的。后来,就开始用深度网络了。
。以前的做法,参数是用经验公式估计的。后来,就开始用深度网络了。
-
Li,提出用CNN来预测每个CTU的参数。这种方法能有更高的压缩效率和更低的速率控制误差。
-
Hu,利用强化学习进行帧内速率控制。块的纹理复杂度和比特平衡看成是强化学习问题的环境状态,量化参数看成是需要采取的行动,块的负失真看成是奖励,就可以用强化学习来搞了。
ROI编码:ROI就是按兴趣区域。图像压缩中,需要ROI区域的内容质量高,ROI之外的区域内容质量低。JPEG和JPEG2000都支持ROI编码。但问题来了,怎么识别ROI呢?Prakash,提出一种基于CNN的方法来生成多尺度ROI图,用以指导JPEG编码。在图像上用图像分类网络,选择网络预测的前五个类别,并识别这些类别对应的区域。
I. 小结
现有的深度工具可以分成三种:
-
以增加编码/解码时间为代价来提高压缩率。这种由各种预测工具、变换工具、滤波工具和下采样上采样工具组成。目前能显著提高压缩性能的工具,应该是环后/环内滤波和概率分布预测。
-
以降低压缩效率为代价来提高编码速度。这种是最有前途的,因为这种在编码时间和压缩性能之间取得了较好的平衡。
-
速率控制和ROI,这种还在研究,不好说行不行。
机器学习/深度学习,还有有监督和无监督之分。变换工具和下采样工具就属于无监督学习,而目前对有监督学习的研究比较多,因此后面无监督的深度工具应该也会越来越多。
【后话】
原Paper是很长的,后面还有作者团队他们提出的深度编码方案,我就没继续写下去了,没什么必要看,前面这部分的综述重要点。这个AI编解码器看下来,我就感觉,这领域是不是被国人垄断了,大部分工具都是咱们国人做的。编解码是一个很复杂的系统性工程,这个大工程的一个小工具拉出来,都能研究上好久。但其实上面讨论到的编解码器,更加倾向于本地化使用,在短视频时代,其实结合互联网,可以做一些更加特别的编解码方案,例如前段时间有个视频平台公司就提出过通过提取运动信息,在手机端侧直接做运动合成,可以将视频所需的带宽压低到几十kb。当然这是两个不同的领域的工作就不多说了。