ReID学习
ReID学习
- ReID学习
-
- 1 基本认识
-
- 1.1 目标
- 1.2 数据集
- 1.3 评判标准
- 1.4 方法
- 1.5 挑战及展望
-
- 1.5.1 数据量太小的解决方案
- 1.5.2 训练有效性的提升:
- 1.5.3 效率的提升
- 1.5.4 有限标注
- 1.5.5 Domain Gap
- 1.5.6 非限制场景
- 2 数据集
-
- 2.1 内容
-
- 2.1.1 CUHK03
- 2.1.2 Market1501
- 2.1.3 DukeMTMC-reID/DukeMTMC4ReID
- 2.1.4 MSMT17
- 2.1.5 PRID2011
- 2.1.6 MARS
- 2.1.7 iLIDS-VID
- 2.2 使用
-
- 2.2.1 CUHK03
- 2.2.2 Market1501
- 2.2.3 MARS[^11]
- 3 评判标准
-
- 3.1 CMC
- 3.2 Precision & recall
- 3.3 mAP
- 3.3 FLOP
- 4 文献阅读
-
- 4.1 Deep Learning for Person Re-identification: A Survey and Outlook
-
- 4.1.1 Abstract:
- 4.1.2 Intorduction
- 4.1.3 Close-world ReID
-
- 4.1.3.1 Feature representation learning
- 4.1.3.2 Deep Metric Learning
- 4.1.3.3 Ranking Optimization
- 4.1.3.4 Datasets and evaluation
- 4.1.4 Open-World Re-ID
-
- 4.1.4.1 多模态(异构)数据
- 4.1.4.2 端到端Re-ID(End-to-end Person Search)
- 4.1.4.3 半监督和无监督的Re-ID
- 4.1.4.4 噪声鲁棒的Re-ID
- 4.1.4.5 Open-set Re-ID and Beyond
- 4.1.5 展望
-
- 4.1.5.1 新的评价指标mINP:
- 4.1.5.2 AGW:
- 4.1.5.3 对未来一些研究方向的思考
ReID学习
1 基本认识
这一部分的内容主要都是从知乎、csdn上看到的,主要是为了对ReID有基本的认识。这一部分的图片主要来自于知乎上的郑哲东大佬的一篇文章。如有侵权,我会立刻删除。1
1.1 目标
目的:用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。一个区域有多个摄像头拍摄视频序列,ReID的要求对一个摄像头下感兴趣的行人,检索到该行人在其他摄像头下出现的所有图片。2
意义:安防,个人定位,配合推荐系统3
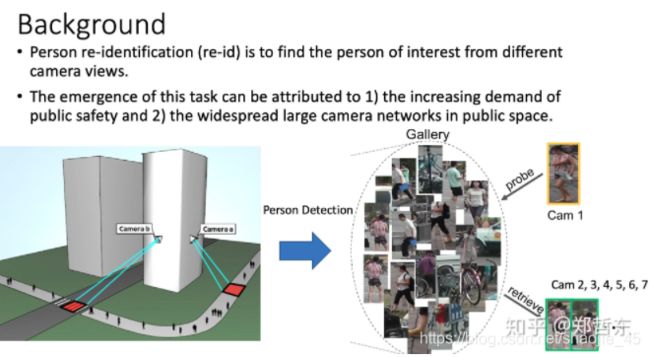
1.2 数据集
数据集分为训练集、验证集、Query、Gallery。在训练集上进行模型的训练,得到模型后对Query与Gallery中的图片提取特征计算相似度,对于每个Query在Gallery中找出前N个与其相似的图片。训练、测试中人物身份不重复。2
目前一些主流的数据集:

不同数据集的大小:

1.3 评判标准
- rank-k:算法返回的排序列表中,前k位为存在检索目标则称为rank-k命中
- CMC curve:计算rank-k的击中率,形成rank-acc的曲线
- mAP(mean average precision):反应检索的人在数据库中所有正确的图片排在排序列表前面的程度;如被检索行人在gallery中有4张图片,在检索的list中位置分别为1、2、5、7,则ap为(1 / 1 + 2 / 2 + 3 / 5 + 4 / 7) / 4 =0.7932
1.4 方法
最基本的思想:
首先要做的是Detection,也就是检测出行人,其实这一步数据集已经帮我们做到了,下面介绍数据集的时候会讲到不同数据集采用的不同的目标检测方法以及ID的标注方式。剩下的部分,就是要去训练一个特征提取网络,根据特征所计算的度量距离得到损失值,我们选用一个优化器去迭代找到loss最小值,并不断更新网络的参数达到学习的效果。在测试的时候,我们用将要检索的图片(称为query或者probe),在底库gallery中,根据计算出的特征距离进行排序,选出最TOP的几张图片,来达到目标检索的目的。
今年来一些主流的方法:

1.5 挑战及展望
- 首要的难度是在于不同摄像头下,由于视角的差异所引入的appearance变化
- 同时,也需要一些细粒度的信息来区分不同人

- 数据量相对较小
一些可能的解决方案:

1.5.1 数据量太小的解决方案
(这些方案是郑哲东大佬和他的课题组做的工作,这里只是搬运过来):
- 3D game engine:用3D游戏产生数据
- GAN生成数据
- GAN风格迁移
1.5.2 训练有效性的提升:
- 图像层面基于部件的像素对齐(我的理解是把部件提取并放规整,方便识别)
- 局部部件特征学习、特征对齐
- 不同的损失函数
1.5.3 效率的提升
- 模型剪枝
- Auto-ML
1.5.4 有限标注
- 单样本行人重识别任务
- 无监督学习(软标签)
1.5.5 Domain Gap
产生的原因在于模型不能适应不同的场景(光照、衣着、摄像头角度的影响)
Domain adaptation: 新数据不作人工标注、而是通过聚类的方式赋予伪标签,然后进行微调;利用先验知识和soft label在目标域进一步挖掘信息
1.5.6 非限制场景
主要是考虑遮挡
- 关键点检测,识别非遮挡部分
- 3维空间Re-ID
- 多模态输入
总结:

2 数据集
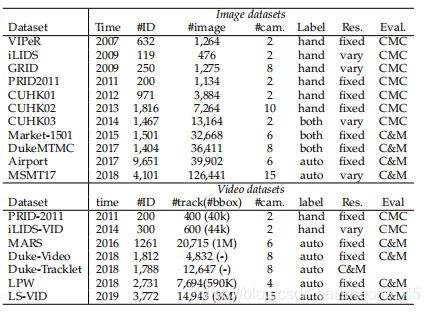
2021年CVPR的论文中,分别用了这些数据集:
可以看到,并没有用什么更新的数据集,还是用的一些接受度比较高、之前的一些数据集,下面是目前主流的数据集的统计:4
| Dataset | Release time | # identities | # cameras | # images | Label method | Crop size | Multi-shot | Tracking sequences | Full frames availability |
|---|---|---|---|---|---|---|---|---|---|
| VIPeR | 2007 | 632 | 2 | 1264 | Hand | 128X48 | |||
| ETH1,2,3 | 2007 | 85, 35, 28 | 1 | 8580 | Hand | Vary | ✔ | ✔ | ✔ |
| QMUL iLIDS | 2009 | 119 | 2 | 476 | Hand | Vary | ✔ | ||
| GRID | 2009 | 1025 | 8 | 1275 | Hand | Vary | |||
| CAVIAR4ReID | 2011 | 72 | 2 | 1220 | Hand | Vary | ✔ | ||
| 3DPeS | 2011 | 192 | 8 | 1011 | Hand | Vary | ✔ | ✔* | |
| PRID2011 | 2011 | 934 | 2 | 24541 | Hand | 128X64 | ✔ | ✔ | ✔* |
| V47 | 2011 | 47 | 2 | 752 | Hand | Vary | ✔ | ✔ | |
| WARD | 2012 | 70 | 3 | 4786 | Hand | 128X48 | ✔ | ✔ | |
| SAIVT-Softbio | 2012 | 152 | 8 | 64472 | Hand | Vary | ✔ | ✔ | ✔ |
| CUHK01 | 2012 | 971 | 2 | 3884 | Hand | 160X60 | ✔ | ||
| CUHK02 | 2013 | 1816 | 10(5 pairs) | 7264 | Hand | 160X60 | ✔ | ||
| CUHK03 | 2014 | 1467 | 10(5 pairs) | 13164 | Hand/DPM | Vary | ✔ | ||
| RAiD | 2014 | 43 | 4 | 6920 | Hand | 128X64 | ✔ | ||
| iLIDS-VID | 2014 | 300 | 2 | 42495 | Hand | Vary | ✔ | ✔ | |
| MPR Drone | 2014 | 84 | 1 | Pyramid Features(ACF) | Vary | ✔ | ✔ | ||
| HDA Person Dataset | 2014 | 53 | 13 | 2976 | Hand/Pyramid Features(ACF) | Vary | ✔ | ✔ | ✔ |
| Shinpuhkan Dataset | 2014 | 24 | 16 | Hand | 128X48 | ✔ | ✔ | ||
| CASIA Gait Database B | 2015(*see below) | 124 | 11 | Background subtraction | Vary | ✔ | ✔ | ✔ | |
| Market1501 | 2015 | 1501 | 6 | 32217 | Hand/DPM | 128X64 | ✔ | ||
| PKU-Reid | 2016 | 114 | 2 | 1824 | Hand | 128X64 | |||
| PRW | 2016 | 932 | 6 | 34304 | Hand | vary | ✔ | ✔ | |
| Large scale person search | 2016 | 11934s | - | 34574 | Hand | vary | ✔ | ||
| MARS | 2016 | 1261 | 6 | 1191003 | DPM+GMMCP | 256X128 | ✔ | ✔ | |
| DukeMTMC-reID | 2017 | 1812 | 8 | 36441 | Hand | Vary | ✔ | ✔ | |
| DukeMTMC4ReID | 2017 | 1852 | 8 | 46261 | Doppia | Vary | ✔ | ✔ | |
| Airport | 2017 | 9651 | 6 | 39902 | ACF | 128X64 | ✔ | ||
| MSMT17 | 2018 | 4101 | 15 | 126441 | Faster RCNN | Vary | ✔ | ||
| RPIfield | 2018 | 112 | 12 | 601,581 | ACF | Vary | ✔ | ✔ | |
| LPW | 2018 | 2,731 | 3,4,4 | 592,438 | Detector+NN+Hand | - | ✔ | ✔ | |
| PKU SketchRe-ID | 2018 | 200 | 2 | 400 | Hand | - | |||
| ThermalWorld | 2018 | 516 | 20 | 15,118 | Hand | - |
2.1 内容
介绍一些比较常用的数据集,下面是图片类型的:
2.1.1 CUHK03
CUHK03
- 第一个足够大,可以训练深度学习的
- 有bounding box和手动标注的标签
- 图片之类还可以
CUHK03 is the first person re-identification dataset that is large enough for deep learning. It provides the bounding boxes detected from deformable part models (DPM) and manually labeling. Person detection quality is relatively good for this dataset.

2.1.2 Market1501
Market1501
- 6个摄像头
- 包含错误数据(模仿真实情况)
- 图片质量不如CUHK03
- 数据集比较大
- 评判指标为mAP
It contains a large number of identities and each identity has several images from six dis-joint cameras. This dataset also includes 2793 false alarms from DPM as distractors to mimic the real scenario. Quality of the bounding boxes is worse than CUHK03. Later in the ICCV 2015 release version, 500K distractors are integrated to make this dataset really large scale. In the original paper proposed this dataset, the author also used mAP as an evalution criteria to test the algorithms.

2.1.3 DukeMTMC-reID/DukeMTMC4ReID
DukeMTMC-reID/DukeMTMC4ReID
- 大
- 多摄像头
- 有手工和机器标注两种方法
The DukeMTMC dataset is a large-scale heavily labeled multi-target multi-camera tracking dataset. In total, more than 2700 people were labeled with unique identities in 8 cameras. With the access to all information (full frames, frame level ground truth, calibration information, etc.), this dataset has a lot of protentials. Based on the released train-validation set, two re-id extension datasets are created. The key difference is the way to generate the bounding boxes. DukeMTMC-reID directly uses the manually labeled ground truth whereas DukeMTMC4ReID adopts Doppia as the person detector.

2.1.4 MSMT17
MSMT17
- 12户外摄像头,3室内
- 不同季节,每个季节4天
- 早中晚各一个小时
- faster rcnn用来标注
- 非常大
This large scale re-id dataset is collected in a campus with 12 outdoor cameras and 3 indoor cameras. It coveres 4 days with different weather in a month. For each day, 3 one-hour videos are selected from morning, noon and afternoon. Faster RCNN is utilized for pedestrian detection. This dataset is the largest re-id dataset so far. It has similar viewpoint with Market, but much more complicated scenarios.

下面视屏类型的数据集:
2.1.5 PRID2011
PRID2011
- 两个摄像头的轨迹
- 出现了200个人
- 有可能会跳帧
PRID dataset has 385 trajectories from camera A and 749 trajectories from camera B. Among them, only 200 people appear in both cameras. This dataset also has a single shot version, which consists with random selected snapshots. Some trajectories are not well-synchronized, which means the person might “jump” between consecutive frames.

2.1.6 MARS
MARS
- 第一个大型的视屏数据集
- 自动生成的bounding box
- 有干扰
- 网上有提前计算的特征
The MARS (Motion Analysis and Re-identification Set) dataset is an extenstion verion of the Market1501 dataset. It is the first large scale video based person re-id datset. Since all bounding boxes and tracklets are generated automatically, it contains distractors and each identity may have more than one tracklets. Precomputed deep features are also avaliable on the website.

2.1.7 iLIDS-VID
iLIDS-VID
- 600个序列
- 有严重遮挡
Based on the assumption that the real person re-identification system should have the trajectory for each identity, iLIDS-VID dataset extracted 600 trajectories for 300 identities from iLIDS MCTS dataset. Due to the limitation of iLIDS MCTS dataset, iLIDS-VID has extremely heavy occlusion.

2.2 使用
2.2.1 CUHK03
MATLAB数据文件格式,1467个行人,收集自The Chinese University of Hong Kong校园内的10个(5对)不同的摄像头。5
数据集结构由三部分组成:
— “detected”:行人框由pedestrian detector绘出,5x1 cell,分别由5对摄像头组收集得到。
-- 843x10 cell,收集自摄像头组pair 1,行数为行人索引,前5列和后5列分别来自同一组的不同摄像头。cell内每个元素为一幅 MxNx3 的行人框图像(uint8 数据类型),个别图像可能空缺,为空集。
-- 440x10 cell,收集自摄像头组pair 2,其它同上。
-- 77x10 cell,收集自摄像头组pair 3,其它同上。
-- 58x10 cell,收集自摄像头组pair 4,其它同上。
-- 49x10 cell,收集自摄像头组pair 5,其它同上。
— “labeled” :5x1 cell,行人框由人类标注,格式和内容大致和上面的"detected"相同。
— “testsets” :20x1 cell,测试协议。由20个 100x2 double类型矩阵组成。
-- 100x2 double,100行代表100个测试样本,第1列为摄像头pair索引,第2列为行人索引。
-- ...
测试协议:
CUHK-03的测试协议有两种。
第一种为旧的版本(参考文献[1], 即数据集的出处 ),参见数据集中的'testsets'测试协议。具体地说,即随机选出100个行人作为测试集,1160个行人作为训练集,100个行人作为验证集(这里总共1360个行人而不是1467个,这是因为实验中没有用到摄像头组pair 4和5的数据),重复二十次。这种测试协议是single-shot setting.
第二种测试协议(参考文献[2] )类似于Market-1501,它将数据集分为包含767个行人的训练集和包含700个行人的测试集。在测试阶段,我们随机选择一张图像作为query,剩下的作为gallery,这样的话,对于每个行人,有多个ground truth在gallery中。(新测试协议可以参考这里)
2.2.2 Market1501
目录介绍6
- “bounding_box_test”——用于测试集的 750 人,包含 19,732 张图像,前缀为 0000 表示在提取这 750 人的过程中DPM检测错的图(可能与query是同一个人),-1 表示检测出来其他人的图(不在这 750 人中)
- “bounding_box_train”——用于训练集的 751 人,包含 12,936 张图像
- “query”——为 750 人在每个摄像头中随机选择一张图像作为query,因此一个人的query最多有 6 个,共有 3,368 张图像
- “gt_query”——matlab格式,用于判断一个query的哪些图片是好的匹配(同一个人不同摄像头的图像)和不好的匹配(同一个人同一个摄像头的图像或非同一个人的图像)
- “gt_bbox”——手工标注的bounding box,用于判断DPM检测的bounding box是不是一个好的box
bounding_box_test 文件夹是 gallery 样本,bounding_box_train 文件夹是 train 样本,query 文件夹是 query 样本
命名规则:以 0001_c1s1_000151_01.jpg 为例
- 0001 表示每个人的标签编号,从0001到1501;
- c1 表示第一个摄像头(camera1),共有6个摄像头;
- s1 表示第一个录像片段(sequece1),每个摄像机都有数个录像段;
- 000151 表示 c1s1 的第000151帧图片,视频帧率25fps;
- 01 表示 c1s1_001051 这一帧上的第1个检测框,由于采用DPM检测器,对于每一帧上的行人可能会框出好几个bbox。00 表示手工标注框
测试协议
Cumulative Matching Characteristics (CMC) curves 是目前行人重识别领域最流行的性能评估方法。考虑一个简单的 single-gallery-shot 情形,每个数据集中的ID(gallery ID)只有一个实例. 对于每一次的识别(query), 算法将根据要查询的图像(query) 到所有gallery samples的距离从小到大排序,CMC top-k accuracy 计算如下:
Acc_k = 1, if top-k ranked gallery samples contain query identity
Acc_k = 0, otherwise
这是一个 shifted step function, 最终的CMC 曲线(curve) 通过对所有queries的shifted step functions取平均得到。尽管在 single-gallery-shot 情形下,CMC 有很明确的定义,但是在 multi-gallery-shot 情形下,它的定义并不明确,因为每个gallery identity 可能存在多个instances.
但是对于每个query identity, 他/她的来自同一个摄像头的 gallery samples 会被排除掉。对于每个 gallery identity,他们不会只随机采样一个instance. 这意味着在计算CMC时, query 将总是匹配 gallery 中“最简单”的正样本,而不关注其他更难识别的正样本。
2.2.3 MARS7
整个Mars数据的大小大概有6.3G,有两个名称为bbox_train和 bbox_test的文件夹。
同时你还应该下载一个关于数据集信息的info文件夹。info文件夹不包括在原始数据集中,下载地址为https://github.com/liangzheng06/MARS-evaluation/tree/master/info。完整版的Mars数据集包含的文件夹如下图所示。

bbox_train文件夹中,有625个子文件夹(代表着625个行人id),共包含了8298个小段轨迹(tracklets),总共包含509,914张图片。

bbox_test文件夹中共有636个子文件夹(代表着636个行人id),共包含了12180个小段轨迹(tracklets),总共包含681,089张图片。在实验中这个文件夹被划分为图库集(gallery)+ 查询集(query)。在info文件夹中会解释这件事。名称为00-1子文件夹表示无用的图片集,他们对应的行人id被设为**-1**,一般在算法中直接无视pid = -1的图片。而名称0000子文件夹中,他们对应的行人id被设为0,表示干扰因素,对检索准确性产生负面影响。

info文件夹中包含了5个子文件,包含了整个数据集的信息,目的是方便使用数据集。
- train_name.txt文件:
这个txt文件里,按照顺序存放bbox_train文件夹里所有图片的名称,一共有509,914行。 - test_name.txt文件
同样地,在这个txt文件中,按照顺序存放bbox_test文件夹里所有图片的名称,一共有681,089行。 - tracks_train_info.mat文件
.mat格式的文件是matlab保存的文件,用matlab打开后可以看到是一个8298 * 4的矩阵。矩阵每一行代表着一个tracklet;第一列和第二列代表着图片的序号,这个序号与 train_name.txt文件中的行号一一对应;第三列是行人的id,也就是 bbox_train文件夹中对应的子文件夹名;第4列是对应的摄像头id(一共有6个摄像头)。 - tracks_test_info.mat文件
这个文件用matlab打开后可以看到是一个12180 * 4的矩阵。矩阵每一行代表着一个tracklet;第一列和第二列代表着图片的序号,这个序号与 test_name.txt 文件中的行号一一对应;第三列是行人的id,也就是 bbox_test文件夹中对应的 子文件夹名;;
第4列是对应的摄像头id(一共有6个摄像头)。 - query_IDX.mat文件
这个文件用matlab打开后可以看到是一个1 * 1980的矩阵,可以看到每一列是对应上面 tracks_test_info.mat文件中的第几行。比如1978列中的值为12177,对应的是 tracks_test_info.mat文件中的第12177行。而12177行中,可以看到其id=1496。不难发现同样id=1496的行还有12166, 12167等。其实这说明在 名称为1496子文件夹中,有多个小段视频(tracklet)。值得注意的是, 并不是所有查询集的id,图库都有对应的相同id行人的行。在1980个查询id中,有效的id(在图库中存在相同id的行)数 = 1840。也就是说,有些文件夹里只有1个tracklet。
3 评判标准
3.1 CMC
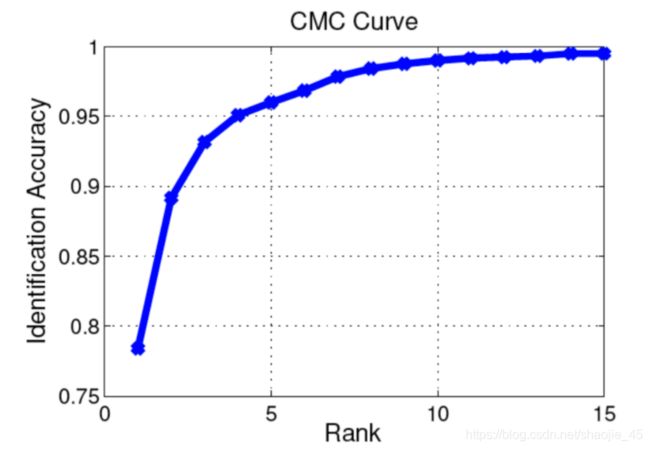
累计匹配特性曲线,一般用Rank-1, Rank-5, Rank-20 scores代替,反应检索准确度8
Rank-1识别率就是表示按照某种相似度匹配规则匹配后,第一次就能判断出正确的标签的测试数目与总的测试样本数目之比,Rank5识别率就是指有五次机会(选取匹配程度最大的五项)去判断是否有正确匹配。
如果一个样本按照匹配程度从大到小排列后,到排序结果的后面,才匹配到正确标签,把最应匹配的判别成最不应匹配的,这就说明分类器不太好。
举个例子来说,比如,我们训练了一个分类器,来识别五个物体,即1,2,3,4,5,他们属于3类即A,B,C。比如属于A类的物体1,经过分类器,得到属于A、B、C类的概率是80%,15%,5%,所以将物体1,判定为A类,物体1经过一次排序就被命中正确的类,所以我们引入Rank-1为100%,若物体2本来属于B类,被我们训练的分类器分类为A、B、C的概率分别为50%,40%,10%,所以被判定为A类,按照概率排序,如果有两次机会,才能命中,这就是Rank-2的含义。
综上五个物体,若果每个都能第一次命中,所以五个物体的Rank分别是 rank-1 100% rank-2 100% rank-3 100%。如果物体1,2为一次就命中,3,4为两次才能命中,5为三次命中,则为 rank-1 40% rank-2 80% rank-3 100%。这就是CMC曲线,而一次命中率越高,说明我们的分类器性能越好。
CMC曲线适合gallery中只有一个查询结果的情况。而对于gallery中有多个查询结果的情况,用mAP更为合适
3.2 Precision & recall
查准率就是和query同一ID的图片在查询结果中的占比。计算公式如下:
precision = ∣ { 同 I D 图片 } ∩ { 查询结果 } ∣ ∣ { 查询结果 } ∣ \text { precision }=\frac{\mid\{\text { 同 } I D \text { 图片 }\} \cap\{\text { 查询结果 }\} \mid}{\mid\{\text { 查询结果 }\} \mid} precision =∣{ 查询结果 }∣∣{ 同 ID 图片 }∩{ 查询结果 }∣
查准率可以同时考虑所有的获取到的结果,也可以单独给定一个特定的值K,只考虑返回结果中排名前K的查询结果,在这种情况下,查准率又可以称为前K查准率,记作P@K。
查全率就是和query同一ID的图片出现在查询结果中的数量占总数的比例。计算公式如下:
r e c a l l = ∣ { 同 I D 图 片 } ∩ { 查 询 结 果 } ∣ ∣ { 同 I D 图 片 } ∣ recall = \frac{\mid\{同ID图片\}\cap\{查询结果\}\mid}{\mid\{同ID图片\}\mid} recall=∣{同ID图片}∣∣{同ID图片}∩{查询结果}∣
查准率和查全率看上去都很有意义,但我们能直接用它俩来评判ReID模型的性能了吗?当然不行,由于查准率和查全率都是通过比例来计算,完全忽略了返回结果的排序!当查询时,返回和当然是不一样的,但其查准率和查全率却是一样的。返回结果的顺序被忽略了。
值得注意的是,查准率和查全率是一个相互矛盾的度量,比如为了增加查全率,我们可以通过增加查询结果的数量来实现,当查询结果数量等于数据集大小时,查全率一定等于1,因为这时所有图片都被查询得到了。但此时查准率就成了最小值。所以比较模型的性能不是那么简单的事情。9
PR图:

P-R图直观地显示出了ReID模型的查全率和查准率,显而易见,如果一个模型的P-R曲线包住了另一个模型的P-R曲线,这个模型的性能就好于另一个模型。
3.3 mAP
根据准确率-召回率曲线计算得到,反应召回率

显然,PR曲线与坐标轴围起来图形的面积一定程度上反应了ReID模型的性能,我们把这个面积叫做Average Precision。这个面积怎么求?由积分知识可得:
A v e P = ∫ 0 1 p ( r ) d r AveP = \int_{0}^1p(r)dr AveP=∫01p(r)dr
可惜,我们得到的是曲线上一个个点,得不到p®p®的准确公式,没法用上面的公式计算。但计算AP的过程已经可以被归结为这么一个问题:假设一共返回NN个查询结果,计算N个点
{ ( r e c a l l k , p r e c i s i o n k ) , k ∈ 1 , 2 , 3 , . . . , N } \{(recall_k, precision_k), k\in1,2,3,...,N\} {(recallk,precisionk),k∈1,2,3,...,N}
的离散积分。
显然,可以用多个长方形条的面积之和表示积分结果。
A v e P = ∑ k = 1 N p r e c i s i o n i ( r e c a l l k − r e c a l l k − 1 ) AveP = \sum_{k=1}^{N}precision_i(recall_k-recall_{k-1}) AveP=k=1∑Nprecisioni(recallk−recallk−1)
拿水果emoji重识别中的查询为时的Similarity1做个例子:

注意,图中r一致,p在变小的前3个点中,只有p最大的点对计算积分值有影响。因为只有此时 r e c a l l k − r e c a l l k − 1 recall_k-recall_{k-1} recallk−recallk−1值不为0。这样,我们得出一个结论,计算积分时,只需要考虑查准的结果处(假设为第k个查询结果)对应的(recall_k, precision_k)
可以这么理解,返回结果[]中第2,3个结果都没查准,那么前2,3个结果中查准个数不变,即recall保持不变,recall保持不变意味着这几个点在P-R图中,位于同一条平行于p轴的直线上。由于 r e c a l l k − r e c a l l k − 1 = 0 recall_k-recall_{k-1}=0 recallk−recallk−1=0,它们不影响积分结果。
所以如果令集合 Ω \Omega Ω为和query同ID的第k个查询结果的集合,Nt为所有与查询图片同ID的图片数目, Δ r e c a l l = 1 / N t \Delta recall=1/N_t Δrecall=1/Nt
A v e P = ∑ i p r e c i s i o n i Δ r e c a l l , i ∈ Ω AveP = \sum_i precision_i\Delta recall, i\in\Omega AveP=i∑precisioniΔrecall,i∈Ω
对于查询结果[], Ω = { 1 , 4 , 5 } \Omega=\{1,4,5\} Ω={1,4,5}, Δ r e c a l l = 1 / 5 \Delta recall=1/5 Δrecall=1/5
网上搜mAP相关教程时经常出现的图片(来自yongyuan.name)用的就是这个公式
3.3 FLOP
首先介绍一个很形似的概念——FLOPS:全称是floating point operations per second,意指每秒浮点运算次数,即用来衡量硬件的计算性能;这里我们讨论的FLOPs全称是floating point operations,即表示浮点运算次数,小s后缀是复数的缩写,可以看做FLOPS在时间上的积分,区别类似速度和时间。
同样从Andrew的前向传播PPT中,我们也可以看到,这里的浮点运算主要就是W相关的乘法,以及b相关的加法,每一个W对应W中元素个数个乘法,每一个b对应一个加法,因此好像FLOPs个数和parameters是相同的。
但其实有一个地方我们忽略了,那就是每个feature map上每个点的权值是共享,这是CNN的一个重要特性,也可以说是优势(因此才获得特征不变性,以及大幅减少参数数量),所以我们在计算FLOPs是只需在parameters的基础上再乘以feature map的大小即可,即对于某个卷积层,它的FLOPs数量为: [ ( K h ∗ K w ∗ C i n ) ∗ C o u t + C o u t ] ∗ ( H ∗ W ) = n u m _ p a r a m s ∗ ( H ∗ W ) [(K_h * K_w * C_{in}) * C_{out} + C_{out}] * (H * W) = num\_params * (H * W) [(Kh∗Kw∗Cin)∗Cout+Cout]∗(H∗W)=num_params∗(H∗W),其中 n u m _ p a r a m s num\_params num_params表示该层参数的数目。
还是里AlexNet网络第一卷积层为例,它的FLOPs数目为:[(11 * 11 * 3) * 96 + 96] * (55 * 55) = 105,705,600。
对于全连接层,由于不存在权值共享,它的FLOPs数目即是该层参数数目: N i n ∗ N o u t + N o u t N_{in} * N_{out} + N_{out} Nin∗Nout+Nout。
运用上面的规律,我们便可以很轻松地计算出AlexNet网络的parameters和FLOPs数目,如下图(来自网络,出处已不可考):

4 文献阅读
4.1 Deep Learning for Person Re-identification: A Survey and Outlook
首先阅读的是一篇综述,这篇综述还是比较有价值的,对于ReID做了一个详细的汇总,初学者可以尝试精读这篇文章:
Ye, M., Shen, J., Lin, G., Xiang, T., Shao, L., & Hoi, S. C. (2020). Deep learning for person re-identification: A survey and outlook. arXiv preprint arXiv:2001.04193.10
4.1.1 Abstract:

主要的工作:
- 分类:封闭世界、开放世界
- 三个不同的角度:深度特征表示学习、深度度量学习和排名优化
- 一种有效的方法:AGW
- 新的评价指标:mINP
4.1.2 Intorduction
-
Represent by: image, video, text
-
Challenge: 不同的视角、分辨率、光照、姿势、遮挡、异构的模式
-
传统方法的一篇综述:11
-
ReID的一般步骤:
- 原始数据收集
- Bounding box: person detection or tracking algorithms
- Annotation
- 训练模型:feature representation learning or distance metric learning
- Pedestrian retrieval: ranking optimization

-
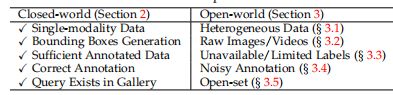
开放世界与封闭世界的区别:
- Single-modality vs. Heterogeneous Data: 这一部分我是这么理解的,就是数据集中的摄像头大部分都是同一款型的,但实际生活中不同的摄像头拍出的照片有不同的风格
- Bounding Box Generation vs. Raw Images/Videos: 现实没有人标注bounding box,需要自己生成,使用end-to-end的方法
- Sufficient Annotated Data vs. Unavailable/Limited Labels: 需要unsupervised and semi-supervised的方法
- Correct Annotation vs. Noisy Annotation: 可能存在的错误标注
- Query Exists in Gallery vs. Open-set: 现实中query中存在的可能在gallery中并不存在
4.1.3 Close-world ReID
- close world 的假设:
- 外貌信息可以被掌握
- 每个人都被bounding boxes表示
- 足够的标注过的数据
- 标注大部分是正确的
- query中的人一定出现在gallery中
- close world方法的组成:
- 特征表示
- deep metric learning(我的理解就是选择不同的loss function之类的)
- 排名优化
4.1.3.1 Feature representation learning

主要有以下几种:
- 全局特征学习,利用全身的全局图像来进行特征学习,常见的改进思路有Attention机制,多尺度融合等
- 局部特征学习,利用局部图像区域(行人部件或者简单的垂直区域划分)来进行特征学习,并聚合生成最后的行人特征表示;
- 辅助特征学习,利用一些辅助信息来增强特征学习的效果,如语义信息(比如行人属性等)、视角信息(行人在图像中呈现的不同方位信息)、域信息(比如每一个摄像头下的数据表示一类域)、GAN生成的信息(比如生成行人图像)、数据增强等;
- 视频特征学习:利用一些视频数据提提取时序特征,并且融合多帧图像信息来构建行人特征表达
- 特定的网络设计:利用Re-ID任务的特性,设计一些细粒度,多尺度等相关的网络结构,使其更适用于Re-ID的场景。
4.1.3.2 Deep Metric Learning

早期的度量学习主要是设计不同类型的距离/相似度度量矩阵。深度学习时代,主要包括不同类型的损失函数的设计及采样策略的改进:
- Identity Loss: 将Re-ID的训练过程当成图像分类问题,同一个行人的不同图片当成一个类别,常见的有Softmax交叉熵损失函数;
- Verification Loss:将Re-ID的训练当成图像匹配问题,是否属于同一个行人来进行二分类学习,常见的有对比损失函数,二分类损失函数;
- Triplet Loss:将Re-ID的训练当成图像检索问题,同一个行人图片的特征距离要小于不同行人的特征距离,以及其各种改进;
- 训练策略的改进:自适应的采样方式(样本不均衡,难易程度)以及不同的权重分配策略
4.1.3.3 Ranking Optimization

用学习好的Re-ID特征得到初始的检索排序结果后,利用图片之间的相似性关系来进行初始的检索结果优化,主要包括重排序(re-ranking)和排序融合
4.1.3.4 Datasets and evaluation
主要包括现有的一些常用图像和视频数据集的概括,以及现有方法SOTA的一些总结和分析:

4.1.4 Open-World Re-ID
由于常规的 Closed-world Re-ID 在有监督的实验场景中已经达到或接近瓶颈了,现在很多的研究都更偏向于 Open-World Re-ID 场景,也是当前Re-ID研究的热点。根据Re-ID系统设计的五个步骤,本章节也从以下五个方面介绍:
- 多模态数据,所采集的数据不是单一的可见光模态
- 端到端的行人检索(End-to-end Person Search),没有预先检测或跟踪好的行人图片/视频
- 无监督和半监督学习,标注数据有限或者无标注的新场景
- 噪声标注的数据,即使有标注,但是数据采集和标注过程中存在噪声或错误;
- 一些其他Open-set场景,查询行人找不到,群体重识别,动态的多摄像头网络等。
4.1.4.1 多模态(异构)数据
- 基于深度图像Re-ID:旨在利用深度图信息的匹配(融合或跨模态匹配),在很多人机交互的室内场景应用中非常重要;
- 文本到图像Re-ID;旨在利用文字语言描述来搜索特定的行人图像,解决实际场景中查询行人图像缺失等问题;
- 可见光到红外Re-ID:旨在跨模态匹配白天的可见光图像到夜晚的红外行人图像,也有一些方法直接解决低照度的重识别任务;
- 跨分辨率Re-ID;不同高低分辨率行人图像匹配,旨在解决不同距离摄像头下行人分辨率差异巨大等问题
总体而言,异构的行人重识别问题需要解决的一大难题是不同模态数据之间的差异性问题
4.1.4.2 端到端Re-ID(End-to-end Person Search)
- 纯图像/视频的Re-ID;从原始raw 图像或者视频中直接检索出行人;
- 多摄像头跟踪的Re-ID;跨摄像头跟踪,也是很多产业化应用的重点。
4.1.4.3 半监督和无监督的Re-ID
为了缓解对标注数据的依赖,半监督和无监督/自监督现在成为了当前研究的热点,在CV顶会上呈爆炸之势。本文也主要分成两个部分:无监督Re-ID(不需要标注的源域)和无监督域自适应Re-ID(需要标注的源域数据或模型):
- 无监督Re-ID:主要包括一些跨摄像头标签估计(聚类或图匹配等)的方法,以及一些其他监督信息挖掘的方法(如local patch相似性等);
- 无监督域自适应Re-ID:包括一些目标域图像数据生成和一些目标域监督信息挖掘等方式。
考虑到无监督学习也是现在研究的热点,本文也对现有的SOTA做了一个简单的总结和分析,可以看到现在的无监督学习方法已经是效果惊人了,未来可期。如下表所示:

4.1.4.4 噪声鲁棒的Re-ID
主要针对标注数据或者数据采集中产生的一些噪声或错误等,方法包括:
- Partial Re-ID:解决行人图像区域部分被遮挡的行人重识别问题;
- Noise Sample:主要针对行人图像或视频中检测、跟踪产生的错误或偏差
- Noise Label:主要针对行人标签标注产生的错误
4.1.4.5 Open-set Re-ID and Beyond
主要针对一些其他开放场景进行一些探讨,如
- allery set 中query 行人没有出现的场景;
- Group Re-ID:行人群体匹配的问题;
- 动态的多摄像头网络匹配等问题
4.1.5 展望
4.1.5.1 新的评价指标mINP:

考虑到实际场景中,目标人物具有隐匿性,很多时候要找到其困难目标都非常难,给侦查工作带来麻烦。mINP主要目的是为了衡量Re-ID算法用来找到最难匹配样本所要付出的代价:
m I N P = 1 n ∑ i ( 1 − N P i ) = 1 n ∑ i ∣ G i ∣ R i hard \mathrm{mINP}=\frac{1}{n} \sum_{i}\left(1-\mathrm{NP}_{i}\right)=\frac{1}{n} \sum_{i} \frac{\left|G_{i}\right|}{R_{i}^{\text {hard }}} mINP=n1i∑(1−NPi)=n1i∑Rihard ∣Gi∣
排名倒数第一的正确样本位置越靠后,人工排查干预的代价越大,mINP的值越小
4.1.5.2 AGW:

主要包括:
- Non-local注意力机制的融合
- Generalized-mean (GeM) Pooling的细粒度特征提取;
- 加权正则化的三元组损失(Weighted Regularization Triplet (WRT) loss)

4.1.5.3 对未来一些研究方向的思考
这一部分也是紧扣前面提出的五个步骤,针对五个步骤未来亟待解决的关键问题或者热点问题进行归纳。由于每个人理解上的认知偏差,这里的建议仅供大家参考:
- 不可控的数据采集:不确定多种模态混合的Re-ID,而不是固定的模态设置;换装的Re-ID,2020年已经有好几个新的数据集;
- 减少人工标注依赖:人机交互的主动学习,选择性的标注;从虚拟数据进行学习(Learning from virtual data),如何解决虚拟数据中的domain gap;
- 面向Re-ID通用网络设计:Domain Generalized Re-ID,如何设计一种在未知场景中也表现优异的模型,如何利用自动化机器学习来设计针对Re-ID任务的网络模型;
- 动态的模型更新:如何以小的代价将学习好的网络模型微调至新摄像头场景中;如何高效的利用新采集的数据(Newly Arriving Data)来更新之前已训练好的模型;
- 高效的模型部署:轻量型快速的行人重识别算法设计,自适应的针对不同类型的硬件配置(小型的移动手机和大型服务器)调整模型。
https://zhuanlan.zhihu.com/p/163255539 ↩︎
https://blog.csdn.net/weixin_41427758/article/details/81188164 ↩︎ ↩︎ ↩︎
https://blog.csdn.net/wlx19970505/article/details/101051278 ↩︎
https://github.com/NEU-Gou/awesome-reid-dataset ↩︎
https://blog.csdn.net/hyk_1996/article/details/79387053 ↩︎
https://blog.csdn.net/ctwy291314/article/details/83544088 ↩︎
https://blog.csdn.net/qq_34132310/article/details/83869605 ↩︎
https://blog.csdn.net/baidu_39622935/article/details/82814027 ↩︎
https://wrong.wang/blog/20190223-reid%E4%BB%BB%E5%8A%A1%E4%B8%AD%E7%9A%84cmc%E5%92%8Cmap/ ↩︎
https://arxiv.org/abs/2001.04193 ↩︎
https://arxiv.org/abs/1610.02984 ↩︎