这 8 个 Python 技巧让你的数据分析提升数倍!
不管是参加Kaggle比赛,还是开发一个深度学习应用,第一步总是数据分析,这篇文章介绍了8个使用Python进行数据分析的方法,不仅能够提升运行效率,还能够使代码更加“优美”。
一行代码定义List
定义某种列表时,写For 循环过于麻烦,幸运的是,Python有一种内置的方法可以在一行代码中解决这个问题。
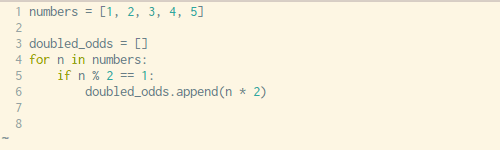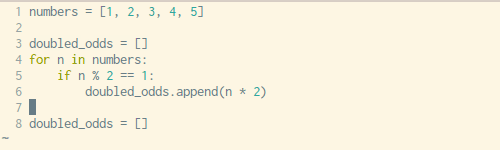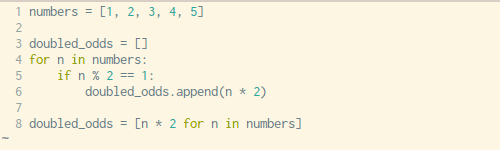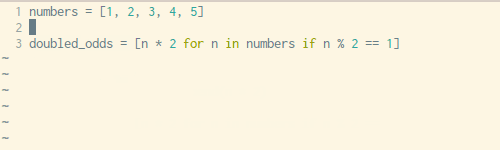
下面是使用For循环创建列表和用一行代码创建列表的对比。
x = [1,2,3,4]
out = []
for item in x:
out.append(item**2)
print(out)
[1, 4, 9, 16]
# vs.
x = [1,2,3,4]
out = [item**2 for item in x]
print(out)
[1, 4, 9, 16]
Lambda表达式
厌倦了定义用不了几次的函数?Lambda表达式是你的救星!Lambda表达式用于在Python中创建小型,一次性和匿名函数对象。它能替你创建一个函数。
lambda表达式的基本语法是:
lambda arguments: expression
请注意,只要有一个lambda表达式,就可以完成常规函数可以执行的任何操作。你可以从下面的例子中,感受lambda表达式的强大功能:
double = lambda x: x * 2
print(double(5))
10
Map和Filter
一旦掌握了lambda表达式,学习将它们与Map和Filter函数配合使用,可以实现更为强大的功能。
具体来说,map通过对列表中每个元素执行某种操作并将其转换为新列表。在本例中,它遍历每个元素并乘以2,构成新列表。请注意,list()函数只是将输出转换为列表类型。
# Map
seq = [1, 2, 3, 4, 5]
result = list(map(lambda var: var*2, seq))
print(result)
[2, 4, 6, 8, 10]
Filter函数接受一个列表和一条规则,就像map一样,但它通过比较每个元素和布尔过滤规则来返回原始列表的一个子集。
# Filter
seq = [1, 2, 3, 4, 5]
result = list(filter(lambda x: x > 2, seq))
print(result)
[3, 4, 5]
Arange和Linspace
Arange返回给定步长的等差列表。它的三个参数start、stop、step分别表示起始值,结束值和步长, 请注意,stop点是一个“截止”值,因此它不会包含在数组输出中。
# np.arange(start, stop, step)
np.arange(3, 7, 2)
array([3, 5])
Linspace和Arrange非常相似,但略有不同。Linspace以指定数目均匀分割区间。所以给定区间start和end,以及等分分割点数目num,linspace将返回一个NumPy数组。这对绘图时数据可视化和声明坐标轴特别有用。
# np.linspace(start, stop, num)
np.linspace(2.0, 3.0, num=5)
array([ 2.0, 2.25, 2.5, 2.75, 3.0])
Axis代表什么?
在Pandas中,删除一列或在NumPy矩阵中求和值时,可能会遇到Axis。我们用删除一列(行)的例子:
df.drop( Column A , axis=1)
df.drop( Row A , axis=0)
如果你想处理列,将Axis设置为1,如果你想要处理行,将其设置为0。但为什么呢?回想一下Pandas中的shape
df.shape
(# of Rows, # of Columns)
从Pandas DataFrame中调用shape属性返回一个元组,第一个值代表行数,第二个值代表列数。如果你想在Python中对其进行索引,则行数下标为0,列数下标为1,这很像我们如何声明轴值。
Concat,Merge和Join
如果您熟悉SQL,那么这些概念对您来说可能会更容易。无论如何,这些函数本质上就是以特定方式组合DataFrame的方式。在哪个时间跟踪哪一个最适合使用可能很困难,所以让我们回顾一下。
Concat允许用户在表格下面或旁边追加一个或多个DataFrame(取决于您如何定义轴)。
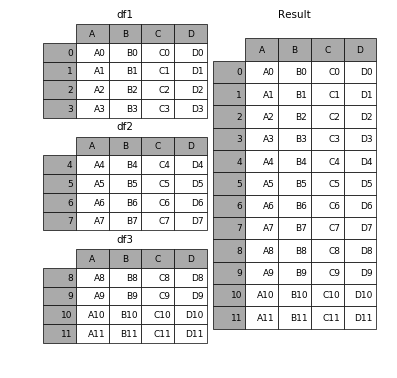
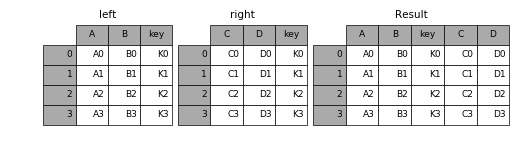
Merge将多个DataFrame合并指定主键(Key)相同的行。
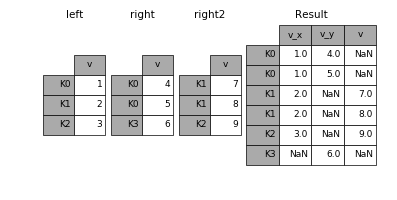
Join,和Merge一样,合并了两个DataFrame。但它不按某个指定的主键合并,而是根据相同的列名或行名合并。
Pandas Apply
Apply是为Pandas Series而设计的。如果你不太熟悉Series,可以将它想成类似Numpy的数组。
Apply将一个函数应用于指定轴上的每一个元素。使用Apply,可以将DataFrame列(是一个Series)的值进行格式设置和操作,不用循环,非常有用!
df = pd.DataFrame([[4, 9],] * 3, columns=[ A , B ])
df
A B
0 4 9
1 4 9
2 4 9
df.apply(np.sqrt)
A B
0 2.0 3.0
1 2.0 3.0
2 2.0 3.0
df.apply(np.sum, axis=0)A 12
B 27
df.apply(np.sum, axis=1)
0 13
1 13
2 13
Pivot Tables
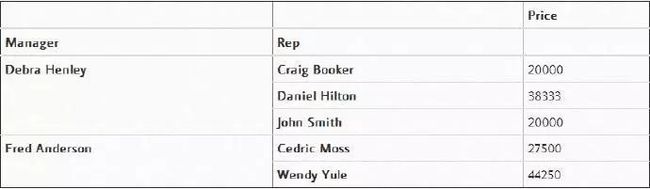
最后是Pivot Tables。如果您熟悉Microsoft Excel,那么你也许听说过数据透视表。Pandas内置的pivot_table函数以DataFrame的形式创建电子表格样式的数据透视表,,它可以帮助我们快速查看某几列的数据。下面是几个例子:非常智能地将数据按照“Manager”分了组
pd.pivot_table(df, index=["Manager", "Rep"])
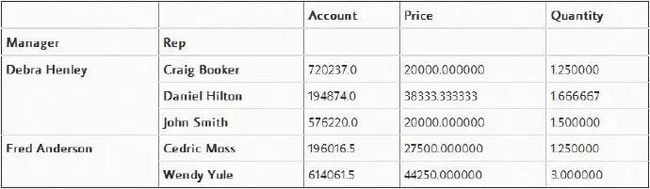
或者也可以筛选属性值
pd.pivot_table(df,index=["Manager","Rep"],values=["Price"])
总结
我希望上面的这些描述能够让你发现Python一些好用的函数和概念。
原文链接:
https://towardsdatascience.com/python-for-data-science-8-concepts-you-may-have-forgotten-i-did-825966908393
![]()