HorNet
又发现了个清华神器哦~~
一种基于递归的门控卷积的通用视觉模型,是来自清华大学周杰老师,鲁继文老师团队,以及 Meta AI 的学者们在通用视觉模型方面有价值的探索。精度超越ConvNeXt的新CNN,厉害把
1 HorNet:通过递归门控卷积实现高效高阶的空间信息交互
论文名称:HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions
论文地址:
http://arxiv.org/pdf/2207.14284.pdf
1.1 HorNet 原理分析
1.1.1 背景和动机
本文提出了一种基于递归的门控卷积的通用视觉模型,是来自清华大学周杰老师,鲁继文老师团队,以及 Meta AI 的学者们在通用视觉模型方面有价值的探索。
卷积神经网络 (CNN) 推动了深度学习和计算视觉领域的显著进步。CNN 因其自身固有的一系列优良的特性,使得它们很自然地适合很多种计算机视觉任务。比如一种特性是平移不变性 (Translation equivariance),这种特性为 CNN 模型引入了归纳偏置 (inductive bias),使之能够适应不同大小的输入图片的尺寸。与此同时,CNN 因为发展已久,社区已经贡献了很多高度优化的实现方案,这些方案使得它在高性能的 GPU 和边缘设备上都非常高效。
视觉 Transformer 模型的发展也撼动了 CNN 的统治地位,通过借鉴 CNN 中的一些优秀的架构设计思路 (金字塔结构,归纳偏置,残差连接等) 和训练策略 (知识蒸馏等),视觉 Transformer 模型已经在图像分类,目标检测,语义分割等等下游任务中取得了不输 CNN 的卓越性能。
人们不禁想问:究竟是什么使得视觉 Transformer 模型比 CNN 性能更强?
其实这个问题很难回答得好,但是我们其实也并不需要完全解答这个问题,可以先从反过来借鉴视觉 Transformer 模型的特点来设计更强大的 CNN 模型开始。
比如,视觉 Transformer 的架构设计一般来将遵循一个 meta architecture,就是虽然 token mixer 的类型会有不同 (Self-attention,Spatial MLP,Window-based Self-attention 等等),但是基本的宏观架构一般都是由4个 stage 组成的金字塔架构。比如:
-
ConvNeXt[1] 借鉴了这样一套宏观架构,并结合 7×7 的 Depth-wise Convolution 构建了一系列高性能的 CNN 架构。
-
GFNet[2] 借鉴了这样一套宏观架构,并结合 2D-FFT 的傅里叶变换和 2D-IFFT 的反变换构建了一系列高性能的通用 Backbone 架构。
-
RepLKNet[3] 借鉴了这样一套宏观架构,并结合 31×31 的超大核卷积操作以及结构重参数化的方案构建了一系列高性能的通用 Backbone 架构。
在一个模型的特征中间,其任意的两个空间位置之间可能存在着复杂和高阶的相互作用,但是这种相互作用也希望模型中显式地建模出来。而 Self-attention 的成功其实就证明了:显式地建模高阶的相互作用有利于提升模型的表达能力。
但是在卷积神经网络中,似乎还没有最近的工作注意到了要显式地建模高阶的相互作用,这也是本文的动机。
1.1.2 HorNet 简介
如下图1所示是本文核心思想图解:通过这张图分析不同操作中特征 (红色块) 和它周围的区域 (灰色块) 的交互。(a) 普通卷积操作不考虑空间的信息交互。(b) 动态卷积操作借助动态权重,考虑周边的区域的信息交互,使得模型性能更强。(c) Self-attention 操作通过 query,key 和 value 之间的两个连续的矩阵乘法实现了二阶的空间信息交互。(d) 本文所提出的方法可以借助门控卷积和递归操作高效地实现任意阶数的信息交互。可视化建模的基本操作趋势表明,模型的表达能力可以通过增加空间相互作用的阶数来提高。
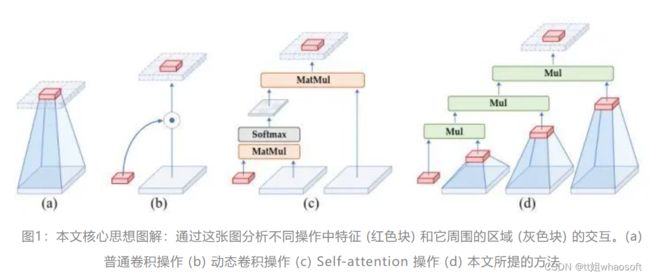
在本文中,作者把视觉 Transformer 成功的关键因素归结为动态权重 (指的是 attention 矩阵的值与具体的输入有关,input-adaptive),长距离建模 (long-range) 和高阶的空间交互 (high-order)。之前的工作 ConvNeXt[1],GFNet[2] ,RepLKNet[3]都满足了动态权重和长距离建模这两条性质,但是却没有考虑到如何使得一个卷积神经网络实现高阶的空间交互。
 视觉 Transformer 用来混合空间 token 信息的 Self-attention 矩阵的权重是与输入相关的。但是 Self-attention 的复杂度是和图片的输入分辨率成二次性相关的,在需要高分辨率的下游任务上面带来的计算代价是很大的。在这个工作里面,作者采用高效的卷积和全连接层来执行空间的信息交互。
视觉 Transformer 用来混合空间 token 信息的 Self-attention 矩阵的权重是与输入相关的。但是 Self-attention 的复杂度是和图片的输入分辨率成二次性相关的,在需要高分辨率的下游任务上面带来的计算代价是很大的。在这个工作里面,作者采用高效的卷积和全连接层来执行空间的信息交互。




1.1.6 通过大卷积核进行长距离的交互

-
7×7 Depth-wise 卷积 (ConvNeXt[1]):是 Swin 和 ConvNeXt 的默认感受野大小。已经被验证在多种视觉任务上表现出了优良的性质。PyTorch 代码如下:
def get_dwconv(dim, kernel, bias):
return nn.Conv2d(dim, dim, kernel_size=kernel, padding=(kernel-1)//2 ,bias=bias, groups=dim)
-
Global Filter (GFNet[2]):通过 2D-FFT 将特征从空域转化到频域中,而频域中 Element-wise 的相乘操作等价于空域中一个具有全局核大小和圆形填充的空间域卷积。在实际实现的时候把 channel 分成两部分,一部分通过 Global Filters,另一部分通过 3×3 Depth-wise Convolution。PyTorch 代码如下:
class GlobalLocalFilter(nn.Module):
def __init__(self, dim, h=14, w=8):
super().__init__()
self.dw = nn.Conv2d(dim // 2, dim // 2, kernel_size=3, padding=1, bias=False, groups=dim // 2)
self.complex_weight = nn.Parameter(torch.randn(dim // 2, h, w, 2, dtype=torch.float32) * 0.02)
trunc_normal_(self.complex_weight, std=.02)
self.pre_norm = LayerNorm(dim, eps=1e-6, data_format='channels_first')
self.post_norm = LayerNorm(dim, eps=1e-6, data_format='channels_first')
def forward(self, x):
x = self.pre_norm(x)
x1, x2 = torch.chunk(x, 2, dim=1)
x1 = self.dw(x1)
x2 = x2.to(torch.float32)
B, C, a, b = x2.shape
x2 = torch.fft.rfft2(x2, dim=(2, 3), norm='ortho')
weight = self.complex_weight
if not weight.shape[1:3] == x2.shape[2:4]:
weight = F.interpolate(weight.permute(3,0,1,2), size=x2.shape[2:4], mode='bilinear', align_corners=True).permute(1,2,3,0)
weight = torch.view_as_complex(weight.contiguous())
x2 = x2 * weight
x2 = torch.fft.irfft2(x2, s=(a, b), dim=(2, 3), norm='ortho')
x = torch.cat([x1.unsqueeze(2), x2.unsqueeze(2)], dim=2).reshape(B, 2 * C, a, b)
x = self.post_norm(x)
return x

class gnconv(nn.Module):
def __init__(self, dim, order=5, gflayer=None, h=14, w=8, s=1.0):
super().__init__()
self.order = order
self.dims = [dim // 2 ** i for i in range(order)]
self.dims.reverse()
self.proj_in = nn.Conv2d(dim, 2*dim, 1)
if gflayer is None:
self.dwconv = get_dwconv(sum(self.dims), 7, True)
else:
self.dwconv = gflayer(sum(self.dims), h=h, w=w)
self.proj_out = nn.Conv2d(dim, dim, 1)
self.pws = nn.ModuleList(
[nn.Conv2d(self.dims[i], self.dims[i+1], 1) for i in range(order-1)]
)
self.scale = s
print('[gnconv]', order, 'order with dims=', self.dims, 'scale=%.4f'%self.scale)
def forward(self, x, mask=None, dummy=False):
B, C, H, W = x.shape
fused_x = self.proj_in(x)
pwa, abc = torch.split(fused_x, (self.dims[0], sum(self.dims)), dim=1)
dw_abc = self.dwconv(abc) * self.scale
dw_list = torch.split(dw_abc, self.dims, dim=1)
x = pwa * dw_list[0]
for i in range(self.order -1):
x = self.pws[i](x) * dw_list[i+1]
x = self.proj_out(x)
return x
1.1.7 与 Self-attention 之间的联系

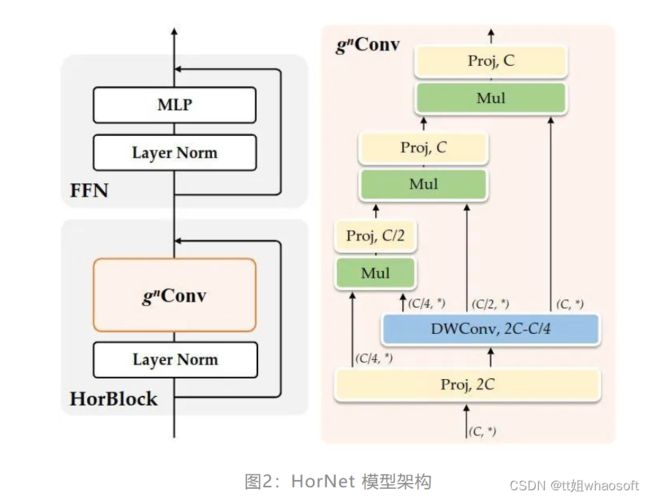
1.1.8 HorNet 模型架构
HorNet

HorFPN

1.1.9 实验结果
ImageNet-1K 图像分类
不使用 ImageNet-22K 预训练的实验设置:直接在 ImageNet-1K 上训练 300 Epochs。
使用 ImageNet-22K 预训练的实验设置:先使用 ImageNet-22K 预训练 90 Epochs,再在 ImageNet-1K 上训练 30 Epochs。
结果如下图3所示。可以看到,HorNet 模型与最先进的 Transformer 和 CNN 相比,实现了极具竞争力的性能,超过了 Swin ConvNeXt。此外,HorNet 模型也很好地推广到更大的图像分辨率、更大的模型尺寸和更多的训练数据,证明了 HorNet 模型的有效性和通用性。
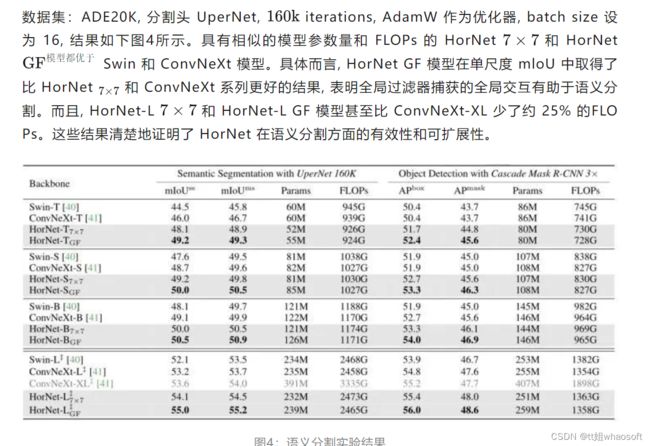
 语义分割实验结果
语义分割实验结果
目标检测和实例分割实验结果
数据集:COCO,分割头 Mask R-CNN,结果如上图4所示。HorNet 模型在 box AP 和 mask AP 都比Swin/ConvNeXt 的同尺寸模型展现出了更好的性能。与 ConvNeXt 相比,HorNetGF 系列获得 +1.2 ~ 2.0 的 box AP 和 +1.0 ~ 1.9 的 mask AP。
密集预测实验结果

whaosoft aiot http://143ai.com
(b) 各向同性架构实验

总结
