MMDet逐行代码解读之ResNet50+FPN
文章目录
- 前言
- 1、ResNet50
-
- 1.1. 构建一个resnet50
- 1.2. 搭建过程
-
- 1.2.1 stem部分
- 1.2.2 ResLayer部分
- 1.2.3 冻结部分参数
- 1.2.4 重写train方法
- 1.3. 前向传播
- 2、FPN
-
- 2.1. 跑个demo
- 2.2. 实现细节
-
- 2.2.1 FPN初始化部分
- 2.2.2 FPN中forward部分
- 2.2.3 额外卷积部分初始化
- 总结
前言
本篇是MMdet逐行解读第五篇。从本篇开始介绍mmdet/models文件夹内容。首先介绍最常用的resnet50+fpn结构。
历史文章如下:
AnchorGenerator解读
MaxIOUAssigner解读
DeltaXYWHBBoxCoder解读
正负样本采样解读
1、ResNet50
1.1. 构建一个resnet50
# 骨架网络构建
from mmdet.models import build_backbone
if __name__ == '__main__':
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0,1,2,3), # 返回四个特征图的索引
frozen_stages=1, # 冻结stem和第一层
# 表示全部的BN需要梯度更新
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True, # 且全局网络的BN进入eval模式
style='pytorch')
resnet50 = build_backbone(backbone)
代码细节先暂时不看,首先打印下resnet50结构:
1.2. 搭建过程
从上节中可以看出,resnet50主要包括两部分:stem部分 + 若干stage的ResLayer + 冻结部分层。实际上在resnet的初始化部分就是按照上述顺序构造resnet50的。我这里截取部分代码:
@BACKBONES.register_module()
class ResNet(nn.Module):
def __init__(self):
super(ResNet, self).__init__()
# 构建stem部分
self._make_stem_layer(in_channels, stem_channels)
# 构建stage个残差层
self.res_layers = []
for i, num_blocks in enumerate(self.stage_blocks):
res_layer = self.make_res_layer()
# 冻结参数
self._freeze_stages()
接下来分别看下各个部分源码
1.2.1 stem部分
这块比较简单:stem部分 = 7*7conv + bn + relu + maxpool。这部分通常只是提取图像低级特征,故一般都需要固定这部分权重。
def _make_stem_layer(self, in_channels, stem_channels):
self.conv1 = build_conv_layer(
self.conv_cfg,
in_channels,
stem_channels,
kernel_size=7,
stride=2,
padding=3,
bias=False)
self.norm1_name, norm1 = build_norm_layer(
self.norm_cfg, stem_channels, postfix=1)
self.add_module(self.norm1_name, norm1)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
1.2.2 ResLayer部分
每层ResLayer内部实际上就是堆叠了若干个Bottleneck。
def make_res_layer(self, **kwargs):
"""Pack all blocks in a stage into a ``ResLayer``"""
return ResLayer(**kwargs) # 调用现成模块构造残差块
1.2.3 冻结部分参数
在讲解之前,先注意一个配置参数:norm_cfg=dict(type=‘BN’, requires_grad=True), 在构造stem和ResLayer时均传入了这个参数,即内部所有BN层均需要梯度更新。即到此为止,resnet50里面的所有BN的参数均需要更新。
继续看另一个参数:frozen_stages。
frozen_stages=-1,表示全部可学习。
frozen_stage=0,表示stem权重固定。
frozen_stages=1,表示 stem 和第一个 stage 权重固定。
frozen_stages=2,表示 stem 和前两个 stage 权重固定。
在来看下该部分代码:
def _freeze_stages(self):
# 若frozen_stages>=0,则必须冻住stem
if self.frozen_stages >= 0:
self.norm1.eval() # BN进入eval模式,使用全局均值和方差
for m in [self.conv1, self.norm1]:
for param in m.parameters():
param.requires_grad = False # 冻结参数
# 冻结特定stage:先eval,之后再冻结参数。
for i in range(1, self.frozen_stages + 1):
m = getattr(self, f'layer{i}')
m.eval() # eval控制BN使用的是全局均值和方差。并没有冻结参数
# 在测试时候也要+eval,否则即使不训练,一轮测试也会
#更新滑动均值和方差的。eval模式下会计算梯度并保存,但是
#不会反传;而加速则需要使用torch.no_grad。
for param in m.parameters():
param.requires_grad = False
【注意】:这里比较纳闷的是为啥eval在冻结参数。eval模式下BN层使用的全局均值和方差,但依旧会计算梯度并保存,但不会反向传播;所以,为了节省GPU和内存,单独在将参数的梯度设置为False;与之相反,若不设置eval模式,BN不使用全局均值和方差,这肯定是错误的。即eval主要影响的是BN。
1.2.4 重写train方法
上述过程只是完成了resnet50的初始化。在评估模型时,可以直接使用冻结好的resnet50;但是在train模式下,resnet50的所有层进入训练模式,白固定了,因此需要重新写train方法。
def train(self, mode=True):
super(ResNet, self).train(mode)
self._freeze_stages() # 重新调用冻结参数方法
# 若需要固定全网络的BN,则需要让所有BN使用eval模式。
if mode and self.norm_eval:
for m in self.modules():
if isinstance(m, _BatchNorm):
m.eval()
另外,注意配置文件最后一个参数norm_eval=True,即让全网络的BN均使用全局均值和方差。
1.3. 前向传播
这部分比较简单,主要注意下配置参数out_indices=(0,1,2,3),即输出对应ResLayer的特征图。
def forward(self, x):
"""Forward function"""
if self.deep_stem:
x = self.stem(x)
else:
x = self.conv1(x)
x = self.norm1(x)
x = self.relu(x)
x = self.maxpool(x)
outs = []
for i, layer_name in enumerate(self.res_layers):
res_layer = getattr(self, layer_name)
x = res_layer(x)
if i in self.out_indices: # 保存对应特征图
outs.append(x)
return tuple(outs)
这里简单写个测试代码:
x = torch.randn(1,3,64,64)
outputs = resnet50(x)
for out in outputs:
print(out.shape)
#torch.Size([1, 256, 16, 16])
#torch.Size([1, 512, 8, 8])
#torch.Size([1, 1024, 4, 4])
#torch.Size([1, 2048, 2, 2])
同理,若将out_indices=(3,),则将返回最后一个特征图。[1,2048,2,2]。
2、FPN
2.1. 跑个demo
from mmdet.models import build_neck
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048], # 接收输入特征图的通道数
out_channels=256, # FPN的各个特征图的输出通道数
start_level=1, # 从1号输入特征图开始fpn
add_extra_convs='on_input',
num_outs=5) # 控制输出特征图个数
fpn = build_neck(neck).eval()
# 构造四个虚拟的输入
in_channels = [256, 512, 1024, 2048]
scales = [16, 8, 4, 2]
inputs = [torch.rand(1, c, s, s) for c, s in zip(in_channels, scales)]
outputs = fpn(inputs)
for i in range(len(outputs)):
print(f'outputs[{i}].shape = {outputs[i].shape}')
'''
outputs[0].shape = torch.Size([1, 256, 8, 8])
outputs[1].shape = torch.Size([1, 256, 4, 4])
outputs[2].shape = torch.Size([1, 256, 2, 2])
outputs[3].shape = torch.Size([1, 256, 1, 1])
outputs[4].shape = torch.Size([1, 256, 1, 1])
'''
这里我手绘了一张图来展示上述参数是如何控制FPN的。
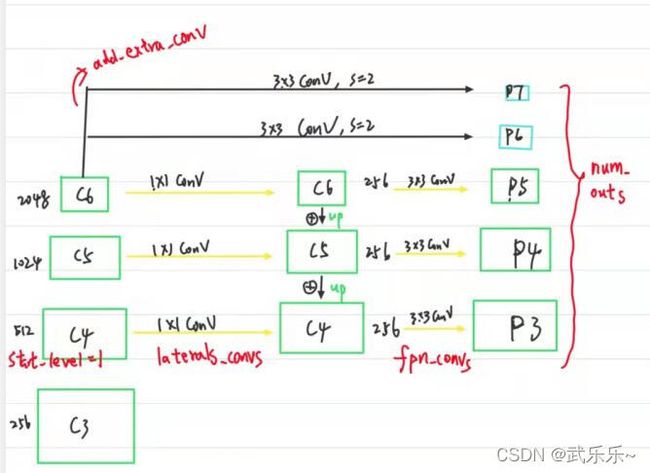
下面逐个介绍下参数:
1)start_level=1: 是从Backbone返回的输入特征图的第二个开始也就是C4;本例中表示的是:经过ResNet的stem + layer1 + layer2之后的特征图。
2)add_extra_convs = ‘on_input’: 是在输入特征图的最后一个C6上额外在多执行几次conv。
3)num_outs=5 输出P3-P7五个特征图;其中由于start_level=1故只能由C4-C6得到P3-P5,在额外多了P6和P7。
2.2. 实现细节
在理解了各个参数后,来看下核心代码:
2.2.1 FPN初始化部分
self.lateral_convs = nn.ModuleList() # C4/5/6-C4/5/6 的1*1卷积
self.fpn_convs = nn.ModuleList() # C4/5/6-P4/5/6 的3*3卷积
# 遍历开始level和结束level,来往里面添加卷积核
for i in range(self.start_level, self.backbone_end_level):
l_conv = ConvModule(
in_channels[i],
out_channels,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg if not self.no_norm_on_lateral else None,
act_cfg=act_cfg,
inplace=False)
fpn_conv = ConvModule(
out_channels,
out_channels,
3,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg,
inplace=False)
self.lateral_convs.append(l_conv)
self.fpn_convs.append(fpn_conv)
2.2.2 FPN中forward部分
# 首先经过1*1卷积得到将C3-C5特征图变成相同的通道数
laterals = [
lateral_conv(inputs[i + self.start_level])
for i, lateral_conv in enumerate(self.lateral_convs)
]
# 向上插值在相加
used_backbone_levels = len(laterals)
for i in range(used_backbone_levels - 1, 0, -1):
if 'scale_factor' in self.upsample_cfg:
laterals[i - 1] += F.interpolate(laterals[i],
**self.upsample_cfg)
else:
prev_shape = laterals[i - 1].shape[2:]
laterals[i - 1] += F.interpolate(
laterals[i], size=prev_shape, **self.upsample_cfg)
# 经过3*3卷积得到P3-P5
# part 1: from original levels
outs = [
self.fpn_convs[i](laterals[i]) for i in range(used_backbone_levels)
]
2.2.3 额外卷积部分初始化
# 计算需要几个额外的特征图
extra_levels = num_outs - self.backbone_end_level + self.start_level
if self.add_extra_convs and extra_levels >= 1:
for i in range(extra_levels):
# 获取C6的特征图通道数
if i == 0 and self.add_extra_convs == 'on_input':
in_channels = self.in_channels[self.backbone_end_level - 1]
else:
in_channels = out_channels
# 添加卷积
extra_fpn_conv = ConvModule(
in_channels,
out_channels,
3,
stride=2,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg,
inplace=False)
self.fpn_convs.append(extra_fpn_conv) # 添加到fpn里
总结
慢慢写。若有问题欢迎+vx:wulele2541612007,拉你进群探讨交流。