DeformableDetr论文简介+mmdet源码解读
文章目录
- 前言
- 一、论文解读
-
- 1.1. 研究问题
- 1.2. 可形变注意力模块
- 1.3. 拓展到多层特征图
- 二、 mmdet源码讲解
-
- 2.1. 图像特征提取
- 2.2. 生成mask和位置编码
- 2.3. 送入Transformer
- 2.3.1. Transformer初始化部分
- 2.3.2. Transformer的forward方法
- 2.3.3. Transformer的encoder部分
- 2.3.4. Transformer的decoder部分
- 2.4. 预测bbox阶段
- 总结
前言
论文地址
本篇博客内容有点儿多,包含论文解读和源码解读两部分,当然,限于篇幅原因,本人不可能做到面面俱到。不过大家若想厘清Transformer–>detr–>deforable detr的过程,墙裂推荐可以先看下两篇本人博客,因为Deformable detr很多继承自Detr,而Detr继承自Transfomer。
mmdet之detr源码解读
nn.Transformer实现简单的机器翻译任务
一、论文解读
1.1. 研究问题
主要为了克服1)训练时间长(这个问题出现原因有好几篇论文研究,比如DAB-Detr或DN-Detr);2)detr限于计算复杂度的原因仅用一层特征图,没用FPN对小目标检测不友好。
核心就是如何降低计算复杂度,因为MultiHeadAttn属于hw个高维度的特征向量相互进行密集运算,所以本文借鉴可形变卷积思想,让每个特征向量不要和其余所有像素点进行计算,而是通过网络学习出K个采样点来进行注意力计算,从而降低了复杂度。
1.2. 可形变注意力模块
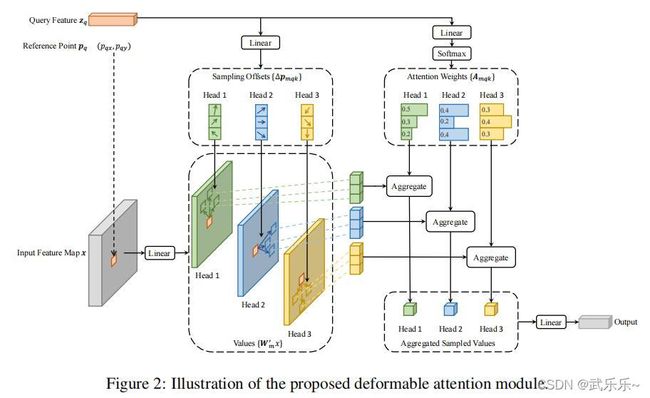
简述下流程:在得到特征图x上的参考点p位置的特征向量zq之后,首先经过线性层变换预测得到三组偏移量offset,然后将三组偏移量添加到位置p上来得到采样后的位置,之后经过插值提取出对应位置的特征向量作为v;同时zq经过线性变换+softmax得到相似度矩阵,并和v做乘法得到最终output。
1.3. 拓展到多层特征图
为了在Detr中引入多层特征图,作者将上述模块拓展到多层特征图。举个简单例子:假设有三层特征图f1-f3。假如现在计算特征图f1上参考点p1的注意力,那么首先将p1位置经过归一化后得到p1在f2,f3上的参考点位置p2,p3。同时提取出p1位置的特征向量zq,然后zq分别预测出p1,p2,p3位置的多头偏移量,并通过插值得到各个修正位置后的特征向量v1,v2,v3。最后经过softmax并将zq和v相乘便能得到融合后的特征向量q。
二、 mmdet源码讲解
2.1. 图像特征提取
该部分没有用到FPN,仅仅用到了多层特征图,并将各个特征图的通道数统一变成256。这部分代码比较简单,我这里只贴下配置文件。若不理解可参考:mmdet逐行解读ResNet。
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(1, 2, 3), # 用到了三层特征图
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=False),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
type='ChannelMapper',
in_channels=[512, 1024, 2048],
kernel_size=1,
out_channels=256, # 将输入特征图的通道数目统一变成256
act_cfg=None,
norm_cfg=dict(type='GN', num_groups=32),
num_outs=4)
2.2. 生成mask和位置编码
在得到多层尺寸不一特征图后,首先给每层特征图创建一个mask矩阵(不计算pad部分图像的注意力),并为各个特征图创建了位置编码。生成位置编码部分详见:mmdet之detr源码解读。
# mlvl_feats是个元祖,各个元素是特征图。每个元素shape = [b,c,h,w]
batch_size = mlvl_feats[0].size(0)
input_img_h, input_img_w = img_metas[0]['batch_input_shape']
# 创建一个全1的尺寸为pad后图像的mask矩阵
img_masks = mlvl_feats[0].new_ones((batch_size, input_img_h, input_img_w))
# 遍历每个图像,将原始图像部分设置为0,1的位置表示pad部分
for img_id in range(batch_size):
img_h, img_w, _ = img_metas[img_id]['img_shape']
img_masks[img_id, :img_h, :img_w] = 0
# 遍历每张特征图的尺寸,来对每个img_masks进行采样
mlvl_masks = []
mlvl_positional_encodings = []
for feat in mlvl_feats:
mlvl_masks.append(
# 这里将img_masks扩充了一个维度:[b,h,w]-->[1,b,h,w],此时的b视为通道,即需要在
# 每个通道上进行上采样,所产生的效果就是分别为每个mask进行了对应的采样。
F.interpolate(img_masks[None],size=feat.shape[-2:]).to(torch.bool).squeeze(0))
# 为每个特征图生成了对应的位置编码,每个位置对应一个256维的位置编码信息:[b,256,h,w]
mlvl_positional_encodings.append(self.positional_encoding(mlvl_masks[-1]))
2.3. 送入Transformer
在得到特征图,位置编码之后,便可送入Transformer。其中各个参数含义我已经注释好了。接下来是Deformable detr的核心。
# 初始化query:[300,512]
self.query_embedding = nn.Embedding(self.num_query,self.embed_dims * 2)
hs, init_reference, inter_references, \
enc_outputs_class, enc_outputs_coord = self.transformer(
mlvl_feats, # tuple([b,c,h1,w1],[b,c,h2,w2],[b,c,h3,w3])
mlvl_masks, # list([b,h1,w1],[b,h2,w2],[b,h3,w3])
query_embeds, # 由nn.Embedding生成的shape:[300,512]
mlvl_positional_encodings, # list([b,256,h1,w1],[b,256,h2,w2],[b,256,h3,w3])
reg_branches=self.reg_branches if self.with_box_refine else None, # None
cls_branches=self.cls_branches if self.as_two_stage else None # None
)
2.3.1. Transformer初始化部分
首先,transformer在初始化过程中创建了两个张量:层编码:[4个特征层,256]; 参考点的线性层:nn.Liear(256,2),参考点含义后续用到在进行说明。 注意此处的levle_embed使用nn.Parameter()进行了封装,故层级编码需要梯度更新。
def init_layers(self):
"""Initialize layers of the DeformableDetrTransformer."""
self.level_embeds = nn.Parameter(
torch.Tensor(self.num_feature_levels, self.embed_dims)) # level_embedding:[4,256]
else:
self.reference_points = nn.Linear(self.embed_dims, 2) # [256,2]
然后看forward部分,也就是接收了来自上节中的forward参数。
2.3.2. Transformer的forward方法
在forward函数内部,首先将多层特征图mlvl_feats、多层特征图有效掩码mlvl_masks、多层特征图的位置嵌入mlvl_positional_encodings三个list进行了拉平并拼接操作。
feat_flatten = torch.cat(feat_flatten, 1) # [b,sum(hw),256]
mask_flatten = torch.cat(mask_flatten, 1) # [b,sum(hw)]
# [b,sum(hw),256]此时已经添加过层级编码,我没贴那行代码
lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1)
# 每张特征图的尺寸[[h1,w1],[h2,w2],[h3,w3],[h4,w4]]
spatial_shapes = torch.as_tensor(
spatial_shapes, dtype=torch.long, device=feat_flatten.device)
# 找出每张特征图开始的的位置[0,9680,12120,12740]
level_start_index = torch.cat((spatial_shapes.new_zeros(
(1, )), spatial_shapes.prod(1).cumsum(0)[:-1]))
# 得到每张特征图的有效宽高比例: [b,4,2]--> 每张特征图的有效宽高
valid_ratios = torch.stack(
[self.get_valid_ratio(m) for m in mlvl_masks], 1)
'''
valid_ratios =
tensor([[[1.0000, 1.0000],
[1.0000, 1.0000],
[1.0000, 1.0000],
[1.0000, 1.0000]],
[[0.7638, 1.0000],
[0.7656, 1.0000],
[0.7812, 1.0000],
[0.8125, 1.0000]]], device='cuda:0')
'''
到此为止还没有结束,还需要获取各个特征图上参考点的位置,即特征图上每个像素点的位置。 获取特征图上所有像素点的位置通过以下函数:
def get_reference_points(spatial_shapes, valid_ratios, device):
"""Get the reference points used in decoder.
Args:
spatial_shapes (Tensor): The shape of all
feature maps, has shape (num_level, 2).
valid_ratios (Tensor): The radios of valid
points on the feature map, has shape
(bs, num_levels, 2)
device (obj:`device`): The device where
reference_points should be.
Returns:
Tensor: reference points used in decoder, has \
shape (bs, num_keys, num_levels, 2).
"""
reference_points_list = []
for lvl, (H, W) in enumerate(spatial_shapes):
# 获取每个参考点中心横纵坐标
ref_y, ref_x = torch.meshgrid(
torch.linspace(
0.5, H - 0.5, H, dtype=torch.float32, device=device),
torch.linspace(
0.5, W - 0.5, W, dtype=torch.float32, device=device))
# 将横纵坐标进行归一化
ref_y = ref_y.reshape(-1)[None] / (
valid_ratios[:, None, lvl, 1] * H)
ref_x = ref_x.reshape(-1)[None] / (
valid_ratios[:, None, lvl, 0] * W)
# ref: [1,12,2]
ref = torch.stack((ref_x, ref_y), -1)
reference_points_list.append(ref)
reference_points = torch.cat(reference_points_list, 1) # [1,60,2]
# 将参考点的位置映射到有效区域
reference_points = reference_points[:, :, None] * valid_ratios[:, None]
return reference_points
2.3.3. Transformer的encoder部分
在准备好了上述各个张量后,后续的逻辑类似于Transformer,首先经过encoder部分:
# 送入encoder
memory = self.encoder(
query=feat_flatten, # [sum(hw), b, 256]
key=None,
value=None,
query_pos=lvl_pos_embed_flatten, # [sum(hw), b ,256]
query_key_padding_mask=mask_flatten, # [b, sum(hw)]
spatial_shapes=spatial_shapes,
reference_points=reference_points, # [b,sum(hw),4,2]
level_start_index=level_start_index, # [4]
valid_ratios=valid_ratios, # [b,4,2]
**kwargs)
这里看下encoderlayer的内部调用流程:内部本质调用的是可形变注意力的部分,而可形变注意力则本文提出的核心,代码地址:mmcv/ops/multi_scale_deform_attn.py,首先看下可形变注意力模块的初始化部分:
self.embed_dims = embed_dims
self.num_levels = num_levels
self.num_heads = num_heads
self.num_points = num_points # 论文中的K,采样点的个数
# num_heads * num_level * num_points * 2
self.sampling_offsets = nn.Linear(
embed_dims, num_heads * num_levels * num_points * 2)
self.attention_weights = nn.Linear(embed_dims,
num_heads * num_levels * num_points)
self.value_proj = nn.Linear(embed_dims, embed_dims)
self.output_proj = nn.Linear(embed_dims, embed_dims)
这里需要留意的是这几个nn.Linear函数,在后续forward部分会用到。
在看下可形变注意力的forward部分:
value = self.value_proj(value) # 将value多了一层线性映射
if key_padding_mask is not None:
value = value.masked_fill(key_padding_mask[..., None], 0.0)
# value进行维度变换: [b, sum(hw), 8, 256/8]
value = value.view(bs, num_value, self.num_heads, -1)
# 经过一个线性层映射得到每个query的偏移量:[b,sum(hw),8,4,2,2]
sampling_offsets = self.sampling_offsets(query).view(
bs, num_query, self.num_heads, self.num_levels, self.num_points, 2)
# 经过一个线性层映射+softmax得到每个query的注意力权重
attention_weights = self.attention_weights(query).view(
bs, num_query, self.num_heads, self.num_levels * self.num_points)
attention_weights = attention_weights.softmax(-1)
attention_weights = attention_weights.view(bs, num_query,
self.num_heads,
self.num_levels,
self.num_points)
# 将预测得到的偏移量修正参考点 并进行归一化
if reference_points.shape[-1] == 2:
offset_normalizer = torch.stack(
[spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)
sampling_locations = reference_points[:, :, None, :, None, :] \
+ sampling_offsets \
/ offset_normalizer[None, None, None, :, None, :]
# 若有cuda则调用cuda算子
if torch.cuda.is_available() and value.is_cuda:
output = MultiScaleDeformableAttnFunction.apply(
value, spatial_shapes, level_start_index, sampling_locations,
attention_weights, self.im2col_step)
# 没有则调用cpu版本
else:
output = multi_scale_deformable_attn_pytorch(
value, spatial_shapes, sampling_locations, attention_weights)
output = self.output_proj(output) # 将输出经过线性变换
这里在看下cpu版本的可形变注意力,这里面主要是维度变换比较绕。大家可以慢慢调试下(奥利给):
def multi_scale_deformable_attn_pytorch(value, value_spatial_shapes,
sampling_locations, attention_weights):
"""CPU version of multi-scale deformable attention.
Args:
value (torch.Tensor): The value has shape
(bs, num_keys, mum_heads, embed_dims//num_heads)
value_spatial_shapes (torch.Tensor): Spatial shape of
each feature map, has shape (num_levels, 2),
last dimension 2 represent (h, w)
sampling_locations (torch.Tensor): The location of sampling points,
has shape
(bs ,num_queries, num_heads, num_levels, num_points, 2),
the last dimension 2 represent (x, y).
attention_weights (torch.Tensor): The weight of sampling points used
when calculate the attention, has shape
(bs ,num_queries, num_heads, num_levels, num_points),
Returns:
torch.Tensor: has shape (bs, num_queries, embed_dims)
"""
bs, _, num_heads, embed_dims = value.shape
_, num_queries, num_heads, num_levels, num_points, _ =\
sampling_locations.shape
# 在第一个维度上进行拆分成list:其中每个元素shape:[b,hw, num_heads, embed_dims//num_heads]
value_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes],
dim=1)
# 后续用到的F.grid_sample函数所要求坐标为[-1,1],故需要做一次映射
sampling_grids = 2 * sampling_locations - 1
# 用来存储采样后的坐标
sampling_value_list = []
for level, (H_, W_) in enumerate(value_spatial_shapes):
# bs, H_*W_, num_heads, embed_dims ->
# bs, H_*W_, num_heads*embed_dims ->
# bs, num_heads*embed_dims, H_*W_ ->
# bs*num_heads, embed_dims, H_, W_
value_l_ = value_list[level].flatten(2).transpose(1, 2).reshape(
bs * num_heads, embed_dims, H_, W_)
# bs, num_queries, num_heads, num_points, 2 ->
# bs, num_heads, num_queries, num_points, 2 ->
# bs*num_heads, num_queries, num_points, 2
sampling_grid_l_ = sampling_grids[:, :, :,
level].transpose(1, 2).flatten(0, 1)
# 该函数value和grid均是4D,且二者第一个维度必须相等,
# 最终采样后的特征图第一个维度一样,第二个维度跟value一样,
# 第三四个维度跟采样点的维度一样
# sampling_value_l_ = [bs*num_heads, embed_dims, num_queries, num_points]
sampling_value_l_ = F.grid_sample(
value_l_, # [bs*num_heads, embed_dims, H_, W_]
sampling_grid_l_, # [bs*num_heads, num_queries, num_points, 2]
mode='bilinear',
padding_mode='zeros',
align_corners=False)
sampling_value_list.append(sampling_value_l_)
# (bs, num_queries, num_heads, num_levels, num_points) ->
# (bs, num_heads, num_queries, num_levels, num_points) ->
# (bs, num_heads, 1, num_queries, num_levels*num_points)
attention_weights = attention_weights.transpose(1, 2).reshape(
bs * num_heads, 1, num_queries, num_levels * num_points)
#将list的四个元素进行了堆叠,将对应元素相乘并在最后一个维度上进行求和
# [bs*num_heads, embed_dims, num_queries, num_levels*num_points] *
# (bs*num_heads, 1, num_queries, num_levels*num_points)
output = (torch.stack(sampling_value_list, dim=-2).flatten(-2) *
attention_weights).sum(-1).view(bs, num_heads * embed_dims,
num_queries)
return output.transpose(1, 2).contiguous()
最终输出的output的shape为:[batch, num_queries, embed_dims]。
2.3.4. Transformer的decoder部分
在得到memory后,便送入decoder部分。首先看下整体逻辑:
# encoder输出的memory
memory = memory.permute(1, 0, 2) # [b, num_querie,256]
bs, _, c = memory.shape
# 一阶段部分
else:
# 可学习的nn.Embedding:[300,512],即decoder中的可学习位置编码
query_pos, query = torch.split(query_embed, c, dim=1)# [300,256]
query_pos = query_pos.unsqueeze(0).expand(bs, -1, -1)#[b,300,256]
query = query.unsqueeze(0).expand(bs, -1, -1) # [b,300,256]
# 将query_pos经过一次线性变换+sigmoid正好能作为初始参考点坐标
reference_points = self.reference_points(query_pos).sigmoid()
init_reference_out = reference_points
# decoder
query = query.permute(1, 0, 2)
memory = memory.permute(1, 0, 2)
query_pos = query_pos.permute(1, 0, 2)
# inter_states: [6,300,bs,256],6表示经过了6层layer
# inter_references:[6,bs,300,2]
inter_states, inter_references = self.decoder(
query=query,
key=None,
value=memory,
query_pos=query_pos,
key_padding_mask=mask_flatten,
reference_points=reference_points,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
valid_ratios=valid_ratios,
reg_branches=reg_branches,
**kwargs)
inter_references_out = inter_references
return inter_states, init_reference_out, \
inter_references_out, None, None
我这里简单贴下decoder流程,跟encoder一样,只是多返回了每层layer的中间状态:
output = query
intermediate = [] # 存储每层decoder layer的query
intermediate_reference_points = [] # 用来存储每层decoder layer的参考点
for lid, layer in enumerate(self.layers):
else:
assert reference_points.shape[-1] == 2
reference_points_input = reference_points[:, :, None] * \
valid_ratios[:, None]
output = layer( # 此处和encoder中类似,不在赘述
output, # 唯一区别是有了key即memory
*args,
reference_points=reference_points_input,
**kwargs)
output = output.permute(1, 0, 2)
if self.return_intermediate:
intermediate.append(output)
intermediate_reference_points.append(reference_points)
if self.return_intermediate:
return torch.stack(intermediate), torch.stack(
intermediate_reference_points)
return output, reference_points
最后decoder输出三个张量:inter_states, init_reference_out, 和
inter_references_out:分别表示每层layer的query,初始预测的参考点,以及每层layer的预测出的中间参考点。三个张量维度我在这单独在记下:
'''
inter_states: [num_dec_layers, bs, num_query, embed_dims]
init_reference_out: (bs, num_queries, 4)
inter_references_out: (num_dec_layers, bs,num_query, embed_dims)
'''
2.4. 预测bbox阶段
终于来到最后一步,最后预测bbox的过程就比较简单,将初始点作为参考点,把每层layer的中间状态来修正初始点6次即可。
'''
hs: [num_dec_layers, bs, num_query, embed_dims]
init_reference_out: (bs, num_queries, 4)
inter_references_out: (num_dec_layers, bs,num_query, embed_dims)
'''
hs = hs.permute(0, 2, 1, 3)
outputs_classes = []
outputs_coords = []
for lvl in range(hs.shape[0]):
if lvl == 0:
reference = init_reference # 作为初始点
else:
reference = inter_references[lvl - 1]
reference = inverse_sigmoid(reference) # 做反sigmoid
outputs_class = self.cls_branches[lvl](hs[lvl])
tmp = self.reg_branches[lvl](hs[lvl])
if reference.shape[-1] == 4:
tmp += reference
else:
assert reference.shape[-1] == 2
tmp[..., :2] += reference # 仅修正参考点中心位置即可
outputs_coord = tmp.sigmoid()
outputs_classes.append(outputs_class)
outputs_coords.append(outputs_coord)
outputs_classes = torch.stack(outputs_classes)
outputs_coords = torch.stack(outputs_coords)
if self.as_two_stage:
return outputs_classes, outputs_coords, \
enc_outputs_class, \
enc_outputs_coord.sigmoid()
else:
return outputs_classes, outputs_coords, \
None, None
总结
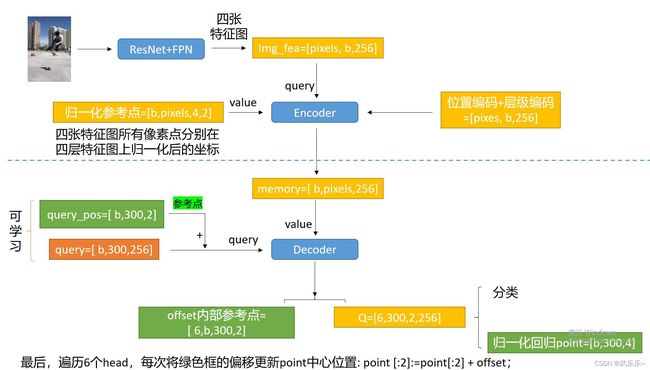
我这里简单的画了张结构图方便大家理解:
这篇文章还有好多细节没有厘清,有问题欢迎随时评论交流。若有问题欢迎+vx:wulele2541612007,拉你进群探讨交流。