tensorflow2.0之卷积神经网络
tf.keras实现卷积神经网络
- Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。
Keras可以很明确的定义了层的概念,反过来层与层之间的参数反倒是用户不需要关心的对象,所以构建神经网络的方法对于普通开发者来说,相对tensorflow,Keras更易上手。
并且Keras也是tensorflow官方在tensorflow2.0开始极力推荐使用的。 - 卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一,对于图片(height,weight,channel)的输入数据,如果用DNN网络提取图片特征的话,那模型需要学习的参数每一层就有HWC这么多,这是一个呈几何倍数增长的数字,那么模型学习难度将会特别大,极易发生过拟合。考虑CNN网络,通过卷积核在图片上滑动进行卷积操作,参数量将会大大减少,并且卷积核可以提取图片特征向后传,最后通过全连接层对图片特征进行输出。
- 首先导入一些需要使用的包,然后导入fashion_mnist数据集并分割好训练和测试集
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
(train_image,train_label),(test_image,test_label) = tf.keras.datasets.fashion_mnist.load_data()
print(train_image.shape)
print(train_label)
>> (60000, 28, 28)
[9 0 0 ... 3 0 5]
- 由于tf.keras的卷积神经网络的训练需要是一个四维(num,hight,weight,channel)的数据,所以下面对输入图片数据拓宽一个通道
# 把输入数据拓宽一个维度,转换成(num,hight,weight,channel)
train_images = np.expand_dims(train_image, -1)
test_images = np.expand_dims(test_image, -1)
train_images.shape
>> (60000, 28, 28, 1)
- 建立顺序模型
# 新建顺序模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, (3,3), input_shape = train_images.shape[1: ], activation = 'relu')) # 输入维度为3,取图片的后三维
model.add(tf.keras.layers.MaxPool2D(pool_size = (2,2))) #下采样,降低参数数量,同时增强下一层卷积的视野
model.add(tf.keras.layers.Conv2D(64, kernel_size = (3,3), activation = 'relu'))
model.add(tf.keras.layers.GlobalAveragePooling2D()) #把卷积之后的图片转换为2维,连到全连接层
model.add(tf.keras.layers.Dense(10, activation = 'softmax'))
model.summary()
>>
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
global_average_pooling2d_1 ( (None, 64) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 19,466
Trainable params: 19,466
Non-trainable params: 0
_________________________________________________________________
- 编译训练模型
# 模型编译
model.compile(optimizer='adam',
loss = 'sparse_categorical_crossentropy',
metrics = ['acc']
)
history = model.fit(train_images, train_label, epochs=20, validation_data=(test_images,test_label))
>>
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
60000/60000 [==============================] - 32s 527us/sample - loss: 0.7983 - acc: 0.7568 - val_loss: 0.5376 - val_acc: 0.8111
Epoch 2/20
60000/60000 [==============================] - 32s 529us/sample - loss: 0.4884 - acc: 0.8296 - val_loss: 0.4993 - val_acc: 0.8262
...
Epoch 14/20
60000/60000 [==============================] - 26s 441us/sample - loss: 0.2627 - acc: 0.9064 - val_loss: 0.3258 - val_acc: 0.8891
Epoch 15/20
60000/60000 [==============================] - 28s 460us/sample - loss: 0.2544 - acc: 0.9100 - val_loss: 0.3256 - val_acc: 0.8876
Epoch 16/20
60000/60000 [==============================] - 31s 524us/sample - loss: 0.2499 - acc: 0.9105 - val_loss: 0.3323 - val_acc: 0.8868
Epoch 17/20
60000/60000 [==============================] - 35s 576us/sample - loss: 0.2455 - acc: 0.9121 - val_loss: 0.3455 - val_acc: 0.8830
Epoch 18/20
60000/60000 [==============================] - 29s 491us/sample - loss: 0.2382 - acc: 0.9144 - val_loss: 0.3173 - val_acc: 0.8884
Epoch 19/20
60000/60000 [==============================] - 30s 500us/sample - loss: 0.2348 - acc: 0.9151 - val_loss: 0.3155 - val_acc: 0.8880
Epoch 20/20
60000/60000 [==============================] - 32s 531us/sample - loss: 0.2310 - acc: 0.9167 - val_loss: 0.3366 - val_acc: 0.8834
- 画图更直观的查看模型的训练情况
plt.figure(figsize=(20,8),dpi = 200)
plt.plot(history.epoch, history.history.get('acc'), label = 'acc')
plt.plot(history.epoch, history.history.get('val_acc'), label = 'val_acc')
plt.legend()
>>
<matplotlib.legend.Legend at 0x18f7148ecc8>

通过绘制训练epochs与训练数据集的准确率和测试数据集的准确率折线图的观察到,模型在训练数据集上的准确率比验证数据集上的准确率高,而且模型的准确率在最后还一直呈现上升趋势,说明模型过拟合了并且模型的没有完全达到状态,下面对其进行优化。
优化模型,增加卷积层,提升模型拟合能力;添加Dropout层,防止过拟合。
- 首先新建顺序模型,增加了一个隐藏层,并且每个隐藏层的输出通道数也增加了,因为通道数是用来传递数据集特征的,通道数过小有可能不能承接图片的全部特征导致部分特征丢失,模型效果变差。然后在每个卷积层之后添加一个Dropout层防止过拟合,最后利用softmax激活输出10中类别。
# 新建顺序模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(64, (3,3),
input_shape = train_images.shape[1: ],
activation = 'relu',padding = "same")) # 输入维度为3,取图片的后三维
model.add(tf.keras.layers.Conv2D(64, kernel_size = (3,3), activation = 'relu', padding = 'same'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.MaxPool2D(pool_size = (2,2))) # 下采样,降低参数数量,同时增强下一层卷积的视野
model.add(tf.keras.layers.Conv2D(128, kernel_size = (3,3), activation = 'relu',padding = 'same'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.MaxPool2D(pool_size = (2,2)))
model.add(tf.keras.layers.Conv2D(256, kernel_size = (3,3), activation = 'relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.GlobalAveragePooling2D()) # 把卷积之后的图片转换为2维,连到全连接层
model.add(tf.keras.layers.Dense(10, activation = 'softmax'))
model.summary()
>>
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 28, 28, 64) 640
_________________________________________________________________
conv2d_5 (Conv2D) (None, 28, 28, 64) 36928
_________________________________________________________________
dropout (Dropout) (None, 28, 28, 64) 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 14, 14, 128) 73856
_________________________________________________________________
dropout_1 (Dropout) (None, 14, 14, 128) 0
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 5, 5, 256) 295168
_________________________________________________________________
dropout_2 (Dropout) (None, 5, 5, 256) 0
_________________________________________________________________
global_average_pooling2d_1 ( (None, 256) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 2570
=================================================================
Total params: 409,162
Trainable params: 409,162
Non-trainable params: 0
_________________________________________________________________
- 模型编译
model.compile(
optimizer='adam',
loss = 'sparse_categorical_crossentropy',
metrics = ['acc']
)
history = model.fit(train_images, train_label, epochs=20, validation_data=(test_images,test_label))
>>
Epoch 1/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.7331 - acc: 0.7903 - val_loss: 0.5045 - val_acc: 0.8555
Epoch 2/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.3989 - acc: 0.8558 - val_loss: 0.4424 - val_acc: 0.8773
Epoch 3/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.3585 - acc: 0.8683 - val_loss: 0.4049 - val_acc: 0.8851
Epoch 4/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.3288 - acc: 0.8810 - val_loss: 0.3946 - val_acc: 0.8867
Epoch 5/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.3084 - acc: 0.8876 - val_loss: 0.3423 - val_acc: 0.9027
Epoch 6/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2901 - acc: 0.8941 - val_loss: 0.3753 - val_acc: 0.8991
Epoch 7/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2826 - acc: 0.8963 - val_loss: 0.3452 - val_acc: 0.9002
Epoch 8/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2719 - acc: 0.9010 - val_loss: 0.3152 - val_acc: 0.9117
Epoch 9/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2663 - acc: 0.9027 - val_loss: 0.3082 - val_acc: 0.9103
Epoch 10/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2605 - acc: 0.9038 - val_loss: 0.2891 - val_acc: 0.9025
Epoch 11/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2544 - acc: 0.9065 - val_loss: 0.3096 - val_acc: 0.9154
Epoch 12/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2512 - acc: 0.9088 - val_loss: 0.2958 - val_acc: 0.9105
Epoch 13/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2469 - acc: 0.9092 - val_loss: 0.2882 - val_acc: 0.9178
Epoch 14/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2436 - acc: 0.9108 - val_loss: 0.2783 - val_acc: 0.9124
Epoch 15/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2400 - acc: 0.9123 - val_loss: 0.2788 - val_acc: 0.9185
Epoch 16/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2400 - acc: 0.9125 - val_loss: 0.2649 - val_acc: 0.9191
Epoch 17/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2376 - acc: 0.9136 - val_loss: 0.2707 - val_acc: 0.9193
Epoch 18/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2368 - acc: 0.9139 - val_loss: 0.2546 - val_acc: 0.9191
Epoch 19/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2327 - acc: 0.9155 - val_loss: 0.3030 - val_acc: 0.9174
Epoch 20/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2314 - acc: 0.9154 - val_loss: 0.2615 - val_acc: 0.9239
- 下面绘制训练轮数epochs与准确率之间的折线图
plt.figure(figsize=(20,8),dpi = 200)
plt.plot(history.epoch, history.history.get('acc'), label = 'acc')
plt.plot(history.epoch, history.history.get('val_acc'), label = 'val_acc')
plt.legend()
>>
<matplotlib.legend.Legend at 0x7f85d0736990>
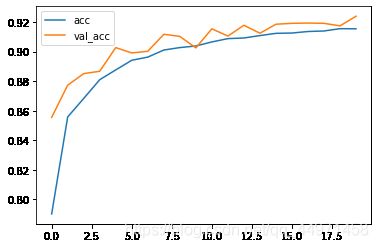
可以看到测试数据集的准确率一直在训练数据集之上,说明模型没有过拟合,但是训练数据集依然有上升的趋势,说明模型还是训练不足,可以考虑继续优化。