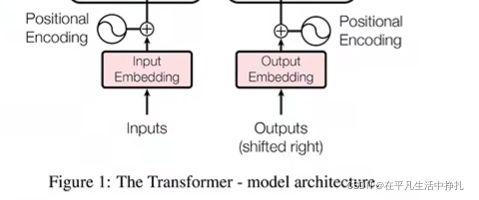
学习李沐老师讲解Transformer知识点记录(更新)
一、一些概念解释
1
CNN通过卷据核看一张图像时只能看到图像的一部分。
Transformer每一层看图像都可以看到整个图像信息。
2
为了达到CNN可以有多个输出通道的优点,Transformer设计了Multi-Head attention,模拟卷积神经网络多输出通道的效果。

3
编码器-解码器的过程中,编码阶段可以把句子的所有向量输入进去,在解码的时候只能一个词一个词的生成。自回归指的是在解码的这个过程中过去时刻的输出又是当前时刻的输入。

二、Transformer网络结构理解
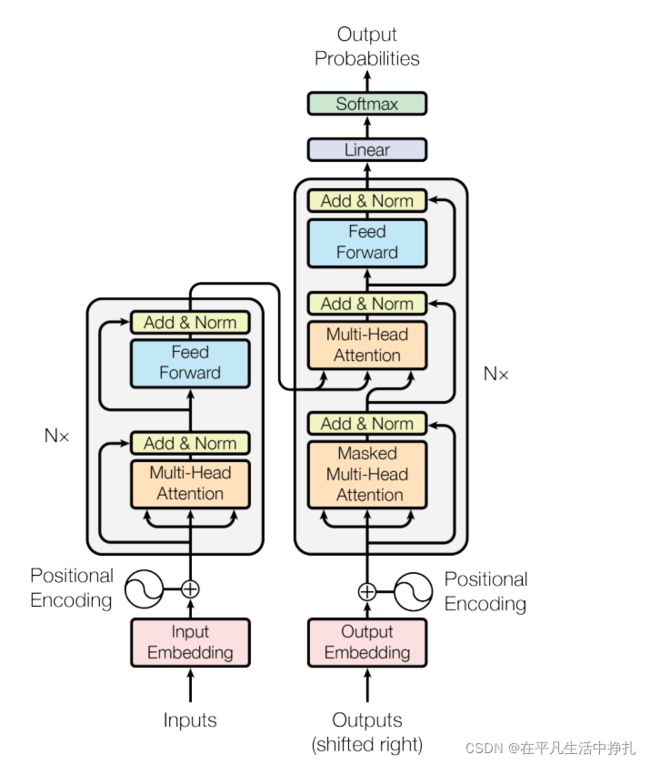
1.layer Normalization是什么?
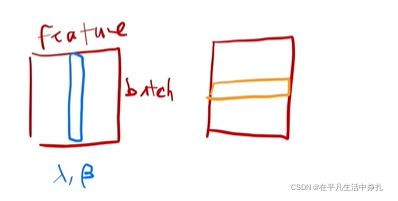
和batch Normalization操作相似,transformer中layer Normalization是对每一个样本做归一化,将均值归为0,方差归为1。
layer Norm实际上就是把数据转置以后,计算batch Norm,再转置回去就是layer Norm。
在RNN中,输入是一个序列,里面有词向量。输入是一个三维的特征,相应的batch norm 和layer norm归一化就是不同方向进行切片,对切面的特征做归一化均值为零方差为一。
蓝色面表示batch norm,黄色面表示layer norm。
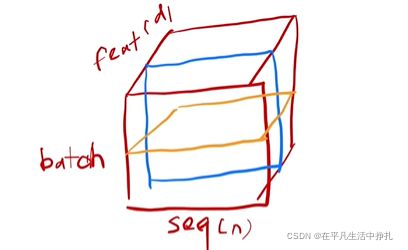
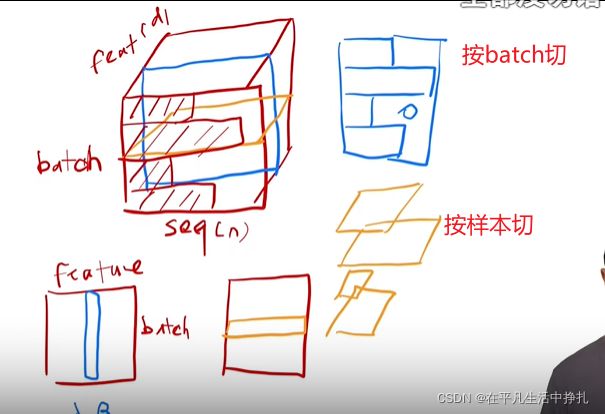
layer norm比batch norm稳定一点,因为layer norm对每个样本算均值方差,不需要存全局的均值和方差。
当某个样本特殊长时,batch norm之前计算记录的均值和方差可能不适用了。但layer norm会更有效。
2.为什么是带Mask掩码的Multi-Head Attention?
因为decoder解码器是一种自回归的结构,解码器中某一层的输入是上一层的输出(预测第t个时刻的输入是t-1时刻的输出),意味着在解码器预测训练的时候,预测第t个时刻的输出时不应该看到t+1时刻的输入,而attention机制会让每一层都看到序列的全部输入,因此需要一个带mask的attention去屏蔽t时刻之后的输入信息。

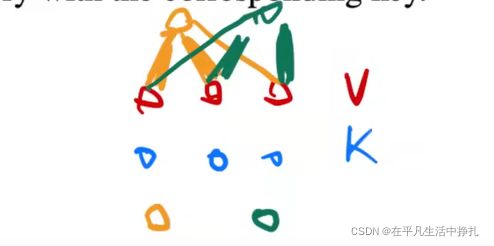
3.什么是注意力机制?

“注意函数可以描述为将查询和一组键值对映射到输出”,设有一组Key-Value对,对于不同的query输入,它和不同的Key之间相似度不同,因此在计算结果v的时候,有着不同的权值系数关系。
attention是一组Key-Value对的关系权重,虽然Key-Value关系没有变,但是随着query不同,计算的结果各不相同。
4.Attention模块怎么计算?

对于一组Key-Value对,当n个query向量(维度dk)组成的矩阵输入时,由图中的attention公式,可以通过两次矩阵乘法计算出n×dv的输出特征。其中:
第三个红框中蓝线部分表示每一个query对所有key的内积值,将它除以根号dk,再对蓝线表示的每一行做softmax计算得分,得到权重。

论文中的示意图
5.为什么要除以根号dk?
为了避免Q和K两个矩阵相乘后结果较大(或较小),导致softmax异常趋于一或区域零,导致训练时梯度太小,因此除以一个系数根号dk。dk为经验值512。
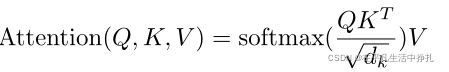
6.如何通过mask来屏蔽query在t时刻之后计算的权重?
对t时刻之后的结果,乘以一个很大的负数,这样在softmax之后就变成0。
7.Multi-Head Attention是干什么?为什么要做多头的注意力机制?
由于Scaled Dot-Product Attention中,没有什么可以学习的参数,因此为了学习不同任务中的不同模式,我们希望有一些不同的计算相似度的办法。因此,先将query投影到低维,这个低维个数w是可以学习的。
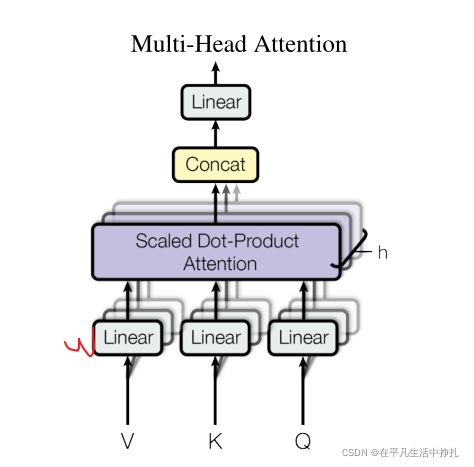
这张图中就表示给你h次机会,让query以不同的投影方式去进行降维,学习不同的投影方法,使得在输入的度量空间里面,可以匹配不同模式的相似函数。最后计算出Scaled Dot-Product Attention的结果后相加,统一再做一次投影,还原为原来的维度。这种方法增加了学习的参数,可以更好的适应不同的任务模式。

多头注意力机制计算公式:

8.注意力机制在transformer中是如何使用的?
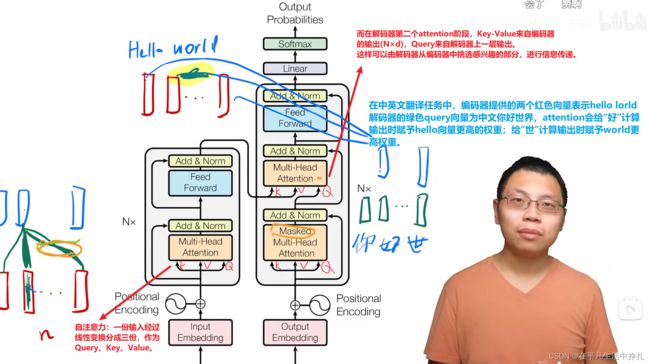
在transformer网络中,Multi-Head Attention共有三处使用,编码器一处,解码器两处。
1.编码器中的attention采用自注意力机制,将输入特征经过线性变换分为三份,作为Query、Key、Value输入attention。
2.解码器中第一个attention采用自注意力机制,并且通过自回归方法,采用mask去抑制t时刻以后的预测信息。
3.解码器中第二个attention,Query来自上一层attention的使出,Key-Value来自编码器的attention输出。这样可以在解码器和编码器之间进行信息传递,从编码器中挑选解码器感兴趣的部分。
9.图中蓝色框Feed-Forward Networks介绍
它实际就是一个单隐层的线性的前向神经网络(MLP)。
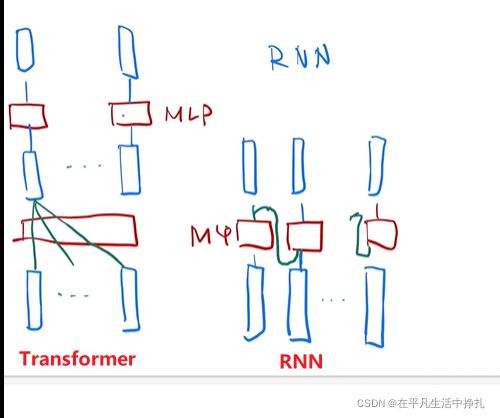
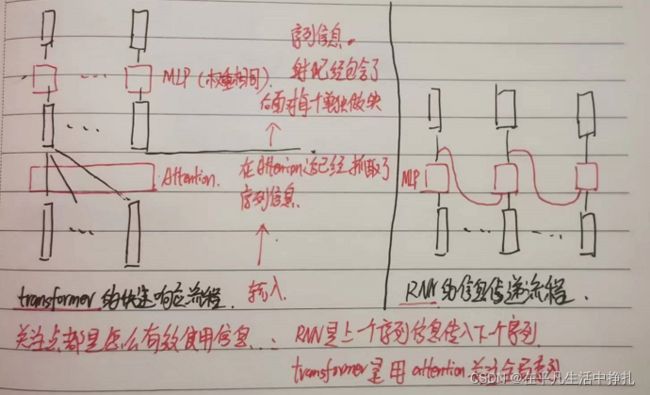
10.Transformer和RNN如何使用和传递序列信息?
11.什么是Positional Encoding?为什么要加?
问题10图中,输入信息具有时序性,RNN处理时本身就根据时序性进行传递,但attention直接获取全局信息,没有了时序性处理。
比如在翻译句子时,attention抓取一句话的信息,然后把这句话里词顺序打乱,attention提取的信息是不变的。因此需要记录Position Encoding位置信息作为句子的时序信息,让attention记录时序性。