hudi_on_flink
hudi_on_flink
下载hudi
首先 在github官网下载hudi的包 https://github.com/apache/hudi/tree/release-0.7.0 并编译,自己编译可能会出错 或者到maven仓库直接下载编译好的jar包 :https://repository.apache.org/#nexus-search;quick~hudi
编写hudi配置文件以及表元数据文件
元数据配置表以及配置信息:我是把这俩个文件上传到hdfs上的,这个也是支持本地的 需要把hdfs:// 换为file://
hudi-conf.properties
hoodie.datasource.write.recordkey.field=uuid #uuid 作为行的标识 也就是 key
hoodie.datasource.write.partitionpath.field=ts # hudi的分区字段,一般为时间戳
bootstrap.servers=192.168.100.10:9092
hoodie.deltastreamer.keygen.timebased.timestamp.type=EPOCHMILLISECONDS
hoodie.deltastreamer.keygen.timebased.output.dateformat=yyyy/MM/dd
hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.TimestampBasedAvroKeyGenerator
hoodie.embed.timeline.server=false
#hoodie.deltastreamer.schemaprovider.source.schema.file=file:///home/hadoop/zxf/config/schema.avsc 本地文件
#hoodie.deltastreamer.schemaprovider.target.schema.file=file:///home/hadoop/zxf/config/schema.avsc
#hoodie.deltastreamer.schemaprovider.source.schema.file=hdfs://he.novalocal:8020/hudi/flink/config/schema.avsc
#hoodie.deltastreamer.schemaprovider.target.schema.file=hdfs://he.novalocal:8020/hudi/flink/config/schema.avsc flink 集群是Standalone模式启动的
# 以下是flink集群以yarn 模式启动的
hoodie.deltastreamer.schemaprovider.source.schema.file=hdfs://mycluster/user/zxf/hudi/flink/config/schema.avsc
hoodie.deltastreamer.schemaprovider.target.schema.file=hdfs://mycluster/user/zxf/hudi/flink/config/schema.avsc
schema.avsc
这个文件也可以在hudi的源码当中找到docker/demo/config/schema.avsc
{
"type":"record",
"name":"stock_ticks",
"fields":[{
"name": "uuid",
"type": "string"
}, {
"name": "ts",
"type": "long"
}, {
"name": "symbol",
"type": "string"
},{
"name": "year",
"type": "int"
},{
"name": "month",
"type": "int"
},{
"name": "high",
"type": "double"
},{
"name": "low",
"type": "double"
},{
"name": "key",
"type": "string"
},{
"name": "close",
"type": "double"
}, {
"name": "open",
"type": "double"
}, {
"name": "day",
"type":"string"
},{
"name": "_hoodie_is_deleted",
"type": "boolean",
"default": false
}
]}
# 这是一个是否删除的标志位:当值为true的时候 hudi 会删除这条记录,默认为false 只执行upsert操作
"name": "_hoodie_is_deleted",
"type": "boolean",
"default": false
执行flink on yarn 脚本
flink run -m yarn-cluster \
-d -yjm 1024 \
-ytm 1024 \
-p 4 -ys 3 \
-ynm hudi_on_flink -c org.apache.hudi.HoodieFlinkStreamer /opt/tmpdatas/hudi/packaging/hudi-flink-bundle/target/hudi-flink-bundle_2.11-0.7.0.jar \
--kafka-topic hudi_on_flink5 \
--kafka-group-id hudi_test \
--kafka-bootstrap-servers 192.168.100.10:9092 --target-table hudi_on_flink \
--table-type COPY_ON_WRITE \
--props hdfs://mycluster/user/zxf/hudi/flink/config/hudi-conf.properties \
--target-base-path hdfs://mycluster/user/zxf/hudi/flink/test/data/hudi_on_flink\
--checkpoint-interval 3000 \
--flink-checkpoint-path hdfs://mycluster/user/zxf/hudi/flink/hudi_on_flink_cp
执行完脚本后 一般都会报错需要在flink lib 目录下 加入报错所需要的jar包。
**注意:**yarn 模式要配置环境变量
export HADOOP_CLASSPATH=`hadoop classpath`
执行完之后到 启动日志末尾有一条信息如下:he.novalocal:36148 这个域名和端口号 为flink运行job界面。
Found Web Interface he.novalocal:36148 of application 'application_1609386259137_0634'.
启动后如下(这是我跑任务之后的状态):
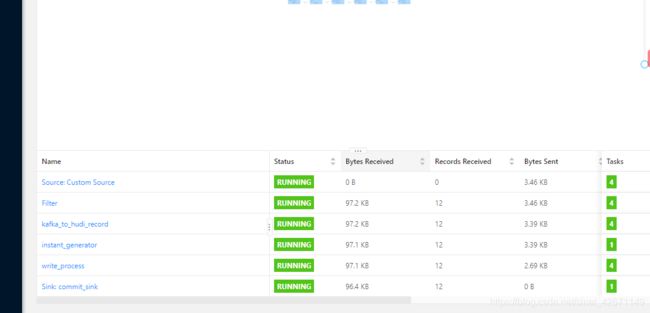
kafka 发送消息
表数据属性
private String uuid;
private long ts;
private String symbol;
private int year;
private int month;
private double high;
private double low;
private String key;
private double close;
private double open;
private String day;
private boolean _hoodie_is_deleted;
数据格式如下:
{"_hoodie_is_deleted":false,"close":12.86204565867414,"day":"2020-3-3","high":13.542298987295728,"key":"java.util.Random@1b604f19","low":6.4727870845780044,"month":2,"open":3.0832023151561474,"symbol":"this is demo","ts":1615882318557,"uuid":"4f27a7f6f3bb47c8b24447af1971cb2a","year":2020}
查询数据
如果有presto就更好了,spark查询 不太方便,在有spark的集群上:
#启动脚本
spark-shell \
--packages org.apache.spark:spark-avro_2.11:2.4.1 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--jars /opt/core/hudi/packaging/hudi-spark-bundle/target/hudi-spark-bundle_2.11-0.6.0-SNAPSHOT.jar
#查询代码
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_on_flink"
val basePath = "/user/zxf/hudi/flink/test/data/hudi_on_flink"
val roViewDF = spark.
read.
format("org.apache.hudi").
load(basePath + "/*/*/*/*")
roViewDF.registerTempTable("hudi_flink_table")
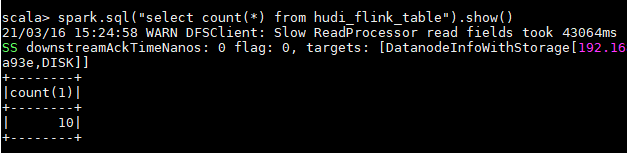
spark.sql("select count(*) from hudi_flink_table").show()
第一次查询结果如下:
当把之前的一条数据 _hoodie_is_deleted 的值为true,再次进入spark交互窗,可以看到 少了一条
