论文笔记 | code pretraining(代码预训练系列)
文章目录
-
- Pre-trained contextual embedding of source code
- CodeBERT: A Pre-trained model for programming and natural languages
- GraphCodeBert: Pre-training code representations with data flow
- Contrastive code representation learning
- InferCode: Self-Supervised Learning of Code Representations by Predicting Subtrees
- DOBF: A Deobfuscation Pre-Training Objective for Programming Languages
- IntelliCode Compose: Code Generation using Transformer
Pre-trained contextual embedding of source code
ICLR 2020 reject,后改为Learning and Evaluating Contextual Embedding of Source Code,发表在ICML 2020
Google Brain
CuBERT:开源代码和数据链接
和Bert无区别,只是替换了语料和微调的任务。
本文做的是代码预训练,提出了CuBERT(Code Understanding BERT)。在6.6M python files的语料上做训练。数据是public Github repository hosted on Google’s BigQuery platform。
预训练任务
-
Masked language modeling (MLM)
预测mask的token是什么 -
Next Sentence Prediction(NSP)
预测两个代码逻辑行是否为上下句的关系
微调任务
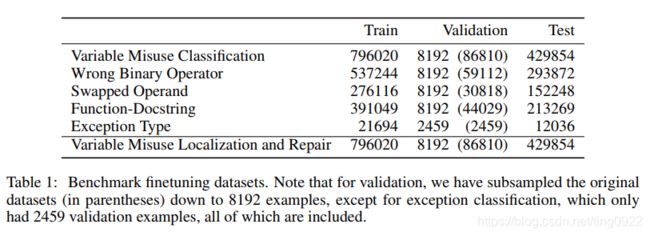
5个分类任务和一个其他任务
- Variable Misuse Classification
- Wrong Binary Operator
- Swapped Operand
- Function-Docstring Mismatch
- Exception type
- Variable Misuse localization and repair
微调的数据集为:
CodeBERT: A Pre-trained model for programming and natural languages
EMNLP findings, 2020
Zhangyin Feng, Daya Guo, Duyu Tang …
哈工大,中山大学,微软亚洲研究院
开源代码和数据
可用:预训练模型;在每种语言上进行微调比在6种语言上一起微调效果更优;
本文做的是代码预训练,提出了CodeBERT(a first large bimodal pre-trained model for natural language and programming language)。
模型架构
Follow Bert,RoBERTa,使用多层双向Transformer作为CodeBERT的模型架构,和RoBERTa-Base中的架构一样,其中的模型参数有125 Million(1.25亿参数)
input: [ C L S ] , w 1 , w 2 , ⋯ , w n , [ S E P ] , c 1 , c 2 , ⋯ , c m , [ E O S ] [CLS], w_1, w_2, \cdots, w_n, [SEP], c_1, c_2, \cdots, c_m, [EOS] [CLS],w1,w2,⋯,wn,[SEP],c1,c2,⋯,cm,[EOS]
其中的 w i w_i wi表示句子的token, c i c_i ci表示代码的token
output: 每一个token基于上下文的表示;[CLS]的表示,代表聚合的序列表示
预训练数据
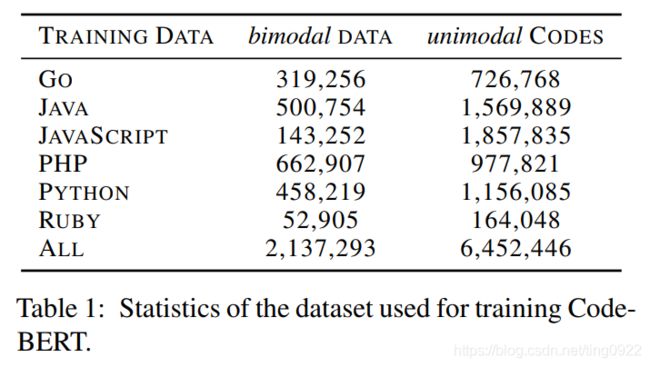
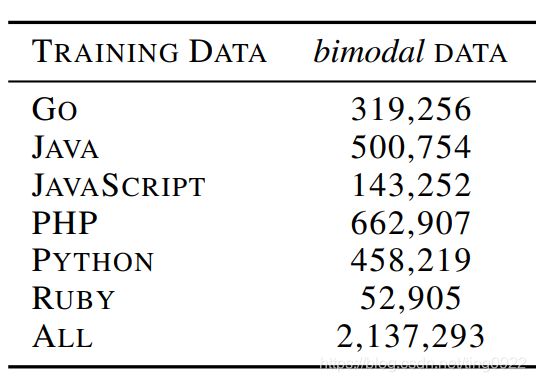
数据集来自CodeSearchNet,其中的2.4M bimodal data的形式为
预训练的任务
-
Masked Language Modeling (MLM)
输入是NL-PL pair,在其中随机选择一些位置mask掉。MLM的目标是预测被mask掉的原始token。

-
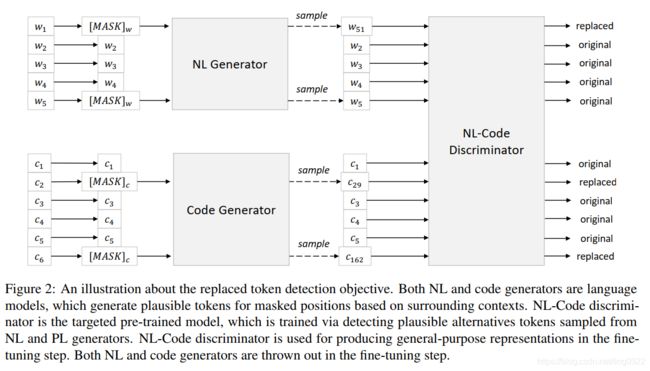
Replaced Token Detection (RTD)
使用bimodal和unimodal数据做训练,包括两个generator和一个discriminator,generator是随机选择位置替换成其他token,discriminator是判断某一位置是否被替换。
实验部分(模型微调)
对于不同的下游任务,会有不同的设置。如:在code search任务中,输入是和预训练阶段一致的,然后使用输出的[CLS]向量来表示代码和自然语言查询之间的相关性。再比如:在code-to-text generation任务中,使用encoder-decoder架构,并用CodeBERT初始化encoder的参数。在实验部分,作者给出了四个下游任务:
-
Natural language code search
数据形式为 ( c , w ) (c, w) (c,w) pair,与预训练的输入一样,该正样本对应的负样本可以通过 ( c , w ^ ) , ( c ^ , w ) (c, \hat{w}), (\hat{c}, w) (c,w^),(c^,w)来构造。该任务建模为一个二分类任务,模型输出的[CLS]表示后,再接上一层softmax,得到该pair是否匹配。 -
NL-PL probing
该任务是想要探究模型预测mask掉的token是什么的能力。输入是(c, w) pair,但这里的pair是经过筛选的。包含两个方面的筛选,一方面是NL side,输入是,其中的自然语言描述是选出带有max, min, less, greater的句子,然后将该任务建模为一个多项选择的任务。在PL side,输入是 ,其中的代码段是选择的带有max和min token的片段,将该任务建模为一个二项选择的任务。 -
Code documentation generation
encoder-decoder架构,其中的decoder是6层,768个隐层神经元,12个attention heads的设置。 -
Generalization to programming languages not in pre-training
预训练的语言包括6种,不包括C#。作者利用CODE-NN中的数据集,包含66015 pairs of questions and answers,结果比CODE-NN效果稍好,但不如code2seq(文中的解释是因为code2seq包含了AST path的信息,而这里只用到了codesequence的信息。)

优点
和ICLR 2020被拒稿的工作相比,这个工作有三个不同点:1. cross modal,既用到了bimodal的语料,又用到了unimodal的语料;2. 6种编程语言;3. 预训练的任务有所不同,没有NSP,而是换成了replaced token dection。
GraphCodeBert: Pre-training code representations with data flow
CoRR 2020
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, …
中山大学,北航,北大,哈工大,微软亚洲研究院
可用:关于data flow结构的预训练任务,微调任务(代码克隆检测,不同语言之间代码翻译)
Motivation
本文做的是代码预训练,在此之前的两个代码预训练的工作分别是:
- CuBERT: 和BERT一样的预训练任务(Masked Laguage Modeling, Next Sentence Prediction),在python语料上训练模型。(Pre-trained contextual embedding of source code, ICLR 2020 reject)
- CodeBERT: 基于RoBERTa的架构,与CuBERT不同的是,这里用到了cross modal的数据(bimodal 和 unimodal),并且在6种编程语言上进行了预训练。预训练的任务将NSP换成了replaced token detection(预测哪个位置上的token被替换了)。
基于以上两个工作,作者认为之前的代码预训练模型都只是将代码作为序列来考虑,忽略了代码中的结构信息。本文将代码的data flow信息引入预训练过程,并且设计了有关结构预测的预训练任务。
具体方法
模型架构
和RoBERTa架构一样,12层Transformer,768个隐层神经元,12个attention head。
输入包含三个部分:{[CLS], W, [SEP], C, [SEP], V}
预训练框架如下:

预训练数据(CodeSearchNet)
预训练任务
- Masked Language Modeling (MLM):预测被mask的token是什么
- Edge Prediction预测变量之间是否有data flow边
- Node Alignment将变量和code token对齐
模型微调
作者给出了四个下游任务:
-
natural language code search
给定自然语言查询,模型找出最匹配的代码段。 -
code clone detection
数据集:BigCodeBench 901724/416328/416328 examples for training/validation/testing
输入:source code and data flow
输出:[CLS]的表示,然后计算点乘,得出两段代码是clone的概率。
在微调阶段,学习率5e-5,batch size=128,Adam optimizer

-
code translation

-
code refinement
分析
- 结合代码结构的预训练任务的设计,不错
- 在除预训练的6种编程语言外的下游任务上进行微调,效果未知。【CodeBERT中给出了C#代码摘要生成的效果,不太理想】
Contrastive code representation learning
arxiv 2020
Paras Jain, Ajay Jain, Tianjun Zhang, Pieter Abbeel, Joseph E. Gonzalez & Ion Stoica
加州大学伯克利分校
关键词:code pre-training, syntactically diverse but functionally equivalent programs, contrastive training
Motivation
在此之前的代码预训练工作包括:CuBERT和CodeBERT,它们使用和BERT一样的架构和类似的预训练任务,比如MLM(Masking Language Modeling,预测mask的token)任务。这使得预训练阶段模型关注的是浅层的语言推理,表现在代码中就是在基于代码token级别进行表示。
然而很多下游任务需要理解一段代码的功能,MLM预训练任务存在欠缺。所以,作者设计了基于代码功能表示的预训练任务。
具体方法
作者假定:在下游任务中,具有相同的功能的代码应该有类似的向量表示。
【programs with the same functionality have the same underlying representation for downstream code understanding tasks.】
基于此,在预训练模型前,需要准备大量的正负样本,正样本是一对功能相同的代码,负样本是一对功能不同的代码。
构造正样本可以有两种方式:
-
在类似github的代码资源库中搜索与给定代码相似功能的代码,组成pair,作为正样本。
但这种方式需要在大量资源中搜索出功能相似的代码,复杂度较高,并且搜索到的代码不一定功能相同。 -
通过source-to-source compiler transformation工具生成和给定代码功能相同,但形式不同的代码。
这些转换工具包括:

预训练的使用的是JavaScript 1.8M 无标注的方法。(self-supervised training)
模型的架构如下:

其中的f_q表示对代码进行表示的encoder,可以是BiLSTM,Transformer,RoBERTa等。
基于contrastive training的目标函数是:

下游任务:
-
Type inference
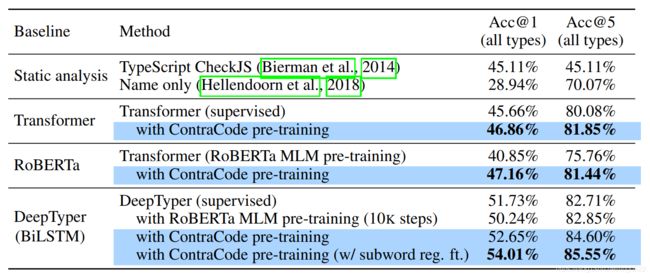
-
Code summarization

-
Method name prediction

创新点
- 基于功能相似性的代码预训练任务,相比token级别的预训练任务,更符合下游任务的要求
- source-to-source compiler transformation生成功能相同的代码的做法,使得正样本的构造更简单高效
可改进的点
- 负样本的构造方式
- 仅在JavaScript语料上进行预训练,较难泛化到其他语言
- 只关注method-level 的语义,可以结合token-level
- encoder可以选择LSTM,RoBERTa等,说明只使用了代码的序列信息,没有结构信息。
后续关注工作
- Md. Rafiqul Islam Rabin and Mohammad Amin Alipour. Evaluation of generalizability of neural program analyzers under semantic-preserving transformations, 2020.
作者发现,在对代码中的变量进行改名,代码行顺序变换等其他保留代码语义的变换操作后,一些工作(code2seq和code2vec)就会将代码分类到不同的类别。
InferCode: Self-Supervised Learning of Code Representations by Predicting Subtrees
ICSE 2021
Nghi D. Q. Bui, Yiyun Yu, Lingxiao Jiang
Singapore Management University, The Open University
Key words: Doc2vec(skip-gram), self-supervised code representation, similar ASTs will have similar subtrees
python代码
研究动机
目前代码表示的工作可以分为两类:
- 特定于任务的代码表示,比如:code classification。这类方法需要大量标注数据来训练模型,并且很难迁移到其他任务上。
- 代码预训练的工作,在无标签的数据上训练模型,但仅可以为代码的token,statement,function生成表示,而无法生成其他代码其他形式的表示,如AST树节点表示。
所以,作者提出InferCode,在大规模无标签的代码数据上自监督地训练模型,只要代码可以转换为AST,InferCode就可以作为encoder得出代码表示。预训练得到的InferCode encoder在5个下游任务中表现较好。
具体方法
key intuition: similar ASTs will have similar subtrees.

Doc2Vec (Le, Mikolov, 2014)的思想:
- 给定一系列文档 { d 1 , d 2 , ⋯ , d n } \{d_1, d_2, \cdots, d_n\} {d1,d2,⋯,dn},以及词序列 { ⋯ , w i j , ⋯ } \{\cdots, w_{ij}, \cdots\} {⋯,wij,⋯}。 w i j w_{ij} wij表示文档 i 中采样出的词 j。
- 模型的目标是最大化对数似然: ∑ j l o g P r ( w i j ∣ d i ) \sum_{j} log Pr(w_{ij}| d_i) ∑jlogPr(wij∣di),其中, P r ( w i j ∣ d i ) = e x p ( v i ⋅ v i j ) ∑ w ∈ V e x p ( v i ⋅ w ) Pr(w_{ij}|d_i) = \frac{exp(v_i \cdot v_{ij})}{\sum_{w \in V} exp(v_i \cdot w)} Pr(wij∣di)=∑w∈Vexp(vi⋅w)exp(vi⋅vij)
本文引用Doc2Vec的思想,将代码的AST视为文档,AST中的子树视为词。目标是最大化给定AST表示下的子树表示的最大对数似然。
步骤为:
- 将代码转换为AST
- 利用TBCNN学习AST中的节点表示
- 利用attention机制学习AST的表示(即代码段的表示)
- 最大化对数似然,更新模型参数

其他注意点:
- 初始AST节点表示包含type embedding和token embedding,从 W t y p e W^{type} Wtype和 W t o k e n W^{token} Wtoken矩阵中获取,这两个矩阵在训练中学习。
- 子树的embedding是从 W s u b t r e e W^{subtree} Wsubtree矩阵中获得,该矩阵也在训练中学习
- 子树是从AST中采样得来的,采样根节点的类型为{expr_stmt, decl_stmt, expr, condition}的子树。
下游任务(3个无监督,2两个有监督)
- code clustering
- code clone detection
- cross language code-to-code search
- code classification
- method name prediction
DOBF: A Deobfuscation Pre-Training Objective for Programming Languages
arxiv 2021
Baptiste Roziere, Marie-Anne Lachaux, Marc Szafraniec, Guillaume Lample
Facebook AI Research, Paris Dauphine University
研究动机
目前基于BERT的代码预训练,预训练任务中基本都会包含Masked language modeling(MLM)。该任务在nlp领域应用广泛,即给定一个自然语言序列,随机替换掉其中的一些token,由模型预测替换掉的位置原来的token是什么。由于源代码相对于自然语言来说,更加规范,变量之间存在关联,所以预测mask掉的token更容易。这就意味着,如果使用MLM作为代码预训练的任务,模型可以学到的信息就相对较少,对于代码理解来说是不利的。至于其他的代码预训练模型中使用到的Next sentence prediction(NSP)和Replaced token detection(RTD),都是从nlp领域引入的,没有考虑代码的特性来设计特定的预训练任务。
其次,代码相对自然语言来说更规范,更具结构性,mask掉的token更容易被预测出来,如:mask掉一个右括号,可能根据括号的匹配,就可以被预测出来,但这对于模型学习代码特征来说是不利的。
所以,本文提出了一个特定于代码的预训练任务:code deobfuscation。也就是输入模糊化后的代码,模型试图还原原先的代码。
code obfuscation:是指在保证其主要功能的前提下,修改源代码,或者缩短代码,以增加人们理解代码的难度。
具体方法
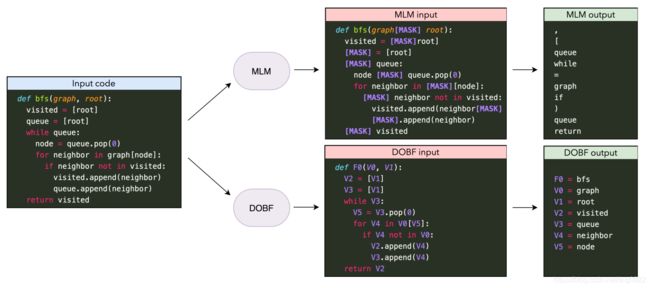
下图为MLM任务和DOBF任务的对比。
- MLM任务:以一定比例将input code中的token进行mask,得到了MLM input,模型需要预测出这些mask掉的token是什么(MLM output中的内容)。这些被mask的token可能是标点符号等的,对于模型的表示能力帮助不大。
- DOBF任务(图中为 P o b f = 1 P_{obf}=1 Pobf=1的情况):input code中所有类名、函数名和变量名都被替换成一些无信息量的名称,如:F0, V0等,这样转换之后的程序被称为obfuscated code(也就是图中的DOBF input)。模型需要将obfuscated code进行deobfuscation,预测这些无信息量的名称在原始的input code中的名称(DOBF output)。
the model is trained to generate the sequence: FUNC_0 bfs | VAR_0 graph | VAR_1 root | VAR_2 visited | VAR_3 queue | VAR_4 neighbor | VAR_5 node.
预训练任务中,mask的比例在(0, 1)之间:
- 当 P o b f = 0 P_{obf}=0 Pobf=0时,随机选择input code中的一个变量进行替换(该变量所在的其他位置也会被mask)。
- 当 P o b f = 1 P_{obf}=1 Pobf=1时,input code中所有的类名、函数名、变量名都会被替换成无信息量的名称。
模型架构:seq2seq model with attention
BERT(12 layers, 12 attention heads, and a hidden dimensionality of 768,还有一个6 layers, 8 attention heads, and a hidden dimensionality of 1024.)
数据集:Google BigQuery中的19G python和26G java数据
Baselines: CodeBERT 和 TransCoder
下游任务:
- CodeXGLUE clone detection
- CodeXGLUE code summarization
- CodeXGLUE code search
分析
- 对于学生写的变量命名不准确的代码,可以考虑采用该预训练的模型优化代码理解。
- 预测类名、函数名、变量,如果是基于一个特定的词典,无法预测出新词。在预测词与原词意思相近时,可能还是会有较大的损失。
其他参考文献
[1] Roziere, B., Lachaux, M.-A., Chanussot, L., and Lample, G. Unsupervised translation of programming languages. Advances in Neural Information Processing Systems, 33, 2020.
[2] Lacomis, J., Yin, P., Schwartz, E., Allamanis, M., Le Goues, C., Neubig, G., and Vasilescu, B. Dire: A neural approach to decompiled identifier naming. In 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), pp. 628–639. IEEE, 2019.
[3] David, Y., Alon, U., and Yahav, E. Neural reverse engineering of stripped binaries using augmented control flow graphs. Proceedings of the ACM on Programming Languages, 4(OOPSLA):1–28, 2020.
[4] Codexglue: An open challenge for code intelligence. arXiv, 2020.
IntelliCode Compose: Code Generation using Transformer
ESEC/FSE 2020
Alexey Svyatkovskiy, Shao Kun Deng, Shengyu Fu, Shengyu Fu (微软)
keywords: GPT-C (GPT model pretrianed on code corpus), multi-type code completion, multilingual model
研究动机
本文的任务是代码补全,目前代码补全的工作存在两点不足:
- 关注于特定的token types or features,根据上文token预测之后的token。忽略了整个方法全局的上下文。可能导致生成与方法功能不相容的token,更无法保证生成一整行代码的质量。
- 目前的工作在多语言建模时效果不佳。

针对以上不足,本文有三个贡献点:
- 提出了一个代码预训练模型GPT-C(GPT-2在大量代码语料上训练出来的模型)
- 基于GPT-C,构建了一个代码序列生成的模型IntelliCode Compose,可以较好地生成一整行代码
- 对多种语言的代码进行建模
具体方法
-
GPT-C
模型:GPT-2
数据集:12亿行Python, C#, Javascript, TypeScript语言的代码
分词方式: Byte-Pair Encoding (BPE),应对OOV问题

-
IntelliCode Compose
将sequence decoding的过程视为树的搜索过程,直至 token出现

-
Multilingual model
比较了四种建模多语言的方式:
1)忽略语言之间的不同,用统一的模型训练多种语言【实验表明:这种方式比单独对单语言训练效果更差】
2)加入language type embedding信息,每种语言用一个向量表示,和原本的token embedding等结合。
3)在每个训练样本的最开始加上一句"lang * remaining token sequence"
4)在预训练时,加入一个language type classification任务