图像识别:CNN、Spatial Transformer Layer(李宏毅2022
第三节 2021 - 卷积神经网络(CNN)_哔哩哔哩_bilibili
network架构设计

我们往往需要假设一个模型输入的影像大小都是一样的
把所有图片都先rescale成大小一样,再丢到影像辨识系统里
今天比较强的影像辨识系统,往往可以辨识出1000种以上的东西、甚至上万种
接下来的问题是,怎么把一个影像当作一个模型的输入?

对于一个machine来说,一张图片其实是一个三维的tensor(Tensor张量,可以看做是一个多维数组。维度大于2的矩阵)
一张彩色的图片,他每个pixel都是由R G B三个颜色所组成的,3个channel就代表了R G B三个颜色
长和宽代表了图片的解析度,这张图片里有的pixel像素的数目
接下来把三维的tensor拉直,拉直后就可以丢到一个network里去了(因为network的输入都是一个向量,)

目前为止 只讲过fully connected network
如果把这个向量当作network的输入,input这边 这个feature vector的长度就是100*100*3,假设第一层的neuron数目有1000个,那能计算一下第一层一共多少个weight吗?
参数增加可以增加模型的弹性、但也增加了overfitting的风险。
如何减少参数,考虑到影像辨识问题本身的特性,不需要fully connected。不需要每个neuron和input的每个dimension都有一个weight
对影像辨识问题本身的特性的观察:
1.


这些neuron只需要把图片的一小部分当作输入(receptive field(自己决定的)),就足以观察某些特别重要的pattern有没有出现了,


有的neuron只考虑一个channel的情况,也是可以的, 之后讲到network corporation时,会讲到这种架构。一般CNN里不常这样考虑
经典的 receptive field安排方式,会看所有的channel,高和宽合起来叫kernel size(一般不会设太大,3x3就足够了),
一般同一个receptive field会有一组neuron去守卫这个范围,
移动的量叫stride,自己决定的,往往不会设太大,1或2就可以了,因为希望receptive field之间是有重叠的
超出范围就做padding,补0,也有别的补植的方法,可以补整张图片里所有value的平均,可以拿边边的这些数字来补,etc.

观察2,同样的pattern可能出现在图片的不同区域里,
这些侦测鸟嘴的neuron做的事情其实是一样的,只是守卫的范围不一样,”公共课程“

怎么共享参数,自己决定的,
常见的共享方法,

fully connected layer可以做各式各样的事,但是他可能没有办法在任何特定的任务上做好,
CNN是转为影像设计的,但如果将他用在影像之外的任务,就要小心,那些任务是否有影像有的特性

另一种解释方式:

convolutional layer就是,里面有一排filter,每个都是一个3 x 3 x channel 这么大的tensor,每个filter的作用就是抓取图片里的某个pattern,每个pattern需要在3 x 3 x channel那么小的范围内,才能被filter抓出来
e.g.

假设这些filter的参数已知,filter就是一个个的tensor,这个tensor里的数值其实就是model里的parameter,(是透过梯度下降找出来的)
filter怎么去图片里侦测pattern的呢?
filter里对角线的地方都是1,所以他看到image里出现什么东西时 值最大,也出现连三个1时,如图,左上角和左下角出现pattern


当我们把一张图,通过convolutional layer,里面有一堆filter,我们产生出一个feature map,可以看成另外一张新图片channel为64,convolutional layer可以叠第二层,


network叠的越深, 同样是3x3大小的filter,他看的范围就会越来越大。

第一个版本里说neuron可以共用参数,这些共用的参数,就是第二个版本里的filter
share weight就是我们 把filter扫过一张图,这件事就是convolution



在做影像辨识时,第三个常用的东西,pooling
pooling本身没有参数,没有要Learn的东西,所以他不是个layer,比较像是个activation function,他就是一个operator,他的行为都是固定好的,没有要根据data学任何东西。

每组里选一个代表, 有max pooling,mean pooling,选几何平均,etc...自己决定的
2x2 一组也是自己决定的

我们做完convolution以后,往往还会搭配pooling,pooling做的事就是把图片变小,
实作上,往往convolution和pooling交替使用,

full convolutional neuron network
一个经典的影像辨识的network:

CNN另一个耳熟能详的应用,
下围棋就是一个分类的问题,

就是说每个位置有48种状态


CNN近年来也用在语言和文字处理上, 需要仔细看下文献上的方法,receptive field的设计、参数共享的设计 跟图像上不是一样的,考虑了语言和文字处理上的特性

CNN无法处理图片放大缩小的问题
这两张图形状一样,但是拉长成向量 里面的数值不一样,

(选修)To Learn More - Spatial Transformer Layer_哔哩哔哩_bilibili
李宏毅老师另一门课叫MLDS里有这节课的课件
CNN有一些translation invariance (平移不变性), image里某个object移动一点点,对他来说可能一样,这是因为max pooling,但如果这个人从左上角移到右下角,对CNN来说还是不一样,
spatial transformer layer功能是旋转缩放
Spatial Transformer Layer本身也是一个NN layer,
可以跟CNN并在一起直接训练,
不仅可以Transform输入,所有的feature map都可以(可以想成image)。

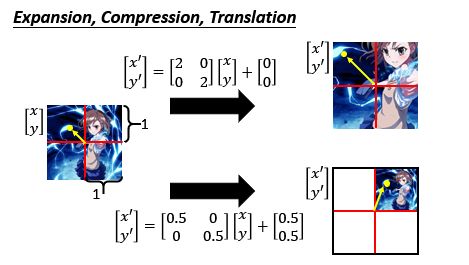
那么我们要怎么对一个image/feature map做transform呢?我们假设以下图左边这个image是transform前的结果 ,右边这个image是transform后的结果 ,很明显,这次转换是把image由上往下做了平移。

in general而言,fully connect layer可以写成 (将Output视为Input与Weight的计算加总),
(将Output视为Input与Weight的计算加总),
它也可以做的到Transformation,只要对Weight做一些适当的调整。
Weight设计成图里式子,就可以达成平移的目的。所以,我们想要对照片做缩放或旋转的话,只需要对Weight做不同的设计。
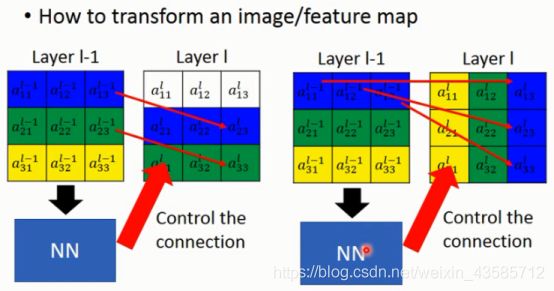
但问题是,怎么找weight,可以用NN来控制这两个image间weight的连接

数字图像处理的基操
(缩放之后,你的特征值的排列都改变了,CNN学习不到
在training数据不变的情况下,CNN不能处理放缩、旋转。能解决的方法之一是输入数据做了增强
不能说CNN完全不能学习,但是往往需要数据增强来辅助,也就是无法仅靠CNN有效提取这种差异
cnn应该是训练不出来的,比如说一根棍子,cnn学习的都是长度为5。所以cnn就认为连着5个1是棍子的特征,但是现在你棍子变成3个长度了,cnn就找不到这个特征了)

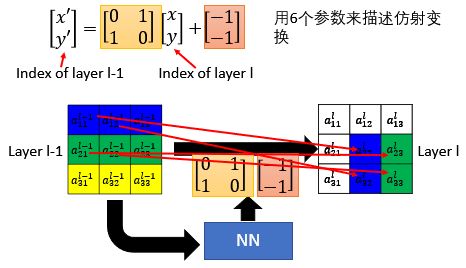
如果我们想要控制两张image之间的关系,我们要怎么做呢?如果只是旋转平移缩放的话,即其实只需要6个参数
(这边是不是输入和输出写反了呀,应该是输出=矩阵*输入+向量吧
其实老师没有讲错,layer L-1代表图片原始的样子,Layer L是变换后的样子,我们要做的工作是将变换后的图片还原成原始样子再送入CNN
注意老师没写反,这是一种“反向映射”技术
在实践中,一般都是由l层反推回去对应l-1层的哪一个像素的,这样子才能保证第l层每一个像素都能对应有值
没有反,这样相当于我们找这个位置应该填写原来位置的哪个数字)
翻转再左上移动
那么如果参数是小数的情况呢?
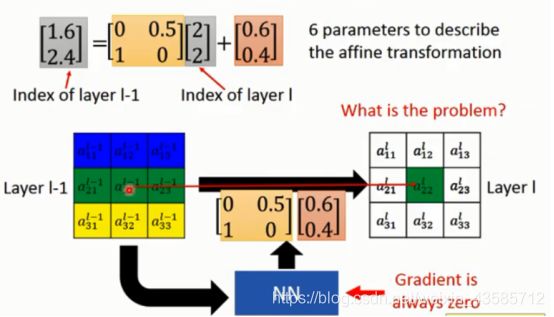
四舍五入?不能这么做。这种情况下。是无法利用梯度下降来求解的,
梯度是: 将参数做小小的变化,它对Output会有多少影响,
无法train这个network
(取整和梯度冲突了,取整函数的有效梯度都是0啊
.不可以用gradient descent,因为你四舍五入之后,函数相当于做了分段处理,都不连续了怎么求导‘
不连续是可以求导的,把坏点填平就可以gd的,主要是取整函数有效梯度都是0,所以没法做了
应该是四舍五入后,相当于前后一段区间对应的值都固定不变,所以梯度为零)
解决方案:插值 interpolation
这个小数索引实际上是在4个点的区间内,我们不单纯的参考它跟距离最近的那个点(没法微分),而是4个点的数值都参考。

这种情况下NN参数有些微的变化的时候Output也会有些微的变化,就可以利用梯度下降来优化求解了。

STN一般作为中间模块,不单独使用,可以加入到CNN的任意位置,而且相应的计算量也很少.
将 spatial transformers 模块集成到 cnn 网络中,允许NN自动地学习如何进行 feature map 的转变,从而有助于降低NN训练中整体的loss。
从“卷积”、到“图像卷积操作”、再到“卷积神经网络”,“卷积”意义的3次改变_哔哩哔哩_bilibili


一个系统,输入不稳定,输出稳定,用卷积求系统存量
f 函数,图像=输入不稳定
g 函数,卷积核=输出稳定

f 函数 某时刻发生一件事,是受到之前发生事的影响(x时刻蝴蝶扇动翅膀)
g函数 规定随着时间 事件影响力的变换
对图像进行卷积操作:看很多像素点对某个像素点是如何产生影响的
卷积核的点阵不一样,处理图像的效果也不一样。
 平滑卷积核
平滑卷积核
卷积核就是规定了周围像素点如何对当前像素点产生影响的.

对图像进行过滤,保存某些特征
一个像素点如何试探周围的像素点,如何筛选图像的特征。过滤器


