利用pytorch实现VGG网络
目 录
1 VGG网络介绍
1.1 VGG网络概述及特点
1.2 16层(D)网络详解
2 利用Pytorch实现AlexNet网络
2.1 模型定义
2.2 训练过程和预测部分
3 总结
1 VGG网络介绍
1.1 VGG网络概述及特点
在VGG网络原论文中,作者尝试了不同的网络深度:

在我们平常使用中,一般采取16层(D)的配置, 包括13个卷积层和3个全连接层。该网络的一个亮点是通过堆叠多个3×3的卷积核来替代大尺度卷积核,目的是可以减少所需的训练参数。
该网络的论文中提到通过堆叠两个3x3的卷积核来替代一个5x5的卷积核,堆叠三个3x3的卷积核来替代一个7x7的卷积核,他们之间有相同的感受野。
对于感受野:
在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层的区域大小,被称作感受野(receptive field)。通俗的解释是,输出特征矩阵上的一个单元对应输入层上的区域大小。比如下图的卷积过程:

根据公式:
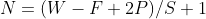
通过conv1,N=(9-3)/2+1=4,因此得到的输出为4×4×1,再经过一个池化层,最终得到2×2×1的输出。然后往回计算感受野,感受野计算公式如下:
![]()
其中的![]() 为第
为第 层的感受野,
层的感受野, 为第层的步长,
为第层的步长,![]() 为卷积核或池化核尺寸。第一层的感受野为1,池化层的感受野通过公式计算=(1-1)×2+2=2,卷积层的感受野通过公式计算=(2-1)×2+3=5。所以输出层的一个单位在原图中拥有5×5的感受视野。
为卷积核或池化核尺寸。第一层的感受野为1,池化层的感受野通过公式计算=(1-1)×2+2=2,卷积层的感受野通过公式计算=(2-1)×2+3=5。所以输出层的一个单位在原图中拥有5×5的感受视野。
对于VGG网络的论文中提到的卷积核替代,计算过程如下(该网络卷积核的步长默认为1):
①输出层:F=1
②Conv3×3(3):F=(1-1)×1+3=3
③Conv3×3(2):F=(3-1)×1+3=5
④Conv3×3(1):F=(5-1)×1+3=7
因此通过三层3×3的卷积核卷积之后所得到的1个单位在原图上所对应的感受野是7×7大小,如果只采用一层卷积核,根据公式计算1=(7-F)/1+1解得需要一个7×7的卷积核,然后我们分别计算所需要的参数,假设输入和输出的层数相同均为C:
7×7卷积核:7×7×C×C=49C²(第一个C是因为卷积核深度和输入深度相同;第二个C是因为假设了输出层数为C,因此需要C个卷积核)
三个3×3卷积核:3×3×C×C+3×3×C×C+3×3×C×C=27C²
因此采用三个3×3卷积代替一个7×7卷积核,所需的参数要少很多。
1.2 16层(D)网络详解
VGG网络16层结构如图所示:

输入是[3, 224, 224]的图片;conv的步长为1,padding为1,这样使得输入输出的特征矩阵宽和高是不变的(根据公式计算N=(224-3+2×1)/1+1=224);池化核是2×2的,步长为2,使特征矩阵的宽和高变为原来一半。
对于图中的网络,输入[3, 224, 224]的图片,首先经过①两个卷积层(深度为3,卷积核为3×3,个数为64),得到[64, 224, 224]的输出矩阵;再经过一个池化层,得到[64, 112, 112]的输出矩阵;再经过②两个卷积层(深度为64,卷积核为3×3,个数为128),得到[128, 112, 112]的输出矩阵;再经过一个池化层,得到[128, 56, 56]的输出矩阵,再经过③三个卷积层(深度为128,卷积核为3×3,个数为256),得到[256, 56, 56]的输出矩阵;再经过一个池化层,得到[256, 28, 28]的输出矩阵;再经过④三个卷积层(深度为256,卷积核为3×3,个数为512),得到[512, 28, 28]的输出矩阵;再经过一个池化层,得到[512, 14, 14]的输出矩阵;再经过⑤三个卷积层(深度为512,卷积核为3×3,个数为512),得到[512, 14, 14]的输出矩阵;再经过一个池化层,得到[512, 7, 7]的输出矩阵;再经过两个节点个数为4096的全连接层,最后一层全连接层的节点个数由类别个数决定;最后通过softmax激活函数转化为概率分布。
2 利用Pytorch实现AlexNet网络
2.1 模型定义
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}分别配置A、B、D、E四个网络结构,其中的数字代表卷积层卷积核的个数,'M'代表池化层。通过该列表我们可以生成不同的提取特征网络结构,具体思路如下(代码已注释):
# 传入需要的网络列表
def make_features(cfg: list):
# 创建一个空列表,由于遍历是有顺序的,因此网络结构会按照顺序传入
layers = []
# 定义输入图片的通道数
in_channels = 3
# 开始遍历列表
for v in cfg:
# 如果列表值为M,说明是池化层,就将一个池化层加到空列表中
if v == "M":
# 池化核为2×2,步长为2
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
# 如果不为M,说明是卷积层
else:
# 定义一个卷积层,卷积核个数为列表中的值即为v,卷积核大小为3×3,padding为1
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
# 卷积层紧跟着一个激活函数,因此把卷积层和激活函数都加到空列表中
layers += [conv2d, nn.ReLU(True)]
# 上一层的输入为下一层的输出,因此要把in_channels值更新为v
in_channels = v
# 将列表通过非关键字参数(把列表中的元素拆开传入)输入到nn.Sequential中生成一个网络结构(也可以通过有序字典的形式输入)
return nn.Sequential(*layers)定义整个的网络结构:
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
# 展平要展1维,因为第0维是batch
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
# 遍历网络的每一个子模块
for m in self.modules():
# 如果当前层是卷积层
if isinstance(m, nn.Conv2d):
# 使用xavier方法初始化卷积核权重
nn.init.xavier_uniform_(m.weight)
# 如果卷积核采用了偏置
if m.bias is not None:
# 则将偏置初始化为0
nn.init.constant_(m.bias, 0)
# 若为全连接层
elif isinstance(m, nn.Linear):
# 使用xavier方法初始化全连接层权重
nn.init.xavier_uniform_(m.weight)
# 将偏置初始化为0
nn.init.constant_(m.bias, 0)在网络定义中涉及到是否对网络进行参数的初始化使用了xavier初始化方法,该方法能够使每一层输出的方差尽量相等,以减小深层神经网络训练的困难;还用到了nn.init.constant_函数,该函数的作用是用值填充输入的张量(在此即为初始化为0),对于为什么将偏置初始化为0,还需要再学习学习。
然后需要实例化网络:
# 传入需要实例化的网络配置
def vgg(model_name="vgg16", **kwargs):
# 获得该网络在字典中对应的配置
cfg = cfgs[model_name]
# 将配置传入make_features函数得到一个网络,后面的可变长度字典中的参数包括分类个数和是否要初始化网络参数的布尔值
model = VGG(make_features(cfg), **kwargs)
return model2.2 训练过程和预测部分
训练过程和预测部分和利用pytorch实现AlexNet网络相同,唯一不同的一点是实例化vgg网络的方法:
model_name = "vgg16"
net = vgg(model_name=model_name, num_classes=5, init_weights=True)根据model_name的不同使用不同的网络结构,数据集仍然是花分类数据集,类别个数为5。
3 总结
VGG网络模型较大,需要充足的数据集来支持训练,并且训练速度很慢,对于花分类数据集,训练的正确率能达到75%左右。