中文词向量:使用pytorch实现CBOW
整个项目和使用说明地址:链接:https://pan.baidu.com/s/1my30wyqOk_WJD0jjM7u4TQ
提取码:xxe0
关于词向量的理论基础和基础模型都看我之前的文章。里面带有论文和其他博客链接。可以系统学习关于词向量的知识。
之前已经使用numpy手动实现skip-gram,现在使用pytorch框架实现CBOW 这是pytorch官网的CBOW案例的修改,简单明了,没有涉及底层代码,没有层次优化or负采样优化等问题。这里直接使用pytorch实现并且做了结果可视化。
中文词向量:word2vec之skip-gram实现(不使用框架实现词向量模型)_Richard_Kim的博客-CSDN博客
这一次可以使用完整语料进行训练,不用担心内存爆炸问题,使用了cuda加速。
实验原理还是原来那样。
1. 项目结构

2. 需要的依赖:pytorch,numpy,matplotlib,sklearn,tqdm,jieba。
3. 中文乱码问题同上面的skip-gram一样
4.运行
我只设置了100维,没有像skip-gram设置了300维
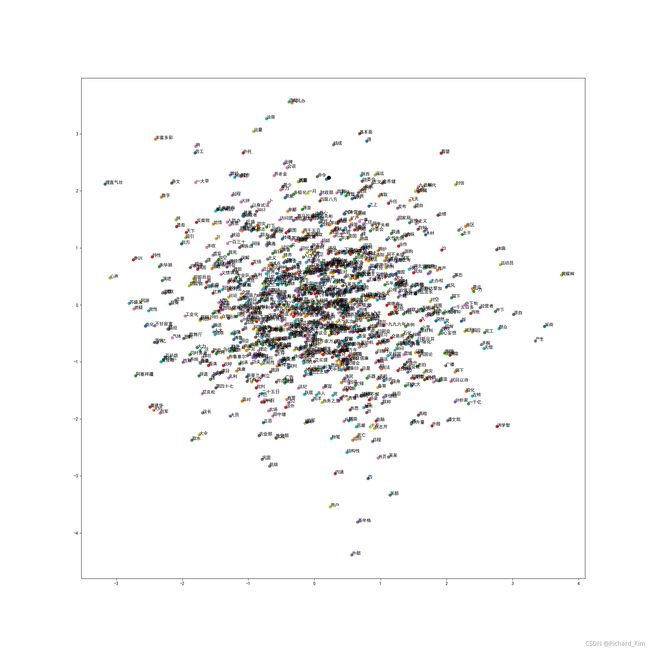
中文语料运行结果

完整代码
#!/usr/bin/endimension python
# -#-coding:utf-8 -*-
# author:by ucas iie 魏兴源
# datetime:2021/11/07 16:45:21
# software:PyCharm
"""
之前已经使用numpy手动实现skip-gram,现在使用pytorch框架实现CBOW
这是pytorch官网的CBOW案例的修改,简单明了,没有涉及底层代码,没有层次优化or负采样优化等问题
地址:https://pytorch.org/tutorials/beginner/nlp/word_embeddings_tutorial.html?highlight=cbow
"""
import jieba
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from matplotlib import pyplot as plt
from sklearn.decomposition import PCA
from tqdm import tqdm, trange
# 初始化矩阵
torch.manual_seed(1)
# 加载停用词词表
def load_stop_words():
"""
停用词是指在信息检索中,
为节省存储空间和提高搜索效率,
在处理自然语言数据(或文本)之前或之后
会自动过滤掉某些字或词
"""
with open('data/stopwords.txt', "r", encoding="utf-8") as f:
return f.read().split("\n")
# 加载文本,切词
def cut_words():
stop_words = load_stop_words()
with open('data/zh.txt', encoding='utf8') as f:
allData = f.readlines()
result = []
for words in allData:
c_words = jieba.lcut(words)
result.append([word for word in c_words if word not in stop_words])
return result
# 用一个集合存储所有的词
wordList = []
# 调用切词方法
data = cut_words()
count = 0
for words in data:
for word in words:
if word not in wordList:
wordList.append(word)
print("wordList=", wordList)
raw_text = wordList
print("raw_text=", raw_text)
# 超参数
learning_rate = 0.001
# 放cuda或者cpu里
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 上下文信息,即涉及文本的前n个和后n个
context_size = 2
# 词嵌入的维度,即一个单词用多少个浮点数表示比如 the=[10.2323,12.132133,4.1219774]...
embedding_dim = 100
epoch = 10
def make_context_vector(context, word_to_ix):
idxs = [word_to_ix[w] for w in context]
return torch.tensor(idxs, dtype=torch.long)
# 把所有词集合转成dict
vocab = set(raw_text)
vocab_size = len(vocab)
word_to_idx = {word: i for i, word in enumerate(vocab)}
idx_to_word = {i: word for i, word in enumerate(vocab)}
# cbow那个词表,即{[w1,w2,w4,w5],"label"}这样形式
data = []
for i in range(2, len(raw_text) - 2):
context = [raw_text[i - 2], raw_text[i - 1],
raw_text[i + 1], raw_text[i + 2]]
target = raw_text[i]
data.append((context, target))
print(data[:5])
class CBOW(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.proj = nn.Linear(embedding_dim, 128)
self.output = nn.Linear(128, vocab_size)
def forward(self, inputs):
embeds = sum(self.embeddings(inputs)).view(1, -1)
out = F.relu(self.proj(embeds))
out = self.output(out)
nll_prob = F.log_softmax(out, dim=-1)
return nll_prob
# 模型在cuda训练
model = CBOW(vocab_size, embedding_dim).to(device)
# 优化器
optimizer = optim.SGD(model.parameters(), lr=0.001)
# 存储损失的集合
losses = []
"""
负对数似然损失函数,用于处理多分类问题,输入是对数化的概率值。
对于包含N NN个样本的batch数据 D ( x , y ) D(x, y)D(x,y),x xx 是神经网络的输出,
进行了归一化和对数化处理。y yy是样本对应的类别标签,每个样本可能是C种类别中的一个。
"""
loss_function = nn.NLLLoss()
for epoch in trange(epoch):
total_loss = 0
for context, target in tqdm(data):
# 把训练集的上下文和标签都放到GPU中
context_vector = make_context_vector(context, word_to_idx).to(device)
target = torch.tensor([word_to_idx[target]]).cuda()
# print("context_vector=", context_vector)
# 梯度清零
model.zero_grad()
# 开始前向传播
train_predict = model(context_vector).cuda() # 这里要从cuda里取出,不然报设备不一致错误
loss = loss_function(train_predict, target)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
total_loss += loss.item()
losses.append(total_loss)
print("losses-=", losses)
# 测试一下,用['present', 'food', 'can', 'specifically']这个上下预测一下模型,正确答案是‘surplus’
context = ['粮食', '出现', '过剩', '恰好']
# 这个变量要放到gpu中,不然又要报设备不一致错误,因为只有把这个数据 同cuda里训练好的数据比较,再能出结果。。很好理解吧
context_vector = make_context_vector(context, word_to_idx).to(device)
# 预测的值
predict = model(context_vector).data.cpu().numpy()
print('Raw text: {}\n'.format(' '.join(raw_text)))
print('Test Context: {}\n'.format(context))
max_idx = np.argmax(predict)
# 输出预测的值
print('Prediction: {}'.format(idx_to_word[max_idx]))
# 获取词向量,这个Embedding就是我们需要的词向量,他只是一个模型的一个中间过程
print("CBOW embedding'weight=", model.embeddings.weight)
W = model.embeddings.weight.cpu().detach().numpy()
# 生成词嵌入字典,即{单词1:词向量1,单词2:词向量2...}的格式
word_2_vec = {}
for word in word_to_idx.keys():
# 词向量矩阵中某个词的索引所对应的那一列即为所该词的词向量
word_2_vec[word] = W[word_to_idx[word], :]
print("word2vec=", word_2_vec)
"""
待转换类型的PyTorch Tensor变量带有梯度,直接将其转换为numpy数据将破坏计算图,
因此numpy拒绝进行数据转换,实际上这是对开发者的一种提醒。
如果自己在转换数据时不需要保留梯度信息,可以在变量转换之前添加detach()调用。
"""
pca = PCA(n_components=2)
principalComponents = pca.fit_transform(W)
# 降维后在生成一个词嵌入字典,即即{单词1:(维度一,维度二),单词2:(维度一,维度二)...}的格式
word2ReduceDimensionVec = {}
for word in word_to_idx.keys():
word2ReduceDimensionVec[word] = principalComponents[word_to_idx[word], :]
# 将生成的字典写入到文件中,字符集要设定utf8,不然中文乱码
with open("CBOW_ZH_wordvec.txt", 'w', encoding='utf-8') as f:
for key in word_to_idx.keys():
f.write('\n')
f.writelines('"' + str(key) + '":' + str(word_2_vec[key]))
f.write('\n')
# 将词向量可视化
plt.figure(figsize=(20, 20))
# 只画出1000个,太多显示效果很差
count = 0
for word, wordvec in word2ReduceDimensionVec.items():
if count < 1000:
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号,否则负号会显示成方块
plt.scatter(wordvec[0], wordvec[1])
plt.annotate(word, (wordvec[0], wordvec[1]))
count += 1
plt.show()
QQ:530193235