基于pytorch实现Word2Vec(skip-gram+Negative Sampling)
目录
word2vec简介
语料处理
数据预处理
训练模型
近似训练法
参数设定
预测及可视化
word2vec简介
2013 年,Google 团队发表了 word2vec 工具。word2vec 工具主要包含两个模型:跳字模型(skip-gram)和连续词模型(continuous bag of words,简称 CBOW),以及两种高效训练的方法:负采样(negative sampling)和层序 softmax(hierarchical softmax)。
类似于f(x)->y,Word2vec 的最终目的,不是要把 f 训练得多么完美,而是只关心模型训练完后的副产物——模型参数(这里特指神经网络的权重),并将这些参数,作为输入 x 的某种向量化的表示,这个向量便叫做——词向量。
word2vec 词向量可以较好地表达不同词之间的相似度和类比关系。
语料处理
步骤:
- 使用 re 的 findall 方法以及正则表达式去除标点符号;
- 使用 jieba 进行分词;
- 使用停用词典剔除无意义的词。
处理前:

处理后:

代码如下:
import re
import jieba
stopwords = {}
fstop = open('stop_words.txt', 'r', encoding='utf-8', errors='ingnore')
for eachWord in fstop:
stopwords[eachWord.strip()] = eachWord.strip() # 创建停用词典
fstop.close()
f1 = open('红楼梦.txt', 'r', encoding='utf-8', errors='ignore')
f2 = open('红楼梦_p.txt', 'w', encoding='utf-8')
line = f1.readline()
while line:
line = line.strip() # 去前后的空格
if line.isspace(): # 跳过空行
line = f1.readline()
line = re.findall('[\u4e00-\u9fa5]+', line) # 去除标点符号
line = "".join(line)
seg_list = jieba.cut(line, cut_all=False) # 结巴分词
outStr = ""
for word in seg_list:
if word not in stopwords: # 去除停用词
outStr += word
outStr += " "
if outStr: # 不为空添加换行符
outStr = outStr.strip() + '\n'
f2.writelines(outStr)
line = f1.readline()
f1.close()
f2.close()
数据预处理
步骤:
- 剔除低频词;
- 生成 id 到 word、word 到 id 的映射;
使用 subsampling 处理语料;- 定义获取正、负样本方法;
- 估计数据中正采样对数。
测试结果:
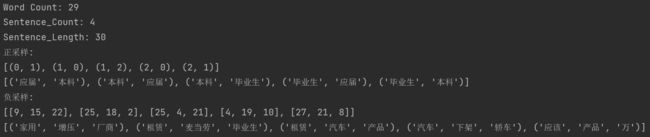
这里 min_count=1 也就是不剔除低频词,窗口大小设定为2,负样本数量 k 设定为3。
代码如下:
import math
import numpy
from collections import deque
from numpy import random
numpy.random.seed(6)
class InputData:
def __init__(self, file_name, min_count):
self.input_file_name = file_name
self.get_words(min_count)
self.word_pair_catch = deque() # deque为队列,用来读取数据
self.init_sample_table() # 采样表
print('Word Count: %d' % len(self.word2id))
print("Sentence_Count:", self.sentence_count)
print("Sentence_Length:", self.sentence_length)
def get_words(self, min_count): # 剔除低频词,生成id到word、word到id的映射
self.input_file = open(self.input_file_name, encoding="utf-8")
self.sentence_length = 0
self.sentence_count = 0
word_frequency = dict()
for line in self.input_file:
self.sentence_count += 1
line = line.strip().split(' ') # strip()去除首尾空格,split(' ')按空格划分词
self.sentence_length += len(line)
for w in line:
try:
word_frequency[w] += 1
except:
word_frequency[w] = 1
self.word2id = dict()
self.id2word = dict()
wid = 0
self.word_frequency = dict()
for w, c in word_frequency.items(): # items()以列表返回字典(键, 值)
if c < min_count:
self.sentence_length -= c
continue
self.word2id[w] = wid
self.id2word[wid] = w
self.word_frequency[wid] = c
wid += 1
self.word_count = len(self.word2id)
def subsampling(self, corpus, word2id_freq): # 使用二次采样算法(subsampling)处理语料,强化训练效果
# 这个discard函数决定了一个词会不会被替换,这个函数是具有随机性的,每次调用结果不同
# 如果一个词的频率很大,那么它被遗弃的概率就很大
def discard(word_id):
return random.uniform(0, 1) < 1 - math.sqrt(
1e-5 / word2id_freq[word_id] * len(corpus))
corpus = [word for word in corpus if not discard(word)]
return corpus
def init_sample_table(self): # 获得负样本采样表
self.sample_table = []
sample_table_size = 1e8 # 10*8
pow_frequency = numpy.array(list(self.word_frequency.values())) ** 0.75 # 采样公式
words_pow = sum(pow_frequency) # 求和获得归一化参数Z
ratio = pow_frequency / words_pow
count = numpy.round(ratio * sample_table_size) # round四舍五入,得到每个词的出现次数
for wid, c in enumerate(count): # 按采样频率估计的次数将词放入词表
self.sample_table += [wid] * int(c)
self.sample_table = numpy.array(self.sample_table)
numpy.random.shuffle(self.sample_table) # 打乱采样表
# self.sample_table = self.subsampling(self.sample_table,self.word_frequency) # 重采样
def get_batch_pairs(self, batch_size, window_size): # 获取正样本
while len(self.word_pair_catch) < batch_size: # 当队列中数据个数小于batch_size, 向队列添加数据
sentence = self.input_file.readline()
if sentence is None or sentence == '':
self.input_file = open(self.input_file_name, encoding="utf-8")
sentence = self.input_file.readline()
word_ids = []
for word in sentence.strip().split(' '):
try:
word_ids.append(self.word2id[word]) # 获取中心词
except:
continue
for i, u in enumerate(word_ids): # 按窗口依次取不同的id对
for j, v in enumerate(
word_ids[max(i - window_size, 0):i + window_size]): # 获取周围词
assert u < self.word_count
assert v < self.word_count
if i == j: # 上下文词=中心词 跳过
continue
self.word_pair_catch.append((u, v)) # 将正样本对(u, v)加入队列
batch_pairs = []
for _ in range(batch_size): # 返回batch大小的正采样对
batch_pairs.append(self.word_pair_catch.popleft()) # popleft()左出
return batch_pairs
def get_neg_v_neg_sampling(self, pos_word_pair, count): # 获取负样本
neg_v = numpy.random.choice( # 有选择的随机
self.sample_table, size=(len(pos_word_pair), count)).tolist()
return neg_v
def evaluate_pair_count(self, window_size): # 估计数据中正采样对数,用于设定batch
return self.sentence_length * (2 * window_size - 1) - (
self.sentence_count - 1) * (1 + window_size) * window_size训练模型(skip-gram)
skip-gram 的思想是用一个词语作为输入,来预测它周围的上下文。

步骤:
- 初始化词向量矩阵及权重;
- 根据传入的词向量以及公式计算Loss;
- 保存训练后的词向量。
代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SkipGramModel(nn.Module):
def __init__(self, emb_size, emb_dimension):
super(SkipGramModel, self).__init__()
self.emb_size = emb_size
self.emb_dimension = emb_dimension
self.u_embeddings = nn.Embedding(emb_size, emb_dimension, sparse=True) # 初始化中心词向量矩阵
self.v_embeddings = nn.Embedding(emb_size, emb_dimension, sparse=True) # 初始化周围词向量矩阵
self.init_emb()
def init_emb(self):
initrange = 0.5 / self.emb_dimension
self.u_embeddings.weight.data.uniform_(-initrange, initrange) # 初始化中心词词向量矩阵权重
self.v_embeddings.weight.data.uniform_(-0, 0)
def forward(self, pos_u, pos_v, neg_v):
emb_u = self.u_embeddings(pos_u) # [batch_size * emb_dimension]
emb_v = self.v_embeddings(pos_v) # [batch_size * emb_dimension]
score = torch.mul(emb_u, emb_v).squeeze() # [batch_size * emb_dimension]
score = torch.sum(score, dim=1) # [batch_size * 1]
score = F.logsigmoid(score) # [batch_size * 1]
neg_emb_v = self.v_embeddings(neg_v) # [batch_size, k, emb_dimension]
neg_score = torch.bmm(neg_emb_v, emb_u.unsqueeze(2)).squeeze() # [batch_size, k]
neg_score = F.logsigmoid(-1 * neg_score) # [batch_size, k]
# L = log sigmoid (Xu.T * θv) + ∑neg(v) [log sigmoid (-Xu.T * θneg(v))]
return -1 * (torch.sum(score) + torch.sum(neg_score))
def save_embedding(self, id2word, file_name, use_cuda): # 保存中心词与周围词向量矩阵
embedding = self.u_embeddings.weight.cpu().data.numpy()
# embedding_u = self.u_embeddings.weight.cpu().data.numpy()
# embedding_v = self.v_embeddings.weight.cpu().data.numpy()
# embedding = (embedding_u + embedding_v) / 2
fout = open(file_name, 'w', encoding="utf-8")
fout.write('%d %d\n' % (len(id2word), self.emb_dimension))
for wid, w in id2word.items():
e = embedding[wid]
e = ' '.join(map(lambda x: str(x), e))
fout.write('%s %s\n' % (w, e))近似训练法(Negative Sampling)
无论是跳字模型还是连续词袋模型,每一步梯度计算的开销与词典V的大小呈正相关。显然,当词典较大时,这种训练方法的计算开销会很大。所以使用上述训练方法在实际中是由难度的。我们可以使用近似的方法来计算这些梯度,从而减小计算开销。
负采样的核心思想是将多分类问题转化为二分类问题(判断是正样本还是负样本)。
参数设定
-
emb_dimension=100, # 词嵌入维度 batch_size=50, # 批处理批次大小 window_size=5, # 上下文窗口 iteration=1, initial_lr=0.025, k=5, # 负采样数 min_count=5 # 设定低频词出现次数
设定好参数就可以开始训练了 。
from input_data import InputData
from model import SkipGramModel
from torch.autograd import Variable
import torch
import torch.optim as optim
from tqdm import tqdm
from gensim import utils
class Word2Vec(utils.SaveLoad):
def __init__(self,
input_file_name,
output_file_name,
emb_dimension=100, # 词嵌入维度
batch_size=50, # 批处理批次大小
window_size=5, # 上下文窗口
iteration=1,
initial_lr=0.025,
k=5, # 负采样数
min_count=5): # 设定低频词出现次数
self.data = InputData(input_file_name, min_count)
self.output_file_name = output_file_name
self.emb_size = len(self.data.word2id) # 词的数量
self.emb_dimension = emb_dimension
self.batch_size = batch_size
self.window_size = window_size
self.iteration = iteration
self.initial_lr = initial_lr
self.k = k
self.skip_gram_model = SkipGramModel(self.emb_size, self.emb_dimension)
self.use_cuda = torch.cuda.is_available()
if self.use_cuda:
self.skip_gram_model.cuda()
self.optimizer = optim.SGD(self.skip_gram_model.parameters(), lr=self.initial_lr)
def train(self):
pair_count = self.data.evaluate_pair_count(self.window_size) # 样本对数量
batch_count = self.iteration * pair_count / self.batch_size # 批次数量
process_bar = tqdm(range(int(batch_count))) # 进度条
for i in process_bar:
pos_pairs = self.data.get_batch_pairs(self.batch_size, self.window_size) # 获取正样本
neg_v = self.data.get_neg_v_neg_sampling(pos_pairs, self.k) # 获取负样本
pos_u = [pair[0] for pair in pos_pairs]
pos_v = [pair[1] for pair in pos_pairs]
# 传入参数以进行反向传播
pos_u = Variable(torch.LongTensor(pos_u))
pos_v = Variable(torch.LongTensor(pos_v))
neg_v = Variable(torch.LongTensor(neg_v))
if self.use_cuda:
pos_u = pos_u.cuda()
pos_v = pos_v.cuda()
neg_v = neg_v.cuda()
self.optimizer.zero_grad() # 初始化0梯度
loss = self.skip_gram_model.forward(pos_u, pos_v, neg_v) # 正向传播
loss.backward() # 反向传播
self.optimizer.step() # 优化目标函数
process_bar.set_description("Loss: %0.8f, lr: %0.6f" % (loss.data.item(),
self.optimizer.param_groups[0]['lr']))
print(loss)
print(loss.shape)
if i * self.batch_size % 100000 == 0: # 动态更新学习率
lr = self.initial_lr * (1.0 - 1.0 * i / batch_count)
for param_group in self.optimizer.param_groups:
param_group['lr'] = lr
self.skip_gram_model.save_embedding( # 保存词向量
self.data.id2word, self.output_file_name, self.use_cuda)
def save(self, *args, **kwargs): # 保存模型
super(Word2Vec, self).save(*args, **kwargs)
if __name__ == '__main__':
w2v = Word2Vec("data/zhihu_p.txt", "data/zhihu_e.txt")
w2v.train()预测及可视化
类似于f(x)->y,Word2vec 的最终目的,不是要把 f 训练得多么完美,而是只关心模型训练完后的副产物——模型参数(这里特指神经网络的权重),并将这些参数,作为输入 x 的某种向量化的表示,这个向量便叫做——词向量。
word2vec 词向量可以较好地表达不同词之间的相似度和类比关系。
-
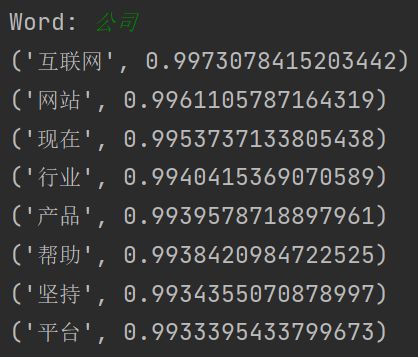
计算相似度
根据余弦相似度计算公式输出 top10 的词语。
测试结果:


代码如下:
from sklearn.metrics.pairwise import cosine_similarity
import numpy
f = open("红楼梦_e.txt", encoding="utf-8")
f.readline()
all_embeddings = []
all_words = []
word2id = dict()
for i, line in enumerate(f):
line = line.strip().split(' ')
word = line[0]
embedding = [float(x) for x in line[1:]]
# assert len(embedding)==100
all_embeddings.append(embedding) # 所有的词向量
all_words.append(word)
word2id[word] = i
all_embeddings = numpy.array(all_embeddings)
while 1:
word = input('Word: ')
if word == 'exit':
exit()
try:
wid = word2id[word]
except:
print('Cannot find this word')
continue
embedding = all_embeddings[wid:wid + 1] # 取出词向量[embedding]
d = cosine_similarity(embedding, all_embeddings)[0] # 计算相似度
d = zip(all_words, d) # 合并成(word,cosine_similarity)的形式
d = sorted(d, key=lambda x: x[1], reverse=True) # 从大到小排序
for w in d[:10]: # 取前10个词
if w[0] == word or len(w[0]) < 2: # 过滤本身及单个字符词
continue
print(w)-
词类比
运用词相似度的原理计算出word1与word2的距离d,从而推测与word3相距d的word4,即:
word1 -> word2 <====> word3 -> word4
代码如下:
import numpy as np
def cosine_similarity(u, v):
dot = np.dot(u, v)
u_norm = np.sqrt(np.sum(np.power(u, 2)))
v_norm = np.sqrt(np.sum(np.power(v, 2)))
cosine_similarity = np.divide(dot, u_norm * v_norm)
return cosine_similarity
def read_vecs(file):
with open(file, 'r', encoding='utf8') as f:
words = set()
word_to_vec_map = {}
for line in f:
line = line.strip().split()
curr_word = line[0]
words.add(curr_word)
word_to_vec_map[curr_word] = np.array(line[1:], dtype=np.float64)
return words, word_to_vec_map
def complete_analogy(word_a, word_b, word_c, word_to_vec_map):
word_a, word_b, word_c = word_a.lower(), word_b.lower(), word_c.lower()
e_a, e_b, e_c = word_to_vec_map[word_a], word_to_vec_map[word_b], word_to_vec_map[word_c]
words = word_to_vec_map.keys()
max_similarity = -100
best_word = None
for word in words:
if word in [word_a, word_b, word_c]:
continue
local_similarity = cosine_similarity((e_b - e_a), (word_to_vec_map[word] - e_c))
if local_similarity > max_similarity:
max_similarity = local_similarity
best_word = word
return best_word
words, word_to_vec_map = read_vecs('红楼梦_e.txt')
triads_to_try = [('男孩', '女孩', '男人')]
for triad in triads_to_try:
print('{} -> {} <====> {} -> {}'.format(*triad, complete_analogy(*triad, word_to_vec_map)))-
词向量可视化
步骤:
- 导入包matplotlib.pyplot、KMeans、PCA;
- 读取词向量文件信息,获取所有词数组(array)和词到词向量的映射(dict);
- 用for循环得到当前所选词的词向量数组(array);
- 将高维向量压缩为二维向量,以此作为可视化图像的X与Y轴坐标;
- 设定好维度、颜色、字体后开始画图,最后再为每个词标注信息。
预测效果:

代码如下:
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
f = open("zhihu_e.txt", encoding="utf-8")
f.readline()
all_words = [] # 所有词
word2emb = dict() # 词到词向量的映射
for i, line in enumerate(f):
line = line.strip().split(' ')
word = line[0]
embedding = [float(x) for x in line[1:]]
all_words.append(word)
word2emb[word] = embedding
pca = PCA(n_components=2) # 将目标向量维度(n_components)设定为2
KM = KMeans(n_clusters=10) # 使用10种颜色进行标注
corpus = all_words[0:200] # 只显示前200个单词
vector = []
for word in corpus: # 获取到当前词的所有词向量
emb = word2emb[word]
vector.append(emb)
vector_2d = pca.fit_transform(vector) # 降维到二维
y_ = KM.fit_predict(vector_2d) # 将所有点分成多个簇,以便标注不同颜色
plt.rcParams['font.sans-serif'] = ['FangSong'] # 标注字体为仿宋
plt.scatter(vector_2d[:, 0], vector_2d[:, 1], c=y_)
for i in range(len(corpus)): # 给每个点进行标注
plt.annotate(text=corpus[i], xy=(vector_2d[:, 0][i], vector_2d[:, 1][i]),
xytext=(vector_2d[:, 0][i] + 0.1, vector_2d[:, 1][i] + 0.1))
plt.show()