机器学习(四)多元线性回归和正规方程
文章目录
-
- Log
- 一、多元线性回归(Multivariate linear regression)
- 二、多元梯度下降法(Multivariate gradient descent)
-
- 1.梯度下降算法引入多变量
- 2.特征缩放(feature scaling)
- 3.学习率
-
- ①确保梯度下降正常工作
- ②正确选择学习率
- 三、特征和多项式回归
-
- 1.特征的选择
- 2.多项式回归(Polynomial regression)
- 四、正规方程(Normal Equation)
-
- 1.梯度下降与正规方程简单的比较
- 2.正规方程的直接理解
- 3.正规方程的一般形式
- 4.梯度下降与正规方程具体的比较
- 5.矩阵不可逆(non-invertibility)情况
- 总结
Log
2022.01.02继续学习,记录一下2022.01.03学习速度比计划中的要慢,得快点了
2022.01.04或许应该调整一下计划
一、多元线性回归(Multivariate linear regression)
- 多变量(Multiple variables): 即每一个样本都有多个特征(features), 于是引入如下符号:
n = number of features(样本特征数量) x ( i ) = input (features) of i t h training example(第i个样本) x j ( i ) = value of feature j in i t h training example(第i个样本的第j个特征值) \begin{aligned} n&=\textbf{number \ of \ features(样本特征数量)}\\ x^{(i)}&=\textbf{input\ (features)\ of }\ i^{th}\ \textbf{training\ example(第i个样本)}\\ x^{(i)}_j&=\textbf{value\ of \ feature }\ j \ \textbf{in} \ i^{th}\ \textbf{training\ example(第i个样本的第j个特征值)}\\ \end{aligned} nx(i)xj(i)=number of features(样本特征数量)=input (features) of ith training example(第i个样本)=value of feature j in ith training example(第i个样本的第j个特征值) - 例如:
| Size(feet²) x_1 |
Number of bedrooms x_2 |
Number of floors x_3 |
Age of home (years) x_4 |
Price($1000) y |
|---|---|---|---|---|
| 2104 | 5 | 1 | 45 | 460 |
| 1416 | 3 | 2 | 40 | 232 |
| 1534 | 3 | 2 | 40 | 315 |
| 852 | 2 | 1 | 36 | 178 |
| … | … | … | … | … |
x ( 2 ) = [ 1416 3 2 40 232 ] x 3 ( 2 ) = 2 \begin{aligned} x^{(2)}&=\left[\begin{matrix} 1416\\ 3\\ 2\\ 40\\ 232 \end{matrix}\right]\\ x^{(2)}_3&=2 \end{aligned} x(2)x3(2)=⎣⎢⎢⎢⎢⎡14163240232⎦⎥⎥⎥⎥⎤=2
- 引入多变量后原来的假设函数(Hypothesis)也随之变化:
P r i v i o u s l y : h θ ( x ) = θ 0 + θ 1 x C u r r e n t l y : h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n \begin{aligned} Priviously:\qquad &h_θ(x) = θ_0 + θ_1x\\ Currently:\qquad &h_θ(x) = θ_0 + θ_1x_1+θ_2x_2+...+θ_nx_n \end{aligned} Priviously:Currently:hθ(x)=θ0+θ1xhθ(x)=θ0+θ1x1+θ2x2+...+θnxn - 为了简化以上表达式,定义:
x_0 = 1,则有:
x = [ x 0 x 1 x 2 . . . x n ] ∈ R n + 1 θ = [ θ 0 θ 1 θ 2 . . . θ n ] ∈ R n + 1 h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n = [ θ 0 θ 1 θ 2 . . . θ n ] ⏟ ( n + 1 ) × 1 [ x 0 x 1 x 2 . . . x n ] = θ T x x = \left[\begin{matrix} x_0\\ x_1\\ x_2\\ ...\\ x_n \end{matrix}\right]\in R^{n+1}\qquad θ=\left[\begin{matrix} θ_0\\ θ_1\\ θ_2\\ ...\\ θ_n \end{matrix}\right]\in R^{n+1}\\\quad\\ \begin{aligned} h_θ(x) &= θ_0 + θ_1x_1+θ_2x_2+...+θ_nx_n\\ &=\underbrace{ \left[\begin{matrix} θ_0&θ_1&θ_2&...&θ_n \end{matrix}\right]}_{(n+1)×1}\left[\begin{matrix} x_0\\ x_1\\ x_2\\ ...\\ x_n \end{matrix}\right] \\&=θ^Tx \end{aligned} x=⎣⎢⎢⎢⎢⎡x0x1x2...xn⎦⎥⎥⎥⎥⎤∈Rn+1θ=⎣⎢⎢⎢⎢⎡θ0θ1θ2...θn⎦⎥⎥⎥⎥⎤∈Rn+1hθ(x)=θ0+θ1x1+θ2x2+...+θnxn=(n+1)×1 [θ0θ1θ2...θn]⎣⎢⎢⎢⎢⎡x0x1x2...xn⎦⎥⎥⎥⎥⎤=θTx - 多元线性回归(Multivariate linear regression): 如上,多元(Multivariate)即多特征,多变量。
二、多元梯度下降法(Multivariate gradient descent)
1.梯度下降算法引入多变量
- 首先将代价函数简化为向量的形式:
J ( θ 0 , θ 1 , . . . , θ n ) ⟹ J ( θ ) J(θ_0,θ_1,...,θ_n)\implies J(θ) J(θ0,θ1,...,θn)⟹J(θ) - 进一步我们就可以从单变量梯度下降变为多变量梯度下降:
P r e v i o u s l y ( n = 1 ) R e p e a t { θ 0 : = θ 0 − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) ⏟ ∂ ∂ θ 0 J ( θ ) θ 1 : = θ 1 − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x ( i ) } Previously\ (n=1)\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\\\quad\\ \\ \begin{aligned}Repeat\{\end{aligned}\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\quad \\ \quad\\ \begin{aligned} θ_0:&=θ_0-α\underbrace{\frac{1}{m}\sum_{i=1}^m (h_θ(x^{(i)}) - y^{(i)} )} _{\frac{\partial}{\partial θ_0}J(θ)} \\ θ_1:&=θ_1-α\frac{1}{m}\sum_{i=1}^m (h_θ(x^{(i)}) - y^{(i)} )\ ·x^{(i)} \end{aligned} \\ \}\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad Previously (n=1)Repeat{θ0:θ1:=θ0−α∂θ0∂J(θ) m1i=1∑m(hθ(x(i))−y(i))=θ1−αm1i=1∑m(hθ(x(i))−y(i)) ⋅x(i)}
N e w a l g o r i t h m ( n ≥ 1 ) R e p e a t { θ j : = θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x j ( i ) } E . g . θ 0 : = θ 0 − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x 0 ( i ) θ 1 : = θ 1 − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x 1 ( i ) θ 2 : = θ 2 − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x 2 ( i ) . . . New \ algorithm\ (n≥1)\qquad\qquad\qquad\qquad\qquad\qquad\qquad\\\quad\\ \\ \begin{aligned}Repeat\{\end{aligned}\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\quad \\ \quad\\ θ_j:=θ_j-α\frac{1}{m}\sum_{i=1}^m (h_θ(x^{(i)}) - y^{(i)} )\ ·x^{(i)}_j \\ \}\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\\\quad\\ E.g.\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad \\ θ_0:=θ_0-α\frac{1}{m}\sum_{i=1}^m (h_θ(x^{(i)}) - y^{(i)} )\ ·x^{(i)}_0\\ \quad\\ θ_1:=θ_1-α\frac{1}{m}\sum_{i=1}^m (h_θ(x^{(i)}) - y^{(i)} )\ ·x^{(i)}_1\\ \quad\\ θ_2:=θ_2-α\frac{1}{m}\sum_{i=1}^m (h_θ(x^{(i)}) - y^{(i)} )\ ·x^{(i)}_2\\ \quad\\... \\ New algorithm (n≥1)Repeat{θj:=θj−αm1i=1∑m(hθ(x(i))−y(i)) ⋅xj(i)}E.g.θ0:=θ0−αm1i=1∑m(hθ(x(i))−y(i)) ⋅x0(i)θ1:=θ1−αm1i=1∑m(hθ(x(i))−y(i)) ⋅x1(i)θ2:=θ2−αm1i=1∑m(hθ(x(i))−y(i)) ⋅x2(i)...
2.特征缩放(feature scaling)
- 要旨: 确保不同特征的取值在相近的范围(a similar scale) 内,这样梯度下降算法就能更快的收敛。
- 以两个特征量为例,如果二者的取值范围相差过大,那么最终展现出来的代价函数J(θ)的等值线(contour) 图像为一个细长的椭圆(下图左),即偏移(skew) 严重,进而导致在梯度下降的过程中来回振荡(meander around),需要花费很长时间才能找到一条到达全局最优解的路线;通过进行特征缩放(scale the features),使两个特征量的取值更加接近,得到的图像看起来会更加圆一些(下图右),梯度下降算法会找到一条更直接的路,速度相比较而言也会更快

- 目标: 令
x_0 = 1, 剩下的变量近似满足-1 ≤ x_i ≤ 1(也就是说,可以稍微大一点或小一点,但是别太大或太小,0到3和-2到0.5也行,相比之下-100到100、-0.00001到0.00001就不行)。并不需要太精确,能够让梯度下降进行的更快就行。 - 具体做法:
- 将特征除以最大值(divide by the maximum value),例如
x 1 = s i z e 2000 x_1=\frac{size}{2000} x1=2000size - 均值归一(mean normalization),例如
x 1 = s i z e − 1000 2000 x_1=\frac{size-1000}{2000} x1=2000size−1000
即
x 1 = x 1 − μ 1 s 1 x_1=\frac{x_1-μ_1}{s_1} x1=s1x1−μ1
其中
μ 1 : 变 量 x 1 的 平 均 值 s 1 : x 1 的 范 围 ( m a x − m i n ) , 或 x 1 的 标 准 差 \begin{aligned} μ_1&:变量x_1的平均值 \\ s_1&:x_1的范围(max-min),或x_1的标准差 \end{aligned} μ1s1:变量x1的平均值:x1的范围(max−min),或x1的标准差
注意:均值归一处理时 x_0 不用变(x_0 = 1)。
- 将特征除以最大值(divide by the maximum value),例如
3.学习率
- 梯度下降算法的更新规则如下:
θ j : = θ j − α ∂ ∂ θ j J ( θ ) θ_j:=θ_j-α\frac{\partial}{\partial θ_j}J(θ) θj:=θj−α∂θj∂J(θ)
①确保梯度下降正常工作
- 调试(Debugging): 如何保证梯度下降正常工作。
- 正常情况:每一步迭代之后J(θ)都应该下降。
- 不同的情况达到近似收敛需要的迭代次数不同,收敛的阈值很难确定,一般通过J(θ)的图像来判断,而不是通过自动收敛测试来判断。

- 与此同时,也可以通过J(θ)的图像来判断梯度下降是否正常工作,如果出现随着迭代次数的增加J(θ)不断增大的情况(下图左),那么有可能是因为学习率α选择过大(下图中,从红点处开始迭代,左右来回振荡,每次都越过最小值不断增大,下图右)。

②正确选择学习率
- 可以证明出,只要学习率α足够小,每次迭代就都会下降,但是学习率α过小则会导致迭代速度变慢。
- 总结:
- 学习率α过大会导致迭代后J(θ)数值增大。
- 学习率α过小会导致迭代速度变慢。
- 在确定学习率α时通常要选择一系列不同的值进行测试,每隔10倍取一个值(也可以是3倍,如0.001–> 0.003–> 0.01–> 0.03–> 0.1–> 0.3–> 1),再对每一个α绘制J(θ)关于迭代步数变化的曲线,然后选择使J(θ)快速下降的α值作为最终的学习率(比最大值小一些或者比最小值大一些,合理即可)。
三、特征和多项式回归
1.特征的选择
- 可以通过定义新特征来建立更好的模型,以房价预测为例:

- 最初的假设函数里有2个特征,分别是临街宽度(frontage) 和 纵深(depth) ,但是预测房价时显然用土地面积(land area) 来预测会更加合理一些,因此进行如下的操作:
h θ ( x ) = θ 0 + θ 1 × f r o n t a g e ⏟ x 1 + θ 2 × d e p t h ⏟ x 2 a r e a = f r o n t a g e × d e p t h ⇓ x = x 1 × x 2 h θ ( x ) = θ 0 + θ 1 × x \begin{aligned} h_θ(x)&=θ_0+θ_1×\underbrace{frontage}_{x_1}+θ_2×\underbrace{depth}_{x_2}\\\quad\\ area&=frontage×depth\\&\Downarrow\\ x&=x_1×x_2\\\quad\\ h_θ(x)&=θ_0+θ_1×x \end{aligned} hθ(x)areaxhθ(x)=θ0+θ1×x1 frontage+θ2×x2 depth=frontage×depth⇓=x1×x2=θ0+θ1×x
2.多项式回归(Polynomial regression)
-
多项式回归(Polynomial regression): 与选择特征相近的想法密切相关的一个概念,通过对算法进行处理来实现对数据的拟合,应用于非线性关系的拟合。
-
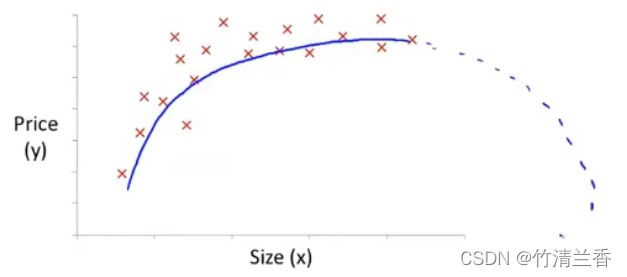
以下图为例,图中展示的是房屋大小与价格的训练集。

-
根据图像的特点,我们可以清楚地发现,通过一次函数来拟合并不能达到最好的效果,自然地我们便想到了用二次函数来拟合:
θ 0 + θ 1 x + θ 2 x 2 θ_0+θ_1x+θ_2x^2 θ0+θ1x+θ2x2
-
虽然二次函数可以较好地拟合当前数据,但是通过分析可知该二次函数是上凸的,也就是说在函数的后半段图像会呈现下降的趋势,即随着房屋面积的增大房价会随之降低,这显然是不合理的,因此用二次函数来拟合数据并不理想,进一步想到用三次函数来拟合:
θ 0 + θ 1 x + θ 2 x 2 + θ 3 x 3 θ_0+θ_1x+θ_2x^2+θ_3x^3 θ0+θ1x+θ2x2+θ3x3 -
使用多项式回归对假设函数进行简单的处理,来实现上述三次函数对数据的拟合:
h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + θ 3 x 3 = θ 0 + θ 1 ( s i z e ) 1 + θ 2 ( s i z e ) 2 + θ 3 ( s i z e ) 3 x 1 = ( s i z e ) x 2 = ( s i z e ) 2 x 3 = ( s i z e ) 3 \begin{aligned} h_θ(x)&=θ_0+θ_1x_1+θ_2x_2+θ_3x_3\\ &=θ_0+θ_1(size)^1+θ_2(size)^2+θ_3(size)^3\\ x_1 &= (size)\\ x_2 &=(size)^2\\ x_3 &=(size)^3\\ \end{aligned} hθ(x)x1x2x3=θ0+θ1x1+θ2x2+θ3x3=θ0+θ1(size)1+θ2(size)2+θ3(size)3=(size)=(size)2=(size)3 -
通过对三个特征量的设置,再应用线性回归的方法,就可以将一个三次函数拟合到上述数据中。
-
值得注意的是,当使用梯度下降算法时,如果三个特征量的范围相差过大,还需要进行特征缩放 ,将值的范围变得具有可比性。
-
除此之外,拟合的方式并不唯一,对于本例而言,还可以用以下的假设函数进项拟合(保证了上升趋势,不会下降):
h θ ( x ) = θ 0 + θ 1 ( s i z e ) + θ 2 ( s i z e ) h_θ(x)=θ_0+θ_1(size)+θ_2\sqrt{(size)} hθ(x)=θ0+θ1(size)+θ2(size)
四、正规方程(Normal Equation)
- 正规方程对于某些线性回归问题会给出更好的方法来求参数θ的最优值。
1.梯度下降与正规方程简单的比较
- 梯度下降算法通过多次迭代实现代价函数J(θ)的最小化。
- 正规方程则提供了 一种求θ的解析解法(analytical method),即不需要进行迭代,一步求出最佳θ的值。
2.正规方程的直接理解
- θ为实数时: 假设有一个非常简单的代价函数J(θ),就是一个实数θ的函数(θ是一个标量/实数值,不是向量),其中该函数是θ的二次函数(quadratic function),通过对其求导(take derivation) 并将导数(derivatives) 置零来最小化该二次函数,得到使J(θ)最小的θ值。
θ ∈ R J ( θ ) = a θ 2 + b θ + c ∂ ∂ θ J ( θ ) = 0 ⇒ θ θ\in\R\qquad\\\qquad\qquad\\ \begin{aligned} J(θ)&=aθ^2+bθ+c\\ \frac{\partial}{\partial{θ}}J(θ)&=0\quad\Rightarrow\quad θ \end{aligned} θ∈RJ(θ)∂θ∂J(θ)=aθ2+bθ+c=0⇒θ - θ为向量时: 当θ为一个n+1维的参数向量时,可以通过逐个对参数θ_j求J的偏导,再全部将其置零得到最小化代价函数J的θ值。
θ ∈ R n + 1 J ( θ 0 , θ 1 , . . . , θ m ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 ∂ ∂ θ j J ( θ ) = 0 ⇒ θ 0 , θ 1 , . . . , θ n θ\in \R^{n+1}\\\quad\\ \begin{aligned} J(θ_0,θ_1,...,θ_m)&=\frac{1}{2m}\sum_{i=1}^{m}(h_θ(x^{(i)})-y^{(i)})^2\\ \frac{\partial}{\partial θ_j}J(θ)&=0\quad\Rightarrow\quad θ_0,θ_1,...,θ_n\\ \end{aligned} θ∈Rn+1J(θ0,θ1,...,θm)∂θj∂J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2=0⇒θ0,θ1,...,θn - 实际上,当θ为向量时,求出的偏导形式会十分复杂,下面通过一个例子来引入一个更简单的方法:
- 下面是一个m=4(样本容量为4)n=4(特征数为4)的训练样本,为了能够实现正规方程,需要在最前面一列加上x_0,再构建出一个包含所有特征向量的矩阵X
x_0 |
Size(feet²) x_1 |
Number of bedrooms x_2 |
Number of floors x_3 |
Age of home (years) x_4 |
Price($1000) y |
|---|---|---|---|---|---|
| 1 | 2104 | 5 | 1 | 45 | 460 |
| 1 | 1416 | 3 | 2 | 40 | 232 |
| 1 | 1534 | 3 | 2 | 40 | 315 |
| 1 | 852 | 2 | 1 | 36 | 178 |
X = [ 1 2104 5 1 45 1 1416 3 2 40 1 1534 3 2 40 1 852 2 1 36 ] ⏟ m × ( n + 1 ) y = [ 460 232 315 178 ] ⏟ m × 1 X=\underbrace{\left[\begin{matrix} 1&2104&5&1&45\\ 1&1416&3&2&40\\ 1&1534&3&2&40\\ 1&852&2&1&36\\ \end{matrix}\right]}_{m×(n+1)}\qquad y=\underbrace{\left[\begin{matrix} 460\\ 232\\ 315\\ 178 \end{matrix}\right]}_{m×1} X=m×(n+1) ⎣⎢⎢⎡11112104141615348525332122145404036⎦⎥⎥⎤y=m×1 ⎣⎢⎢⎡460232315178⎦⎥⎥⎤
- 进一步可以通过下面的式子直接求出使代价函数最小化的θ:
θ = ( X T X ) − 1 X T y \Huge\red {θ=(X^TX)^{-1}X^Ty} θ=(XTX)−1XTy - Octave中计算这个量的命令:
pinv(X'*X)*X'*y
3.正规方程的一般形式
- 假设有m个训练样本,n个特征变量,每一个训练样本x(i)的形式如下:
m e x a m p l e s ( x ( 1 ) , y ( 1 ) ) , . . . , ( x ( m ) , y ( m ) ) n f e a t u r e s x ( i ) = [ x 0 ( i ) x 1 ( i ) x 2 ( i ) . . . x n ( i ) ] ∈ R n + 1 \begin{aligned} &m\ \ examples\ (x^{(1)},y^{(1)}),...,(x^{(m)},y^{(m)})\\ &n \ \ \ features\\\quad\\ \end{aligned}\\ x^{(i)}=\left[\begin{matrix} x^{(i)}_0\\ x^{(i)}_1\\ x^{(i)}_2\\ .\\.\\.\\ x^{(i)}_n\\ \end{matrix}\right]\in\R^{n+1} m examples (x(1),y(1)),...,(x(m),y(m))n featuresx(i)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡x0(i)x1(i)x2(i)...xn(i)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤∈Rn+1 - 设计矩阵(design matrix): 使用上面给出的x(i)构造出的如下矩阵X:
X = [ ( x ( 1 ) ) T ( x ( 2 ) ) T . . . . . . ( x ( m ) ) T ] ⏟ m × ( n + 1 ) X=\underbrace{\left[\begin{matrix} (x^{(1)})^T\\ (x^{(2)})^T\\ ...\\ ...\\ (x^{(m)})^T\\ \end{matrix}\right]}_{\red{m×(n+1)}}\qquad X=m×(n+1) ⎣⎢⎢⎢⎢⎡(x(1))T(x(2))T......(x(m))T⎦⎥⎥⎥⎥⎤ - 例如:
i f x ( i ) = [ 1 x 1 ( i ) ] t h e n X = [ 1 x 1 ( 1 ) 1 x 2 ( 1 ) . . . . . . 1 x m ( 1 ) ] ⏟ m × 2 y = [ y ( 1 ) y ( 2 ) . . . . . . y ( m ) ] ⏟ m × 2 if\qquad x^{(i)}=\left[\begin{matrix} 1\\ x^{(i)}_1\\ \end{matrix}\right] \qquad then\quad X=\underbrace{\left[\begin{matrix} 1&x^{(1)}_1\\ 1&x^{(1)}_2\\ ...\\ ...\\ 1&x^{(1)}_m\\ \end{matrix}\right]}_{m×2}\qquad y=\underbrace{\left[\begin{matrix} y^{(1)}\\ y^{(2)}\\ ...\\ ...\\ y^{(m)}\\ \end{matrix}\right]}_{m×2}\qquad ifx(i)=[1x1(i)]thenX=m×2 ⎣⎢⎢⎢⎢⎢⎡11......1x1(1)x2(1)xm(1)⎦⎥⎥⎥⎥⎥⎤y=m×2 ⎣⎢⎢⎢⎢⎡y(1)y(2)......y(m)⎦⎥⎥⎥⎥⎤
4.梯度下降与正规方程具体的比较
m个训练样本,n个特征
| 梯度下降法 (Gradient Descent) |
正规方程法 (Normal Equation) |
|---|---|
| 缺点: 需要选择学习率α (即需要进行多次尝试,选择最佳学习率) |
优点: 不需要选择学习率α |
| 缺点: 需要进行多次迭代 | 优点: 不需要进行迭代 |
| 优点: 当n很大时仍然可以正常运行 |
缺点: 需要计算(X’X)的逆(n×n维) (计算机实现逆矩阵计算的代价以矩阵维度的三次方增长) |
| 缺点: n如果很大计算的速度就会慢 |
- 总结:如果n很大就选择梯度下降法,如果n很小就选择正规方程法,一般以10000作为大小的判断结点(n为10000时)。
- 注意:使用正规方程法不需要进行特征缩放。
- 对于后面将会学到的更加复杂的学习算法,正规方程法并不适用,梯度下降法反而更具优势,但对于线性回归这个特定的模型,正规方程法是一个比梯度下降法更快的替代算法。
5.矩阵不可逆(non-invertibility)情况
- 当计算下式时,如果
X'X不可逆怎么办?
θ = ( X T X ) − 1 X T y θ=(X^TX)^{-1}X^Ty θ=(XTX)−1XTy - 一般来说,不可逆的情况很少发生,如果使用Octave的
pinv(X'*X)*X'*y命令来计算,仍然可以得到正解。技术上来说,Octave里有两个可以计算矩阵的逆的函数:pinv和inv,区别就在于pinv是伪逆函数(pseudo-inverse,可以计算不可逆的情况),inv是逆。 - 导致不可逆发生的主要原因:
- ①包含了多余的特征(redundant features),即线性依赖(linearly dependent)、线性相关
- 例如:特征量x1代表房子的面积,以平方英尺作为单位,特征量x2也表示房子的面积,以平方米为单位,二者相互依赖,一个可以用另一个表示。
- 从数学的角度来说,就是一个矩阵的某两行存在着倍数的关系,即对应的两个方程实际上是一个方程(互为线性函数),通过对矩阵的化简操作可以产生“0”行,从而导致矩阵不可逆。
- ②有太多的特征变量(例如m≤n)
- 个人理解是样本数量太少,特征量之间更容易产生关联,导致线性相关(回到①,本质上的原因应该都是一样的)
- 解决方案:删去一些特征,或者使用一种叫做正则化(regularization) 的方法(后面会学到)。
- ①包含了多余的特征(redundant features),即线性依赖(linearly dependent)、线性相关
总结
- 本文介绍了多元线性回归以及两个相关的算法,分别是多元梯度下降法以及正规方程法,除此之外还讨论了特征以及多项式回归的问题。
- 多元线性回归是一种新的线性回归版本,具有更有效的形式,适用于多个变量或者多特征量的情况。
- 多元梯度下降法是在原来的梯度下降算法的基础上引入了多变量,当不同的特征取值范围相差太大时需要要进行特征缩放,一般以±1为边界,但对精度的要求并不是很高,除此之外,多元梯度下降法中还介绍了正确选择学习率的方法以及选择不恰当时会出现的问题。
- 对于正规方程法,只要特征变量的数目并不大(通常以10000作为边界),它就是一个很好的计算参数θ的替代方法,此时在线性回归模型中比梯度下降法更具有优势。
- 我们可以自由的对特征变量进行组合变换修改(或者定义新的特征),以获得更好的线性回归模型,通常可以通过多项式回归来实现这一变换。