深度学习第7周
本文为365天深度学习训练营内部限免文章 参考本文所写记录性文章,请在文章开头保留以下内容
本文为365天深度学习训练营 中的学习记录博客
参考文章:365天深度学习训练营-第7周:咖啡豆识别https://www.heywhale.com/mw/project/631160cd9b96502cad2a33ac
原作者:K同学啊|接辅导、项目定制
要求:
自己搭建VGG-16网络框架
调用官方的VGG-16网络框架
拔高(可选):
验证集准确率达到100%
使用PPT画出VGG-16算法框架图(发论文需要这项技能)
探索(难度有点大)
在不影响准确率的前提下轻量化模型
一、前期准备
1、设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices('GPU')
if gpus:
tf.config.experimental.set_memory_growth(gpus[0],True)
tf.config.set_visible_devices([gpus[0]],'GPU')
2、导入数据
from tensorflow import keras
from tensorflow.keras import models,layers
import numpy as np
import matplotlib.pyplot as plt
import PIL,pathlib
data_dir = '/home/mw/input/coffee5523/data/data/49-data'
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*.png')))
print('图片总数为',image_count)
图片总数为 1200
二、数据预处理
1、加载数据
batch_size = 32
img_height = 224
img_width = 224
train_ds = keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
seed = 123,
subset='training',
batch_size=batch_size,
image_size=(img_height,img_width)
)
train_ds = keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
seed = 123,
subset='training',
batch_size=batch_size,
image_size=(img_height,img_width)
)
class_names = train_ds.class_names
print(class_names)
[‘Dark’, ‘Green’, ‘Light’, ‘Medium’]
2、可视化
plt.figure(figsize=(12,6))
for images,labels in train_ds.take(1):
for i in range(10):
plt.subplot(2,5,i+1)
plt.imshow(images[i].numpy().astype('uint8'))
plt.title(class_names[labels[i]])
plt.axis('off')

for image_batch,label_batch in train_ds:
print(image_batch.shape)
print(label_batch.shape)
break
(32, 224, 224, 3)
(32,)
3、配置数据集
AUTOTUNE = tf.data.experimental.AUTOTUNE
train_ds = train_ds.cache().shuffle(1500).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
新知识点:模型外调用方法标准化
#数据标准化,这次标准化选择在模型外
normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)
train_ds = train_ds.map(lambda x,y : (normalization_layer(x),y))
val_ds = val_ds.map(lambda x,y : (normalization_layer(x),y))
image_batch,label_batch = next(iter(val_ds))
first_image = image_batch[0]
#查看归一化后数据
print(np.min(first_image),np.max(first_image))
0.0 1.0
三、构建VGG16模型
VGG优缺点分析:
-
VGG优点
VGG的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。 -
VGG缺点
1)训练时间过长,调参难度大。2)需要的存储容量大,不利于部署。例如存储VGG-16权重值文件的大小为500多MB,不利于安装到嵌入式系统中。
from tensorflow.keras import layers,models,Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D,MaxPooling2D,Dense,Flatten,Dropout
def VGG16(classes,input_shape):
input_tensor = Input(shape=input_shape)
x = Conv2D(64,(3,3),activation='relu',padding='same')(input_tensor)
x = Conv2D(64,(3,3),activation='relu',padding='same')(x)
x = MaxPooling2D((2,2),strides=(2,2))(x)
x = Conv2D(128,(3,3),activation='relu',padding='same')(x)
x = Conv2D(128,(3,3),activation='relu',padding='same')(x)
x = MaxPooling2D((2,2),strides=(2,2))(x)
x = Conv2D(256,(3,3),activation='relu',padding='same')(x)
x = Conv2D(256,(3,3),activation='relu',padding='same')(x)
x = Conv2D(256,(3,3),activation='relu',padding='same')(x)
x = MaxPooling2D((2,2),strides=(2,2))(x)
x = Conv2D(512,(3,3),activation='relu',padding='same')(x)
x = Conv2D(512,(3,3),activation='relu',padding='same')(x)
x = Conv2D(512,(3,3),activation='relu',padding='same')(x)
x = MaxPooling2D((2,2),strides=(2,2))(x)
x = Conv2D(512,(3,3),activation='relu',padding='same')(x)
x = Conv2D(512,(3,3),activation='relu',padding='same')(x)
x = Conv2D(512,(3,3),activation='relu',padding='same')(x)
x = MaxPooling2D((2,2),strides=(2,2))(x)
x = Flatten()(x)
x = Dense(4096,activation='relu')(x)
x = Dropout(0.3)(x)
x = Dense(2048,activation='relu')(x)
x = Dropout(0.3)(x)
output_tensor = Dense(classes,activation='softmax')(x)
model = Model(input_tensor,output_tensor)
return model
model = VGG16(len(class_names),(img_width,img_height,3))
model.summary()
Model: “functional_3”
Layer (type) Output Shape Param #
input_2 (InputLayer) [(None, 224, 224, 3)] 0
conv2d_13 (Conv2D) (None, 224, 224, 64) 1792
conv2d_14 (Conv2D) (None, 224, 224, 64) 36928
max_pooling2d_5 (MaxPooling2 (None, 112, 112, 64) 0
conv2d_15 (Conv2D) (None, 112, 112, 128) 73856
conv2d_16 (Conv2D) (None, 112, 112, 128) 147584
max_pooling2d_6 (MaxPooling2 (None, 56, 56, 128) 0
conv2d_17 (Conv2D) (None, 56, 56, 256) 295168
conv2d_18 (Conv2D) (None, 56, 56, 256) 590080
conv2d_19 (Conv2D) (None, 56, 56, 256) 590080
max_pooling2d_7 (MaxPooling2 (None, 28, 28, 256) 0
conv2d_20 (Conv2D) (None, 28, 28, 512) 1180160
conv2d_21 (Conv2D) (None, 28, 28, 512) 2359808
conv2d_22 (Conv2D) (None, 28, 28, 512) 2359808
max_pooling2d_8 (MaxPooling2 (None, 14, 14, 512) 0
conv2d_23 (Conv2D) (None, 14, 14, 512) 2359808
conv2d_24 (Conv2D) (None, 14, 14, 512) 2359808
conv2d_25 (Conv2D) (None, 14, 14, 512) 2359808
max_pooling2d_9 (MaxPooling2 (None, 7, 7, 512) 0
flatten_1 (Flatten) (None, 25088) 0
dense_3 (Dense) (None, 4096) 102764544
dropout_2 (Dropout) (None, 4096) 0
dense_4 (Dense) (None, 2048) 8390656
dropout_3 (Dropout) (None, 2048) 0
dense_5 (Dense) (None, 4) 8196
Total params: 125,878,084
Trainable params: 125,878,084
Non-trainable params: 0
四、模型编译
initial_learning_rate = 0.0001
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=initial_learning_rate,
decay_steps=30,
decay_rate=0.92,
staircase=True)
optimizer = tf.keras.optimizers.Adam(learning_rate = lr_schedule)
model.compile(optimizer = optimizer,
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
from tensorflow.keras.callbacks import ModelCheckpoint
checkpointer = ModelCheckpoint('best_model_week6.h5',
monitor = 'val_accuracy',
verbose = 1,
save_best_only = True,
save_weights_only = True)
from tensorflow.keras.callbacks import ModelCheckpoint
checkpointer = ModelCheckpoint('best_model_week6.h5',
monitor = 'val_accuracy',
verbose = 1,
save_best_only = True,
save_weights_only = True)
Epoch 00050: val_accuracy did not improve from 0.99167
30/30 [==============================] - 14s 466ms/step - loss: 4.6766e-04 - accuracy: 1.0000 - val_loss: 0.0166 - val_accuracy: 0.9875
五、模型评估
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
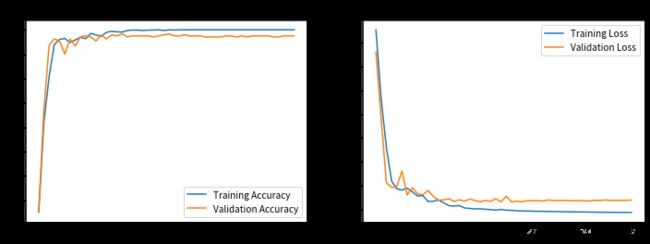
可以发现模型在20轮模拟后验证集准确率再无提升,且模型损失函数反而不断增加,为保险期间将模拟轮数由50轮减少到30轮
修改方案1
尝试添加BN层
效果极差,准去率降低到32%,验证集损失函数超过10
修改方案2
修改L2正则化参数
无明显效果,准确率提升到99%
修改方案3
参考上期题目采取预训练的权重参数
初次结果验证集准确率达到99.7%,尝试对全连接层的参数进行修改当前两个全连接层参数降低到1024,256时验证集准确率达到100%
from tensorflow.keras import layers,models,Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D,MaxPooling2D,Dense,Flatten,Dropout,BatchNormalization
def VGG16(classes,input_shape):
input_tensor = Input(shape=input_shape)
x = Conv2D(64,(3,3),activation='relu',padding='same')(input_tensor)
x = Conv2D(64,(3,3),activation='relu',padding='same')(x)
x = MaxPooling2D((2,2),strides=(2,2))(x)
x = Conv2D(128,(3,3),activation='relu',padding='same')(x)
x = Conv2D(128,(3,3),activation='relu',padding='same')(x)
x = MaxPooling2D((2,2),strides=(2,2))(x)
x = Conv2D(256,(3,3),activation='relu',padding='same')(x)
x = Conv2D(256,(3,3),activation='relu',padding='same')(x)
x = Conv2D(256,(3,3),activation='relu',padding='same')(x)
x = MaxPooling2D((2,2),strides=(2,2))(x)
x = Conv2D(512,(3,3),activation='relu',padding='same')(x)
x = Conv2D(512,(3,3),activation='relu',padding='same')(x)
x = Conv2D(512,(3,3),activation='relu',padding='same')(x)
x = MaxPooling2D((2,2),strides=(2,2))(x)
x = Conv2D(512,(3,3),activation='relu',padding='same')(x)
x = Conv2D(512,(3,3),activation='relu',padding='same')(x)
x = Conv2D(512,(3,3),activation='relu',padding='same')(x)
x = MaxPooling2D((2,2),strides=(2,2))(x)
#x = Flatten()(x)
#x = Dense(4096,activation='relu')(x)
#x = Dropout(0.3)(x)
#x = Dense(2048,activation='relu')(x)
#x = Dropout(0.3)(x)
#output_tensor = Dense(classes,activation='softmax')(x)
model = Model(input_tensor,x)
model.load_weights('/home/mw/project/vgg16_weights_tf_dim_ordering_tf_kernels_notop (1).h5')
for layer in model.layers[:13]:
layer.trainable = False
return model
model = VGG16(len(class_names),(img_width,img_height,3))
tot_model = models.Sequential([
model,
layers.Flatten(),
layers.Dense(1024,activation='relu'),
layers.Dense(256,activation='relu'),
layers.Dense(len(class_names),activation='softmax')
])
tot_model.summary()