神经网络输入层输出层,神经网络输入数据要求
1、bp神经网络对输入数据和输出数据有什么要求
p神经网络的输入数据越多越好,输出数据需要反映网络的联想记忆和预测能力。
BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
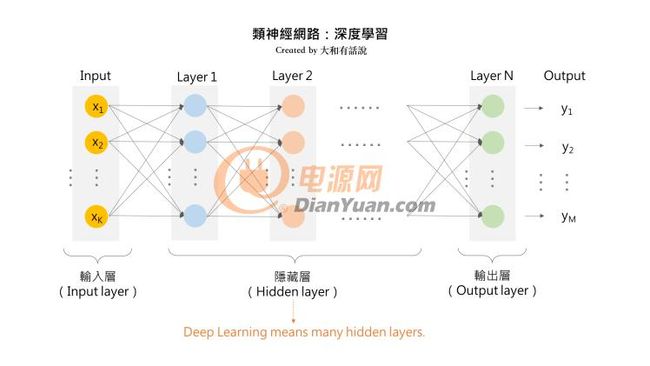
BP神经网络模型拓扑结构包括输入层(input)、隐层(hide layer)和输出层(output layer)。BP网络具有高度非线性和较强的泛化能力,但也存在收敛速度慢、迭代步数多、易于陷入局部极小和全局搜索能力差等缺点。
扩展资料:
BP算法主要思想是:输入学习样本,使用反向传播算法对网络的权值和偏差进行反复的调整训练,使输出的向量与期望向量尽可能地接近,当网络输出层的误差平方和小于指定的误差时训练完成,保存网络的权值和偏差。
1、初始化,随机给定各连接权及阀值。
2、由给定的输入输出模式对计算隐层、输出层各单元输出
3、计算新的连接权及阀值,计算公式如下:
4、选取下一个输入模式对返回第2步反复训练直到网络设输出误差达到要求结束训练。
参考资料来源:
谷歌人工智能写作项目:小发猫

2、LSTM神经网络输入输出究竟是怎样的?
输入输出都是向量,或者说是矩阵神经网络输入层的数据格式。LSTM用于分类的话,后面一般会接softmax层。个人浅薄理解,拿动作识别分类举例,每个动作帧放入LSTM中训练,还是根据task来训练每个LSTM单元的Weights。所以LSTM的单元数量跟输入和输出都没有关系,甚至还可以几层LSTM叠加起来用。分类的话,一般用最后一个单元接上softmax层。LSTM结构是传统的RNN结构扩展,解决了传统RNN梯度消失/爆炸的问题,从而使得深层次的网络更容易训练。从这个角度理解,可能会容易很多。今年的ResNet也是使传统的CNN更容易训练weights。看来deeplearning越来越深是趋势啊。如果说训练,就一个关键,所谓LSTMUnroll,将RNN展开成一个静态的“并行”网络,内部有“侧向连接”,实现长的短时记忆功能(状态“记忆”在LSTMCell里)。如果说预测,也就一个关键,要将Cell的h和C弄出来,作为当前状态(也就是所谓“记忆”)作为init参数输入,这样,携带了当前记忆状态的网络,预测得到的就是下一个输入了,所谓的recurrent了。那份代码里还包含了一个使用cudnn的实现(built-inRNNoperator),这是一个高性能的版本,可以真正干活的。原来我也尝试搞懂一些天书般的公式,很快发现从那里入手是个错误。强烈推荐:理解LSTM网络(翻译自UnderstandingLSTMNetworks)只要有一点点CNN基础+半个小时,就可以通过这篇文章理解LSTM的基础原理。回答你的问题:和神经元个数无关,不知道你是如何理解“神经元”这个概念的,输入输出层保证tensor的维数和输入输出一致就可以了。
3、神经网络参数如何确定
神经网络各个网络参数设定原则:
①、网络节点 网络输入层神经元节点数就是系统的特征因子(自变量)个数,输出层神经元节点数就是系统目标个数。隐层节点选按经验选取,一般设为输入层节点数的75%。如果输入层有7个节点,输出层1个节点,那么隐含层可暂设为5个节点,即构成一个7-5-1 BP神经网络模型。在系统训练时,实际还要对不同的隐层节点数4、5、6个分别进行比较,最后确定出最合理的网络结构。
②、初始权值的确定 初始权值是不应完全相等的一组值。已经证明,即便确定 存在一组互不相等的使系统误差更小的权值,如果所设Wji的的初始值彼此相等,它们将在学习过程中始终保持相等。故而,在程序中,我们设计了一个随机发生器程序,产生一组一0.5~+0.5的随机数,作为网络的初始权值。
③、最小训练速率 在经典的BP算法中,训练速率是由经验确定,训练速率越大,权重变化越大,收敛越快;但训练速率过大,会引起系统的振荡,因此,训练速率在不导致振荡前提下,越大越好。因此,在DPS中,训练速率会自动调整,并尽可能取大一些的值,但用户可规定一个最小训练速率。该值一般取0.9。
④、动态参数 动态系数的选择也是经验性的,一般取0.6 ~0.8。
⑤、允许误差 一般取0.001~0.00001,当2次迭代结果的误差小于该值时,系统结束迭代计算,给出结果。
⑥、迭代次数 一般取1000次。由于神经网络计算并不能保证在各种参数配置下迭代结果收敛,当迭代结果不收敛时,允许最大的迭代次数。
⑦、Sigmoid参数 该参数调整神经元激励函数形式,一般取0.9~1.0之间。
⑧、数据转换。在DPS系统中,允许对输入层各个节点的数据进行转换,提供转换的方法有取对数、平方根转换和数据标准化转换。
扩展资料:
神经网络的研究内容相当广泛,反映了多学科交叉技术领域的特点。主要的研究工作集中在以下几个方面:
1.生物原型
从生理学、心理学、解剖学、脑科学、病理学等方面研究神经细胞、神经网络、神经系统的生物原型结构及其功能机理。
2.建立模型
根据生物原型的研究,建立神经元、神经网络的理论模型。其中包括概念模型、知识模型、物理化学模型、数学模型等。
3.算法
在理论模型研究的基础上构作具体的神经网络模型,以实现计算机模拟或准备制作硬件,包括网络学习算法的研究。这方面的工作也称为技术模型研究。
神经网络用到的算法就是向量乘法,并且广泛采用符号函数及其各种逼近。并行、容错、可以硬件实现以及自我学习特性,是神经网络的几个基本优点,也是神经网络计算方法与传统方法的区别所在。
参考资料:百度百科-神经网络(通信定义)
4、卷积神经网络用全连接层的参数是怎么确定的?
卷积神经网络用全连接层的参数确定:卷积神经网络与传统的人脸检测方法不同,它是通过直接作用于输入样本,用样本来训练网络并最终实现检测任务的。
它是非参数型的人脸检测方法,可以省去传统方法中建模、参数估计以及参数检验、重建模型等的一系列复杂过程。本文针对图像中任意大小、位置、姿势、方向、肤色、面部表情和光照条件的人脸。
输入层
卷积神经网络的输入层可以处理多维数据,常见地,一维卷积神经网络的输入层接收一维或二维数组,其中一维数组通常为时间或频谱采样;二维数组可能包含多个通道;二维卷积神经网络的输入层接收二维或三维数组;三维卷积神经网络的输入层接收四维数组。
由于卷积神经网络在计算机视觉领域应用较广,因此许多研究在介绍其结构时预先假设了三维输入数据,即平面上的二维像素点和RGB通道。
5、什么是神经网络的input; output; class?? neuron 怎么构成的网络?? 看书没看明白,求大牛解答.. 15
输入就是样本啊,就是数据,只不过每个数据可能有很多项,那些是特征值,这些都是不一定的,要看数据本身。几种类型?一般情况,神经网络的输入都是实数,应该不能是其他类型的吧?
输入层的个数就是这些样本的特征数。神经元就是相当于里面的一个节点,有输入也有输出,因为是模拟生物神经的一个基本单元,所以称为神经元而已。
输出层的个数一般为类别数,根据编码方式不一样可能略有不同。比如,三类的可以只有两个输出。但是一般为类别数,那个输出最多,属于那个类别的可能性也比较大。
输入不含权值,权值是训练出来的,根据一定的训练样本。
建议看看《神经网络设计》