PyTorch源码学习系列 - 2. Tensor
本系列文章会优先发布于微信公众号和知乎专栏,欢迎大家关注
微信公众号:小飞怪兽屋
知乎: PyTorch源码学习 - 知乎 (zhihu.com)
目录
前言
Tensor是什么?
Tensor如何存储?
PyTorch眼中的Tensor
Tensor的创建过程
Tensor的函数与方法
前言
如果有人问我刚开始接触PyTorch该从何处学起时,我的回答一定不会是举世瞩目,让人惊叹不已的神经网络(NN, Neural Network),也不会是不明觉厉,精巧设计的梯度自动求导系统(Autograd),反而恰恰是平淡无奇,却无处不在的张量(Tensor)。正如所有人学习编程所做的第一件事情就是在控制台输出“Hello World”一样,Tensor就是PyTorch的“Hello World” ,每一位初学者在接触PyTorch时所做的第一件事就是用torch.tensor函数创建一个属于自己的Tensor。
import torch
torch.tensor([1,2,3])当我们写下上面这段代码的时候,我们就已经开始走进PyTorch的宏观世界,我们利用PyTorch提供的函数创建了一个Tensor对象。但是,不知你们是否曾好奇过Tensor是如何创建的,是否曾想过Tesnor是如何存储的,是否曾探究过Tensor是如何设计的 ?今天,就让我们深入研究上面这段代码,一起走入Tensor的微观世界。
Tensor是什么?
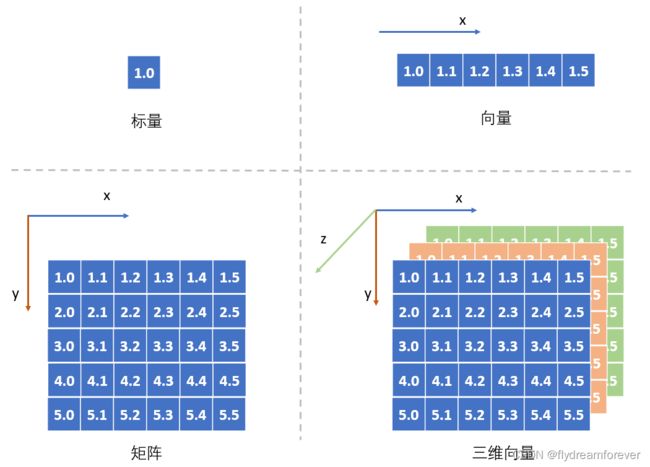
在深入研究之前让我们先来简单回顾下Tensor是什么?从数学角度上来说,Tensor本质上是一个多维向量。在数学里,一个数我们称之为标量,一维数据我们称之为向量,二维数据我们称之为矩阵,到三维及更高维度的时候,我们并没有为每一个维度数据都提供一个专有名称,我们将这些包含维度信息的数据统称为张量(Tensor)。
 Tensor
Tensor
从图上可以看出,标量就是0维的Tensor,向量是1维的Tesnor,矩阵是二维的Tensor。在介绍Tensor的时候我们引入一个叫做维度的抽象概念,维度本质上是衡量事物的一种方式。比如时间就是一种维度,假如我们在网上卖东西,每天晚上都要汇总今天的销售额,我们就可以得到销售额相对于时间的关系,这里销售额就是基于时间的一维Tensor。当我们觉得销售额不仅仅和时间有关系,可能还和当天的客户访问量有关系,我们就又引入了一种维度,可以得到销售额与(时间,访问量)之间的关系,我们就建立一个二维的Tensor。Tensor就是用来表示这种多维数据的一种抽象概念,在不同的场景下具有不同的物理含义。在空间上,它是表示长宽高的三维tensor;在RGB颜色上,它是表示红绿蓝的三维Tensor;在语音通话中,它是表示时间与语音信息的二维Tensor。
Tensor如何存储?
当我们了解了Tensor的概念后,那该如何在计算机中存储包含多维信息的Tensor呢?当程序在计算机中运行时,我们需要将程序代码,程序运行需要的数据以及程序运行过程中生成的数据加载到内存中,所以我们可以得出一个结论,存储Tensor的物理媒介是内存(GPU上是显存),内存是一块可供寻址的存储单元。在我们设计Tensor的存储方案时,我们需要先弄清Tensor的特性:
- Tensor需要支持随机访问。这很重要,因为在Python中Tensor是支持索引(index)和切片(slice)操作的,支持随机访问可以让我们快速的找到需要的数据,提高我们数据访问效率
- Tensor的大小是固定的。当我们创建了一个Tensor的时候,它的大小就已经确定了,我们可以修改其上的任意元素,就是不能增加元素来修改它的大小。如果要修改其大小,我们必须根据其大小创建一个新的Tensor,将旧的Tensor上的数据复制过去
说到这里大家是不是觉得很熟悉?没错,就是在数据结构课上学到的第一个数据结构,数组。当我们创建一个数组的时候,我们会向内存申请一块指定大小的连续存储空间,而这恰恰就是PyTorch中Strided Tensor的存储方式。
 Tensor逻辑表示与物理存储的映射关系
Tensor逻辑表示与物理存储的映射关系
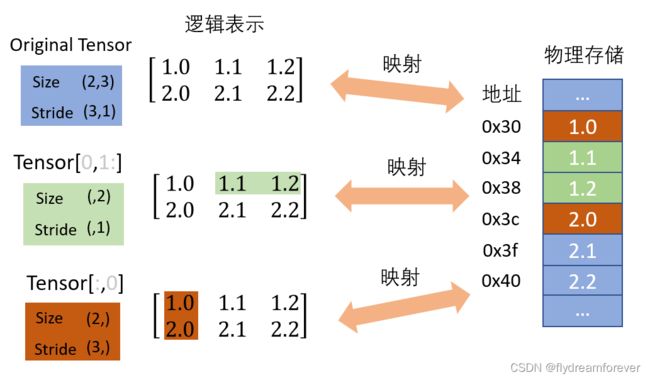
PyTorch引入了一个叫做步伐(Stride)的概念,其本质上是逻辑索引的一个相对距离,表明当你从某个元素沿着某一维度移动一个元素时的距离。图中是一个二维矩阵,所以其Stride是个size为2的一维向量。当我们从左往右移动的时候(1.0 -> 1.1),由于这两个数在内存中紧挨着,所以我们只移动了一次,Stride在这一维度的值是1;当我们从上往下移动的时候(1.0 -> 2.0),在内存中这两个数之间隔着2个数,所以我们移动了3次,Stride在这一维度的值是3。最终对于这个Tensor来说,它的Stride是(3,1)。
 Tensor元素索引
Tensor元素索引
当我们有了Stride后就可以快速的计算出一个元素的物理地址。熟悉C/C++的朋友会发现这其实和C/C++里的多级指针寻址方式非常类似。当我们在Tensor中查找索引是[1,1]的数时,我们通过计算索引和Stride的点积就可以得到逻辑表示的相对位置。而此元数的物理地址就是Tensor的第一个元素地址加上逻辑相对位置与字节数的乘积。最终我们计算出Tensor [1,1] 的物理地址是0x3f, 值是2.1。当然Stride在PyTorch里不仅仅是用来为某一个特定元素寻址。
 Tensor视图
Tensor视图
前面也说了Tensor是支持Python的切片操作,所以我们经常会有个需求是查看当前Tensor里的部分元素,当我们使用切片操作时就会获得一个新的Tensor。如果我们为每个切片操作都开辟一个新的内存空间,那势必会降低程序的运行效率以及造成内存空间浪费,所以PyTorch引入了一个叫做视图的概念,所有的视图都会共享相同的内存空间,而Stride就是创建新Tesnor视图的关键所在。当我们想要访问Tensor[0,1:] 时,我们创建了一个包含2个元素的一维Tensor视图,这两个元数在内存中是相邻的,所以其Stride是1。但当我们想要访问Tensor[:, 0] 时,我们虽然也创建了一个包含2个元素的一维Tensor,但是这两个数在内存中却相隔2个元素,所以其Stride是3. 正是由于Stride的存在,PyTorch才可以便捷地使所有Tensor视图共享一块内存空间。那PyTorch是怎么做到这些的呢?
PyTorch眼中的Tensor
在我们用户眼中,Tensor就是一个Python类,但是在PyTorch的眼中,事实却绝不仅仅如此简单。
 Tensor 类关系
Tensor 类关系
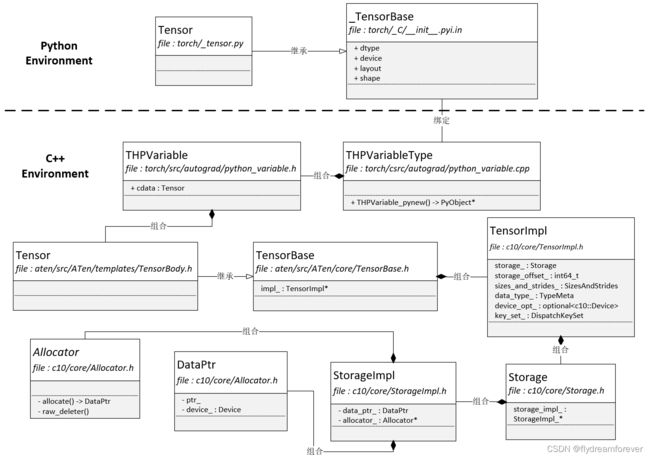
PyTorch将Tensor的物理存储抽象成一个Storage类,与逻辑表示类Tensor解耦,这样我们就可以建立Tensor视图和物理存储Storage之间多对一的联系。Storage是一个声明类,其具体实现在其实现类StorageImpl中。StorageImp中有两个核心的成员:
- data_ptr。其指向数据实际存储的内存空间。在类DataPtr中包含了Device相关的成员变量
- allocator_。其是一个内存分配器。Allocator是一个抽象类,所有派生类必须实现allocate和raw_deleter两个抽象函数
PyTorch的Tensor除了用Storage类来管理物理存储外,还在Tensor中定义了很多相关的元信息。比如我们前面说到的size,stride以及dtye,这些信息都存在TensorImpl类中的sizes_and_strides_以及data_type_中。key_set_中保存的是PyTorch对Tensor的layout,device以及dtype相关的调度信息。我们在前一篇文章中的架构图里还介绍过PyTorch在C++实现层中实现了算子(Operator),那Operator是如何和Tensor绑定的了?其实PyTorch创建了一个TensorBody.h的模板文件,在该文件中创建了一个继承基类TesnorBase的类Tensor。TensorBase基类中封装了所有和Tensor存储相关的细节,在类Tensor中,PyTorch使用代码自动生成工具将aten/src/ATen/native/native_functions.yaml 中声明的函数替换此处的宏${tensor_method_declarations}
class TORCH_API Tensor: public TensorBase {
...
public:
${tensor_method_declarations}
...
}
当我们了解了C++实现层中的Tensor后,让我们来看看Python中的Tensor是如何与C++中的Tensor绑定的。Python中的Tensor继承于基类_TensorBase,该类并不是用Python语言定义的,其是用Python C API绑定的一个C++类
bool THPVariable_initModule(PyObject* module) {
...
static std::vector methods;
THPUtils_addPyMethodDefs(methods, torch::autograd::variable_methods);
THPUtils_addPyMethodDefs(methods, extra_methods);
THPVariableType.tp_methods = methods.data();
if (PyType_Ready(&THPVariableType) < 0)
return false;
Py_INCREF(&THPVariableType);
PyModule_AddObject(module, "_TensorBase", (PyObject*)&THPVariableType);
torch::autograd::initTorchFunctions(module);
torch::autograd::initTensorImplConversion(module);
return true;
}
从代码中可以看到Python中的_TensorBase类就是C++中的THPVariableType对象。THPVariable_initModule函数除了声明一个_TensorBase python类之外,还通过 torch::autograd::initTorchFunctions(module) 函数声明了Python Tensor相关的函数,我们常用的 torch.tensor 函数就是在此函数中声明。THPVariableType对象的类型是类PyTypeObject,该类由Python C API 提供,不熟悉的朋友可以自己网上找下相关资料了解下,这里就不详细展开。
PyTypeObject THPVariableType = {
PyVarObject_HEAD_INIT(
&THPVariableMetaType,
0) "torch._C._TensorBase", /* tp_name */
sizeof(THPVariable), /* tp_basicsize */
...
THPVariable_properties, /* tp_getset */
...
THPVariable_pynew, /* tp_new */
};
这里主要需要了解的就是THPVariable_properties 和THPVariable_pynew 两个函数。THPVariable_properties主要声明Python Tensor中的属性,如detype,device,layout,shape。THPVariable_pynew 就是Python Tensor通过new语法创建对象时候调用的函数,可以理解为类的构造函数。下面的python代码就会调用该函数
torch.Tensor([1,2,3])直接通过torch.Tensor创建Python Tensor对象与直接用torch.tensor创建Python Tensor对象是等效的。唯一的区别是前者调用的是类自身的new方法,而后者是用函数(在python中类里的函数称之为方法,类外的函数称之为函数,与C++习惯不同)去创建一个Python Tensor。
Tensor的创建过程
现在我们终于可以来看看当我们用torch.tensor去创建Python Tensor的时候,PyTorch到底做了什么。
import torch
torch.tensor([1,2,3])torch.Tensor 会调用C++的THPVariable_tensor 函数,该函数在文件 torch/csrc/autograd/python_torch_functions_manual.cpp 中。在经过一系列的参数检测之后,在函数结束之前调用了torch::utils::tensor_ctor 函数。
// implemented on python object to allow torch.tensor to be constructed with
// arbitrarily nested python objects - list, tuple, np array, scalar, etc.
static PyObject* THPVariable_tensor(
PyObject* self,
PyObject* args,
PyObject* kwargs)
HANDLE_TH_ERRORS
...
return THPVariable_Wrap(torch::utils::tensor_ctor(
torch::tensors::get_default_dispatch_key(),
torch::tensors::get_default_scalar_type(),
r));
END_HANDLE_TH_ERRORS
}
torch::utils::tensor_ctor 在文件torch/csrc/utils/tensor_new.cpp 中,该文件包含了创建Tensor的一些工具函数。在该函数中调用了internal_new_from_data 函数创建Tensor。
Tensor tensor_ctor(
c10::DispatchKey dispatch_key,
at::ScalarType scalar_type,
PythonArgs& r) {
...
auto new_tensor = internal_new_from_data(
typeIdWithDefault(r, 2, dispatch_key),
r.scalartypeWithDefault(1, scalar_type),
r.deviceOptional(2),
data,
/*copy_variables=*/true,
/*copy_numpy=*/true,
/*type_inference=*/type_inference,
pin_memory);
...
return new_tensor;
}
在internal_new_from_data 函数中有3个比较重要的函数
- empty。该函数主要根据参数的大小来为Tensor在CPU内存上申请一块空间用来后面存储元素。
- recursive_store。一个递归函数用来遍历传进来的每个元素并将其保存到对应位置
- to。根据设备参数来决定Tensor放到哪个设备中
Tensor internal_new_from_data(
c10::TensorOptions options,
at::ScalarType scalar_type,
c10::optional device_opt,
PyObject* data,
bool copy_variables,
bool copy_numpy,
bool type_inference,
bool pin_memory = false) {
...
Tensor tensor;
{
...
tensor = at::empty(sizes, opts.pinned_memory(pin_memory));
if (c10::multiply_integers(tensor.sizes()) != 0) {
recursive_store(
(char*)tensor.data_ptr(),
tensor.sizes(),
tensor.strides(),
0,
inferred_scalar_type,
tensor.dtype().itemsize(),
data);
}
tensor = tensor.to(
device, inferred_scalar_type, /*non_blocking=*/false, /*copy=*/false);
...
return at::lift_fresh(tensor);
}
最后我们来看看recursive_store 这个函数。该函数的核心就在于
- 递归函数的退出条件。当我们递归到最后一维元素的时候,用store_scalar函数来将元素放到对应的空间上
- 递归函数循环体。这个函数本质上是一个深度优先遍历算法。
void recursive_store(
char* data,
IntArrayRef sizes,
IntArrayRef strides,
int64_t dim,
ScalarType scalarType,
int elementSize,
PyObject* obj) {
int64_t ndim = sizes.size();
if (dim == ndim) {
torch::utils::store_scalar(data, scalarType, obj);
return;
}
auto n = sizes[dim];
auto seq = THPObjectPtr(PySequence_Fast(obj, "not a sequence"));
...
PyObject** items = PySequence_Fast_ITEMS(seq.get());
for (const auto i : c10::irange(n)) {
recursive_store(
data, sizes, strides, dim + 1, scalarType, elementSize, items[i]);
data += strides[dim] * elementSize;
}
}Tensor的函数与方法
Tensor创建之后我们就需要通过函数或方法来对Tensor进行操作。前面也说到在Python中,类外的函数称之为函数,类内的函数称之为方法。我们通过THPVariable_initModule 函数来将Tensor相关的类和函数与Python对象联系起来。从下面code可以看出,Tensor的方法主要是通过torch::autograd::variable_methods 和extra_methods 两个对象来初始化的。
bool THPVariable_initModule(PyObject* module) {
...
static std::vector methods;
THPUtils_addPyMethodDefs(methods, torch::autograd::variable_methods);
THPUtils_addPyMethodDefs(methods, extra_methods);
THPVariableType.tp_methods = methods.data();
if (PyType_Ready(&THPVariableType) < 0)
return false;
Py_INCREF(&THPVariableType);
PyModule_AddObject(module, "_TensorBase", (PyObject*)&THPVariableType);
torch::autograd::initTorchFunctions(module);
torch::autograd::initTensorImplConversion(module);
return true;
}
而Tensor的函数则是通过函数initTorchFunctions 来初始化。在initTorchFunctions 中我们调用gatherTorchFunctions 来初始化函数,其里面主要分两种函数
- torch_functions_manual 数组。这个数组在代码中手动加入了一些函数的声明,我们前面一直讨论的torch.tensor 函数就是在这里注册的。
- gatherTorchFunctions_n 函数。这是利用PyTorch的代码自动生成脚本生成的函数,脚本会根据模板文件将aten/src/ATen/native/native_functions.yaml 中声明的函数生成到对应的函数中。
// File: torch/csrc/autograd/python_torch_functions_manual.cpp
void initTorchFunctions(PyObject* module) {
static std::vector torch_functions;
gatherTorchFunctions(torch_functions);
THPVariableFunctions.tp_methods = torch_functions.data();
...
}
void gatherTorchFunctions(std::vector& torch_functions) {
constexpr size_t num_functions =
sizeof(torch_functions_manual) / sizeof(torch_functions_manual[0]);
torch_functions.assign(
torch_functions_manual, torch_functions_manual + num_functions);
// NOTE: Must be synced with num_shards in
// tools/autograd/gen_python_functions.py
gatherTorchFunctions_0(torch_functions);
gatherTorchFunctions_1(torch_functions);
gatherTorchFunctions_2(torch_functions);
...
}