论文笔记系列:轻量级网络(一)-- RepVGG
✨写在前面:强烈推荐给大家一个优秀的人工智能学习网站,内容包括人工智能基础、机器学习、深度学习神经网络等,详细介绍各部分概念及实战教程,通俗易懂,非常适合人工智能领域初学者及研究者学习。➡️点击跳转到网站。
RepVGG笔记
论文名称:RepVGG: Making VGG-style ConvNets Great Again
论文下载地址:https://arxiv.org/abs/2101.03697
参考代码:GitHub - DingXiaoH/RepVGG: RepVGG: Making VGG-style ConvNets Great Again
RepVGG概念介绍
- RepVGG是一种简单的VGG式结构,大量使用3x3卷积,BN层,Relu激活函数,利用重参数化提升性能,准确率直逼其他SOTA网络,特点是训练时使用多分支网络,推理时融合多分支为单分支。主要解决原始VGG网络模型较大,不便于部署及性能较差提出VGG升级版本。
- 论文提出一种简单高效的卷积神经网络,该模型的推理结构类似于V G G {\rm VGG}VGG,训练模型使用多分支结构。通过结构再参数化技术实现训练结构和推理结构的解耦,得到模型RepVGG。
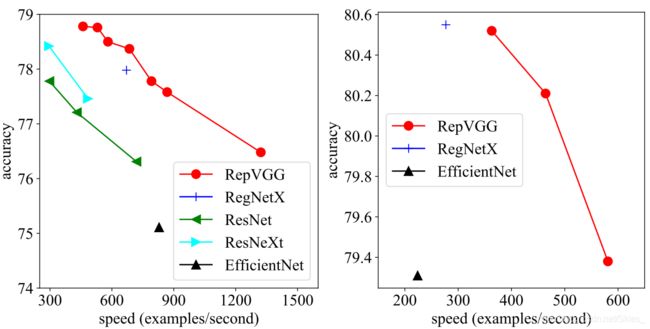
RepVGG主要思路
(1)在VGG网络Block块中加入Identity和残差分支,相当于ResNet网络精华应用到VGG网络中;
(2)模型推理阶段,通过Op融合策略将所有的网络层都转换为Conv3*3,便于网络部署和加速。
RepVGG模型
1.主要架构
RepVGG模型的整体结构:将20多层3x3卷积堆起来,分成5个stage,每个stage的第一层是stride=2的降采样,每个卷积层用ReLU作为激活函数。
RepVGG模型的详细结构:RepVGG-A的5个stage分别有[1, 2, 4, 14, 1]层,RepVGG-B的5个stage分别有[1, 4, 6, 16, 1]层,宽度是[64,128, 256, 512]的若干倍。
2.RepVGG Block构造
训练时,为每一个3x3卷积层添加平行的1x1卷积分支和恒等映射分支,构成一个RepVGG Block。借鉴ResNet的做法,区别在于ResNet是每隔两层或三层加一分支,RepVGG Block是每层都加。
部署时,我们将1x1卷积分支和恒等映射分支以及3x3卷积融合成一个3x3卷积达到单路结构的目的。

2.3 RepVGG特点
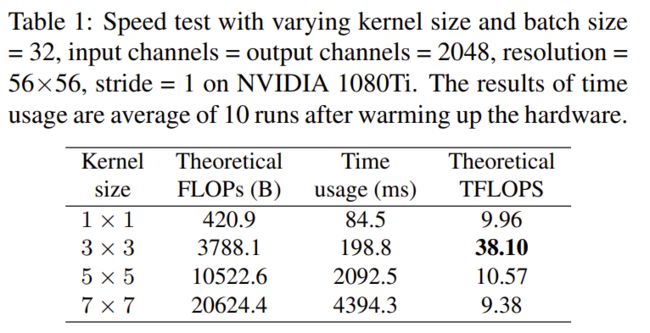
2.3.1更快的速度
现有的计算库(如CuDNN,Intel MKL)和硬件针对3x3卷积有深度的优化,相比其他卷积核,3x3卷积计算密度更高,更加有效。
2.3.2更节省内存
以残差块结构为例子,它有2个分支,其中主分支经过卷积层,假设前后张量维度相同,我们认为是一份显存消耗,另外一个旁路分支需要保存初始的输入结果,同样也是一份显存消耗,这样在运行的时候是占用了两份显存,直到最后一步将两个分支结果Add,显存才恢复成一份。而Plain结构只有一个主分支,所以其显存占用一直是一份。RepVGG主体部分只有一种算子:3x3卷积接ReLU。在设计专用芯片时,给定芯片尺寸或造价,我们可以集成海量的3x3卷积-ReLU计算单元来达到很高的效率。单路架构省内存的特性也可以帮我们少做存储单元.

2.3.3更加灵活
多分支结构会引入网络结构的约束,比如Resnet的残差结构要求输入和卷积出来的张量维度要一致(这样才能相加),这种约束导致网络不易延伸拓展,也一定程度限制了通道剪枝。对应的单路结构就比较友好,剪枝后也能得到很好的加速比。
方法论:多分支融合
3x3卷积和1x1卷积融合
假设输入是5x5,stride=1
1x1卷积前后特征图大小不变
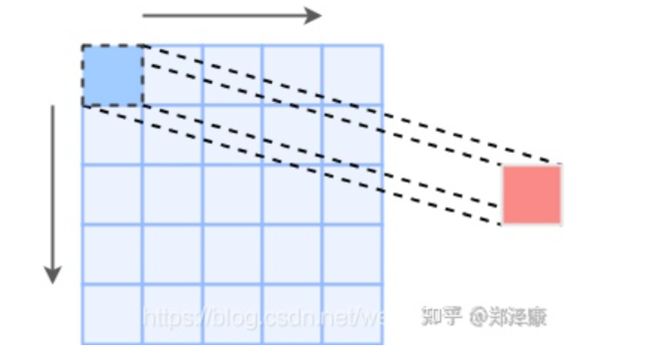
3x3卷积在原特征图补零,卷积前后特征图大小不变

将1x1卷积核加在3x3卷积核中间,就能完成卷积分支融合
融合示例图如下:

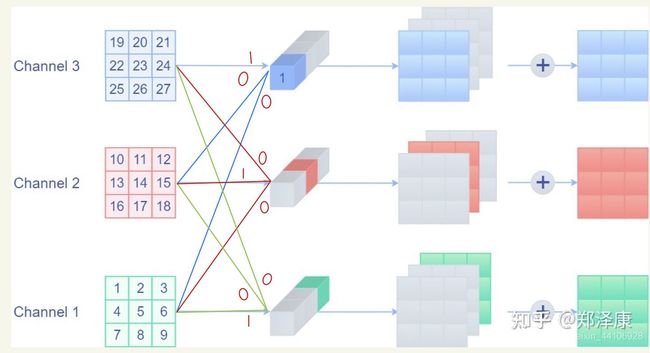
identity分支等效特殊权重卷积层
我们试想一下,输入与输出要相等,假设输入输出都是三通道
即每一个卷积核的通道数量,必须要求与输入通道数量一致,因为要对每一个通道的像素值要进行卷积运算,所以每一个卷积核的通道数量必须要与输入通道数量保持一致。
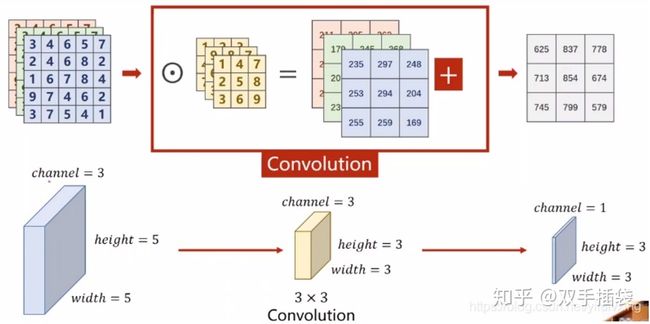
那么要保持原有三通道数据各权重应该如何初始化呢?
一个卷积核的尺寸为3x3x3,将对应通道的权重设为1其他为零,就能完好的保证输出原有值。
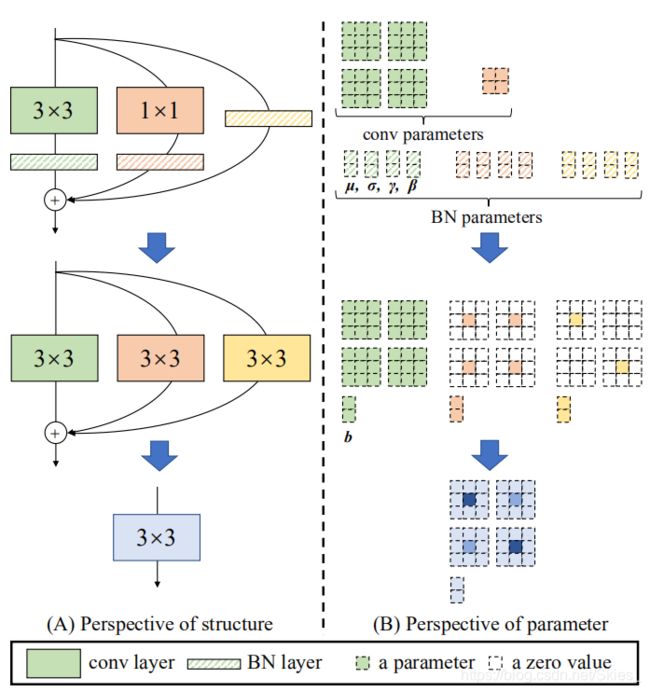
卷积+BN融合
在将identity分支和1x1卷积融合到3x3卷积后,我们将BN层融到卷积中去
Batch-Normalization (BN)是一种让神经网络训练更快、更稳定的方法(faster and more stable)。它计算每个mini-batch的均值和方差,并将其拉回到均值为0方差为1的标准正态分布。BN层通常在nonlinear function的前面/后面使用。
RepVGG的再参数化:

经过上述转换,我们可以得到一个3×3卷积,两个1 × 1 卷积和三个表示偏置的向量。然后,将三个偏置向量相加得到最后的偏置参数,然后使用零填充将1 × 1 卷积填充为3 × 3 大小,最后将所有3 × 3 大小的卷积相加,得到最后的卷积参数。
Architectural Specification

上图中的a和b 表示通道的缩放系数。
实验部分
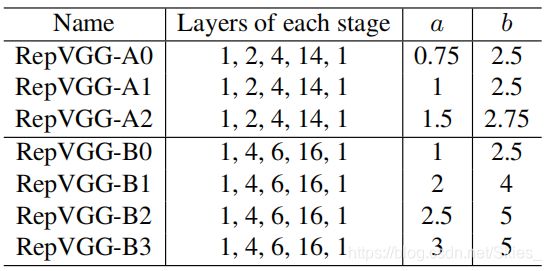
基于不同a和b得到的RepVGG.
RepVGG for ImageNet Classification

Structural Re-parameterization is the Key

Ablation Studies

Comparison with variants and baselines

PyTorch实现RepVGG
RepVGG模块构建:
class RepVGGBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', deploy=False):
super(RepVGGBlock, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
assert kernel_size == 3
assert padding == 1
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
# 根据deploy决定构建训练模型还是推理模型
if deploy:
# 推理时仅有一个3x3卷积
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=True, padding_mode=padding_mode)
else:
# 训练时包含一个恒等连接、一个3x3卷积核一个1x1卷积
self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups)
print('RepVGG Block, identity = ', self.rbr_identity)
def forward(self, inputs):
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.rbr_reparam(inputs))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
# 核和偏置的转换,具体实现在_fuse_bn_tensor函数
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
# 核和偏置合并
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1,1,1,1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
# 卷积层权重
kernel = branch.conv.weight
# μ
running_mean = branch.bn.running_mean
# σ
running_var = branch.bn.running_var
# BN层权重
gamma = branch.bn.weight
# BN层偏置
beta = branch.bn.bias
# BN层防止除零的参数
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
# 式(3),返回 W'和 b'
return kernel * t, beta - running_mean * gamma / std
def repvgg_convert(self):
kernel, bias = self.get_equivalent_kernel_bias()
return kernel.detach().cpu().numpy(), bias.detach().cpu().numpy(),
RepVGG主体部分构建:
class RepVGG(nn.Module):
def __init__(self, num_blocks, num_classes=1000, width_multiplier=None, override_groups_map=None, deploy=False):
super(RepVGG, self).__init__()
assert len(width_multiplier) == 4
self.deploy = deploy
self.override_groups_map = override_groups_map or dict()
assert 0 not in self.override_groups_map
self.in_planes = min(64, int(64 * width_multiplier[0]))
# 构建RepVGG的各阶段
self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1, deploy=self.deploy)
self.cur_layer_idx = 1
self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
self.gap = nn.AdaptiveAvgPool2d(output_size=1)
# 用于分类的全连接层
self.linear = nn.Linear(int(512 * width_multiplier[3]), num_classes)
def _make_stage(self, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
blocks = []
for stride in strides:
cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)
blocks.append(RepVGGBlock(in_channels=self.in_planes, out_channels=planes, kernel_size=3,
stride=stride, padding=1, groups=cur_groups, deploy=self.deploy))
self.in_planes = planes
self.cur_layer_idx += 1
return nn.Sequential(*blocks)
def forward(self, x):
out = self.stage0(x)
out = self.stage1(out)
out = self.stage2(out)
out = self.stage3(out)
out = self.stage4(out)
out = self.gap(out)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
RepVGG构建用于分类和分割等任务的模型,并返回推理模型:
def whole_model_convert(train_model:torch.nn.Module, deploy_model:torch.nn.Module, save_path=None):
all_weights = {}
for name, module in train_model.named_modules():
# 条件语句判断不同形式的层
if hasattr(module, 'repvgg_convert'):
# 获得转换后的卷积层权重和偏置
kernel, bias = module.repvgg_convert()
# 加载权重
all_weights[name + '.rbr_reparam.weight'] = kernel
all_weights[name + '.rbr_reparam.bias'] = bias
print('convert RepVGG block')
else:
for p_name, p_tensor in module.named_parameters():
full_name = name + '.' + p_name
if full_name not in all_weights:
all_weights[full_name] = p_tensor.detach().cpu().numpy()
for p_name, p_tensor in module.named_buffers():
full_name = name + '.' + p_name
if full_name not in all_weights:
all_weights[full_name] = p_tensor.cpu().numpy()
# 加载权重
deploy_model.load_state_dict(all_weights)
if save_path is not None:
torch.save(deploy_model.state_dict(), save_path)
return deploy_model
调用
# 1. 构建基于RepVGG的任务模型,如这里构建PSPNet
# 调用流程如下:
###################### 1 ######################
train_backbone = create_RepVGG_B2(deploy=False)
train_backbone.load_state_dict(torch.load('RepVGG-B2-train.pth'))
train_pspnet = build_pspnet(backbone=train_backbone)
segmentation_train(train_pspnet)
###################### 2 ######################
# 2. 构建PSPNet的推理模型
deploy_backbone = create_RepVGG_B2(deploy=True)
deploy_pspnet = build_pspnet(backbone=deploy_backbone)
whole_model_convert(train_pspnet, deploy_pspnet)
segmentation_test(deploy_pspnet)
RepVGG转换成推理模型:
def repvgg_model_convert(model:torch.nn.Module, build_func, save_path=None):
converted_weights = {}
for name, module in model.named_modules():
if hasattr(module, 'repvgg_convert'):
kernel, bias = module.repvgg_convert()
converted_weights[name + '.rbr_reparam.weight'] = kernel
converted_weights[name + '.rbr_reparam.bias'] = bias
elif isinstance(module, torch.nn.Linear):
converted_weights[name + '.weight'] = module.weight.detach().cpu().numpy()
converted_weights[name + '.bias'] = module.bias.detach().cpu().numpy()
del model
deploy_model = build_func(deploy=True)
for name, param in deploy_model.named_parameters():
print('deploy param: ', name, param.size(), np.mean(converted_weights[name]))
param.data = torch.from_numpy(converted_weights[name]).float()
if save_path is not None:
torch.save(deploy_model.state_dict(), save_path)
return deploy_model
调用
# 构建模型
train_model = create_RepVGG_A0(deploy=False)
# 训练模型
train train_model
# 转换模型
deploy_model = repvgg_convert(train_model, create_RepVGG_A0, save_path='repvgg_deploy.pth')
参考文章与资料推荐:
RepVGG网络简介(强推)
论文阅读 | 轻量级网络之RepVGG_zhangts20的博客
图解RepVGG - 知乎 (zhihu.com)
RepVGG 论文详解 - 知乎 (zhihu.com)
RepVGG:极简架构,SOTA性能,让VGG式模型再次伟大(CVPR-2021)