统计篇(一)-- 概率论、随机过程、信息论知识汇总
1 概率与分布
1.1 基本概念
统计学研究的一个主要问题是通过试验推断总体。而概率论为整个统计学奠定了基础,它为总体、随机试验等几乎所有随机现象的建模提供了方法。
(一)样本与事件
称某次试验全体可能的结果所构成的集合S 为该试验的 样本空间(sample space)。
一个事件(event)是一次试验若干可能的结果所构成的集合,即 S 的一个子集(可以是S本身)。
(二)事件的运算
设试验 E 的样本空间为 S ,而 A, B, A k A_k Ak(k= l,2,…)是S的子集。
- 若 A ⊂ B A \subset B A⊂B,则称事件B包含事件A,即事件A发生必导致事件B 发生。若 A ⊂ B A \subset B A⊂B且 B ⊂ A B \subset A B⊂A,即A=B,则称事件A与事件B相等。
- 事件 A ∪ B = { x ∣ x ∈ A 或 x ∈ B } A \cup B= \{x|x \in A 或 x \in B\} A∪B={x∣x∈A或x∈B}称为事件A与事件B的和事件。当且仅当A,B中至少有一个发生时,事件 A ∪ B A \cup B A∪B发生。类似地,称 ⋃ i = 1 n A i \bigcup_{i=1}^{n} {A_i} ⋃i=1nAi 为 n 个事件 A 1 , A 2 , ⋯ , A n A_1, A_2, \cdots, A_n A1,A2,⋯,An 的和事件;称 ⋃ i = 1 ∞ A i \bigcup_{i=1}^{\infty} {A_i} ⋃i=1∞Ai 为可列个事件 A 1 , A 2 , ⋯ A_1, A_2, \cdots A1,A2,⋯ 的和事件。
- 事件 A ∩ B = { x ∣ x ∈ A 且 x ∈ B } A \cap B = \{x|x \in A 且 x \in B\} A∩B={x∣x∈A且x∈B}称为事件A与事件B的积事件。当且仅当A,B同时发生时,事件 A ∩ B A \cap B A∩B发生。 A ∩ B A \cap B A∩B也记作AB。类似地,称 ⋂ i = 1 n A i \bigcap_{i=1}^{n} {A_i} ⋂i=1nAi 为 n 个事件 A 1 , A 2 , ⋯ , A n A_1, A_2, \cdots, A_n A1,A2,⋯,An 的积事件;称 ⋂ i = 1 ∞ A i \bigcap_{i=1}^{\infty} {A_i} ⋂i=1∞Ai 为可列个事件 A 1 , A 2 , ⋯ A_1,A_2,\cdots A1,A2,⋯ 的积事件。
- 事件 A − B = { x ∣ x ∈ A 且 x ∉ B } A-B = \{x|x \in A 且 x \notin B\} A−B={x∣x∈A且x∈/B} 称为事件A与事件B的差事件。当且仅当 A 发生、B不发生时事件 A-B 发生。
- 若 A ∩ B = ∅ A \cap B = \emptyset A∩B=∅,则称事件 A 与 B 是互不相容的,或互斥的。这指的是事件A 与事件 B 不能同时发生。基本事件是两两互不相容的。
- 若 A ∪ B = S 且 A ∩ B = ∅ A \cup B = S且A \cap B = \emptyset A∪B=S且A∩B=∅ , 则称事件 A 与事件 B 互为逆事件。又称事件 A 与事件 B 互为对立事件。这指的是对每次试验而言,事件 A、B 中必有一个发生,且仅有一个发生。A 的对立事件记为 A C A^C AC,有些教材记为 A ˉ \bar A Aˉ。 A C = S − A A^C=S-A AC=S−A
补充:
如果事件 A 1 , A 2 , ⋯ A_1, A_2, \cdots A1,A2,⋯ 两两不交,并且 ⋂ i = 1 ∞ A i = S \bigcap_{i=1}^{\infty} {A_i}=S ⋂i=1∞Ai=S,则称 A 1 , A 2 , ⋯ A_1, A_2, \cdots A1,A2,⋯ 构成 S 的一个划分(partition)。
(三)定理
对于样本空间 S 上的任意事件 A, B 和 C,有:
- 交换律: A ∪ B = B ∪ A , A ∩ B = B ∩ A A \cup B = B \cup A ,A \cap B = B \cap A A∪B=B∪A,A∩B=B∩A
- 结合律: A ∪ ( B ∪ C ) = ( A ∪ B ) ∪ C , A ∩ ( B ∩ C ) = ( A ∩ B ) ∩ C A \cup (B \cup C) = (A \cup B) \cup C,A \cap (B \cap C) = (A \cap B) \cap C A∪(B∪C)=(A∪B)∪C,A∩(B∩C)=(A∩B)∩C
- 分配律: A ∩ ( B ∪ C ) = ( A ∩ B ) ∪ ( A ∩ C ) , A ∪ ( B ∩ C ) = ( A ∪ B ) ∩ ( A ∪ C ) A \cap (B \cup C) = (A \cap B)\cup (A \cap C) ,A \cup (B \cap C) = (A\cup B) \cap (A \cup C) A∩(B∪C)=(A∩B)∪(A∩C),A∪(B∩C)=(A∪B)∩(A∪C)
- DeMorgan律: ( A ∪ B ) C = A C ∩ B C , ( A ∩ B ) C = A C ∪ B C (A \cup B)^C = A^C \cap B^C, (A \cap B)^C = A^C \cup B^C (A∪B)C=AC∩BC,(A∩B)C=AC∪BC
(四)概率函数
S 的一族子集如果满足下列三个性质,就称作一个 σ \sigma σ 代数(sigma algebra)或一个 Borel 域(Borel field),记作 B \Beta B。
- ∅ ∈ B \emptyset \in B ∅∈B(空集属于 B \Beta B)。
- 若 A ∈ B A \in B A∈B,则 A C ∈ B A^C \in B AC∈B( B \Beta B 在补运算下封闭)。
- 若 A 1 , A 2 , ⋯ ∈ B A_1, A_2, \cdots \in B A1,A2,⋯∈B,则 ⋃ i = 1 ∞ A i ∈ B \bigcup_{i=1}^{\infty} {A_i} \in B ⋃i=1∞Ai∈B
例子:如果样本空间 S 有限或者可数,则我们可以直接对 S 定义: B = { S 的全体子集,包括 S 本身 } B = \{ S 的全体子集,包括 S 本身\} B={S的全体子集,包括S本身};若 S = ( − ∞ , ∞ ) S = (-\infty,\infty) S=(−∞,∞)为实数轴。令 B \Beta B 包含全体形如 [ a , b ] , ( a , b ] , ( a , b ) 和 [ a , b ) [a, b], (a, b], (a, b)和[a, b) [a,b],(a,b],(a,b)和[a,b)的集合,其中 a, b 为任意实数。
已知样本空间 S 和 σ \sigma σ 代数 B \Beta B,定义在 B \Beta B上且满足下列条件的函数 P 称为一个概率函数(probability function):
- 对任意 A ∈ B A \in \Beta A∈B, P ( A ) ≥ 0 P(A) \geq 0 P(A)≥0。
- P ( S ) = 1 P(S) = 1 P(S)=1。
- 若 A 1 , A 2 , ⋯ ∈ B A_1,A_2,\cdots \in B A1,A2,⋯∈B 且两两不交,则 P ( ⋃ i = 1 ∞ A i ) = ∑ i = 1 ∞ P ( A i ) P(\bigcup_{i=1}^{\infty} {A_i}) = \sum_{i=1}^{\infty}P(A_i) P(⋃i=1∞Ai)=∑i=1∞P(Ai)。
上面三条性质通常称作概率公理(或 Kolmogorov(柯尔莫哥洛夫)公理——以概率论创始人之一 A. Kolmogorov 的名字命名,大家会在很多学科遇到这位大牛)。任何满足概率公理的函数 P 都称作概率函数。
有限可加性公理: 若 A , B ∈ B A, B \in \Beta A,B∈B 且两者不交,则 P ( A ∪ B ) = P ( A ) + P ( B ) P(A \cup B) = P(A) + P(B) P(A∪B)=P(A)+P(B)。
(五)概率演算
设 P 是一个概率函数, A , B ∈ B A, B \in \Beta A,B∈B,则
- P ( ∅ ) = 0 P(\emptyset) = 0 P(∅)=0;
- P ( A ) ≤ 1 P(A) \leq 1 P(A)≤1;
- P ( A C ) = 1 − P ( A ) P(A^C) = 1 - P(A) P(AC)=1−P(A);
- P ( B ∩ A C ) = P ( B ) − P ( A ∩ B ) P(B \cap A^C) = P(B) - P(A \cap B) P(B∩AC)=P(B)−P(A∩B);
- P ( A ∪ B ) = P ( A ) + P ( B ) − P ( A ∩ B ) P(A \cup B) = P(A) +P(B) - P(A \cap B) P(A∪B)=P(A)+P(B)−P(A∩B);
- 若 A ⊂ B A \subset B A⊂B,则 P ( A ) ≤ P ( B ) P(A) \leq P(B) P(A)≤P(B);、
- 对任意划分 C 1 , C 2 , ⋯ C_1, C_2, \cdots C1,C2,⋯,都有 P ( A ) = ∑ i = 1 ∞ P ( A ∩ C i ) P(A) = \sum_{i=1}^{\infty}P(A\cap C_i) P(A)=∑i=1∞P(A∩Ci)
- 对于任意集合 A 1 , A 2 , ⋯ A_1, A_2, \cdots A1,A2,⋯,都有 P ( ∪ i = 1 ∞ A i ) ≤ ∑ i = 1 ∞ P ( A i ) P(\cup_{i=1}^{\infty}A_i)\leq \sum_{i=1}^{\infty}P(A_i) P(∪i=1∞Ai)≤∑i=1∞P(Ai)
1.2 条件概率与独立事件
-
条件概率:已知 A A A 事件发生的条件下 B B B 发生的概率,记作 P ( B ∣ A ) P(B|A) P(B∣A),它等于事件 A B AB AB 的概率相对于事件 A A A 的概率,即: P ( B ∣ A ) = A B A P(B|A)=\frac{AB}{A} P(B∣A)=AAB。其中必须有 P ( A ) > 0 P(A)>0 P(A)>0
-
条件概率分布的链式法则:对于 n n n 个随机变量 X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn,有:
P ( X 1 , X 2 , ⋯ , X n ) = P ( X 1 ) ∏ i = 2 n P ( X i ∣ X 1 , ⋯ , X i − 1 ) (1-1) P(X_1,X_2,\cdots,X_n)=P(X_1)\prod_{i=2}^{n}P(X_i \mid X_1,\cdots,X_{i-1})\tag{1-1} P(X1,X2,⋯,Xn)=P(X1)i=2∏nP(Xi∣X1,⋯,Xi−1)(1-1) -
两个随机变量 X , Y X,Y X,Y 相互独立的数学描述: P ( X , Y ) = P ( X ) P ( Y ) P(X,Y)=P(X)P(Y) P(X,Y)=P(X)P(Y)。记作: X ⊥ Y X \bot Y X⊥Y。
-
两个随机变量 X , Y X,Y X,Y关于随机变量 Z Z Z 条件独立的数学描述: P ( X , Y ∣ Z ) = P ( X ∣ Z ) P ( Y ∣ Z ) P(X,Y\mid Z)=P(X\mid Z)P(Y\mid Z) P(X,Y∣Z)=P(X∣Z)P(Y∣Z)。记作: X ⊥ Y ∣ Z X\bot Y|Z X⊥Y∣Z。
1.3 联合概率分布
-
定义 X X X 和 Y Y Y 的联合分布为: P ( a , b ) = P { X ≤ a , Y ≤ b } , − ∞ < a , b < + ∞ P(a,b)=P\{X \le a, Y \le b\}, \quad - \infty \lt a,b \lt + \infty P(a,b)=P{X≤a,Y≤b},−∞<a,b<+∞
- X X X 的分布可以从联合分布中得到:
P X ( a ) = P { X ≤ a } = P { X ≤ a , Y ≤ ∞ } = P ( a , ∞ ) , − ∞ < a < + ∞ (1-2) P_X(a)=P\{X \le a\}=P\{X \le a, Y \le \infty\}=P(a,\infty),\quad - \infty \lt a \lt + \infty\tag{1-2} PX(a)=P{X≤a}=P{X≤a,Y≤∞}=P(a,∞),−∞<a<+∞(1-2) - Y Y Y 的分布可以从联合分布中得到:
P Y ( b ) = P { Y ≤ b } = P { X ≤ ∞ , Y ≤ b } = P ( ∞ , b ) , − ∞ < b < + ∞ (1-3) P_Y(b)=P\{Y \le b\}=P\{X \le \infty, Y \le b\}=P(\infty,b), \quad - \infty \lt b \lt + \infty\tag{1-3} PY(b)=P{Y≤b}=P{X≤∞,Y≤b}=P(∞,b),−∞<b<+∞(1-3)
- X X X 的分布可以从联合分布中得到:
-
当 X X X 和 Y Y Y 都是离散随机变量时,定义 X X X 和 Y Y Y 的联合概率质量函数为:
p ( x , y ) = P { X = x , Y = y } (1-4) p(x,y)=P\{X=x,Y=y\}\tag{1-4} p(x,y)=P{X=x,Y=y}(1-4)
则 X X X 和 Y Y Y 的概率质量函数分布为:
p X ( x ) = ∑ y p ( x , y ) p Y ( y ) = ∑ x p ( x , y ) (1-5) p_X(x)=\sum_{y}p(x,y) \quad p_Y(y)=\sum_{x}p(x,y)\tag{1-5} pX(x)=y∑p(x,y)pY(y)=x∑p(x,y)(1-5) -
当 X X X 和 Y Y Y 联合地连续时,即存在函数 p ( x , y ) p(x,y) p(x,y),使得对于所有的实数集合 A \mathbb{A} A 和 B \mathbb{B} B 满足:
P { X ∈ A , Y ∈ B } = ∫ B ∫ A p ( x , y ) d x d y (1-6) P\{X \in \mathbb A, Y \in \mathbb B\}=\int_\mathbb B \int_\mathbb A p(x,y) dx dy\tag{1-6} P{X∈A,Y∈B}=∫B∫Ap(x,y)dxdy(1-6)
则函数 p ( x , y ) p(x,y) p(x,y) 称为 X X X 和 Y Y Y 的概率密度函数。-
联合分布为: P ( a , b ) = P { X ≤ a , Y ≤ b } = ∫ − ∞ a ∫ − ∞ b p ( x , y ) d x d y P(a,b)=P\{X \le a, Y \le b\}= \int_{-\infty}^{a} \int_{-\infty}^{b} p(x,y) dx dy P(a,b)=P{X≤a,Y≤b}=∫−∞a∫−∞bp(x,y)dxdy。
-
X X X 和 Y Y Y 的分布函数以及概率密度函数分别为:
P X ( a ) = ∫ − ∞ a ∫ − ∞ ∞ p ( x , y ) d x d y = ∫ − ∞ a p X ( x ) d x P Y ( b ) = ∫ − ∞ ∞ ∫ − ∞ b p ( x , y ) d x d y = ∫ − ∞ b p Y ( y ) d y p X ( x ) = ∫ − ∞ ∞ p ( x , y ) d y p Y ( y ) = ∫ − ∞ ∞ p ( x , y ) d x (1-7) P_X(a)=\int_{-\infty}^{a} \int_{-\infty}^{\infty} p(x,y) dx dy =\int_{-\infty}^{a} p_X(x)dx\\ P_Y(b)=\int_{-\infty}^{\infty} \int_{-\infty}^{b} p(x,y) dx dy=\int_{-\infty}^{b} p_Y(y)dy\\ p_X(x)=\int_{-\infty}^{\infty} p(x,y) dy\\ p_Y(y)=\int_{-\infty}^{\infty} p(x,y) dx\tag{1-7} PX(a)=∫−∞a∫−∞∞p(x,y)dxdy=∫−∞apX(x)dxPY(b)=∫−∞∞∫−∞bp(x,y)dxdy=∫−∞bpY(y)dypX(x)=∫−∞∞p(x,y)dypY(y)=∫−∞∞p(x,y)dx(1-7)
-
2 期望和方差
2.1 期望
-
期望描述了随机变量的平均情况,衡量了随机变量 X X X 的均值。它是概率分布的泛函(函数的函数)。
- 离散型随机变量 X X X 的期望: E [ X ] = ∑ i = 1 ∞ x i p i \mathbb E[X]=\sum_{i=1}^{\infty}x_ip_i E[X]=∑i=1∞xipi。若右侧级数不收敛,则期望不存在。
- 连续性随机变量 X X X 的期望: E [ X ] = ∫ − ∞ ∞ x p ( x ) d x \mathbb E[X]=\int_{-\infty}^{\infty}xp(x)dx E[X]=∫−∞∞xp(x)dx。 若右侧极限不收敛,则期望不存在。
-
定理:对于随机变量 X X X,设 Y = g ( x ) Y=g(x) Y=g(x) 也为随机变量, g ( ⋅ ) g(\cdot) g(⋅) 是连续函数。
- 若 X X X 为离散型随机变量,且 Y Y Y 的期望存在,则: E [ Y ] = E [ g ( X ) ] = ∑ i = 1 ∞ g ( x i ) p i \mathbb E[Y]=\mathbb E[g(X)]=\sum_{i=1}^{\infty}g(x_i)p_i E[Y]=E[g(X)]=∑i=1∞g(xi)pi。也记做: E X ∼ P ( X ) [ g ( X ) ] = ∑ x g ( x ) p ( x ) \mathbb E_{X\sim P(X)}[g(X)]=\sum_{x}g(x)p(x) EX∼P(X)[g(X)]=∑xg(x)p(x)。
- 若 X X X 为连续型随机变量,且 Y Y Y 的期望存在,则: E [ Y ] = E [ g ( X ) ] = ∫ − ∞ ∞ g ( x ) p ( x ) d x \mathbb E[Y]=\mathbb E[g(X)]=\int_{-\infty}^{\infty}g(x)p(x)dx E[Y]=E[g(X)]=∫−∞∞g(x)p(x)dx。也记做: E X ∼ P ( X ) [ g ( X ) ] = ∫ g ( x ) p ( x ) d x \mathbb E_{X\sim P(X)}[g(X)]=\int g(x)p(x)dx EX∼P(X)[g(X)]=∫g(x)p(x)dx。
该定理的意义在于:当求 E Y \mathbb E_{Y} EY 时,不必计算出 Y Y Y 的分布,只需要利用 X X X 的分布即可。
该定理可以推广至两个或两个以上随机变量的情况。对于随机变量 X , Y X,Y X,Y,假设 Z = g ( X , Y ) Z=g(X,Y) Z=g(X,Y) 也是随机变量, g ( ⋅ ) g(\cdot) g(⋅) 为连续函数,则有: E [ Z ] = E [ g ( X , Y ) ] = ∫ − ∞ ∞ ∫ − ∞ ∞ g ( x , y ) p ( x , y ) d x d y \mathbb E[Z]=\mathbb E[g(X,Y)]=\int_{-\infty}^{\infty}\int_{-\infty}^{\infty}g(x,y)p(x,y)dxdy E[Z]=E[g(X,Y)]=∫−∞∞∫−∞∞g(x,y)p(x,y)dxdy。也记做: E X , Y ∼ P ( X , Y ) [ g ( X , Y ) ∫ g ( x , y ) p ( x , y ) d x d y \mathbb E_{X,Y\sim P(X,Y)}[g(X,Y)\int g(x,y)p(x,y)dxdy EX,Y∼P(X,Y)[g(X,Y)∫g(x,y)p(x,y)dxdy。
- 期望性质:
- 常数的期望就是常数本身。
- 对常数 C C C 有: E [ C X ] = C E [ X ] \mathbb E[CX]=C\mathbb E[X] E[CX]=CE[X]。
- 对两个随机变量 X , Y X,Y X,Y,有: E [ X + Y ] = E [ X ] + E [ Y ] \mathbb E[X+Y]=\mathbb E[X]+\mathbb E[Y] E[X+Y]=E[X]+E[Y]。该结论可以推广到任意有限个随机变量之和的情况。
- 对两个相互独立的随机变量 X , Y X,Y X,Y,有: E [ X Y ] = E [ X ] E [ Y ] \mathbb E[XY]=\mathbb E[X]\mathbb E[Y] E[XY]=E[X]E[Y]。该结论可以推广到任意有限个相互独立的随机变量之积的情况。
2.2 方差
-
对随机变量 X X X,若 E [ ( X − E [ X ] ) 2 ] \mathbb E[(X-\mathbb E[X])^{2}] E[(X−E[X])2] 存在,则称它为 X X X 的方差,记作 V a r [ X ] Var[X] Var[X]。
X X X 的标准差为方差的开平方。即:
V a r [ X ] = E [ ( X − E [ X ] ) 2 ] σ = V a r [ X ] (2-1) Var[X]=\mathbb E[(X-\mathbb E[X])^{2}] \\ \sigma=\sqrt{Var[X]}\tag{2-1} Var[X]=E[(X−E[X])2]σ=Var[X](2-1)- 方差度量了随机变量 X X X 与期望值偏离的程度,衡量了 X X X 取值分散程度的一个尺度。
- 由于绝对值 ∣ X − E [ X ] ∣ |X-\mathbb E[X]| ∣X−E[X]∣ 带有绝对值,不方便运算,因此采用平方来计算。又因为 ∣ X − E [ X ] ∣ 2 |X-\mathbb E[X]|^2 ∣X−E[X]∣2 是一个随机变量,因此对它取期望,即得 X X X 与期望值偏离的均值
-
根据定义可知:
V a r [ X ] = E [ ( X − E [ X ] ) 2 ] = E [ X 2 ] − ( E [ X ] ) 2 V a r [ f ( X ) ] = E [ ( f ( X ) − E [ f ( X ) ] ) 2 ] (2-2) Var[X]=\mathbb E[(X-\mathbb E[X])^{2}]=\mathbb E[X^{2}]-(\mathbb E[X])^{2}\\ Var [f(X)]=\mathbb E[(f(X)-\mathbb E[f(X)])^{2}]\tag{2-2} Var[X]=E[(X−E[X])2]=E[X2]−(E[X])2Var[f(X)]=E[(f(X)−E[f(X)])2](2-2) -
对于一个期望为 μ \mu μ, 方差为 σ 2 , σ ≠ 0 \sigma^2, \sigma\not=0 σ2,σ=0 的随机变量 X X X,随机变量 X ∗ = X − μ σ X^{*}=\frac {X-\mu}{\sigma} X∗=σX−μ 的数学期望为0,方差为1。 称 X ∗ X^{*} X∗ 为 X X X 的标准化变量。
-
方差的性质:
- 常数的方差恒为 0 。
- 对常数 C C C,有 V a r [ C X ] = C 2 V a r [ X ] Var[CX]=C^2Var[X] Var[CX]=C2Var[X]。
- 对两个随机变量 X , Y X, Y X,Y,有: V a r [ X + Y ] = V a r [ X ] + V a r [ Y ] + 2 E [ ( X − E [ X ] ) ( Y − E [ Y ] ) ] Var[X+Y]=Var[X] +Var[Y] +2\mathbb E[(X-\mathbb E[X])(Y-\mathbb E[Y])] Var[X+Y]=Var[X]+Var[Y]+2E[(X−E[X])(Y−E[Y])];当 X X X 和 Y Y Y 相互独立时,有 V a r [ X + Y ] = V a r [ X ] + V a r [ Y ] Var[X+Y] = Var[X] +Var[Y] Var[X+Y]=Var[X]+Var[Y]。这可以推广至任意有限多个相互独立的随机变量之和的情况。
- V a r [ X ] = 0 Var[X]=0 Var[X]=0 的充要条件是 X X X 以概率1取常数。
2.3 协方差和相关系数
-
对于二维随机变量 ( X , Y ) (X, Y) (X,Y),可以讨论描述 X X X 与 Y Y Y 之间相互关系的数字特征。
- 定义: E [ ( X − E [ X ] ) ( Y − E [ Y ] ) ] \mathbb E[(X-\mathbb E[X])(Y-\mathbb E [Y])] E[(X−E[X])(Y−E[Y])] 为随机变量 X X X 与 Y Y Y 的协方差,记作 C o v [ X , Y ] = E [ ( X − E [ X ] ) ( Y − E [ Y ] ) ] Cov[ X,Y]=\mathbb E[(X-\mathbb E[X])(Y-\mathbb E [Y])] Cov[X,Y]=E[(X−E[X])(Y−E[Y])]。
- 定义: ρ X Y = C o v [ X , Y ] V a r [ X ] V a r [ Y ] \rho_{XY}=\frac {Cov[X,Y]}{\sqrt{Var[X] }\sqrt{Var[Y]}} ρXY=Var[X]Var[Y]Cov[X,Y] 为随机变量 X X X 与 Y Y Y 的相关系数,它是协方差的归一化。
-
由定义可知:
C o v [ X , Y ] = C o v [ Y , X ] C o v [ X , X ] = V a r [ X ] V a r [ X + Y ] = V a r [ X ] + V a r [ Y ] + 2 C o v [ X , Y ] (2-3) Cov[ X,Y] =Cov[ Y,X] \\ Cov [X,X] =Var [X] \\ Var [X+Y] =Var [X] +Var [Y] +2Cov [X,Y] \tag{2-3} Cov[X,Y]=Cov[Y,X]Cov[X,X]=Var[X]Var[X+Y]=Var[X]+Var[Y]+2Cov[X,Y](2-3) -
协方差的性质:
- C o v [ a X , b Y ] = a b C o v [ X , Y ] , a , b 为常数 Cov [aX,bY] =abCov [X,Y], a,b为常数 Cov[aX,bY]=abCov[X,Y],a,b为常数
- C o v [ X 1 + X 2 , Y ] = C o v [ X 1 , Y ] + C o v [ X 2 , Y ] Cov[ X_1+X_2,Y ]=Cov [X_1,Y] +Cov [X_2,Y] Cov[X1+X2,Y]=Cov[X1,Y]+Cov[X2,Y]
- C o v [ f ( X ) , g ( Y ) ] = E [ ( f ( X ) − E [ f ( X ) ] ) ( g ( Y ) − E [ g ( Y ) ] ) ] Cov [f(X),g(Y)]=\mathbb E[(f(X)-\mathbb E[f(X)])(g(Y)-\mathbb E[g(Y)])] Cov[f(X),g(Y)]=E[(f(X)−E[f(X)])(g(Y)−E[g(Y)])]
- ρ [ f ( X ) , g ( Y ) ] = C o v [ f ( X ) , g ( Y ) ] V a r [ f ( X ) ] V a r [ g ( Y ) ] \rho[f(X),g(Y)]=\frac {Cov[f(X),g(Y)]}{\sqrt{Var[f(X)] }\sqrt{Var[g(Y)]}} ρ[f(X),g(Y)]=Var[f(X)]Var[g(Y)]Cov[f(X),g(Y)]
-
协方差的物理意义:
- 协方差的绝对值越大,说明两个随机变量都远离它们的均值。
- 协方差如果为正,则说明两个随机变量同时趋向于取较大的值或者同时趋向于取较小的值;如果为负,则说明一个随变量趋向于取较大的值,另一个随机变量趋向于取较小的值。
- 两个随机变量的独立性可以导出协方差为零。但是两个随机变量的协方差为零无法导出独立性。因为独立性也包括:没有非线性关系。有可能两个随机变量是非独立的,但是协方差为零。如:假设随机变量 X ∼ U [ − 1 , 1 ] X\sim U[-1,1] X∼U[−1,1]。定义随机变量 S S S 的概率分布函数为:
P ( S = 1 ) = 1 2 P ( S = − 1 ) = 1 2 P(S=1)= \frac 12P(S=-1)= \frac 12 P(S=1)=21P(S=−1)=21
定义随机变量 Y = S X Y=SX Y=SX,则随机变量 X , Y X,Y X,Y 是非独立的,但是有: C o v [ X , Y ] = 0 Cov[X,Y]=0 Cov[X,Y]=0。
-
相关系数的物理意义:考虑以随机变量 X X X 的线性函数 a + b X a+bX a+bX 来近似表示 Y Y Y。以均方误差
e = E [ ( Y − ( a + b X ) ) 2 ] = E [ Y 2 ] + b 2 E [ X 2 ] + a 2 − 2 b E [ X Y ] + 2 a b E [ X ] − 2 a E [ Y ] (2-4) e=\mathbb E[(Y-(a+bX))^{2}]=\mathbb E[Y^{2}] +b^{2}\mathbb E[X^{2}] +a^{2}-2b\mathbb E[XY] +2ab\mathbb E[X] -2a\mathbb E [Y]\tag{2-4} e=E[(Y−(a+bX))2]=E[Y2]+b2E[X2]+a2−2bE[XY]+2abE[X]−2aE[Y](2-4)
来衡量以 a + b X a+bX a+bX 近似表达 Y Y Y 的好坏程度。 e e e 越小表示近似程度越高。
为求得最好的近似,则对 a , b a,b a,b 分别取偏导数,得到:
a 0 = E [ Y ] − b 0 E [ X ] = E [ Y ] − E [ X ] C o v [ X , Y ] V a r [ X ] b 0 = C o v [ X , Y ] V a r [ X ] min ( e ) = E [ ( Y − ( a 0 + b 0 X ) ) 2 ] = ( 1 − ρ X Y 2 ) V a r [ Y ] (2-5) a_0=\mathbb E[Y] -b_0\mathbb E[X] =\mathbb E[Y] -\mathbb E[X] \frac{Cov [X,Y]}{Var [X] }\\ b_0=\frac{Cov[ X,Y] }{Var[ X] }\\ \min(e)=\mathbb E[(Y-(a_0+b_0X))^{2}]=(1-\rho^{2}_{XY})Var [Y] \tag{2-5} a0=E[Y]−b0E[X]=E[Y]−E[X]Var[X]Cov[X,Y]b0=Var[X]Cov[X,Y]min(e)=E[(Y−(a0+b0X))2]=(1−ρXY2)Var[Y](2-5)
因此有以下定理:- ∣ ρ X Y ∣ ≤ 1 |\rho_{XY}| \le 1 ∣ρXY∣≤1( ∣ ⋅ ∣ |\cdot| ∣⋅∣ 是绝对值)。
- ∣ ρ X Y = 1 ∣ |\rho_{XY}=1| ∣ρXY=1∣ 的充要条件是:存在常数 a , b a, b a,b 使得 P { Y = a + b X } = 1 P\{Y=a+bX\}=1 P{Y=a+bX}=1。
-
当 ∣ ρ X Y ∣ |\rho_{XY}| ∣ρXY∣ 较大时, e e e 较小,意味着随机变量 X X X 和 Y Y Y 联系较紧密。于是 ∣ ρ X Y ∣ |\rho_{XY}| ∣ρXY∣ 是一个表征 X 、 Y X、Y X、Y 之间线性关系紧密程度的量。
-
当 ∣ ρ X Y ∣ = 0 |\rho_{XY}|=0 ∣ρXY∣=0 时,称 X X X 和 Y Y Y 不相关。
- 不相关是就线性关系来讲的,而相互独立是一般关系而言的。
- 相互独立一定不相关;不相关则未必独立。
2.4 协方差矩阵
-
设 X X X 和 Y Y Y 是随机变量
- 若 E [ X k ] , k = 1 , 2 , ⋯ \mathbb{E}[X^k], k=1, 2,\cdots E[Xk],k=1,2,⋯ 存在,则称它为 X X X 的 k k k 阶原点矩,简称 k k k 阶矩。
- 若 E [ ( X − E [ X ] ) k ] , k = 2 , 3 , ⋯ \mathbb E[(X-\mathbb E[X])^{k}] ,k=2,3,\cdots E[(X−E[X])k],k=2,3,⋯ 存在,则称它为 X X X 的 k k k 阶中心矩。
- 若 E [ X k Y l ] , k , l = 1 , 2 , ⋯ \mathbb E[X^{k}Y^{l}] ,k,l=1,2,\cdots E[XkYl],k,l=1,2,⋯ 存在,则称它为 X X X 和 Y Y Y 的 k + l k+l k+l 阶混合矩。
- 若 E [ ( X − E [ X ] ) k ( Y − E [ Y ] ) l ] , k , l = 1 , 2 , ⋯ \mathbb E[(X-\mathbb E[X])^{k}(Y-\mathbb E[Y])^{l}] ,k,l=1,2,\cdots E[(X−E[X])k(Y−E[Y])l],k,l=1,2,⋯ 存在,则称它为 X X X 和 X X X 的 k + l k+l k+l 阶混合中心矩。
因此:期望是一阶原点矩,方差是二阶中心矩,协方差是二阶混合中心矩。
-
协方差矩阵:
- 二维随机变量 ( X 1 , X 2 ) (X_1,X_2) (X1,X2) 有四个二阶中心矩(假设他们都存在),记作:
c 11 = E [ ( X 1 − E [ X 1 ] ) 2 ] c 12 = E [ ( X 1 − E [ X 1 ] ) ( X 2 − E [ X 2 ] ) ] c 21 = E [ ( X 2 − E [ X 2 ] ) ( X 1 − E [ X 1 ] ) ] c 22 = E [ ( X 2 − E [ X 2 ] ) 2 ] (2-6) c_{11}=\mathbb E[(X_1-\mathbb E[X_1])^{2}] \\ c_{12}=\mathbb E[(X_1-\mathbb E[X_1])( X_2-\mathbb E[X_2]) ] \\ c_{21}=\mathbb E[( X_2-\mathbb E[X_2])(X_1-\mathbb E[X_1] ) ] \\ c_{22}=\mathbb E[(X_2-\mathbb E[X_2])^{2}] \tag{2-6} c11=E[(X1−E[X1])2]c12=E[(X1−E[X1])(X2−E[X2])]c21=E[(X2−E[X2])(X1−E[X1])]c22=E[(X2−E[X2])2](2-6)
称矩阵
C = [ c 11 c 12 c 21 c 22 ] (2-7) \mathbf C=\begin{bmatrix} c_{11}&c_{12}\\ c_{21}&c_{22} \end{bmatrix}\tag{2-7} C=[c11c21c12c22](2-7)
为随机变量 ( X 1 , X 2 ) (X_1,X_2) (X1,X2) 的协方差矩阵。 - 设 n n n 维随机变量 ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2,\cdots,X_n) (X1,X2,⋯,Xn) 的二阶混合中心矩 c i j = C o v [ X i , X j ] = E [ ( X i − E [ X i ] ) ( X j − E [ X j ] ) ] c_{ij}=Cov [X_i,X_j] =\mathbb E[(X_i-\mathbb E[X_i] )( X_j-\mathbb E[X_j] ) ] cij=Cov[Xi,Xj]=E[(Xi−E[Xi])(Xj−E[Xj])] 都存在,则称矩阵
C = [ c 11 c 12 ⋯ c 1 n c 21 c 22 ⋯ c 2 n ⋮ ⋮ ⋱ ⋮ c n 1 c n 2 ⋯ c n n ] (2-8) \mathbf C= \begin{bmatrix} c_{11} & c_{12} & \cdots & c_{1n} \\ c_{21} & c_{22} & \cdots & c_{2n} \\ \vdots &\vdots &\ddots &\vdots \\ c_{n1} & c_{n2} & \cdots & c_{nn} \\ \end{bmatrix}\tag{2-8} C=⎣ ⎡c11c21⋮cn1c12c22⋮cn2⋯⋯⋱⋯c1nc2n⋮cnn⎦ ⎤(2-8)
为 n n n 维随机变量 ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2,\cdots,X_n) (X1,X2,⋯,Xn) 的协方差矩阵。
由于 c i j = c j i , i ≠ j , i , j = 1 , 2 , ⋯ , n c_{ij}=c_{ji}, i\ne j, i,j=1,2,\cdots,n cij=cji,i=j,i,j=1,2,⋯,n,因此协方差矩阵是个对称阵。
- 二维随机变量 ( X 1 , X 2 ) (X_1,X_2) (X1,X2) 有四个二阶中心矩(假设他们都存在),记作:
-
通常 n n n 维随机变量的分布是不知道的,或者太复杂以致数学上不容易处理。因此实际中协方差矩阵非常重要。
3 大数定律及中心极限定理
3.1 切比雪夫不等式
假设随机变量 X X X 具有期望 E ( X ) = μ E(X) = \mu E(X)=μ,方差 D ( X ) = σ 2 D(X) = \sigma^2 D(X)=σ2,则对于任意正数 ϵ \epsilon ϵ,下面的不等式成立:
P { ∣ X − μ ∣ ≥ ϵ } ≤ ϵ 2 σ 2 (3-1) P\{ \lvert X - \mu \rvert \geq \epsilon \} \leq \frac{\epsilon^2}{\sigma^2}\tag{3-1} P{∣X−μ∣≥ϵ}≤σ2ϵ2(3-1)
其意义是:对于距离 E ( X ) E(X) E(X) 足够远的地方(距离大于等于 ϵ \epsilon ϵ),事件出现的概率是小于等于 σ 2 ϵ 2 \frac{\sigma^2}{\epsilon^2} ϵ2σ2 。即事件出现在区间 [ μ − ϵ , μ + ϵ ] [\mu - \epsilon, \mu + \epsilon] [μ−ϵ,μ+ϵ] 的概率大于 1 − σ 2 ϵ 2 1 - \frac{\sigma^2}{\epsilon^2} 1−ϵ2σ2 。 所以该不等式给出了随机变量 X X X 在分布未知的情况下,事件 { ∣ X − μ ∣ ≤ ϵ } \{ \lvert X -\mu \rvert\ \leq \epsilon\} {∣X−μ∣ ≤ϵ} 的下限估计。
证明:
我们以连续随机变量的情况来证明,离散的情况类似可证。设连续随机变量 X X X 的密度函数为 f ( x ) f(x) f(x),事件 X X X 即表示 X X X 落在区间 ( μ − ϵ , μ + ϵ ) (\mu - \epsilon, \mu + \epsilon) (μ−ϵ,μ+ϵ) 外,因此在积分范围内恒有 ( x − μ ) 2 ϵ 2 ≥ 1 \frac{(x - \mu)^2}{\epsilon^2} \geq 1 ϵ2(x−μ)2≥1,故:
P { ∣ X − μ ∣ ≥ ϵ } = ∫ ∣ X − μ ∣ ≥ ϵ p ( x ) d x ≤ ∫ ∣ X − μ ∣ ≥ ϵ ∣ X − μ ∣ 2 ϵ 2 p ( x ) d x ≤ 1 ϵ 2 ∫ − ∞ ∞ ∣ X − μ ∣ 2 p ( x ) d x = σ 2 ϵ 2 (3-2) P \{ \lvert X - \mu \rvert \geq \epsilon \}= \int_{\lvert X - \mu \rvert \geq \epsilon }p(x)dx \leq \int_{\lvert X - \mu \rvert \geq \epsilon }\frac{{\lvert X - \mu \rvert}^2}{\epsilon^2}p(x)dx \\ \leq \frac{1}{\epsilon^2} \int_{-\infty}^{\infty} {\lvert X - \mu \rvert}^2p(x)dx = \frac{\sigma^2}{\epsilon^2}\tag{3-2} P{∣X−μ∣≥ϵ}=∫∣X−μ∣≥ϵp(x)dx≤∫∣X−μ∣≥ϵϵ2∣X−μ∣2p(x)dx≤ϵ21∫−∞∞∣X−μ∣2p(x)dx=ϵ2σ2(3-2)
切比雪夫不等式的特殊情况:设随机变量 X 1 , X 2 , ⋯ , X n , ⋯ X_1, X_2,\cdots,X_n,\cdots X1,X2,⋯,Xn,⋯ 相互独立,且具有相同的数学期望和方差: E [ X k ] = μ , V a r [ X k ] = σ 2 \mathbb E[X_k] =\mu, Var[X_k] =\sigma^{2} E[Xk]=μ,Var[Xk]=σ2。 作前 n n n 个随机变量的算术平均: X ‾ = 1 n ∑ k = 1 n X k \overline X =\frac {1}{n} \sum _{k=1}^{n}X_k X=n1∑k=1nXk, 则对于任意正数 ε \varepsilon ε 有:
lim n → ∞ P { ∣ X ‾ − μ ∣ < ε } = lim n → ∞ P { ∣ 1 n ∑ k = 1 n X k − μ ∣ < ε } = 1 (3-3) \lim_{n\rightarrow \infty}P\{|\overline X-\mu| \lt \varepsilon\}=\lim_{n\rightarrow \infty}P\{|\frac{1}{n}\sum_{k=1}^{n}X_k-\mu| \lt \varepsilon\} =1\tag{3-3} n→∞limP{∣X−μ∣<ε}=n→∞limP{∣n1k=1∑nXk−μ∣<ε}=1(3-3)
证明:根据期望和方差的性质有: E [ X ‾ ] = μ \mathbb E[\overline X]=\mu E[X]=μ, V a r [ X ‾ ] = σ 2 n Var[\overline X]=\frac{\sigma^2}{n} Var[X]=nσ2。根据切比雪夫不等式有:
P { ∣ X ‾ − μ ∣ ≥ ε } ≤ σ 2 n ε 2 (3-4) P\{|\overline X-\mu| \ge \varepsilon\} \le \frac{\sigma^2}{n\varepsilon^2}\tag{3-4} P{∣X−μ∣≥ε}≤nε2σ2(3-4)
则有 lim n → ∞ P { ∣ X ‾ − μ ∣ ≥ ε } = 0 \lim_{n\rightarrow \infty}P\{|\overline X-\mu| \ge \varepsilon\} = 0 limn→∞P{∣X−μ∣≥ε}=0,因此有: lim n → ∞ P { ∣ X ‾ − μ ∣ < ε } = 1 \lim_{n\rightarrow \infty}P\{|\overline X-\mu| \lt \varepsilon\} =1 limn→∞P{∣X−μ∣<ε}=1
3.2 大数定律
大数定律(Law of Large Numbers,LLN)是指某个随机事件在单次试验中可能发生也可能不发生,但在大量重复实验中往往呈现出明显的规律性,即该随机事件发生的频率会向某个常数值收敛,该常数值即为该事件发生的概率。另一种表达方式为当样本数据无限大时,样本均值趋于总体均值。
大数定律的作用:现实生活中,我们无法进行无穷多次试验,也很难估计出总体的参数。大数定律告诉我们能用频率近似代替概率;能用样本均值近似代替总体均值。
大数定律的表达方式主要有:辛钦大数定律、切比雪夫(Cheby—shev)大数法则、贝努利(Bernoulli)大数法则。
3.2.1 辛钦大数定律
弱大数定律即辛钦大数定律,设 X 1 , X 2 , ⋯ X_1, X_2, \cdots X1,X2,⋯ 是相互独立,服从同一分布的随机变量序列,且具有数学期望 E ( X k ) = μ ( k = 1 , 2 , ⋯ ) E(X_k) = \mu (k = 1, 2, \cdots) E(Xk)=μ(k=1,2,⋯)。前 n n n 个变量的算术平均 1 n ∑ k = 1 n X k \frac{1}{n} \sum_{k = 1}^{n}X_k n1∑k=1nXk,则对任意 ϵ > 0 \epsilon > 0 ϵ>0,有
lim n → ∞ P { ∣ 1 n ∑ k = 1 n X k − μ ∣ < ϵ } = 1 (3-5) \lim_{n \to \infty}P\{\lvert \frac{1}{n} \sum_{k = 1}^{n}X_k - \mu \rvert < \epsilon \} = 1\tag{3-5} n→∞limP{∣n1k=1∑nXk−μ∣<ϵ}=1(3-5)
辛钦大数定理从理论上指出,对于独立同分布且具有均值 μ \mu μ 的随机变量 X 1 , ⋯ , X n X_1, \cdots, X_n X1,⋯,Xn,当 n n n 很大时,用它们的算术平均值 1 n ∑ k = 1 n X k \frac{1}{n} \sum_{k = 1}^{n}X_k n1∑k=1nXk 来近似实际真值 μ \mu μ 是合理的。
另外一种描述,设随机变量 X 1 , X 2 , ⋯ , X n , ⋯ X_1, X_2, \cdots, X_n, \cdots X1,X2,⋯,Xn,⋯ 相互独立,服从同一分布且具有数学期望 E ( X k ) = μ ( k = 1 , 2 , ⋯ ) E(X_k) = \mu (k = 1, 2, \cdots) E(Xk)=μ(k=1,2,⋯),则序列 X ‾ = 1 n ∑ k = 1 n X k \overline{X} = \frac{1}{n} \sum_{k = 1}^{n}X_k X=n1∑k=1nXk 依概率收敛于 μ \mu μ,即 X ‾ → P μ \overline{X} \overset{P}{\to} \mu X→Pμ。
注:(1)这里并没有要求随机变量 X 1 , X 2 , ⋯ , X n , ⋯ X_1, X_2, \cdots, X_n, \cdots X1,X2,⋯,Xn,⋯ 的方差存在。(2)当 X X X 为服从0-1分布的随机变量时,辛钦大数定律就是伯努利大数定律,故伯努利大数定律是辛钦伯努利大数定律的一个特例。
3.2.2 伯努利大数定理
设 f A f_A fA 是 n n n 次独立重复试验中事件 A A A 发生的次数, p p p 是事件 A A A 在每次试验中发生的概率,则对于任意正数 ϵ > 0 \epsilon > 0 ϵ>0,有:
lim n → ∞ P { ∣ f A n − p ∣ < ϵ } = 1 或 lim n → ∞ P { ∣ f A n − p ∣ ≥ ϵ } = 0 (3-6) \lim_{n \to \infty}P\{\lvert \frac{f_A}{n} - p \rvert < \epsilon \} = 1 \quad 或 \quad \lim_{n \to \infty}P\{\lvert \frac{f_A}{n} - p \rvert \geq \epsilon \} = 0\tag{3-6} n→∞limP{∣nfA−p∣<ϵ}=1或n→∞limP{∣nfA−p∣≥ϵ}=0(3-6)
伯努利大数定律说明:当独立重复实验执行非常大的次数时,事件 A A A 发生的频率逼近于它的概率。
3.2.3 切比雪夫大数定律
设随机变量 X 1 , X 2 , ⋯ , X n X_1, X_2, \cdots, X_n X1,X2,⋯,Xn 相互独立,分别有数学期望 E ( X 1 ) , E ( X 2 ) , ⋯ , E ( X n ) E(X_1), E(X_2), \cdots, E(X_n) E(X1),E(X2),⋯,E(Xn) 及方差 D ( X 1 ) , D ( X 2 ) , ⋯ , D ( X n ) D(X_1), D(X_2), \cdots, D(X_n) D(X1),D(X2),⋯,D(Xn) 并且方差是一致有界的,即存在某一个常数 K K K,使得 D ( X k ) < K , k = 1 , 2 , ⋯ D(X_k)< K, k=1, 2, \cdots D(Xk)<K,k=1,2,⋯ 则对任意 ϵ > 0 \epsilon > 0 ϵ>0,恒有
lim n → ∞ P ( ∣ 1 n ∑ k = 1 n X k − 1 n ∑ i = 1 n E ( X k ) ∣ < ϵ ) = 1 (3-7) \lim_{n \to \infty}P(\lvert \frac{1}{n} \sum_{k=1}^{n}X_k - \frac{1}{n} \sum_{i=1}^{n}E(X_k) \rvert < \epsilon) =1\tag{3-7} n→∞limP(∣n1k=1∑nXk−n1i=1∑nE(Xk)∣<ϵ)=1(3-7)
切比雪夫大数定理的意义:由于独立随机变量 X 1 , X 2 , ⋯ , X n X_1, X_2, \cdots, X_n X1,X2,⋯,Xn 的算术平均值 X n ‾ = 1 n ∑ k = 1 n X k \overline{X_n} = \frac{1}{n} \sum_{k=1}^{n} X_k Xn=n1∑k=1nXk 的数学期望 E ( X n ‾ ) = 1 n ∑ k = 1 n E ( X k ) E(\overline{X_n}) = \frac{1}{n} \sum_{k=1}^{n} E(X_k) E(Xn)=n1∑k=1nE(Xk) 及方差 D ( X n ‾ ) = 1 n 2 ∑ k = 1 n D ( X k ) D(\overline{X_n}) = \frac{1}{n^2} \sum_{k=1}^{n} D(X_k) D(Xn)=n21∑k=1nD(Xk),当各个方差一致有界时, D ( X n ‾ ) < 1 n 2 n K = K n D(\overline{X_n}) < \frac{1}{n^2}nK = \frac{K}{n} D(Xn)<n21nK=nK,由此可见,当 n n n 充分大时,随机变量 X n X_n Xn 的分布的分散度是很小的, X n ‾ \overline{X_n} Xn 的值比较集中在其数学期望附近。
3.2.4 马尔科夫大数定律
马尔科夫条件:
lim n → ∞ D ( ∑ k = 1 n X k ) n 2 = 0 (3-8) \lim_{n \to \infty} \frac{D(\sum_{k =1}^{n}X_k)}{n^2} = 0\tag{3-8} n→∞limn2D(∑k=1nXk)=0(3-8)
满足马尔科夫条件的随机变量序列 X n X_n Xn 服从大数定律。
小结:
| 大数定理 | 分布 | 期望 | 方差 | 用途 |
|---|---|---|---|---|
| 伯努利 | 二项分布 | 相同 | 相同 | 估算概率 |
| 辛钦 | 独立同分布 | 相同 | 相同 | 估算期望 |
| 切比雪夫 | 独立 | 存在 | 存在 有限 | 估算期望 |
小概率原理或实际推断原理——一个事件如果发生的概率很小的话,那么它在一次试验中是几乎不可能发生的,但在多次重复试验中几乎是必然发生的。统计学里,把小概率事件在一次实验中看成是实际不可能发生的事件,一般认为等于或小于0.05或0.01的概率为小概率。实际推断原理通常在假设检验中使用,即如果小概率事件在一次试验中居然发生了,则有理由首先怀疑原假设的真实性,从而拒绝原假设。
3.3 中心极限定理
当样本量 n n n 逐渐趋于无穷大时, n n n 个抽样样本的均值的频数逐渐趋于正态分布,其对原总体的分布不做任何要求,意味着无论总体是什么分布,其抽样样本的均值的频数的分布都随着抽样数的增多而趋于正态分布。 如下图所示:
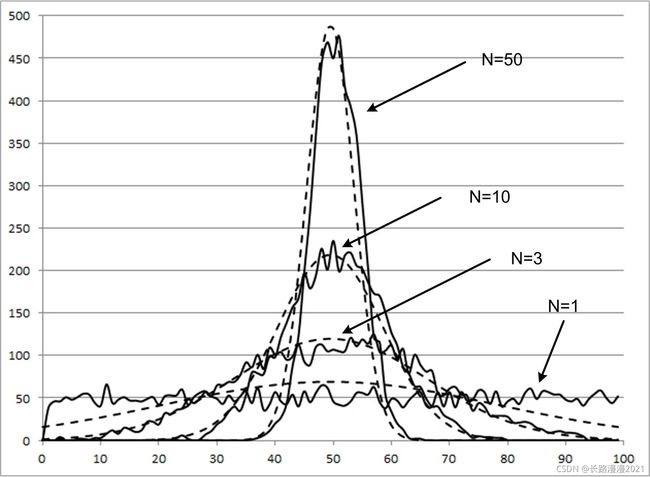
注:图中虚线表示正态分布,可以发现当样本量 n n n 逐渐增大时,样本的分布趋于正态分布。
3.3.1 独立同分布的中心极限定理
设随机变量 X 1 , X 2 , ⋯ , X n , ⋯ X_1, X_2, \cdots, X_n, \cdots X1,X2,⋯,Xn,⋯ 相互独立,服从同一分布,且具有数学期望和方差: E ( X k ) = μ , D ( X k ) = σ 2 ( k = 1 , 2 , ⋯ ) E(X_k) = \mu, \quad D(X_k) = \sigma^2 (k = 1, 2, \cdots) E(Xk)=μ,D(Xk)=σ2(k=1,2,⋯),则随机变量之和 ∑ k = 1 n X k \sum_{k = 1}^{n}X_k ∑k=1nXk 的标准化变量
Y n = ∑ k = 1 n X k − E ( ∑ k = 1 n X k ) D ( ∑ k = 1 n X k ) = ∑ k = 1 n X k − n μ n σ (3-9) Y_n = \frac{\sum_{k=1}^{n}X_k - E(\sum_{k=1}^{n}X_k)}{\sqrt{D(\sum_{k=1}^{n}X_k)}} = \frac{\sum_{k=1}^{n}X_k - n\mu}{\sqrt n \sigma}\tag{3-9} Yn=D(∑k=1nXk)∑k=1nXk−E(∑k=1nXk)=nσ∑k=1nXk−nμ(3-9)
的分布函数 F n ( x ) F_n(x) Fn(x) 对于任意 x x x 满足
lim n → ∞ F n ( x ) = lim n → ∞ P { ∑ k = 1 n X k − n μ n σ ≤ x } = ∫ − ∞ x 1 2 π e − t 2 / 2 d t = Φ ( x ) (3-10) \lim_{n \to \infty}F_n(x) = \lim_{n \to \infty}P\{\frac{ \sum_{k = 1}^{n}X_k - n \mu}{\sqrt{n} \sigma} \leq x \} = \int_{-\infty}^{x}\frac{1}{\sqrt{2 \pi}}e^{-t^2/2}dt = \Phi(x)\tag{3-10} n→∞limFn(x)=n→∞limP{nσ∑k=1nXk−nμ≤x}=∫−∞x2π1e−t2/2dt=Φ(x)(3-10)
其物理意义为:均值方差为 μ , σ 2 \mu, \sigma^2 μ,σ2 的独立同分布的随机变量 X 1 , X 2 , ⋯ , X n X_1, X_2, \cdots, X_n X1,X2,⋯,Xn 之和 ∑ k = 1 n X k \sum_{k = 1}^{n}X_k ∑k=1nXk 的标准变化量 Y n Y_n Yn,当 n n n 充分大时,其分布近似于标准正态分布。 一般情况下,很难求出 n n n 个随机变量之和的分布函数。因此当 n n n 充分大时,可以通过正态分布来做理论上的分析或者计算。
3.3.2 棣莫弗-拉普拉斯定理
棣莫弗-拉普拉斯(De Moivre-Laplace)中心极限定理是独立同分布中心极限定理的特殊情况,它是最先被发现的中心极限定理。设随机变量 η n ( n = 1 , 2 , ⋯ ) \eta_n(n=1, 2, \cdots) ηn(n=1,2,⋯) 服从参数为 n, p(0
lim n → ∞ P { η n − n p n p ( 1 − p ) ≤ a } = ∫ − ∞ x 1 2 π e − t 2 / 2 d t = Φ ( x ) (3-11) \lim_{n \to \infty}P\{\frac{\eta_n - np}{\sqrt{np(1-p)}} \leq a \} = \int_{-\infty}^{x}\frac{1}{\sqrt{2 \pi}}e^{-t^2/2}dt = \Phi(x)\tag{3-11} n→∞limP{np(1−p)ηn−np≤a}=∫−∞x2π1e−t2/2dt=Φ(x)(3-11)
该定理表明,正态分布是二项分布的极限分布。当 n n n 充分大时,我们可以利用上式来计算二项分布的概率。
3.3.3 独立不同分布下的中心极限定理
长度、重量、时间等等实际测量量一般符合正态分布,因为它们受各种微小的随机因素的扰动。这些随机因素的独立性是很普遍的,但很难说它们一定同分布。
实际上,一系列独立不同分布的随机变量也可能满足中心极限定理,只是这些不同分布的随机变量要有所限制。以下给出两个独立不同分布下的中心极限定理,不予证明,简单扩展一下。
3.3.4 林德伯格中心极限定理
设 { X n } \{ X_n\} {Xn} 是一系列相互独立的连续随机变量,它们具有有限的期望 E ( X k ) = μ k E(X_k) = \mu_k E(Xk)=μk 和方差 D ( X k ) = σ k 2 D(X_k) = \sigma_{k}^{2} D(Xk)=σk2 ,记 Y n = ∑ k = 1 n X k , D ( Y n ) = ∑ k = 1 n σ k 2 = B n 2 Y_n = \sum_{k = 1}^{n}X_k, \quad D(Y_n) = \sum_{k = 1}^{n}\sigma_{k}^{2} = B_{n}^{2} Yn=∑k=1nXk,D(Yn)=∑k=1nσk2=Bn2 ,记 X k X_k Xk 的概率密度函数是 f i ( x ) f_i(x) fi(x),若
∀ τ > 0 : lim n → ∞ 1 τ 2 B n 2 ∑ k = 1 n ∣ X − μ ∣ ≥ τ B n ( x − μ ) 2 f k ( x ) d x = 0 (3-12) \forall \tau > 0:\lim_{n \to \infty} \frac{1}{\tau^2 B_n^2}\sum_{k=1}^{n} \lvert X - \mu \rvert \geq \tau B_n (x - \mu)^2f_k(x)dx = 0\tag{3-12} ∀τ>0:n→∞limτ2Bn21k=1∑n∣X−μ∣≥τBn(x−μ)2fk(x)dx=0(3-12)
则
lim n → ∞ P ( 1 B n ∑ k = 1 n ( X k − μ ) < a ) = Φ ( a ) (3-13) \lim_{n \to \infty}P(\frac{1}{B_n}\sum_{k = 1}^{n}(X_k - \mu) < a) = \Phi(a)\tag{3-13} n→∞limP(Bn1k=1∑n(Xk−μ)<a)=Φ(a)(3-13)
林德伯格中心极限定理对 { X n } \{ X_n \} {Xn} 的约束基本上是最弱的,也就是最强的中心极限定理。
3.3.5 Lyapunov定律
设随机变量 X 1 , X 2 , ⋯ , X n , ⋯ X_1, X_2, \cdots, X_n, \cdots X1,X2,⋯,Xn,⋯ 相互独立,他们具有数学期望和方差:
E ( X k ) = μ k , D ( X K ) = σ k 2 > 0 , k = 1 , 2 , ⋯ (3-14) E(X_k) = \mu_k,\quad D(X_K) = \sigma_{k}^2>0,k = 1, 2, \cdots\tag{3-14} E(Xk)=μk,D(XK)=σk2>0,k=1,2,⋯(3-14)
记 B n 2 = ∑ k = 1 n σ k 2 B_{n}^2 = \sum_{k = 1}^{n} \sigma_{k}^2 Bn2=∑k=1nσk2
若存在正数 δ \delta δ,使得当 n → ∞ n \to \infty n→∞ 时,
1 B n 2 + δ ∑ k = 1 n E { ∣ X k − μ k ∣ 2 + δ } → 0 (3-15) \frac{1}{B_{n}^{2 + \delta}} \sum_{k=1}^{n}E\{{\lvert X_k - \mu_k \rvert }^{2 + \delta}\} \to 0\tag{3-15} Bn2+δ1k=1∑nE{∣Xk−μk∣2+δ}→0(3-15)
则随机变量之和 ∑ k = 1 n X k \sum_{k = 1}^{n}X_k ∑k=1nXk 的标准化变量
Z n = ∑ k = 1 n X k − E ( ∑ k = 1 n X k ) D ( ∑ k = 1 n X k ) = ∑ k = 1 n X k − ∑ k = 1 n μ k B n (3-16) Z_n = \frac{\sum_{k = 1}^{n}X_k - E(\sum_{k = 1}^{n}X_k)}{\sqrt{D(\sum_{k = 1}^{n}X_k)}} = \frac{\sum_{k = 1}^{n}X_k - \sum_{k = 1}^{n}\mu_k}{B_n}\tag{3-16} Zn=D(∑k=1nXk)∑k=1nXk−E(∑k=1nXk)=Bn∑k=1nXk−∑k=1nμk(3-16)
的分布函数 F n ( x ) F_n(x) Fn(x) 对于任意 x x x,满足
lim n → ∞ F n ( x ) = lim n → ∞ P { ∑ k = 1 n X k − ∑ k = 1 n μ k B n ≤ x } = ∫ − ∞ x 1 2 π e − t 2 / 2 d t = Φ ( x ) (3-17) \lim_{n \to \infty}F_n(x) = \lim_{n \to \infty}P\{ \frac{\sum_{k = 1}^{n}X_k - \sum_{k = 1}^{n}\mu_k}{B_n} \leq x\} \\ = \int_{-\infty}^{x}\frac{1}{\sqrt{2 \pi}}e^{-t^2/2}dt = \Phi(x)\tag{3-17} n→∞limFn(x)=n→∞limP{Bn∑k=1nXk−∑k=1nμk≤x}=∫−∞x2π1e−t2/2dt=Φ(x)(3-17)
该定理表明,随机变量
Z n = ∑ k = 1 n X k − ∑ k = 1 n μ k B n (3-18) Z_n = \frac{\sum_{k = 1}^{n}X_k - \sum_{k = 1}^{n}\mu_k}{B_n}\tag{3-18} Zn=Bn∑k=1nXk−∑k=1nμk(3-18)
当 n n n 很大时,近似地服从正态分布 N ( 0 , 1 ) N(0,1) N(0,1)。 由此,当 n n n 很大时, ∑ k = 1 n X k = B n Z n + ∑ k = 1 n μ k \sum_{k = 1}^{n}X_k = B_nZ_n + \sum_{k = 1}^{n}\mu_k ∑k=1nXk=BnZn+∑k=1nμk 近似地服从正态分布 N ( ∑ k = 1 n μ k , B n 2 ) N(\sum_{k = 1}^{n}\mu_k, B_n^2 ) N(∑k=1nμk,Bn2)。这就是说,无论各个随机变量 X k ( k = 1 , 2 , ⋯ ) X_k(k=1, 2, \cdots) Xk(k=1,2,⋯) 服从什么分布,只要满足定理的条件,那么它们的 ∑ k = 1 n X k \sum_{k = 1}^{n}X_k ∑k=1nXk,当 n n n 很大时,就近似地服从正态分布。