一文搞懂【知识蒸馏】【Knowledge Distillation】算法原理
知识蒸馏算法原理精讲
文章目录
- 知识蒸馏算法原理精讲
-
- 1. 什么是知识蒸馏?
- 2. 轻量化网络的方式有哪些?
- 3. 为什么要进行知识蒸馏?
-
- 3.1 提升模型精度
- 3.2 降低模型时延,压缩网络参数
- 3.3 标签之间的域迁移
- 4. 知识蒸馏的理论依据?
- 5. 知识蒸馏分类
-
- 5.1目标蒸馏-Logits方法
- 5.2 特征蒸馏方法
- 6. 知识蒸馏的过程
-
- 6.1 升温(T)操作
- 6.2 温度(T)特点
- 7. 蒸馏损失计算过程
- 8. 知识蒸馏在NLP/CV中的应用
-
- 8.1 目标蒸馏-Logits方法应用
- 8.2 特征蒸馏方法应用
- 9. 知识蒸馏的误区
- 参考文献
1. 什么是知识蒸馏?
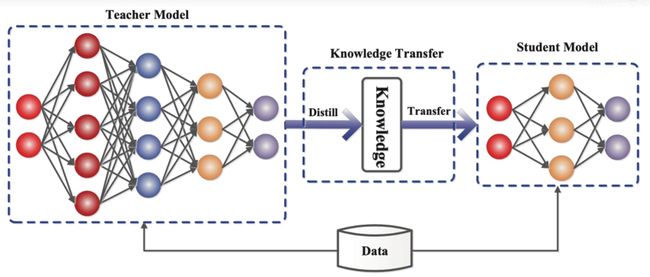
知识蒸馏就是把一个大的教师模型的知识萃取出来,把他浓缩到一个小的学生模型,可以理解为一个大的教师神经网络把他的知识教给小的学生网络,这里有一个知识的迁移过程,从教师网络迁移到了学生网络身上,教师网络一般是比较臃肿,所以教师网络把知识教给学生网络,学生网络是一个比较小的网络,这样就可以用学生网络去做一些轻量化网络做的事情。
2. 轻量化网络的方式有哪些?
- 压缩已训练好的模型:知识蒸馏、权值量化、权重剪枝、通道剪枝、注意力迁移
- 直接训练轻量化网络:SqueezeNet、MobileNetv1v2v3、MnasNet、SHhffleNet、Xception、EfficientNet、EfficieentDet
- 加速卷积运算:im2col+GEMM、Wiongrad、低秩分解
- 硬件部署:TensorRT、Jetson、TensorFlow-Slim、openvino、FPGA集成电路
3. 为什么要进行知识蒸馏?
深度学习在计算机视觉、语音识别、自然语言处理等内的众多领域中均取得了令人难以置信的性能。但是,大多数模型在计算上过于昂贵,无法在移动端或嵌入式设备上运行。因此需要对模型进行压缩,这样小的模型就适用于部署在终端设备上了。
3.1 提升模型精度
如果对目前的网络模型A的精度不是很满意,那么可以先训练一个更高精度的teacher模型B(通常参数量更多,时延更大),然后用这个训练好的teacher模型B对student模型A进行知识蒸馏,得到一个更高精度的A模型。
3.2 降低模型时延,压缩网络参数
如果对目前的网络模型A的时延不满意,可以先找到一个时延更低,参数量更小的模型B,通常来讲,这种模型精度也会比较低,然后通过训练一个更高精度的teacher模型C来对这个参数量小的模型B进行知识蒸馏,使得该模型B的精度接近最原始的模型A,从而达到降低时延的目的。
3.3 标签之间的域迁移
假如使用狗和猫的数据集训练了一个teacher模型A,使用香蕉和苹果训练了一个teacher模型B,那么就可以用这两个模型同时蒸馏出一个可以识别狗、猫、香蕉以及苹果的模型,将两个不同域的数据集进行集成和迁移。
4. 知识蒸馏的理论依据?
知识蒸馏使用的是Teacher—Student模型,其中teacher是“知识”的输出者,student是“知识”的接受者。知识蒸馏的过程分为2个阶段:
- 原始模型训练: 训练"Teacher模型", 简称为Net-T,它的特点是模型相对复杂,也可以由多个分别训练的模型集成而成。我们对"Teacher模型"不作任何关于模型架构、参数量、是否集成方面的限制,唯一的要求就是,对于输入X, 其都能输出Y,其中Y经过softmax的映射,输出值对应相应类别的概率值。
- 精简模型训练: 训练"Student模型", 简称为Net-S,它是参数量较小、模型结构相对简单的单模型。同样的,对于输入X,其都能输出Y,Y经过softmax映射后同样能输出对应相应类别的概率值。
- Teacher学习能力强,可以将它学到的知识迁移给学习能力相对弱的Student模型,以此来增强Student模型的泛化能力。复杂笨重但是效果好的Teacher模型不上线,就单纯是个导师角色,真正部署上线进行预测任务的是灵活轻巧的Student小模型。
5. 知识蒸馏分类
知识蒸馏是对模型的能力进行迁移,根据迁移的方法不同可以简单分为基于目标蒸馏(也称为Soft-target蒸馏或Logits方法蒸馏)和基于特征蒸馏的算法两个大的方向。
5.1目标蒸馏-Logits方法
分类问题的共同点是模型最后会有一个softmax层,其输出值对应了相应类别的概率值。在知识蒸馏时,由于我们已经有了一个泛化能力较强的Teacher模型,我们在利用Teacher模型来蒸馏训练Student模型时,可以直接让Student模型去学习Teacher模型的泛化能力。一个很直白且高效的迁移泛化能力的方法就是:使用softmax层输出的类别的概率来作为“Soft-target” 。
5.1.1 Hard-target 和 Soft-target
注:soft target“软标签”指的是大网络在每一层卷积后输出的特征映射。
5.1.1.1 Hard-target和 Soft-target的区别
传统training过程(hard targets): 对ground truth求极大似然
(原始数据集标注的 one-shot 标签,除了正标签为 1,其他负标签都是 0。)
KD的training过程(soft targets): 用large model的class probabilities作为soft targets
(Teacher模型softmax层输出的类别概率,每个类别都分配了概率,正标签的概率最高,并且标签都以小数分布,0.1,0.35.,0.6。)
5.1.1.2 KD的训练过程为什么更有效?
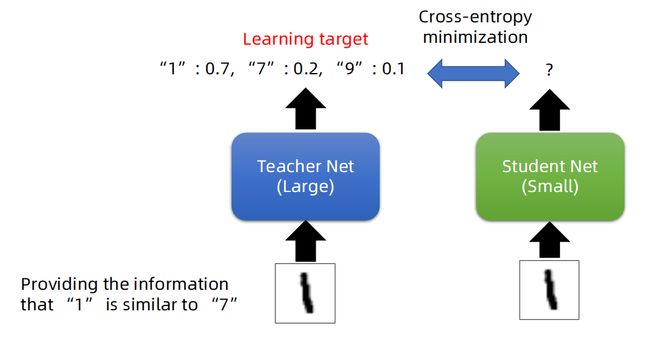
以手写数字为例,教师网络对数字 1 1 1的预测标签为 " 1 " : 0.7 , " 7 " : 0.2 , " 9 " : 0.1 "1":0.7,"7":0.2 ,"9":0.1 "1":0.7,"7":0.2,"9":0.1,这里1的预测概率最大为 0.7 0.7 0.7 是正确的分类,但是标签 " 7 " " 9 " "7""9" "7""9"的预测概率也能提供一些信息,就是说 " 7 " , " 9 " "7","9" "7","9"和预测标签 1 1 1还是有某种预测的相似度的。如果把这个信息也教会学生网络,学生网络就可以了解到这种类别之间的相似度,可以看作为学习到了教师网络中隐藏的知识,对于学生网络的分类是有帮助的。
综上:
(1)在使用Soft-target训练时,Student模型可以很快学习到Teacher模型的推理过程。
(2)传统的Hard-target的训练方式,所有的负标签都会被平等对待。Soft-target给Student模型带来的信息量要大于Hard-target,并且Soft-target分布的熵相对高时,其Soft-target蕴含的知识就更丰富。
(3)使用Soft-target训练时,梯度的方差会更小,训练时可以使用更大的学习率,所需要的样本也更少。
这也解释了为什么通过蒸馏的方法训练出的Student模型相比使用完全相同的模型结构和训练数据只使用Hard-target的训练方法得到的模型,拥有更好的泛化能力。
5.2 特征蒸馏方法
-
它不像Logits方法那样,
Student只学习Teacher的Logits这种结果知识,而是学习Teacher网络结构中的中间层特征。它强迫Student某些中间层的网络响应,要去逼近Teacher对应的中间层的网络响应。这种情况下,Teacher中间特征层的响应,就是传递给Student的知识,本质是Teacher将特征级知识迁移给Student。 -
既宽又深的模型通常需要大量的乘法运算,从而导致对内存和计算的高需求。为了解决这类问题,我们需要通过模型压缩(也称为知识蒸馏)将知识从复杂的模型转移到参数较少的简单模型。到目前为止,知识蒸馏技术已经考虑了
Student网络与Teacher网络有相同或更小的参数。这里有一个洞察点是,深度是特征学习的基本层面,到目前为止尚未考虑到Student网络的深度。一个具有比Teacher网络更多的层但每层具有较少神经元数量的Student网络称为“thin deep network”。因此,该篇论文主要针对Hinton提出的知识蒸馏法进行扩展,允许
Student网络可以比Teacher网络更深更窄,使用teacher网络的输出和中间层的特征作为提示,改进训练过程和student网络的性能。
6. 知识蒸馏的过程
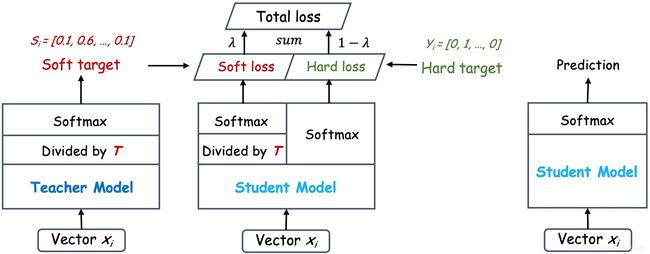
如上图所示,教师网络(左侧)的预测输出除以温度参数(Temperature)之后、再做Softmax计算,可以获得软化的概率分布(软目标或软标签),数值介于 0 − 1 0-1 0−1之间,取值分布较为缓和。Temperature数值越大,分布越缓和;而Temperature数值减小,容易放大错误分类的概率,引入不必要的噪声。针对较困难的分类或检测任务,Temperature通常取 1 1 1,确保教师网络中正确预测的贡献。硬目标则是样本的真实标注,可以用One-hot矢量表示。Total loss设计为软目标与硬目标所对应的交叉熵的加权平均(表示为KD loss与CE loss),其中软目标交叉熵的加权系数越大,表明迁移诱导越依赖教师网络的贡献,这对训练初期阶段是很有必要的,有助于让学生网络更轻松的鉴别简单样本,但训练后期需要适当减小软目标的比重,让真实标注帮助鉴别困难样本。另外,教师网络的预测精度通常要优于学生网络,而模型容量则无具体限制,且教师网络推理精度越高,越有利于学生网络的学习。
教师网络与学生网络也可以联合训练,此时教师网络的暗知识及学习方式都会影响学生网络的学习,具体如下(式中三项分别为教师网络Softmax输出的交叉熵loss、学生网络Softmax输出的交叉熵loss、以及教师网络数值输出与学生网络Softmax输出的交叉熵loss)
6.1 升温(T)操作
蒸馏的时候一般都需要进行升温操作,以分类网络为例,需要改进softmax,除以T
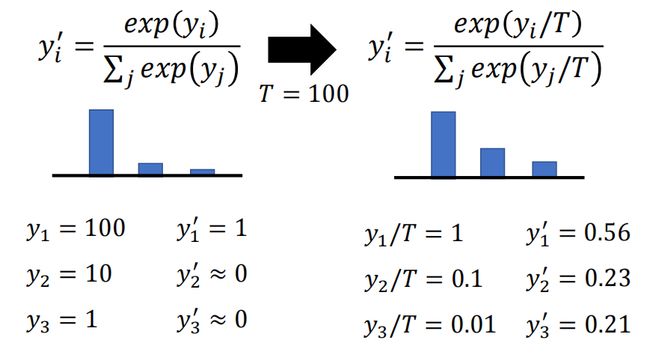
左边是正常的softmax计算,右边引入一个超参T来计算softmax ,即把 y i y_i yi 都除以T再进行softmax计算。结果会有什么不同呢?
假设左边的 y 1 , y 2 , y 3 y1,y2,y3 y1,y2,y3的分类结果,分别是 100 , 10 , 1 100,10,1 100,10,1,没有进行升温操作,带入 softmax 之后 y 1 ‘ y_1^‘ y1‘接近1, y 1 ‘ y_1^‘ y1‘ 和 y 2 ‘ y_2^‘ y2‘ y 3 ‘ y_3^‘ y3‘都接近于0。经过升温操作之后, y 1 ‘ = 0.56 y_1^‘=0.56 y1‘=0.56, y 2 ‘ = 0.23 y_2^‘ =0.23 y2‘=0.23, y 3 ‘ = 0.21 y_3^‘=0.21 y3‘=0.21。此时 y 1 ‘ y_1^‘ y1‘, y 2 ‘ y_2^‘ y2‘, y 3 ‘ y_3^‘ y3‘ 之间的差异就没有那么大了,也就是说能够把类别之间隐藏的关系给暴露出来,所以做蒸馏操作一般都需要除以 T 来进行升温操作。
6.2 温度(T)特点
-
原始的softmax函数是
T=1时的特例;T<1时,概率分布比原始更“陡峭”,也就是说,当T>0时,Softmax的输出值会接近于Hard-target;T>1时,概率分布比原始更“平缓”。 -
随着T的增加,
Softmax的输出分布越来越平缓,信息熵会越来越大。温度越高,softmax上各个值的分布就越平均,思考极端情况,当 ,此时softmax的值是平均分布的。 -
不管温度T怎么取值,
Soft-target都有忽略相对较小的(Teacher模型在温度为T时softmax输出在第i类上的值)携带的信息的倾向。 -
温度的高低改变的是
Student模型训练过程中对负标签的关注程度。当温度较低时,对负标签的关注,尤其是那些显著低于平均值的负标签的关注较少;而温度较高时,负标签相关的值会相对增大,Student模型会相对更多地关注到负标签。 -
实际上,负标签中包含一定的信息,尤其是那些负标签概率值显著高于平均值的负标签。但由于
Teacher模型的训练过程决定了负标签部分概率值都比较小,并且负标签的值越低,其信息就越不可靠。因此温度的选取需要进行实际实验的比较,本质上就是在下面两种情况之中取舍:-
当想从负标签中学到一些信息量的时候,温度应调高一些;
-
当想减少负标签的干扰的时候,温度 应调低一些;
-
总的来说,温度的选择和Student模型的大小有关,Student模型参数量比较小的时候,相对比较低的温度就可以了。因为参数量小的模型不能学到所有Teacher模型的知识,所以可以适当忽略掉。
7. 蒸馏损失计算过程

在分类网络中知识蒸馏的 Loss 计算
- 上部分教师网络,它进行预测的时候,
softmax要进行升温,升温后的预测结果我们称为软标签(soft label) - 学生网络一个分支
softmax的时候也进行升温,在预测的时候得到软预测(soft predictions),然后对soft label和soft predictions计算损失函数,称为distillation loss,让学生网络的预测结果接近教师网络; - 学生网络的另一个分支,在
softmax的时候不进行升温T =1,此时预测的结果叫做hard prediction。然后和hard label也就是ground truth直接计算损失,称为student loss。 - 总的损失结合了
distilation loss和student loss,并通过系数a加权,来平衡这两种Loss,比如与教师网络通过MSE损失,学生网络与ground truth通过cross entropy损失,Loss的公式可表示如下:
L = ( 1 − α ) ⋅ L M S E K D + α ⋅ L C E K D \mathcal{L}=(1-\alpha) \cdot \mathcal{L}_{\mathrm{MSE}}^{\mathrm{KD}}+\alpha \cdot \mathcal{L}_{\mathrm{CE}}^{\mathrm{KD}} L=(1−α)⋅LMSEKD+α⋅LCEKD
8. 知识蒸馏在NLP/CV中的应用
8.1 目标蒸馏-Logits方法应用
- 《Distilling the Knowledge in a Neural Network 》,NIPS,2014。
- 《Deep Mutual Learning》,CVPR,2018。
- 《Born Again Neural Networks》,CVPR,2018。
- 《Distilling Task-Specific Knowledge from BERT into Simple Neural Networks》,2019。
8.2 特征蒸馏方法应用
- 《FitNets: Hints for Thin Deep Nets》,ICLR,2015。
- 《Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer》, ICLR,2017。
- 《A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning》,CVPR,2017。
- 《Learning Efficient Object Detection Models》,NIPS,2017。
9. 知识蒸馏的误区
不要认为学生模型通过蒸馏就可以达到教师模型的水平的,知识蒸馏的学生网络是很难达到和教师模型性能相同的水准的。
参考文献
[1] 【精读AI论文】知识蒸馏_哔哩哔哩_bilibili
[2] 介绍知识蒸馏_距离百年老店还有92年的博客-CSDN博客
[3] 3分钟了解知识蒸馏的认知误区_哔哩哔哩_bilibili
[4] 知识蒸馏(Knowledge Distillation)_Law-Yao的博客-CSDN博客_知识蒸馏