Python技巧分享:groupby 的基础用法这篇太详细了吧
大家好,本文介绍的是分组 groupby 用法
文章目录
-
- 模拟数据
- groupby+单个字段+单个聚合
- groupby+单个字段+多个聚合
-
- 方法1:使用groupby+merge
- 方法2:使用groupby+agg
- groupby+多个字段+单个聚合
- groupby+多个字段+多个聚合
模拟数据
import pandas as pd
import numpy as np
employees = ["小明","小周","小孙","小王","小张"] # 5位员工
time = ["上半年", "下半年"]
df=pd.DataFrame({
"employees":np.random.choice(employees,10), # 在员工中重复选择10次
# 另一种写法
#"employees":[employees[x] for x in np.random.randint(0,len(employees),10)],
"time":np.random.choice(time,10),
"salary":np.random.randint(800,1000,10), # 800-1000之间的薪资选择10个数值
"score":np.random.randint(6,12,10) # 6-11的分数选择10个
})
df

groupby+单个字段+单个聚合
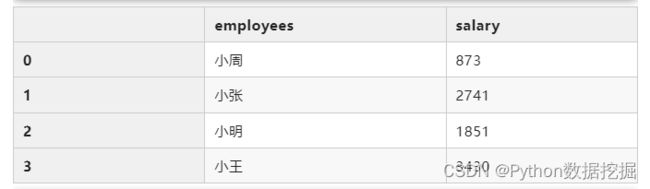
求解每个人的总薪资金额:
total_salary = df.groupby("employees")["salary"].sum().reset_index()
total_salary

使用agg也能够实现上面的效果:
df.groupby("employees").agg({"salary":"sum"}).reset_index()

df.groupby("employees").agg({"salary":np.sum}).reset_index()
groupby+单个字段+多个聚合
求解每个人的总薪资金额和薪资的平均数:
方法1:使用groupby+merge
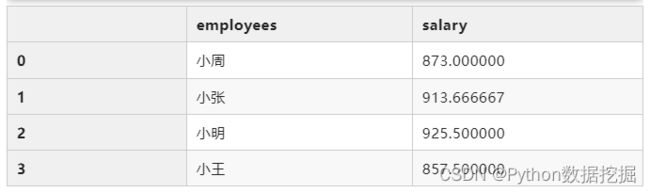
mean_salary = df.groupby("employees")["salary"].mean().reset_index()
mean_salary
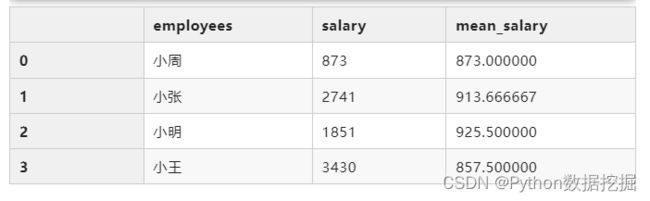
然后将上面的两个结果进行组合;在合并之前为了字段的名字更加的直观,我们重命名下:
total_salary.rename(columns={"employees":"total_salary"})
mean_salary.columns = ["employees","mean_salary"]
total_mean = total_salary.merge(mean_salary)
total_mean
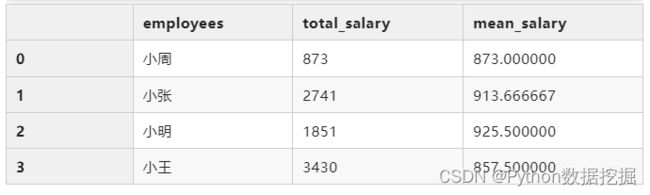
方法2:使用groupby+agg
total_mean = df.groupby("employees")\
.agg(total_salary=("salary", "sum"),
mean_salary=("salary", "mean"))\
.reset_index()
total_mean
groupby+多个字段+单个聚合
针对多个字段的同时聚合:
df.groupby(["employees","time"])["salary"].sum().reset_index()
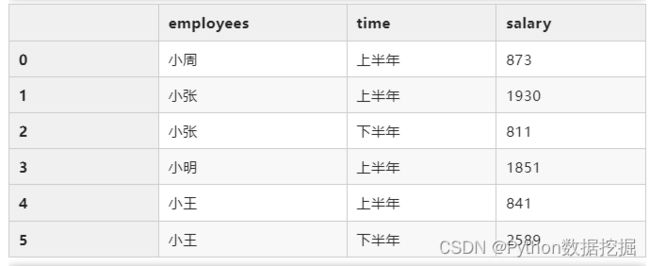
# 使用agg来实现
df.groupby(["employees","time"]).agg({"salary":"sum"}).reset_index()
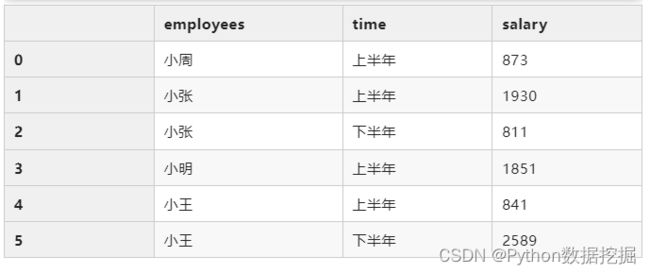
groupby+多个字段+多个聚合
使用的方法是:
agg(’新列名‘=(’原列名‘, ’统计函数/方法‘))
df.groupby(["employees","time"])\
.agg(total_salary=("salary", "sum"),
mean_salary=("salary", "mean"),
total_score=("score", "sum")
)\
.reset_index()
