文档级关系抽取:基于结构先验产生注意力偏差SSAN模型
文档级关系抽取:基于结构先验产生注意力偏差SSAN模型
Entity Structure Within and Throughout: Modeling Mention Dependencies for Document-Level Relation Extraction
实体作为关系抽取任务的基本要素,具有一定的结构。在这项工作中,将这种结构表述为提及对之间的独特依赖关系。提出了SSAN (Structured Self-Attention Network) ,它将这些结构依赖性纳入标准的自我注意机制和整个编码阶段。在每个自注意力构建块内设计了两个替代转换模块,以产生注意力偏差,从而自适应地调整其注意力流。实验证明了所提出的实体结构的有用性和 SSAN 的有效性。

参考链接:
https://arxiv.org/abs/2102.10249
https://github.com/PaddlePaddle/Research/tree/master/KG/AAAI2021_SSAN
https://github.com/PaddlePaddle/ERNIE/tree/repro
0.相关知识补充
0.1 信息抽取面临困难
文档级关系抽取主要面临以下三个挑战:
-
相同关系会出现在多个句子。在文档级关系抽取中,单一关系可能出现在多个输入的句子中,因此模型需要依赖多个句子进行关系推断。
-
相同实体会具有多个指称。在复杂的文档中,同一个实体具有各种各样的指称,因此模型需要聚合不同的指称学习实体表示。
-
不同的实体之间的关系需要逻辑推理。文档包含多个实体关系三元组,不同的实体关系三元组之间存在逻辑关联,因此模型需要具备一定的逻辑推理能力。
信息抽取是构建大规模知识图谱的必备关键,先来说一下图谱的三元组形式,在以往常常将三元组以 (head,relation, tail) 的形式表示,在这里以(subject, relation, object)的形式表示,即(S, R,O),为了方便描述,后文将以这种形式阐述。
信息抽取分为两大部分,一部分是命名实体识别,识别出文本中的实体,另外就是关系抽取,对识别出来的实体构建对应的关系,两者便是构建三元组的基本组成。在以往的研究工作中,早期两个任务以pipline的方式进行,先做命名实体识别,然后做关系抽取。但是pipline的流程可能造成实体的识别错误,也就造成关系构建的错误,所以后续的一些研究工作将两者采用联合学习的方式。
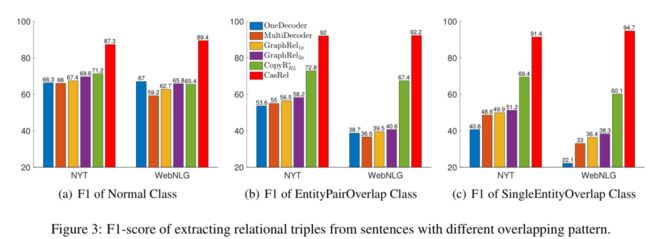
但是上述存在很少的研究工作解决三元组重叠的问题:
-
Normal: 代表没有重叠的部分。
-
EPO(EntityPairOverlap): 关系两端的实体都是一致的,例如 QT 既在电影 DU 中扮演角色,又是电影 DU 的执导。
-
SEO(SingleEntityOverlap): 关系两端只有单个实体共享,图中的例子,从小范围来说,JRB 出生在 Washington, 但是 Washington 是 USA 的首都,所以也可以说 JRB 出生在 USA。

以往工作的不足以及重叠三元组出现的挑战:
-
在实体对的组合之中,大多数实体对是没有关系链接的,这便存在很多的负例,也就造成了关系分类的不平衡。
-
重叠三元组的问题更是一个难点,因为其存在共享的实体,甚至两个实体存在多种关系,这便增加了难度,没有足够的训练数据,是难以学习或者根本无法学习这种关系的。
0.2 如何去解决
思想:采用全新的视角代替以往分类的视角,将关系建模为 S 到 O 的映射函数。提出一个全新的框架:CASREL。
ACL2020 关系抽取框架 :A Novel Cascade Binary Tagging Framework for Relational Triple Extraction (一种用于关系三元组提取的新型级联二元标签框架)
论文链接:https://aclanthology.org/2020.acl-main.136/
从非结构化文本中提取关系型三元组对于大规模知识图谱的构建至关重要。然而,现有的工作在解决重叠三联体问题上表现出色,即同一句子中的多个关系三联体共享相同的实体。引入了一个新的视角来重新审视关系型三联体的提取任务,并提出了一个新颖的级联二元标签框架(CasRel),该框架源自一个原则性的问题表述。新框架没有像以前的工作那样将关系视为离散的标签,而是将关系建模为函数,将句子中的主体映射到对象,这就自然地处理了重叠问题。实验表明,即使在其编码器模块使用随机初始化的BERT编码器时,CasRel框架已经超过了最先进的方法,显示了新标签框架的力量。当采用预训练的BERT编码器时,它的性能得到了进一步的提升,在两个公共数据集NYT和WebNLG上的F1分数绝对值分别比最强的基线高出17.5和30.2。
框架详解
CASREL框架抽取三元组(subject, relation, object)主要包含两个步骤,三个部分。
两个步骤:
第一步要识别出句子中的 subject 。
第二部要根据识别出的 subject, 识别出所有有可能的 relation 以及对应的 object。
三个部分:
BERT-based encoder module: 可以替换为不同的编码框架,主要对句子中的词进行编码,论文最终以BERT为主,效果很强。
subject tagging module:目的是识别出句子中的 subject。
relation-specific object tagging module:根据 subject,寻找可能的 relation 和 object。
其中 a 是 Encoder, b 和 c 称为 Cascade Decoder

BERT Encoder
这部分的就是对句子编码,获取每个词的隐层表示,可以采用 BERT 的任意一层,另外这部分是可以替换的,例如用 LSTM 替换 BERT。
Subject Tagger
这部分的主要作用是对 BERT Encoder 获取到的词的隐层表示解码,构建两个二分类分类器预测 subject 的 start 和 end 索引位置,对每一个词计算其作为 start 和 end 的一个概率,并根据某个阈值,大于则标记为1,否则标记为0
如框架图中所示,Jackie 被标记为 start,R 既不是 start 也不是 end, Brown 被标记为 end,其他的类似。在这里采用了最近匹配的原则,即与 jackie 最近的一个 end 词是 Brown, 所以 Jackie R. Brown 被识别为一个subject。文中并未考虑前面位置的情况。
Relation-specific Object Taggers
这部分会同时识别出 subject 的 relation 和相关的 object。
解码的时候比 Subject Tagger 不仅仅考虑了 BERT 编码的隐层向量, 还考虑了识别出来的 subject 特征,即下图。vsub 代表 subject 特征向量,若存在多个词,将其取向量平均,hn 代表 BERT 编码向量。
我们以图中的例子详细说明一下,图中的例子仅仅画出了第一个 subject 的过程,即 Jackie R. Brown,对于这个,在关系 Birth_place 中识别出了两个 object,即 Washington 和 United States Of America,而在其他的关系中未曾识别出相应的 object。当对 Washington 这个 subject 解码时,仅仅在 Capital_of 的关系中识别出 对应的 object: United States Of America。
以上我们便可以得到抽取到的三个三元组如下:
(Jackie R. Brown, Birth_place, Washington)
(Jackie R. Brown, Birth_place, United States Of America)
(Washington, Capital_of, United States Of America)
从以上抽取出来的三元组,确实解决了最开始提到的 SEO 和 EPO 的重叠问题。
实验效果
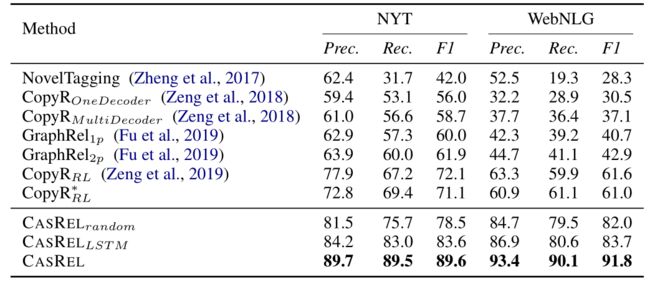
验证CASREL框架效果采用的是两个公开的数据集,NYT 和 WebNLG。
具体的实验效果如下,其中 CASREL 分别采用了 随机初始化参数的BERT编码端、 LSTM 编码端以及预训练 BERT 编码端,实验结果主要说明以下结论:
-
CASREL 框架确实有效,三种编码结构的效果都是要远高于其他的模型性能。
-
采用预训练 BERT 之后,CASREL 框架更是逆天。
最后附上开源码源:
https://github.com/weizhepei/CasRel
https://github.com/weizhepei/BERT-NER
0.3相关领域经典文章推荐:
1.基于知识图谱嵌入的链接预测综述(Knowledge Graph Embedding for Link Prediction: A Comparative Analysis)2021
知识图谱 (KGs) 在工业和学术环境中发现了许多应用,这反过来又推动了从各种来源进行大规模信息提取的大量研究工作。尽管做出了这些努力,但众所周知,即使是最先进的 KG 也存在不完整的问题。链接预测 (LP) 是在已经是 KG 的实体中预测缺失事实的任务,是一项有前途且被广泛研究的任务,旨在解决 KG 的不完整性。在最近的 LP 技术中,基于 KG 嵌入的技术在一些基准测试中取得了非常有希望的性能。尽管该主题的文献快速增长,但对这些方法中各种设计选择的影响关注不足。而且,该领域的标准做法是通过汇总大量测试事实来报告准确性,其中某些实体被过度代表;这允许 LP 方法通过只关注包含此类实体的结构属性来展示良好的性能,同时忽略 KG 的剩余大部分。该分析提供了基于嵌入的 LP 方法的全面比较,将分析的维度扩展到了文献中通常可用的范围之外。我们通过实验比较了 16 种最先进方法的有效性和效率,考虑了基于规则的基线,并报告了对文献中最流行的基准的详细分析。这允许 LP 方法通过只关注包含此类实体的结构属性来展示良好的性能,同时忽略 KG 的剩余大部分。该分析提供了基于嵌入的 LP 方法的全面比较,将分析的维度扩展到了文献中通常可用的范围之外。我们通过实验比较了 16 种最先进方法的有效性和效率,考虑了基于规则的基线,并报告了对文献中最流行的基准的详细分析。这允许 LP 方法通过只关注包含此类实体的结构属性来展示良好的性能,同时忽略 KG 的剩余大部分。该分析提供了基于嵌入的 LP 方法的全面比较,将分析的维度扩展到了文献中通常可用的范围之外。我们通过实验比较了 16 种最先进方法的有效性和效率,考虑了基于规则的基线,并报告了对文献中最流行的基准的详细分析。
论文链接:https://arxiv.org/abs/2002.00819
https://blog.csdn.net/u011983997/article/details/122948242
2. Modeling Relational Data with Graph Convolutional Networks,知识图谱推理–混合神经网络与分布式表示推理 2017
知识图谱支持广泛的应用,包括问答和信息检索。尽管在它们的创建和维护上投入了巨大的努力,但即使是最大的(例如,Yago、DBPedia 或 Wikidata)仍然不完整。我们引入了关系图卷积网络(R-GCNs)并将它们应用于两个标准的知识库完成任务:链接预测(缺失事实的恢复,即主体-谓词-对象三元组)和实体分类(缺失实体属性的恢复)。R-GCNs 与最近一类在图上运行的神经网络有关,并且是专门为处理现实知识库的高度多关系数据特征而开发的。我们证明了 R-GCNs 作为实体分类的独立模型的有效性。
论文链接:https://arxiv.org/abs/1703.06103

为了完成上述任务,这篇论文实现:
实体分类模型:图中每个结点使用softmax分类器,分类器接受RGCN提供的结点表示,并且进行预测标签。
链路预测模型:编码器,RGCN产生实体潜在特征表示;解码器,一个张量因子分解模型利用这些表示来预测标记的边缘,因式分解方法:distmult.
主要贡献:
- 1.是第一个证明GCN框架可以应用于关系数据建模的人,特别是链接预测和实体分类任务。
- 2.引入了参数共享和加强稀疏约束的技术,并利用它们将R-GCNs应用于具有大量关系的多图。
- 3.以DistMult为例,作者证明了因子分解模型的性能可以通过在关系图中执行多个信息传播步骤的编码器模型来丰富它们
3. 在知识库中嵌入实体和关系以进行学习和推理(Embedding Entities and Relations for Learning and Inference in Knowledge Bases)2014
我们考虑使用神经嵌入方法学习知识库中实体和关系的表示。我们展示了大多数现有模型,包括 NTN (Socher et al., 2013) 和 TransE (Bordes et al., 2013b),可以在统一的学习框架下进行泛化,其中实体是从神经网络学习的低维向量,并且关系是双线性和/或线性映射函数。在这个框架下,我们比较了链接预测任务上的各种嵌入模型。我们展示了一个简单的双线性公式为该任务实现了新的最先进的结果(在 Freebase 上实现了 73.2% 与 54.7% 的前 10 名准确率)。此外,我们引入了一种新颖的方法,该方法利用学习到的关系嵌入来挖掘逻辑规则,例如“BornInCity(a,b) 和 CityInCountry(b,c) => Nationality(a,c)”。我们发现从双线性目标中学习的嵌入特别擅长捕捉关系语义,并且关系的组合以矩阵乘法为特征。更有趣的是,我们证明了我们的基于嵌入的规则提取方法在挖掘涉及组合推理的 Horn 规则时成功地优于最先进的基于置信度的规则挖掘方法。
论文链接:https://arxiv.org/abs/1412.6575
- 3.1 推理任务一:链接预测
破坏掉三元组,对于测试数据中的每个三元组,我们将每个实体视为要依次预测的目标实体。将为字典中正确的实体和所有损坏的实体计算分数,并按降序排列。采用hit@n,mrr,mr等信息作为评估方式。
其在实现时,提出一些改善
相比于TransE这种模型,引用了非线性函数t a n h tanhtanh函数
使用了预训练的方法进行embedding,通过word2vec方式
- 3.2 推理任务二:规则抽取
规则抽取,这种逻辑规则有四个重要目的,其目的如下:
- 首先,他们可以帮助推断新的事实,完善现有的K B s KBsKBs。
- 其次,它们可以通过只存储规则而不是大量的扩展数据来帮助优化数据存储,并且只在推理时生成事实。
- 第三,它们可以支持复杂的推理。
- 最后,它们可以为推理结果提供解释,例如,我们可以推断人们的职业通常涉及他们研究的领域的专业化,等等。
1.数据集介绍和获取
目前文档级关系抽取有三个公开的学术的数据集,分别是 CDR、GDA 以及清华大学团队发布的 DocRED。
- CDR是生物领域的一个人工标注的一个数据集,其任务是预测化学和疾病概念之间的二元相互作用,包含了 500 多篇训练文章;(20MB)
- GDA 也是一个生物医学领域的大规模数据集,其任务主要是预测基因和疾病概念之间的二元相互作用,由 2 万~3 万篇训练文档组成;相对而言,(568MB)
- DocRED 是一个比较新的大规模的众包数据集。其原始语料主要基于维基百科,包含了 3053 份文章,其中大约存在 7% 的实体,DocRED 还提供了公开的 leaderboard,用户可将模型预测的结果上传,评估文档级关系抽取的各种性能。(160MB)
目前,针对这种文档及关系抽取,主要有两类研究方法,一类是基于文档图的方法;另一类是基于序列的方法,基于 Transformer 等模型来进行文档级的关系抽取。

1.1 DocRED数据集
DocRED: A Large-Scale Document-Level Relation Extraction Dataset:https://arxiv.org/abs/1906.06127v3
DocRED:
https://github.com/thunlp/DocRED
2019年的ACL上清华大学刘知远团队提出了一个关系抽取数据集DocRED[1],为文档级关系抽取的研究提供了一个非常好的标注数据集。DocRED包含对超过5000篇Wikipedia文章的标注,包括96种关系类型、143,375个实体和56,354个关系事实,这在规模上超越了以往的同类精标注数据集。与传统的基于单句的关系抽取数据集相比,DocRED中超过40%的关系事实只能从多个句子中联合抽取,因此需要模型具备较强的获取和综合文章中信息的能力,尤其是抽取跨句关系的能力。DocRED还有一个在线的Leaderboard
https://competitions.codalab.org/competitions/20717#results
排行榜如下:

下载一下即可。
1.2 CDR&GDA数据集:
https://github.com/fenchri/edge-oriented-graph/tree/reproduceEMNLP
CDR是生物医学领域的人类标注的化学疾病关系抽取数据集,由500份文档组成,该数据集的任务是预测化学和疾病概念之间的二元相互作用关系。
GDA是生物医学领域的一个大规模数据集,它包含29192篇文档以供训练,其任务是预测基因和疾病概念之间的二元相互作用。
文档级关系抽取方法归纳-参考链接:
https://zhuanlan.zhihu.com/p/428119149
https://blog.csdn.net/qq_27590277/article/details/118005349
https://blog.csdn.net/qq_27590277/article/details/118005433