【研一小白论文精读】Joint Generative and Contrastive Learning for Unsupervised Person Re-identification
Abstract
就是将GAN和对比学习模块结合起来,对比学习不是需要数据增强吗,就用GAN的视图生成器来做这个增强,还提出了一种对比学习的损失函数,实验也证明取得了SOTA。
Introduction
ReID的目标是从不同视图中识别物体,也即是根据可视化相似度从gallery中识别query,gallery和query其实就是对比学习中的两个试图,也是一大一小数据集和样本这样的一个关系。直白一点就是左边是传统对比学习的方法,只不过右边用GAN来代替数据增强的这种方法。。
这个生成器不是普通的生成器,作者先从无标签的数据集上生成了一种网状结构,之前的方法总是忽视这个人身材,这种网就可以联合得恢复身材和姿势,然后这个生成器就可以生成非常好的视图。一旦得到新的视图,我们就可以设计一些基于对比学习的伪标签,结合我们提出的损失函数最大化原始视图和生成视图之间的相似度。
对比学习和GAN是一起一起训练的,这是一个相互促进的过程,可以提高生成的质量。
**1.**提出了一种联合模型,将对比学习和GAN结合在一起。
**2.**在这个模型的生成器部分使用了网结构,和之前的方法对比不仅能考虑到人的姿势还能考虑到人的身材。
**3.**在对比学习模块中提出了一种视图不变的损失函数。
**4.**克服了以前基于gan的无监督ReID方法的局限性,这些方法严重依赖于标记源数据集,并且SOTA。
The method
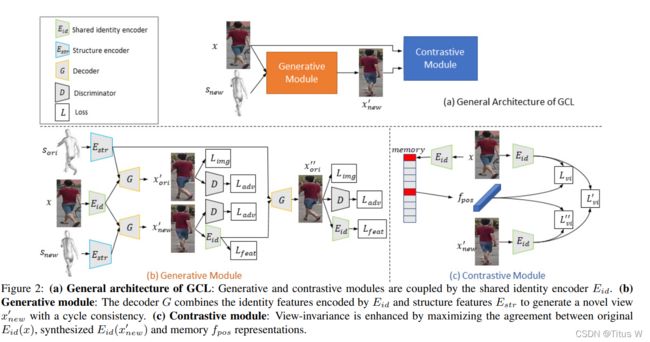
View Generator
首先我们定义一个3D网络中的一个2D平面作为原始的基础平面Sori,我们分别旋转3d网络,并且继续随机选择一个二维投影作为一个新的平面Snew。其实目的就是使用3D模型旋转来模拟不同角度照相机。Sori,x,Snew分别得到的represention两两结合通过编码器得到两个表示,结合各自的判别器,其实也就是生成了两种数据。第一种网格和第二种数据的表示结合起来再次生成一个最终表示。
整个过程有如下几个优化目标:
1.视图的重构损失
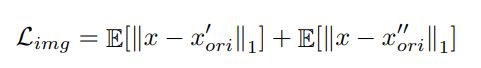
2.特征的重构损失
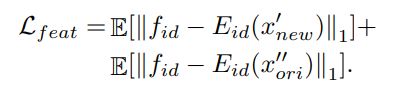
3.GAN的对抗损失
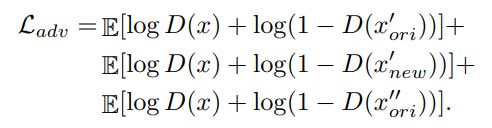
最后相加就是这一阶段的总体优化目标
![]()
View Contrast
这里使用了memory bank,可以稳定伪标签和扩大负样本的数量,而且这个memory bank也是通过一个动量的方式去更新的。我们使用一种聚类的算法去生成伪标签,通过得到伪标签,我们可以定义正样本和负样本。给定一个图像x,我们从memory bank中随机抽取K个具有不同伪标签的实例和一个与x具有相同伪标签的实例表示fpos。f,fnew,fpos三个两两之间组成正样本对,fnew和K个实例组成负样本对。损失函数呢其实还是传统的InferNCE,因为正样本对有三组,三组之间两两互相结合,负样本对就那一组,三个函数嘛很简单,都加起来。因为最后是联合训练,所以再把上述两个加起来就是最后的损失函数。## Abstract
就是将GAN和对比学习模块结合起来,对比学习不是需要数据增强吗,就用GAN的视图生成器来做这个增强,还提出了一种对比学习的损失函数,实验也证明取得了SOTA。
Introduction
ReID的目标是从不同视图中识别物体,也即是根据可视化相似度从gallery中识别query,gallery和query其实就是对比学习中的两个试图,也是一大一小数据集和样本这样的一个关系。直白一点就是左边是传统对比学习的方法,只不过右边用GAN来代替数据增强的这种方法。。
这个生成器不是普通的生成器,作者先从无标签的数据集上生成了一种网状结构,之前的方法总是忽视这个人身材,这种网就可以联合得恢复身材和姿势,然后这个生成器就可以生成非常好的视图。一旦得到新的视图,我们就可以设计一些基于对比学习的伪标签,结合我们提出的损失函数最大化原始视图和生成视图之间的相似度。
对比学习和GAN是一起一起训练的,这是一个相互促进的过程,可以提高生成的质量。
**1.**提出了一种联合模型,将对比学习和GAN结合在一起。
**2.**在这个模型的生成器部分使用了网结构,和之前的方法对比不仅能考虑到人的姿势还能考虑到人的身材。
**3.**在对比学习模块中提出了一种视图不变的损失函数。
**4.**克服了以前基于gan的无监督ReID方法的局限性,这些方法严重依赖于标记源数据集,并且SOTA。
The method
View Generator
首先我们定义一个3D网络中的一个2D平面作为原始的基础平面Sori,我们分别旋转3d网络,并且继续随机选择一个二维投影作为一个新的平面Snew。其实目的就是使用3D模型旋转来模拟不同角度照相机。Sori,x,Snew分别得到的represention两两结合通过编码器得到两个表示,结合各自的判别器,其实也就是生成了两种数据。第一种网格和第二种数据的表示结合起来再次生成一个最终表示。
整个过程有如下几个优化目标:
1.视图的重构损失
2.特征的重构损失
3.GAN的对抗损失
最后相加就是这一阶段的总体优化目标
![]()
View Contrast
这里使用了memory bank,可以稳定伪标签和扩大负样本的数量,而且这个memory bank也是通过一个动量的方式去更新的。我们使用一种聚类的算法去生成伪标签,通过得到伪标签,我们可以定义正样本和负样本。给定一个图像x,我们从memory bank中随机抽取K个具有不同伪标签的实例和一个与x具有相同伪标签的实例表示fpos。f,fnew,fpos三个两两之间组成正样本对,fnew和K个实例组成负样本对。损失函数呢其实还是传统的InferNCE,因为正样本对有三组,三组之间两两互相结合,负样本对就那一组,三个函数嘛很简单,都加起来。因为最后是联合训练,所以再把上述两个加起来就是最后的损失函数。
第一次读综述不知道,其实用思维导图比直接读综述更好。而且这篇论文就像我的第一个课题的课本一样。
Abstract
这好像是一篇综述,就说SSL方法的表现都很好,并且能胜任很多downstream task,应用在视觉、NLP、还有图学习上。本文主要根据SSL的目标将SSL划分为3类:生成、对比、生成加对比(也叫对抗)。并且SSL为什么能work起来有更深的思考,最后简单的地讨论了SSL未来的方向。
Introduction
自监督学习好啊,在三个领域已经很强了,但是手动标签、泛化误差,虚假的相关性、对抗攻击有很强的依赖性。利用不同输入型号之间的相关性自动标签。自监督学习的特征有二:1.通过半自动的方式从数据本身获取标签。2.数据之间的相互预测。人们经常混淆自监督学习和无监督学习,首先自监督学习属于无监督学习,因为确实没有使用手工标签。然而真正的无监督学习主要方向还是检测这一类,例如聚类降维这些,但是自监督的主要方向是恢复,既然是恢复本质上又属于有监督。给出了一张图片来区分:

有监督学习:人为告诉他是牛。
无监督学习:啥也没有
自监督学习:从有相关信息的其他输入自行获取标签。而对比学习其实属于自监督学习的一种。自监督学习虽然不需要知道标签信息,就是知道是牛,但是还是需要知道那些是类似的那些是不同的,也就是人为指定的正负样本规则本身就是一种标签,其实本质上也是一种有监督学习。
最后这篇综述的贡献主要有三点:1.自监督学习的回顾。2.自监督学习的分类和方法。3.自监督学习方向。
Motivation of Self-supervised Learning
end-to-end的定义首先得理解什么是非端到端,传统机器学习模型,输入并不是原始数据,而直接输入特征,其实有时候数据的特征提取往往比模型算法还要重要。端到端的意思就是输入原始数据,直接输出最后结果。其实也就是说,端到端将分步解决的中间步骤连接整合在一起,成为一个黑盒子,我能看看到的只是输入的数据和输出的结果,就是从数据的端,到了结果的端。数据做了预处理,比如图像裁剪,句子分词仍然属于端到端。所以端到端的学习需要非常少的先验假设。
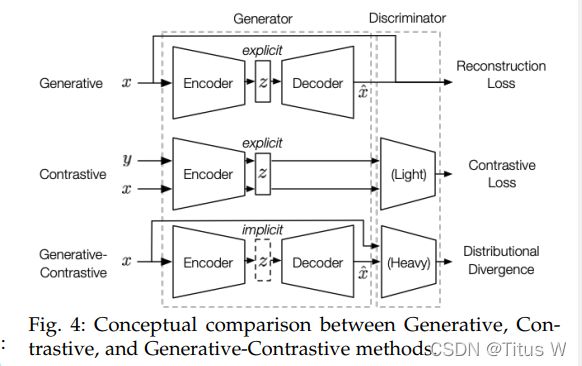
SSL主要分为三类:
Generative:自编码器的重构
Contrastive:latent representation的使用
Generative-Contrastive:GAN
区别:1)前两种的latent representation显式的且直接利用于下游任务,而GAN中的latent representation是隐式的。
2)后两种方法都有判别器,而第一种没有。
3)损失函数不同,分别使用MSE,InfoNCE,Wasserstein Distance。
Generative Self-supervised Learning
这种方法主要这么几种模型比较常用:Auto-regressive (AR) Model,Flow-based Model,Auto-encoding (AE) Model,Hybrid Generative Models,Pros and Cons。
Auto-regressive (AR) Model
第一种是自回归模型,自回归模型也叫贝叶斯网络结构,这种联合分布可以被分解为条件的乘积,其中每个变量的概率都取决于他先前的变量,所以自回归模型本质上是分解概率的过程。在自然语言处理中,自回归语言建模的目标通常是在正向自回归因子分解下最大化似然值。这种模型常见的代表有GPT、GPT-2这类使用Transformer解码器部分的结构。与GPT不同,GPT-2去掉了不同任务的微调过程。为了泛化不同的下游任务,GPT-2使用相同的输入可以有不同的输出。此外,自回归模型在CV领域拥有很多应用,比如PixelRNN或者PixelCNN等等,大致思路就是几种对图像逐像素建模的方法,就是右边的像素是通过左边的像素通过条件反射生成的。对于二维图像,自回归模型只能根据特定方向(如右和下)分解概率。为了处理长期的时间依赖性,作者开发了扩大的因果卷积来改善接受区域。此外,门控剩余块和跳跃连接被用来增强更好的表达能力。自回归模型也可以被用在图领域,比如图生成,提出GraphRNN,用深度自回归模型生成真实的图。GraphRNN可以看作是一个层次模型,图级RNN维护图的状态并生成新的节点,而边缘级RNN根据当前的图状态生成新的边。MRNN和CRNN都使用了强化学习的方法。MRNN主要采用基于rnn的网络进行状态表示,而GCPN采用基于gcn的编码器网络。自回归模型的优点是能够很好地对上下文依赖性建模。然而,一个AR模型的缺点是每一处的token Position只能从一个方向访问其上下文。
Flow-based Model
流模型的目标是从数据中估计复杂的高维密度p(x)。为了得到一个复杂的密度,我们希望将一系列描述不同数据特征的变换函数分别叠加,“一步一步”地生成。我们的目标是学习x和z之间的变换,这样x的密度就可以被描述出来。基于流的模型的优势在于映射x和z之间是可逆的。然而,它也需要x和z一定有相同的维数。fθ需要精心设计。因为它应该是可逆的,并且要计算出式中的雅可比行列式很容易。
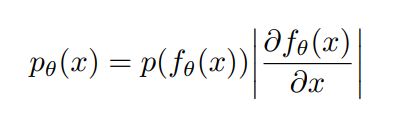
函数f是连续可逆的也就是有反函数,z和x分别服从概率分布,所以他们的积分都是1,所以两个概率分布的绝对值是相等的,移项就可以得到上边的式子。x=f(z),所以反函数z=f(x)-1次方。这种方法是一种比较传统的机器学习方法。
Auto-encoding (AE) Model
自编码器再熟悉不过了,目的就是重构输入与输出之间的损失,由于其灵活性,AE模型可能是最流行的生成模型,有许多变体。
Basic AE Model
传统自编码器的目标是使模型的边际分布与数据分布之间的差异最小化。
Context Prediction Model(CPM)
在NLP中,自监督词嵌入的方法有CBOW和Sikp-Gram作为先驱工作,基于这些方法的启发。在此基础上,提出了许多网络嵌入模型
在相似的背景下预测目标
Denoising AE Model
去噪自编码器,一看名字就知道对噪声应该有很强的鲁棒性,比如掩码语言模型MLM是一个比较成功的语言模型,就是随机掩盖了一些token值,类似于完形填空。BERT就是利用掩码学习这样训练的。BERT之后,更多扩展的MLM也相继出现比如ERNIE。比较自回归模型而言,去噪自编码器预测token值可以访问双方的上下文信息,而非只有一方的信息。然而,如果给出了未隐藏的token,那么MLM假设预测的token是独立的(这在现实中并不存在),这一事实长期以来一直被认为是其固有的缺陷。
Variational AE Model
变分自动编码模型假设数据是从潜在的(未观察到的)表示生成的,也叫VAE。VAE这篇论文也是比较经典了。
VAE
x是很高维度的随机变量,z的维度比x低很多,z倾向于一种根本质的描述。其实就是z和x之间的相互转化,也就是下面的双箭头就是VAE的主要内容。就是为了从x得到z,用了贝叶斯公式,因为维度太高有一项很难求,所以想用一个模型来近似概率分布。随后又介绍了VQ-VAE和VQ-VAE2。如今,VAE及其变体已广泛应用于计算机中视觉区域,如图像表示学习,图像生成视频生成等等。变分自编码模型也被用于图上的节点表示学习。
Hybrid Generative Models
混合生成模型顾名思义就是将上面提到的几种模型结合起来。
Pros and Cons
生成式自我监督学习成功的原因,在自我监督学习中最重要的是其恢复原始的能力,对下游任务没有假设的数据分布。总结而言有两个缺点:
首先,尽管生成式自我监督学习在生成任务中处于中心地位,但最近发现在某些分类场景中,生成式自我监督学习的竞争力远不如对比式自我监督学习,因为对比式学习的目标自然与分类目标一致。包括MoCo [52], SimCLR [19], BYOL[47]和SwAV[18]在内的作品在各种CV基准上都表现出了压倒性的性能。然而,在自然语言处理领域,研究者仍然依赖生成语言模型来进行文本分类。第二,生成目标的逐点性存在一些内在缺陷。
Contrastive Self-Supervised Learning
对比学习我可是再熟悉不过了
Context-Instance Contrast
上下文与实例的对比,也就是建立局部与全局之间的关联,大概有两种类型,PRP和MI。
Predict Relative Position
预测相对位置:许多数据在其各部分之间包含丰富的空间或序列关系。
maximize mutual information
最大化互信息:在应用中,MI因其复杂的计算而臭名昭著。一种常见的做法是最大化I的下端与NCE目标绑定。但是引入对比学习就很好了,Deep InfoMax为我们提供了一个新的范例促进自我监督学习的发展。的第一个有影响力的追随者是对比预测编码(CPC)[95]用于语音识别。
Instance-Instance Contrastive
尽管基于mi的对比学习取得了巨大的成功,一些研究对MI带来的实际改善提出了质疑。实例级表示,而不是上下文级表示,对于广泛的分类任务来说更为关键。例如,在一个分类为“狗”的图像中,虽然一定有狗的实例,但可能会出现一些其他不相关的上下文对象,如草。但对于图像分类来说,重要的是狗,而不是背景。另一个例子是句子情感分类,它主要依赖于少数但重要的关键词。
Cluster Discrimination
首先研究基于聚类的实例与实例之间的对比,也就是利用聚类产生伪标签,这种方法不行。
Instance Discrimination
其实就是moco,SimCLR, SwAV,BYOL,SimSiam这些,图结构有M3s这些。主要还是moco打破了一正一负,大大增加了负样本的数量。
Self-supervied Contrastive Pre-training for Semi-supervised Self-training
半监督自我训练的自我监督前对比训练:其实就是半监督加知识蒸馏的方法。
这里需要澄清半监督学习的概念,就是利用少量无监督数据和大量无监督数据。
Zoph等人研究了MoCo预训练和自我训练方法,其中首先对下游数据集(如COCO)进行训练,然后对未标记数据(如ImageNet)生成伪标签,最后,学生共同学习下游数据集上的真实标签和未标记数据上的伪标签。他们惊奇地发现,训练前的表现是有害的,而自我训练仍然受益于强大的数据增强。此外,更多的标签数据降低了前训练的价值,而半监督的自我训练总是提高。他们还发现训练前和自我训练的改进是相互正交的,即从不同的角度对绩效的贡献。预训练与自训练相结合的模型效果最好。SimCLR也验证了这个结论。自我监督对比前训练和半监督自我训练的成功结合,为未来数据高效的深度学习范式打开了我们的视野。预计还会有更多的工作来研究它们的潜在机制。
Pos and Cons
因为对比学习假设了下游的应用程序是分类,所以与生成模型相比,它在架构中只使用了编码器,而丢弃了解码器。因此,对比模型通常重量轻,在鉴别下游应用中表现更好。
但是也有缺点:1)对比学习在CV领域非常成功,但是在NLP领域不太行。很少有人提出在预训练阶段应用对比学习的算法,由于大多数语言理解任务是分类的,对比语言训练前方法应该比现有的生成语言模型更好。2)采样效率,采样方式千变万化,也很依赖于负样本,也不清楚负样本在对比学习中究竟是个什么角色。3)数据增强严重妨碍了离散数据,比如NLP领域和图领域。
Generative-Contrastive(Adversarial) Self-Supervised Learning
其实就是一个GAN:
dversarial loss is based on a paper [40]. The traditional GAN will train two models of generator and discriminator , and the objective function is the value function defined as
$ min G max D V ( D , G ) = E x ∼ p data ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min _{G} \max _{D} V(D, G)=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}[\log D(\boldsymbol{x})]+\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}[\log (1-D(G(\boldsymbol{z})))] GminDmaxV(D,G)=Ex∼pdata (x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]$ (11)
is a two-player minimax game with two expectations added. In the first term is sampled from the true distribution , so this term is 0 under the prior assumption that the discriminator is perfect. In the second term, is sampled from the noise distribution , and then fed to the generator, so this term is also 0 under the prior assumption that the discriminator is perfect. Without this prior hypothesis, the sum of the above two must be a negative number. In order to optimize the discriminator, should be close to 0, so should be maximized. But if the generator is perfect a priori assumption, the second term of will approach negative infinity, in order to train the generator, so to minimize.
Generate with Complete Input
就是GAN和GAN的变体,目的就是捕获完整信息。
在VQ-VAE2之前,GAN在图像生成任务上的表现优于纯生成模型,如自回归PixelCNN和自动编码器VAE。我们很自然地会想到这个框架如何有利于表征学习。于是说明了VAE与GAN之间的数学关系,这两种的核心思想是相反的。
Recover with Partial Input
正如我们上面提到的,GAN的架构不是为表征学习而生的,需要修改才能应用它的框架。而BiGAN和ALI选择直接提取隐式分布,其他一些方法如去噪自编码器DAE,掩码学习BERT又很像。比如超分辨率问题。
Pre-trained Language Model
Graph Learning
这两个方面用的不多,暂时就不看了。
Domain Adapation and Multi-modality Representaion
从本质上说,在对抗性学习中鉴别者是有用的
来匹配潜在表征之间的差异
分布和数据分布。这个函数自然
涉及领域适应和多模态表示问题,旨在对齐不同的表示
分布。[1],[2],[42][113]研究了GAN如何帮助
领域适应气候变化。[16],[138]利用对抗抽样
提高阴性样品的质量。对于多模
表示法,[161]的图像到图像的转换,[114]的
文本样式转移,[27]的词到词的翻译和[112]
图像对文本的翻译显示出强大的对抗性
表示学习。