CVPR2021系列(四)—— 深度视频抠图
01 背景
抠图是图像处理里的重要技术之一,被广泛应用于图片/视频编辑,影视制作等实际场景中。传统的抠图技术利用图像的色彩等底层特征来分离前景,但其效果受制于底层特征的有限表达能力。随着深度学习的发展,深度神经网络被应用于抠图技术中,从深度网络提取的高层语义特征能够从复杂场景中准确区别前后背景,从而极大地提升了抠图效果,基于深度学习的图像抠图技术也因此成为主流的图像抠图技术。近年来,短视频的大热进一步催生了更复杂的视频抠图的需求,如何提升视频抠图效果也成为了时下的重要课题之一。
抠图问题可以用公式 ![]() 定义,即图片
定义,即图片  是前景
是前景  和背景
和背景  的加权和,其中权重也被称为透明度或Alpha,是抠图问题中的待求解变量。给定一张图片,由于前景和背景未知,因此对Alpha的估值是一个不适定问题,Trimap图通常作为额外输入来限定求解空间。Trimap是一个三类别的掩膜,用来指定确定的前景、背景以及未知的区域,而未知区域就是需要估值的区域。在实际应用场景中,Trimap可以来源于用户输入,特定场景下也可以由预训练的模型自动产生;比如人像抠图中,可以用人像分割模型预测的掩膜代替Trimap来提供先验知识。
的加权和,其中权重也被称为透明度或Alpha,是抠图问题中的待求解变量。给定一张图片,由于前景和背景未知,因此对Alpha的估值是一个不适定问题,Trimap图通常作为额外输入来限定求解空间。Trimap是一个三类别的掩膜,用来指定确定的前景、背景以及未知的区域,而未知区域就是需要估值的区域。在实际应用场景中,Trimap可以来源于用户输入,特定场景下也可以由预训练的模型自动产生;比如人像抠图中,可以用人像分割模型预测的掩膜代替Trimap来提供先验知识。
02 问题
相比图像抠图,视频抠图面临着更多挑战。首先,缺乏大规模的深度学习视频抠图数据集,这是限制视频抠图发展的首要因素;其次,如果直接将图像抠图算法移植到视频数据上,需要对每一帧提供Trimap,然而逐帧标注Trimap显然不切实际,那么如何节省标注成、减少人力介入也是不可忽视的问题;另外,视频抠图与图像抠图的最大区别就是前者需要考虑帧之间的连续性,如何利用时域信息减少抖动成为了新的挑战。
03 成果
为了解决上述视频抠图的痛点,快手联合香港科技大学推出了新的视频抠图框架,这是第一个基于深度学习的视频抠图算法。该算法是一个两阶段算法,可以在仅提供少量关键帧的Trimap下,将Trimap传播到其他帧,并融合相邻帧的时域信息产生具有连续性和一致性的预测结果。该算法的两个阶段都不需要计算光流,为并行计算提供了便利。在深度视频抠图技术尚未被有效探索之际,该研究填补了这一技术空缺。考虑到深度视频算法通常需要大规模的训练数据,文中还提出了一个基于合成的大规模视频抠图数据集,用来支持后续的视频抠图技术研究。
下面具体介绍该研究提出的视频抠图框架。
Trimap传播
传统的Trimap传播算法通常依赖于光流,然而现有的光流算法不擅长处理精细结构和带有大量透明度像素的场景。而这些场景又是视频抠图任务中常遇到的场景,为了避免依赖光流引入的误差,文中使用了跨越注意力(Cross-attention)机制来传播Trimap。对于一段视频,只需要人为标注极少量关键帧的Trimap,而其他帧则通过传播算法来自动生成Trimap,从而节约大量Trimap的标注成本。其中,人工标注Trimap的帧为参照帧,而未被标注的帧称为目标帧。网络框架如下图。
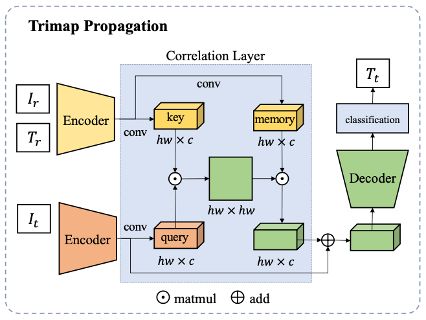
给定参照帧和目标帧,文中做法如下:
-
使用两个分享权重的编码器,来分别提取参照帧(F_r)和目标帧(F_t)的语义特征。
-
使用跨越注意力网络来计算目标帧与参照帧的像素间相似度关系。根据特征相似度的计算公式,如果一个目标帧像素属于前景的话,它也会被对应到参照帧里的前景像素,通过这种对应得到目标帧编码后的特征。
-
用解码器将编码特征重建后,对每个像素分类做三类别分类,产生最后的Trimap。
对于前景运动幅度较小的场景,此方案可以仅提供第一帧Trimap输入;即使在前景物体运动幅度较大的场景下,此方案在可以仅依靠少量关键帧Trimap为视频生成所有帧的Trimap,极大的减少了人工成本。与依赖光流的算法相比,该算法性能不受光流限制,预测更稳定,生成的Trimap质量也更高。同时这个模块可以接入到任意图像抠图算法上,具有普适性。下图是Trimap传播的例子。

时空特征融合模块(ST-FAM)
在第二个阶段,作者提出了一个深度视频抠图框架,用来融合不同尺度的空间特征以及邻近帧之间的时序特性,从而增强目标帧的特征表达能力,得到更好地预测结果,如下图。
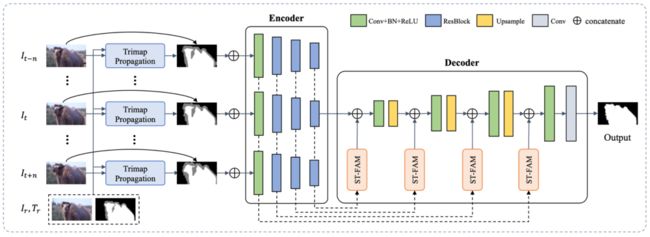
算法主体是一个自动编码器-解码器结构,在编码器与解码器之间有跳层连接,用来将不同层级的特征连接到解码器从而重建原始尺度的Alpha预测。为了利用视频里的时序信息,作者同时将目标帧以及其邻近帧送到编码器中得到对应的多帧多尺度空间特征,并通过时空特征融合模块(ST-FAM)将多帧特征融合,从而将时序信息编码到特征里。ST-FAM模块包括两个子模块: 时序特征对齐(TFA)模块和时许特征融合(TFF)模块,具体结构图如下图。
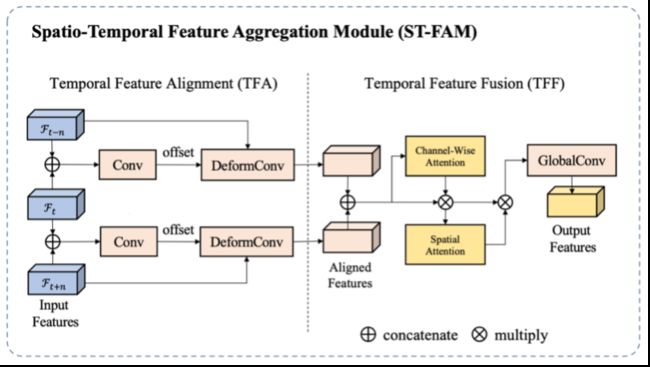
TFA模块
TFA模块是用来对齐相邻帧的特征的。具体而言,对于任意时刻  的特征图的像素
的特征图的像素  ,让其去预测一个位移
,让其去预测一个位移  ,这个 是 帧到
,这个 是 帧到 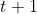 帧之间像素 的运动向量。之后利用可变形卷积层(deformable convolution)将 帧的特征对齐到 帧。通过这种方式可以自动让多个时刻间
帧之间像素 的运动向量。之后利用可变形卷积层(deformable convolution)将 帧的特征对齐到 帧。通过这种方式可以自动让多个时刻间 ![]() 的特征对齐到 帧,这些对齐的特征会送往TFF模块进行融合。
的特征对齐到 帧,这些对齐的特征会送往TFF模块进行融合。
多帧对齐后的特征可能会引入噪声,为了减轻噪声的负面影响,作者提出用注意力机制包括特征层注意力(Channel Attention)和空间注意力(Spatial Attention)来完成多帧合并。首先利用全局平均池化(Global Average Pooling)操作获取特征层注意力权重,乘到对齐的多帧特征上,从而筛选出对目标帧有用的通道。进而使用空间注意力操作,来增加通道内像素之间的交互,增加感受野,从而减少干扰信息带来的影响。
04 实验和对比
作者在合成数据集和真实的高清视频上分别做了定量和定性测试。下表提供了定量的实验结果,这些实验数据充分验证了该算法在视频数据上的有效性。
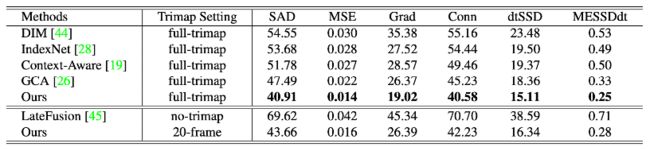
该算法虽然在合成数据集上训练,但在真实数据上性能也很稳定。下图提供了该算法在真实高清视频上的定性测试结果。

05 相关链接
[19] QiqiHouandFengLiu.Context-awareimagemattingforsimultaneous foreground and alpha estimation. In ICCV, 2019.
[26] Yaoyi Li and Hongtao Lu. Natural image matting via guided contextual attention. In AAAI, 2020.
[28] Hao Lu, Yutong Dai, Chunhua Shen, and Songcen Xu. Indices matter: Learning to index for deep image matting. In ICCV, 2019.
[44] Ning Xu, Brian Price, Scott Cohen, and Thomas Huang. Deep image matting. In CVPR, 2017.
[45] Yunke Zhang, Lixue Gong, Lubin Fan, Peiran Ren, Qixing Huang, Hujun Bao, and Weiwei Xu. A late fusion cnn for digital matting. In CVPR, 2019.