yolo系列论文阅读
YOLOv1
yolov1提出了一种新的识别方法,不同于RCNN系列将识别问题转化为对候选区域的分类,yolo使用回归方法直接预测目标的类别和位置。

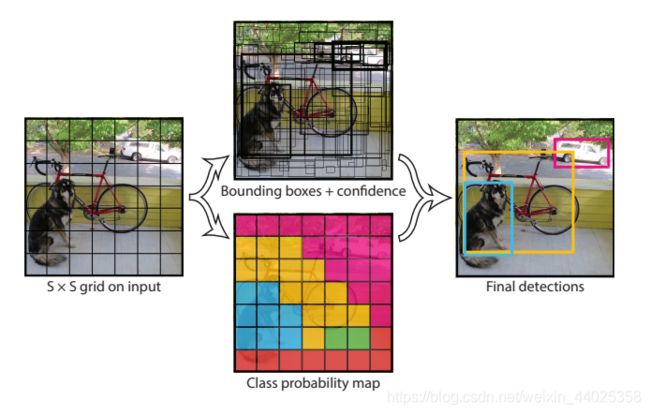
对输入的每幅图片,yolov1将之分割为7×7的网格,每个网格预测2个bounding boxes.对每个bounding box预测一个置信度(confidence scores),confidence scores定义为:
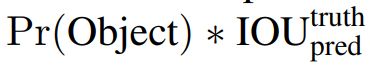
当包围盒中存在物体时Pr(Object)=1, 置信度为ground truth与bounding box的交并比,否则Pr(Object)=0.每个bounding box包含5个预测(x, y, w, h, confidence)。(x,y)表示bounding box的中心坐标,w, h表示bounding box的宽和高。
对每个网格进行类别预测:Pr(Classi|Object) , 表示该网格中包含各类物体的概率。
注意:yolov1只对每个网格进行类别预测,而不是对每个bounding box进行类别预测。默认每个网格中只包含一个物体。若存在多个物体,则取交并比最大的一个计算。
每个网格目标识别的结果(哪个种类,概率是多少):
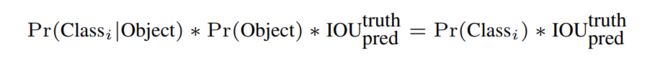
yolov1的网络结构:
网络使用一系列简单的3×3,1×1卷积,最后全连接层输出预测结果tensor。
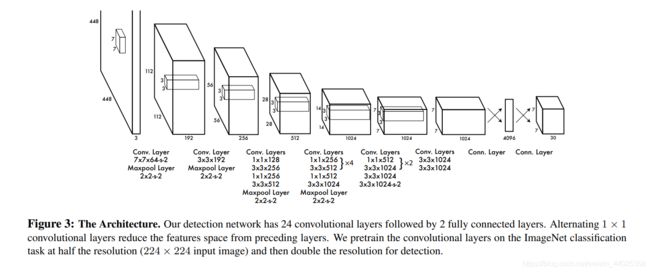
由于目标识别通常需要细粒度的视觉信息,作者将网络的输入分辨率提高到了448×448(注意训练时依然用的224×224分辨率),网络输出为7×7×(20+5×2)的tensor。
损失函数:
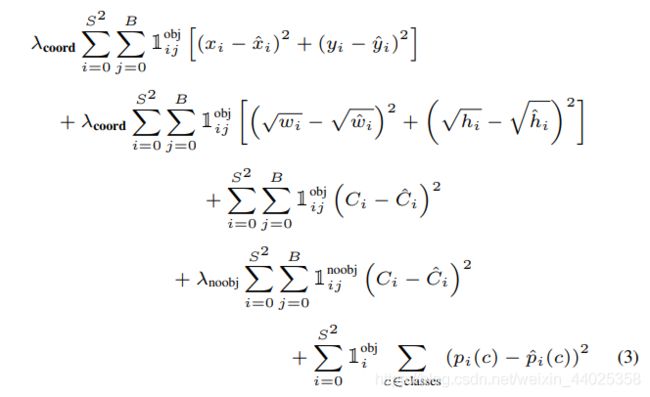
当bounding box中不包含物体时,Pr(Object)=0, 推动置信度为0,不包含物体梯度下降超过了包含物体的梯度,由于一幅图像中不包含物体的网格有很多,这样会在训练时造成梯度发散,模型不稳定。为了解决这个问题,增加坐标预测的权重,减少confidence sorces的预测权重。令λcoord=5, λnoobj=0.5。
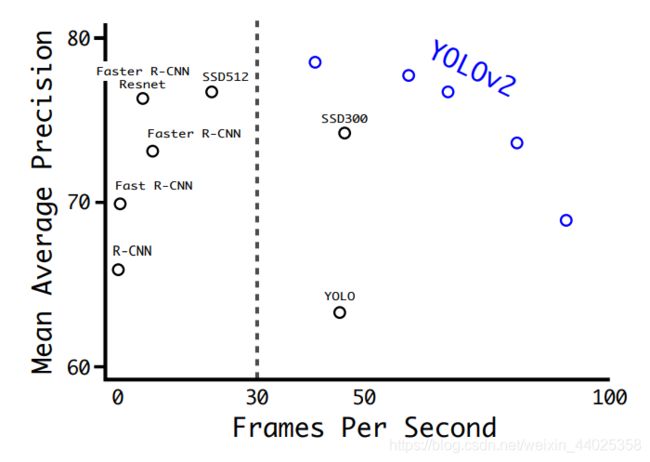
yolo优点:识别速度快,能够达到45帧/s,轻量级版本能够达到155帧/s, 准确度比上不足,比下有余。
yolo缺点:难以识别近距离的两个物体,和在同一网格内体积比较小的同类物体,如鸟群等。
YOLOv2
yolov2在yolov1的基础上进行了很多改进,具体改进措施及效果如下:

Batch Normalization
神经网络训练过程中的两个问题:一方面,底层网络参数的微弱变化经过中间层的线性变换和非线性激活函数,会对输出结果造成巨大的影响。另一方面,参数的变化会使每一层的输入分布发生变化,使上层网络要不断适应变化的分布。这就导致了网络的训练容易进入梯度饱和区,减缓网络收敛速率。
使用batch normalization可以将神经网络每一层的输入规范化为均值为0,方差为1的分布,有效解决了上述问题。使用barch normalization将网络mAP提高了2.4%。
High Resolution Classifier
yolov1使用224×224分辨率在ImageNet上训练,使用448×448分辨率进行识别。yolov2对分类网络进行了微调,在224×224训练的网络基础上,用448×448训练10个epoch之后,进行目标识别。使用High Resolution Classifier将网络mAP提高了3.7%。
Convolutional With Anchor Boxes
作者借鉴了faster-rcnn使用anchor boxes预测bounding box的方法。yolov1使用全连接层直接预测bounding box的位置坐标。yolov2去掉了全连接层,使用anchor预测bounding box。yolov1对每一幅图只预测98个boxes, yolov2却超过一千个,这样做降低了网络0.3%的mAP,却提高了7%的召回率。
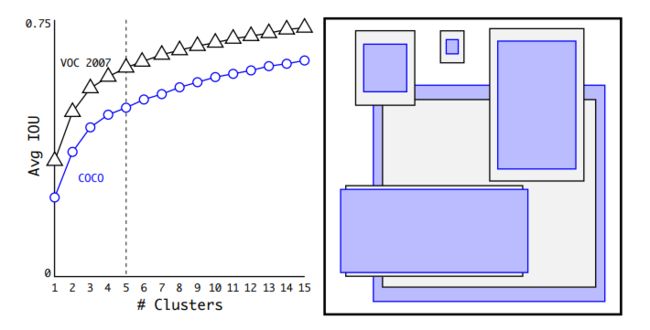
Dimension Clusters
先前的先验框都是手动选择的一组不同大小,宽高比的边框,来覆盖整幅图像不同位置,不同尺度。虽然网络可以学习调整这些boxes的大小,但是选择更匹配数据的先验框可以使网络更容易的学习到boxes的位置。
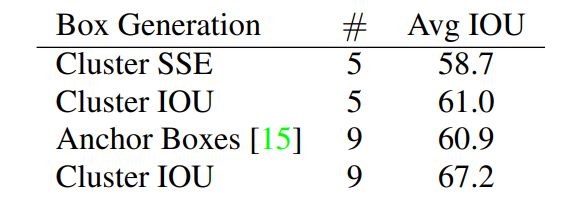
yolov2对训练集的bounding boxes进行k-means聚类,寻找最匹配数据的边框尺寸。如果使用欧氏距离,大边框会比小边框产生更多的错误。寻找最佳先验框的目的是使IOU最大,所以定义聚类距离:
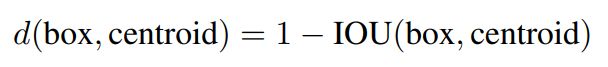
通过实验,经过模型复杂度和召回率的折中考量,选择k=5。
|
|
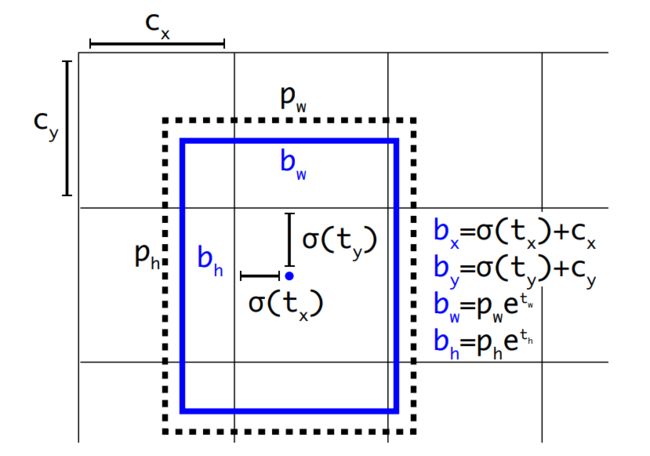
Direct location prediction
作者使用anchor boxes之后发现发现了一个问题:模型变得不稳定。原因是box(x, y)坐标的预测。

由于该公式没有任何约束,anchor box的中心可以出现在任何位置,导致早期训练不稳定。于是作者舍弃anchor boxes的方法,延续使用yolov1直接预测bounding boxes位置坐标的方法。对每个cell预测5个bounding boxes, 并将bounding box的中心约束在cell内,使模型更加稳定。使用Dimension Clusters和Direct location prediction比使用anchor box的mAP提高了5%。
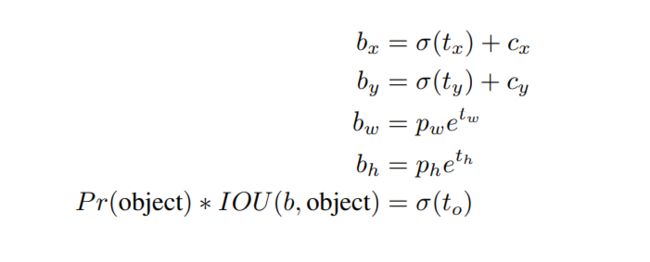
|
|
Fine-Grained Features
yolov2网络的输入为448×448,最后得到的feature map为13×13×1024,小物体的特征几乎不可见,为了更好的识别小物体,yolov2使用一种passthrough layer方法, 将最后一个pooling层之前26×26×512的feature map拆分成4个13×13×512,与13×13×1024的features map连接, 得到13×13×3072。
Multi-Scale Training
yolov2为了实现对不同分辨率的图像都有较好的识别效果,在训练时每隔10个epoch就换一个新的分辨率图像进行训练. 由于下采样参数为32,分辨率要为32的倍数,最小为320×320,最大为608×608. yolov2实现了速度和识别精度的折中,输入图像分辨率低时,网络识别速度快;输入图像分辨率高时,网络识别精度高。
YOLOv3
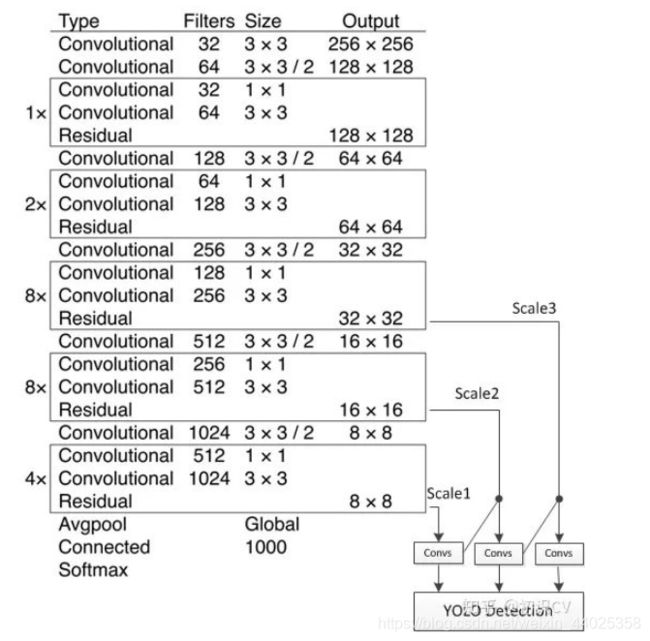
yolov3使用了新的特征提取网络DarkNet53,多尺度预测,将softmax分类改为logistic分类器,使用二分类交叉熵损失函数。
使用logistic分类主要考虑到在进行复杂数据集训练时,同一个物体可能拥有多个交叉标签,softmax分类假设每个box中只存在一个类别,且这些类别互相独立,所以就不能适合多标签的分类。同时,多个logistic分类器也可以实现softmax的效果。
DarkNet53主干网络
DarkNet53由一系列的3×3,1×1卷积,再加上残差网络构成。

多尺度预测
yolov3在三个不同尺度上识别预测,每个尺度上预测3个bounding boxes,输出tensor:N × N × [3 ∗ (4 + 1 + 80)]。先验框的选择仍然使用k-means聚类,在COCO数据集上的9个先验尺寸为(10×13),(16×30),(33×23),(30×61),(62×45),(59× 119),(116 × 90),(156 × 198),(373 × 326).
yolov3将网络最后一层的feature map上采样后,与前面的feature map连接,融合成一个新的feature map,形成不同的尺度。如图所示,
图片来源
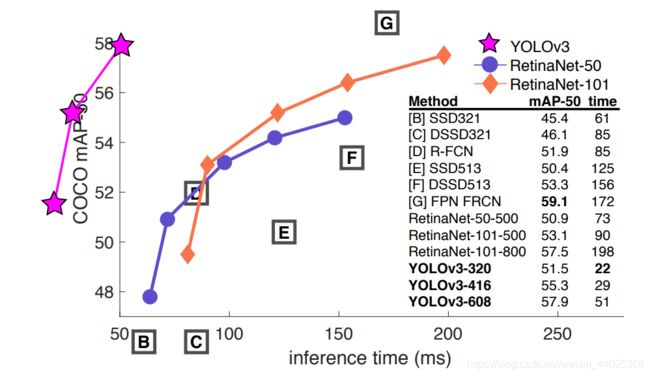
yolov3实验结果对比:当IOU阈值为0.5时,yolov3拥有近乎碾压般的优势。
YOLOv4
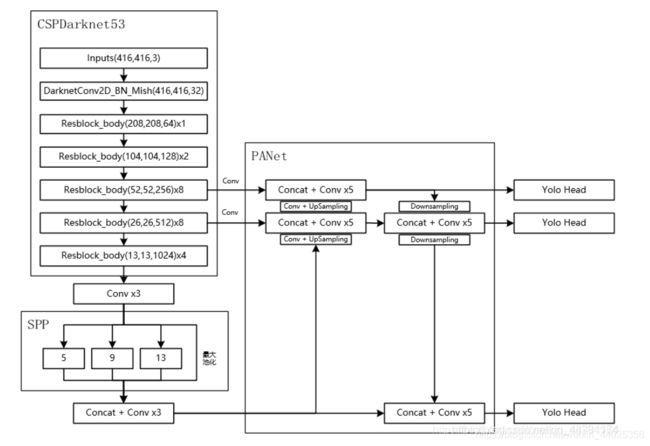
yolov4是集大成之作,融合使用了大量技巧来提高模型的精度。yolov4组成:
Backbone: CSPDarknet53
Neck: SPP, PAN
Head: YOLOv3
yolov4的目标是找到网络输入分辨率,网络卷积层数,网络参数量以及网络感受野等各方面因素之间的最佳平衡。通过大量实验,经过大量参数的调整,网络使用了以下技巧:
用于backbone的BoF: CutMix and Mosaic data augmentation, DropBlock regularization, Class label smoothing
用于backbone的BoS: Mish activation, Cross-stage partial connections (CSP), Multiinput weighted residual connections (MiWRC)
用于detector的BoF: CIoU-loss, CmBN, DropBlock regularization, Mosaic data augmentation, Self-Adversarial Training, Eliminate grid sensitivity, Using multiple anchors for a single ground truth, Cosine annealing scheduler, Optimal hyperparameters, Random training shapes
用于detector的BoS: Mish activation, SPP-block, SAM-block, PAN path-aggregation block, DIoU-NMS
(BoF表示只增加训练时间消耗,而不增加推理阶段时间消耗的方法;BoS表示只增加少量推理阶段时间消耗,而显著增加识别精度的方法)

SPP:Spatial Pyramid Pooling layer
作用:放在卷积神经网络最后一个卷积层之后,全连接层之前,使网络输入图片尺寸无论多大,经过SPP之后输出一个固定尺寸tensor, 使之适合全连接层输入。
![]()
做法:将feature map进行多个窗口的pooling,将pooling 结果叠加。

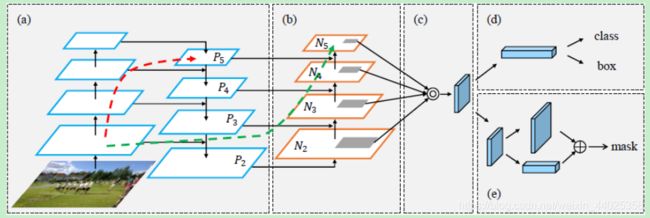
PAN:Bottom-up Path Augmentation
作用:FPN是自顶向下,将高层的强语义特征传递下来,对整个金字塔进行增强,不过只增强了语义信息,对定位信息没有传递。PAN在此基础上又增加了一个自底向上的通道,将底层信息直接向上传递,提高信息利用率。
做法:下图中的 N2 和 P2 完全一样,P2 是FPN上采样后结果。其中的一个具体模块:Ni 经过一个3×3,stride为2的卷积之后,下采样为原来的一半,然后与横向连接传递过来的 Pi+1 进行逐元素相加,再经过一个3×3的卷积生成 Ni+1 ,其中的通道数保持在256,且每个卷积之后会接ReLU。
CSP: Cross Stage Partial Network
作用:神经网络推断过程中计算量大很大部分原因是由于优化过程中梯度重复导致的。CSP优化了梯度传递路径,减少计算量,增强梯度了表现,提高网络学习能力。
做法:将feature map 拆成两部分,一部分直接进行卷积操作,另一部分与卷积操作之后的结果concatenate。

CSPDarknet53:
图片来源
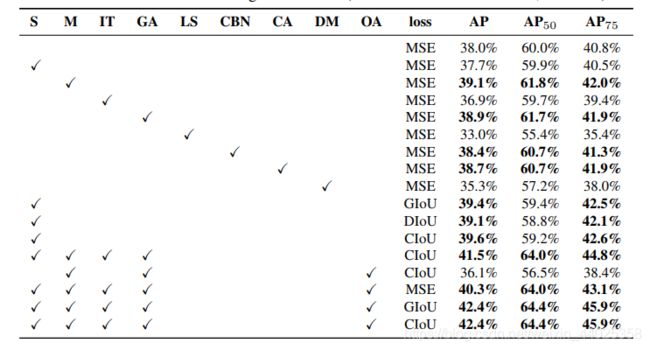
精湛的调参艺术:
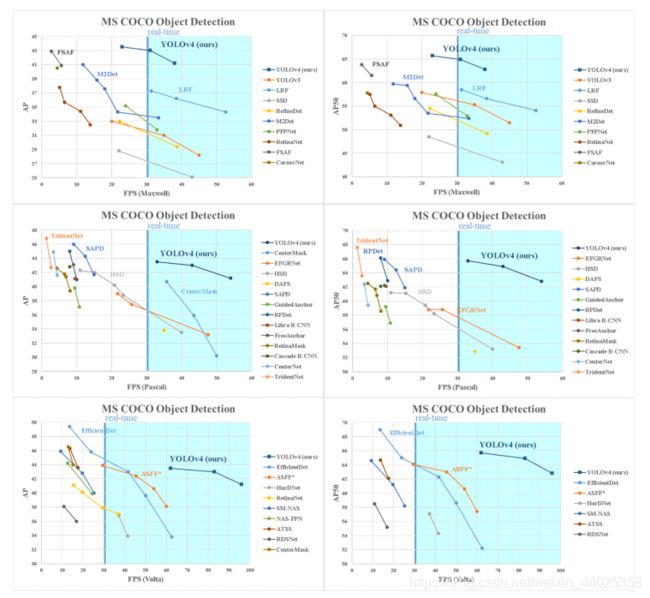
无与伦比的性能优势: