ResNet文章重点、源码手搓、源码正确使用方式——完整训练和测试过程
这里写目录标题
-
- 1 引入原因
-
- 1.1 主要工作
- 1.2 其他实验
- 2 源码分享
-
- 2.1 手搓ResNet18
- 2.2 ResNet正确打开方式
-
- 2.2.1 预训练好的模型进行迁移
- 2.2.2 未训练的模型进行迁移
- 2.3 其余类型的ResNet网络
1 引入原因
1.1 主要工作
一般我们认为,在深度学习中,卷积层越多,效果越好,但实际是,层数多的模型其误差高于层数少的误差,如下图:
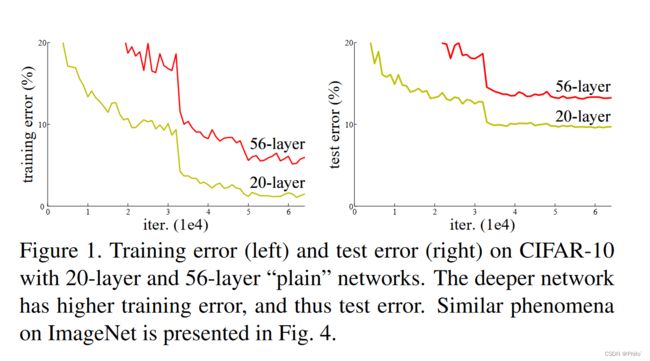
这个和我们的认知相违背,在一般的网络中,随着层数的增加,下层网络学的的是上层传递下来的东西,设置为H(x),假设原始输入的为X,由于层数增加,下层只是拟合H(x),效果如上图所示,层数增加,效果变差,因此HeKaiMing团队提出,下层直接拟合H(x)效果不好,那H(x)上面的层数,拟合H(x)-x的效果如何呢?设上层的拟合为F(x),所以有F(x)=H(x)-x,得到了大名鼎鼎的H(x)=F(x)+x,即下层的结果是F(x)+x,同时文章中也是从这一个点切入,做出的实验证明了这一观点,就是拟合方向不同,学习的难易程度不同。公式如下:

文章中的实验结果如下:
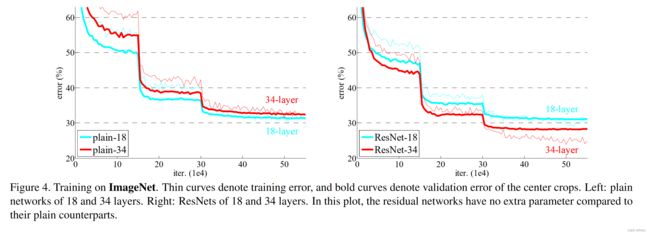
因此,就有了超深的网络模型出现,出现超过100层的网络模型等,文章后期使用的模型是ResNet101和ResNet152进行进一步探索,并且得到的结果是,50,101,152层的ResNet比34层的ResNet有很大的提升,也再一次验证了ResNet对于普通模型在增加深度时起到的作用。
1.2 其他实验
文章后半部分,又使用了CIRAR10数据集进行训练,采用的是网络层数和结果如下:
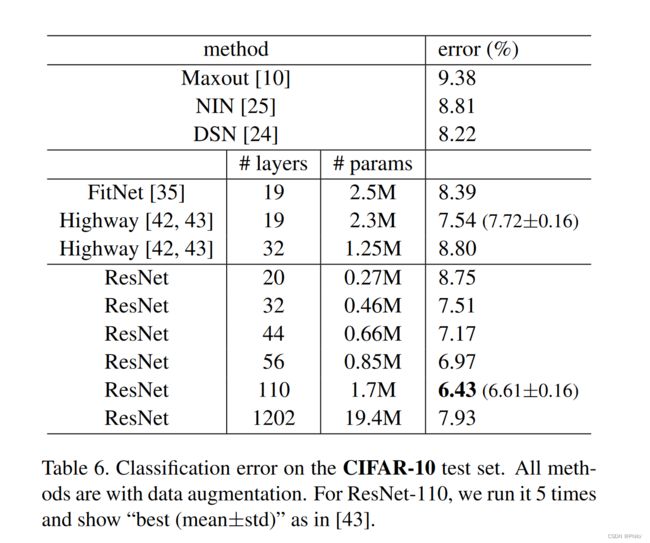
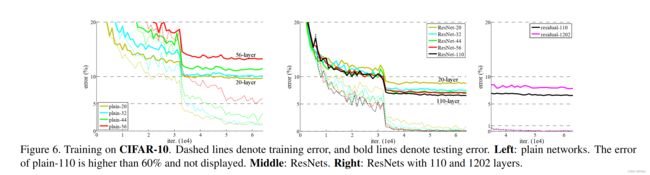
最后,该方法在ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation四个赛道上都达到了最好成绩。
ResNet是真正打开了深层模型的大门。
2 源码分享
2.1 手搓ResNet18
主要是想看看具体的残差如何实现的,但是网上的少之又少,所以凑合写了一个,仅供参考,主要是娱乐自己。具体数据集使用方法可以参考我的另一篇文章:GoogleNet重点介绍和源码分享,主要是使用的是Kaggle平台。
import os
import time
import torch.nn as nn
import torch
import torchvision.transforms as transforms, datasets
import torchvision
from PIL import Image
from matplotlib import pyplot as plt
import torchvision.models as models
from torchvision.models import resnet101,resnet18
import os
from torch.utils.data import DataLoader
from torchvision import datasets, transforms, models
from torchvision.utils import make_grid
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 前期准备工作 一下仅供参考
train_transforms = transforms.Compose([
transforms.RandomRotation(10),
transforms.RandomHorizontalFlip(),
transforms.Resize(227),
transforms.CenterCrop(227),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],
[0.229,0.224,0.225])
])
test_transforms = transforms.Compose([
transforms.Resize([227,227]),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],
[0.229,0.224,0.225])
])
# 第一步 分别传入训练集和测试集
train_dataset = datasets.ImageFolder(root="../input/intel-image-classification/seg_train/seg_train", transform=train_transforms)
test_dataset = datasets.ImageFolder(root="../input/intel-image-classification/seg_test/seg_test" , transform = test_transforms)
# 第二步 不需要索引了, 直接使用数据加载器进行加载
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=True)
NUM_CLASSES = 6
EPOCH = 150
LR = 0.001
# 网络
def conv3x3(in_ch, out_ch, stride=1, groups=1, dilation=1):
return nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=stride, padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_ch, out_ch, stride=1): # 这里的padding为0
return nn.Conv2d(in_ch, out_ch, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes, stride=1, dilation=1, norm_layer=None, downsample=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.stride = stride
self.downsample = downsample
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(identity)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self):
super(ResNet, self).__init__()
self.base = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1)
)
self.layer1 = nn.Sequential(BasicBlock(64,64),
BasicBlock(64,64)
)
self.layer2 = nn.Sequential(BasicBlock(64,128, downsample=nn.Conv2d(64,128,kernel_size=1)),
BasicBlock(128,128)
)
self.layer3 = nn.Sequential(BasicBlock(128,256, downsample=nn.Conv2d(128,256,kernel_size=1)),
BasicBlock(256,256)
)
self.layer4 = nn.Sequential(BasicBlock(256,512,downsample=nn.Conv2d(256,512,kernel_size=1)),
BasicBlock(512,512)
)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(in_features=512, out_features=NUM_CLASSES)
def forward(self, x):
x = self.base(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(-1,512)
x = self.fc(x)
return x
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = ResNet().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=LR)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
def count_parameters(model):
params = [p.numel() for p in model.parameters() if p.requires_grad]
# for item in params:
# print(f'{item:>8}')
print(f'________\n{sum(params):>8}')
count_parameters(net)
import time
start_time = time.time()
train_losses = []
test_losses = []
train_acc = []
test_acc = []
for i in range(EPOCH):
start_time = time.time()
total_train_loss = 0
total_train_acc = 0
for idx, (x_train, y_train) in enumerate(train_loader):
x_train, y_train = x_train.to(device), y_train.to(device)
y_pred = net(x_train)
loss = criterion(y_pred, y_train)
total_train_loss += loss.item()
acc = (y_pred.argmax(1) == y_train).sum()
total_train_acc += acc
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr_scheduler.step()
train_losses.append(total_train_loss)
train_acc.append(total_train_acc/len(train_dataset))
total_test_loss = total_test_acc = 0
with torch.no_grad():
for idx, (x_test, y_test) in enumerate(test_loader):
x_test, y_test = x_test.to(device), y_test.to(device)
y_pred = net(x_test)
loss = criterion(y_pred, y_test)
total_test_loss += loss.item()
acc = (y_pred.argmax(1) == y_test).sum()
total_test_acc += acc
test_losses.append(total_test_loss)
test_acc.append(total_test_acc/len(test_dataset))
end_time = time.time()
print(f"{i+1}/{EPOCH}, time:{end_time-start_time} \t train_loss:{total_train_loss}\t train_acc:{total_train_acc/len(train_dataset)}\t test_loss:{total_test_loss} \t test_acc:{total_test_acc/len(test_dataset)}")
结果仅供娱乐:

整个网络参数大概是11178758,和直接从torchvision.models中加载的预训练模型参数11197002差不多,主要是我实现的时候可能有那些地方漏掉了,再次声明,以上仅供娱乐,现在使用的话,都是直接加载搭建好的模型!!!
学习到的地方:
- 在进行残差相加时,如果通道不同,相加会出现错误,所以BasicBlock中的downsample就是用来控制通道的,是用1✖1的卷积进行实现的,这个主要是在Inception中出现的,如果之前有了解就会很容易理解。
- 在最后的输出时候,用nn.Linear进行改变输出个数的时候,之前都忘记改变数据格式了,后来使用view将其改为(batch_size, num)的二维数据才可以,好久没用了,生疏了。
2.2 ResNet正确打开方式
直接调用torchvision.models中写好的模型,是否预训练好的都可以,以下代码使用torchvision.datasets作为数据集,可以完全复制下去直接跑:
2.2.1 预训练好的模型进行迁移
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
import torchvision.models as models
import torchvision.transforms as transforms
import torch
train_transforms = transforms.Compose([
transforms.RandomRotation(10),
transforms.RandomHorizontalFlip(),
transforms.Resize(227),
transforms.CenterCrop(227),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],
[0.229,0.224,0.225])
])
test_transforms = transforms.Compose([
transforms.Resize([227,227]),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],
[0.229,0.224,0.225])
])
train_data = torchvision.datasets.CIFAR10(root="./data", train=True, transform=train_transforms, download=True)
test_data = torchvision.datasets.CIFAR10(root="./data", train=False, transform=test_transforms, download=True)
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=64, shuffle=True)
class ResNet(nn.Module):
def __init__(self, pretrain=False):
super(ResNet, self).__init__()
self.main = models.resnet18(pretrain)
self.main.fc = nn.Linear(512, 10)
def forward(self, x):
return self.main(x)
# parameters
NUM_CLASSES = 6
EPOCH = 150
LR = 0.001
# initialization
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = ResNet(True).to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=LR)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
# x = torch.randn(10,3,227,227).to(device)
# y = net(x)
# print(y)
import time
start_time = time.time()
train_losses = []
test_losses = []
train_acc = []
test_acc = []
for i in range(EPOCH):
start_time = time.time()
total_train_loss = 0
total_train_acc = 0
for idx, (x_train, y_train) in enumerate(train_loader):
x_train, y_train = x_train.to(device), y_train.to(device)
y_pred = net(x_train)
loss = criterion(y_pred, y_train)
total_train_loss += loss.item()
acc = (y_pred.argmax(1) == y_train).sum()
total_train_acc += acc
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr_scheduler.step()
train_losses.append(total_train_loss)
train_acc.append(total_train_acc/len(train_data))
total_test_loss = total_test_acc = 0
with torch.no_grad():
for idx, (x_test, y_test) in enumerate(test_loader):
x_test, y_test = x_test.to(device), y_test.to(device)
y_pred = net(x_test)
loss = criterion(y_pred, y_test)
total_test_loss += loss.item()
acc = (y_pred.argmax(1) == y_test).sum()
total_test_acc += acc
test_losses.append(total_test_loss)
test_acc.append(total_test_acc/len(test_data))
end_time = time.time()
print(f"{i+1}/{EPOCH}, time:{end_time-start_time} \t train_loss:{total_train_loss}\t train_acc:{total_train_acc/len(train_data)}\t test_loss:{total_test_loss} \t test_acc:{total_test_acc/len(test_data)}")
- 重点是选择模型后,最后修改一下他的全连接层即可,全连接层中的in_features在不同的ResNet中可能不一样,ResNet18是512,ResNet101的in_features是2048,具体可以直接输出一下网络结构,然后查看一下倒数第三层的输出通道是多少,in_features就是倒数第二层的输出层通道个数。
- 具体参考下面:
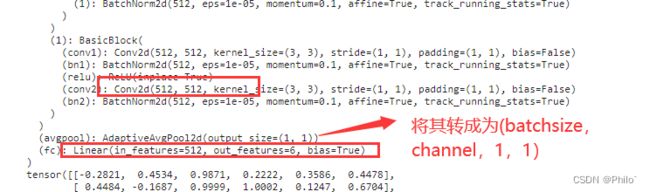
所以修改ResNet.fc = nn.Linear(512, 分类个数)
训练结果截图如下:

效果还是很棒的!
2.2.2 未训练的模型进行迁移
就是修改一下模型调用,将pretrain设置为False即可,以下是完整代码:
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
import torchvision.models as models
import torchvision.transforms as transforms
import torch
train_transforms = transforms.Compose([
transforms.RandomRotation(10),
transforms.RandomHorizontalFlip(),
transforms.Resize(227),
transforms.CenterCrop(227),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],
[0.229,0.224,0.225])
])
test_transforms = transforms.Compose([
transforms.Resize([227,227]),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],
[0.229,0.224,0.225])
])
train_data = torchvision.datasets.CIFAR10(root="./data", train=True, transform=train_transforms, download=True)
test_data = torchvision.datasets.CIFAR10(root="./data", train=False, transform=test_transforms, download=True)
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=64, shuffle=True)
class ResNet(nn.Module):
def __init__(self, pretrain=False):
super(ResNet, self).__init__()
self.main = models.resnet18(pretrain)
self.main.fc = nn.Linear(512, 10)
def forward(self, x):
return self.main(x)
# parameters
NUM_CLASSES = 6
EPOCH = 150
LR = 0.001
# initialzation
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = ResNet(False).to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=LR)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
# x = torch.randn(10,3,227,227).to(device)
# y = net(x)
# print(y)
import time
start_time = time.time()
train_losses = []
test_losses = []
train_acc = []
test_acc = []
for i in range(EPOCH):
start_time = time.time()
total_train_loss = 0
total_train_acc = 0
for idx, (x_train, y_train) in enumerate(train_loader):
x_train, y_train = x_train.to(device), y_train.to(device)
y_pred = net(x_train)
loss = criterion(y_pred, y_train)
total_train_loss += loss.item()
acc = (y_pred.argmax(1) == y_train).sum()
total_train_acc += acc
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr_scheduler.step()
train_losses.append(total_train_loss)
train_acc.append(total_train_acc/len(train_data))
total_test_loss = total_test_acc = 0
with torch.no_grad():
for idx, (x_test, y_test) in enumerate(test_loader):
x_test, y_test = x_test.to(device), y_test.to(device)
y_pred = net(x_test)
loss = criterion(y_pred, y_test)
total_test_loss += loss.item()
acc = (y_pred.argmax(1) == y_test).sum()
total_test_acc += acc
test_losses.append(total_test_loss)
test_acc.append(total_test_acc/len(test_data))
end_time = time.time()
print(f"{i+1}/{EPOCH}, time:{end_time-start_time} \t train_loss:{total_train_loss}\t train_acc:{total_train_acc/len(train_data)}\t test_loss:{total_test_loss} \t test_acc:{total_test_acc/len(test_data)}")
部分训练结果截图:
![]()
2.3 其余类型的ResNet网络

调用方式和上面的差不多,同时分享一下一个解析源码执行流程很棒的博客:ResNet源码解读