【CV】第 11 章:自动编码器和图像处理
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
了解自动编码器
实现香草自动编码器
了解卷积自动编码器
使用 t-SNE 对相似图像进行分组
了解变分自编码器
VAE的工作
KL散度
建立一个 VAE
对图像进行对抗性攻击
执行神经风格迁移
产生深度造假
概括
问题
在前面的章节中,我们学习了图像分类、检测图像中的对象以及分割图像中对象对应的像素。在本章中,我们将学习如何使用自编码器在低维中表示图像,并通过使用变分自编码器利用图像的低维表示来生成新图像。学习以较少的维度表示图像有助于我们在很大程度上操纵(修改)图像。我们将学习利用低维表示来生成新图像以及基于两个不同图像的内容和风格的新图像。接下来,我们还将学习如何修改图像以使图像在视觉上保持不变,但是,与图像对应的类从一个更改为另一个。最后,我们将学习如何生成深度伪造:给定人 A 的源图像,我们生成人 B 的目标图像,其面部表情与人 A 相似。
总的来说,我们将在本章中讨论以下主题:
- 理解和实现自动编码器
- 了解卷积自动编码器
- 了解 变分自编码器
- 对图像进行对抗性攻击
- 执行神经风格迁移
- 产生深度造假
了解自动编码器
到目前为止,在前面的章节中,我们已经了解了通过基于输入图像及其相应标签训练模型来对图像进行分类。现在让我们想象一个场景,我们需要根据图像的相似性和没有相应标签的约束对图像进行聚类。自动编码器可以方便地识别和分组相似的图像。
自动编码器将图像作为输入,将其存储在较低的维度中,并尝试将相同的图像再现为输出,因此术语“自动” (代表能够再现输入)。但是,如果我们只是在输出中重现输入,我们就不需要网络,而是将输入简单地乘以 1 就可以了。自编码器的不同之处在于它以较低维度对图像中存在的信息进行编码,然后再现图像,因此称为编码器(代表图像在较低维度中的信息)。这样,相似的图像将具有相似的编码。此外,解码器致力于从编码矢量重建原始图像。
为了进一步了解自编码器,我们来看下图:

假设输入图像是 MNIST 手写数字的扁平化版本,输出图像与作为输入提供的图像相同。最中间的层是编码层,称为瓶颈层。输入和瓶颈层之间发生的操作代表编码器,瓶颈层和输出之间的操作代表解码器。
瓶颈层通过以下方式提供帮助:
- 具有相似瓶颈层值(编码表示)的图像可能彼此相似。
- 通过改变bottleneck layer的节点值,我们可以改变输出图像。
有了前面的理解,我们来做以下事情:
- 从头开始实现自动编码器
- 根据瓶颈层值可视化图像的相似性
在下一节中,我们将了解如何构建自动编码器,还将了解瓶颈层中不同单元对解码器输出的影响。
实现香草自动编码器
要了解如何构建自动编码器,让我们在 MNIST 数据集上实现一个,其中包含手写数字的图像:
1.导入相关包并定义设备:
!pip install -q torch_snippets
from torch_snippets import *
from torchvision.datasets import MNIST
from torchvision import transforms
device = 'cuda' if torch.cuda.is_available() else 'cpu'2.指定我们希望图像通过的转换:
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
transforms.Lambda(lambda x: x.to(device))
])在前面的代码中,我们看到我们正在将图像转换为张量,对其进行归一化,然后将其传递给设备。
3.创建训练和验证数据集:
trn_ds = MNIST('/content/', transform=img_transform, \
train=True, download=True)
val_ds = MNIST('/content/', transform=img_transform, \
train=False, download=True)4.定义数据加载器:
batch_size = 256
trn_dl = DataLoader(trn_ds, batch_size=batch_size, \
shuffle=True)
val_dl = DataLoader(val_ds, batch_size=batch_size, \
shuffle=False)5.定义网络架构。我们在方法中定义了AutoEncoder构成编码器和解码器的类__init__,以及瓶颈层的维度latent_dim,以及forward方法,并可视化模型摘要:
- 定义包含编码器、解码器和瓶颈层维度的AutoEncoder 类和 __init__方法:
class AutoEncoder(nn.Module):
def __init__(self, latent_dim):
super().__init__()
self.latend_dim = latent_dim
self.encoder = nn.Sequential(
nn.Linear(28 * 28, 128),
nn.ReLU(True),
nn.Linear(128, 64),
nn.ReLU(True),
nn.Linear(64, latent_dim))
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 64),
nn.ReLU(True),
nn.Linear(64, 128),
nn.ReLU(True),
nn.Linear(128, 28 * 28),
nn.Tanh())- 定义forward方法:
def forward(self, x):
x = x.view(len(x), -1)
x = self.encoder(x)
x = self.decoder(x)
x = x.view(len(x), 1, 28, 28)
return x- 可视化前面的模型:
!pip install torch_summary
from torchsummary import summary
model = AutoEncoder(3).to(device)
summary(model, torch.zeros(2,1,28,28))这将产生以下输出:
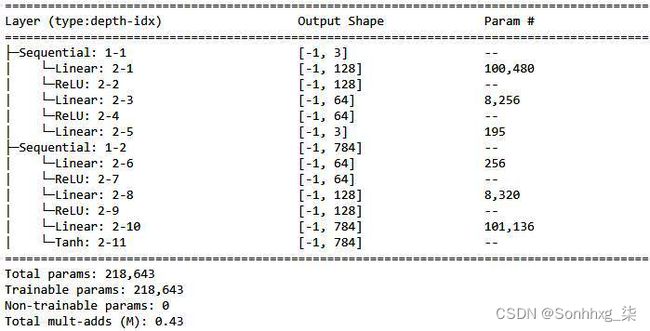
从前面的输出中,我们可以看到这Linear: 2-5 layer是瓶颈层,其中每张图像都表示为一个 3 维向量。此外,解码器层使用瓶颈层中的三个值重建原始图像。
6.定义一个函数来训练一批数据 ( train_batch),就像我们在前几章中所做的那样:
def train_batch(input, model, criterion, optimizer):
model.train()
optimizer.zero_grad()
output = model(input)
loss = criterion(output, input)
loss.backward()
optimizer.step()
return loss7.定义验证数据批的函数 ( validate_batch):
@torch.no_grad()
def validate_batch(input, model, criteria):
model.eval()
output = model(input)
loss = criteria(output, input)
return loss8.定义模型、损失标准和优化器:
model = AutoEncoder(3).to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.AdamW(model.parameters(), \
lr=0.001, weight_decay=1e-5)9.在越来越多的时期训练模型:
num_epochs = 5
log = Report(num_epochs)
for epoch in range(num_epochs):
N = len(trn_dl)
for ix, (data, _) in enumerate(trn_dl):
loss = train_batch(data, model, criteria, optimizer)
log .record(pos=(epoch + (ix+1)/N), \
trn_loss=loss, end='\r')
N = len(val_dl)
for ix, (data, _) in enumerate(val_dl):
loss = validate_batch(数据、模型、标准)
log.record(pos=(epoch + (ix+1)/N), \
val_loss=loss, end='\r')
log.report_avgs(epoch+1)10.可视化增加时期的训练和验证损失:
log.plot_epochs(log=True)前面的代码片段返回以下输出:

11.val_ds在训练期间未提供的数据集上验证模型:
for _ in range(3):
ix = np.random.randint(len(val_ds))
im, _ = val_ds[ix]
_im = model(im[None])[0]
fig, ax = plt.subplots(1, 2, figsize=(3,3))
show(im[0], ax=ax[0], title='input')
show(_im[0], ax=ax[1], title='prediction')
plt.tight_layout()
plt.show()上述代码的输出如下:

我们可以看到,即使瓶颈层只有三个维度,网络也可以非常准确地再现输入。然而,图像并不像我们预期的那样清晰。这主要是因为瓶颈层中的节点数量很少。在下图中,我们将在训练具有不同瓶颈层大小(2、3、5、10 和 50)的网络后可视化重建的图像:

很明显,随着瓶颈层中向量数量的增加,重建图像的清晰度提高了。
在下一节中,我们将学习如何使用卷积神经网络( CNN ) 生成更清晰的图像,并且我们将学习对相似图像进行分组。
了解卷积自动编码器
在上一节中,我们了解了自动编码器并在 PyTorch 中实现了它们。虽然我们已经实现了它们,但我们通过数据集获得的一个便利是每个图像只有一个通道(每个图像都表示为黑白图像)并且图像相对较小(28 x 28)。因此,网络使输入变平,并且能够在 784 (28*28) 个输入值上进行训练,以预测 784 个输出值。然而,在现实中,我们会遇到具有 3 个通道且比 28 x 28 图像大得多的图像。
在本节中,我们将学习如何实现能够处理多维输入图像的卷积自动编码器。然而,为了与普通自动编码器进行比较,我们将使用我们在上一节中使用的相同 MNIST 数据集,但以这样一种方式修改网络,即我们现在构建一个卷积自动编码器而不是普通自动编码器。
卷积自编码器表示如下:

从上图中,我们可以看到输入图像被表示为瓶颈层中的一个块,用于重建图像。图像经过多次卷积获取bottleneck表示(即通过Encoder得到的Bottleneck层),bottleneck表示被放大以获取原始图像(原始图像通过decoder重建)。
现在我们知道了卷积自动编码器是如何表示的,让我们在下面的代码中实现它:
1.步骤 1 到 4 与原版自动编码器部分完全相同,如下所示:
!pip install -q torch_snippets
from torch_snippets import *
from torchvision.datasets import MNIST
from torchvision import transforms
device = 'cuda' if torch.cuda.is_available() else 'cpu'
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
transforms.Lambda(lambda x: x.to(device))
])
trn_ds = MNIST('/content/', transform=img_transform, \
train=True, download=True)
val_ds = MNIST('/content/', transform=img_transform, \
train=False, download=True)
batch_size = 128
trn_dl = DataLoader(trn_ds, batch_size=batch_size, \
shuffle=True)
val_dl = DataLoader(val_ds, batch_size=batch_size, \
shuffle=False)2.定义神经网络的类,ConvAutoEncoder:
- 定义类和__init__方法:
class ConvAutoEncoder(nn.Module):
def __init__(self):
super().__init__()- 定义encoder架构:
self.encoder = nn.Sequential(
nn.Conv2d(1, 32, 3, stride=3, \
padding=1),
nn.ReLU(True),
nn.MaxPool2d(2, stride=2),
nn.Conv2d(32, 64, 3, stride=2, \
padding=1),
nn.ReLU(True),
nn.MaxPool2d(2, stride=1)
)请注意,在前面的代码中,我们从初始通道数开始,即1,并将其增加到32,然后将其进一步增加到 ,同时通过执行和操作64减小输出值的大小。nn.MaxPool2dnn.Conv2d
- 定义decoder架构:
self.decoder = nn.Sequential(
nn.ConvTranspose2d(64, 32, 3, \
stride=2),
nn.ReLU(True),
nn.ConvTranspose2d(32, 16, 5, \
stride=3,padding=1) ,
nn.ReLU(True),
nn.ConvTranspose2d(16, 1, 2, \
stride=2,padding=1),
nn.Tanh()
)- 定义forward方法:
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x3.使用方法获取模型的摘要summary:
model = ConvAutoEncoder().to(device)
!pip install torch_summary
from torchsummary import summary
summary(model, torch.zeros(2,1,28,28));前面的代码产生以下输出:
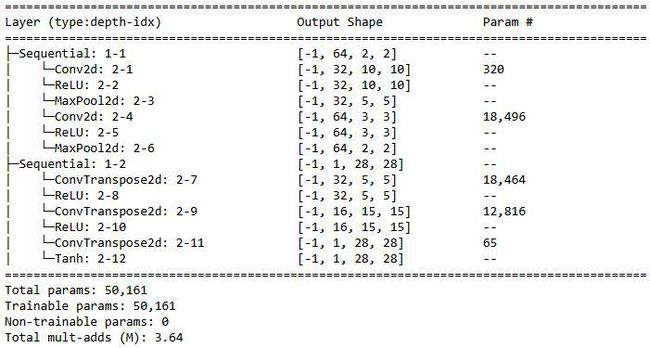
从前面的总结中,我们可以看到,MaxPool2d-6batch size x 64 x 2 x 2 的层作为瓶颈层。
一旦我们训练了模型,就像我们在上一节中所做的那样(在步骤 6、7、8 和 9 中),训练和验证损失随时间增加的变化以及对输入图像的预测如下:

从前面的图像中,我们可以看到卷积自动编码器能够比普通自动编码器对图像做出更清晰的预测。作为练习,我们建议您改变编码器和解码器中的通道数,然后分析结果的变化。
在下一节中,我们将解决在不存在图像标签时根据瓶颈层值对相似图像进行分组的问题。
使用 t-SNE 对相似图像进行分组
在前面的部分中,我们假设相似的图像将具有相似的嵌入,而不相似的图像将具有不同的嵌入,我们以低得多的维度表示每个图像。然而,我们还没有研究图像相似度度量或详细检查嵌入表示。
在本节中,我们将在二维空间中绘制嵌入(瓶颈)向量。我们可以使用称为t-SNE的技术将卷积自编码器的 64 维向量缩减为二维空间。(有关 t-SNE 的更多信息,请访问:http ://www.jmlr.org/papers/v9/vandermaaten08a.html 。)
这样,可以证明我们对相似图像将具有相似嵌入的理解,因为相似图像应该在二维平面中聚集在一起。在以下代码中,我们将在二维平面中表示所有测试图像的嵌入:
1.latent_vectors初始化列表,以便我们存储潜在向量classes(在表示方面确实彼此接近):
latent_vectors = []
classes = []2.遍历验证数据加载器 ( val_dl) 中的图像,并存储编码器层的输出和每个图像对应(model.encoder(im).view(len(im),-1)的类 ( ) ( ):clssim
for im,clss in val_dl:
latent_vectors.append(model.encoder(im).view(len(im),-1))
classes.extend(clss)3.连接 NumPy 数组latent_vectors:
latent_vectors = torch.cat(latent_vectors).cpu()\
.detach().numpy()4.导入 t-SNE ( TSNE) 并指定将每个向量转换为二维向量 ( TSNE(2)) 以便我们绘制它:
from sklearn.manifold import TSNE
tsne = TSNE(2)5.fit_transform通过在图像嵌入 ( ) 上运行该方法来拟合 t-SNE latent_vectors:
clustered = tsne.fit_transform(latent_vectors)6.绘制拟合 t-SNE 后的数据点:
fig = plt.figure(figsize=(12,10))
cmap = plt.get_cmap('Spectral', 10)
plt.scatter(*zip(*clustered), c=classes, cmap=cmap)
plt.colorbar(drawedges=True)上述代码提供以下输出:
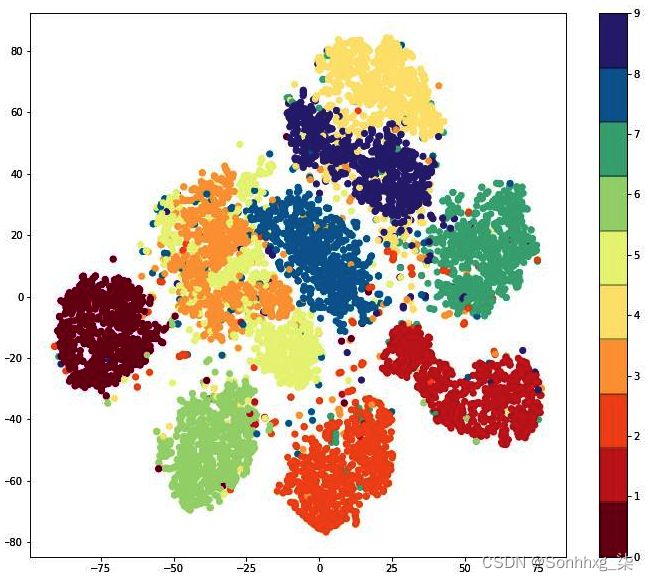
我们可以看到同一类的图像聚集在一起,这加强了我们对瓶颈层的值的理解,即看起来相似的图像将具有相似的值。
到目前为止,我们已经了解了如何使用自动编码器将相似的图像组合在一起。在下一节中,我们将学习使用自动编码器生成新图像。
了解变分自编码器
到目前为止,我们已经看到了一个场景,我们可以将相似的图像分组到集群中。此外,我们了解到,当我们对属于给定集群的图像进行嵌入时,我们可以重新构建(解码)它们。但是,如果嵌入(潜在向量)位于两个集群之间怎么办?无法保证我们会生成逼真的图像。在这种情况下,变分自动编码器会派上用场。
在我们深入构建变分自动编码器之前,让我们探索从不属于集群(或位于不同集群中间)的嵌入生成图像的局限性。首先,我们通过采样向量生成图像:
1.计算上一节中验证图像的潜在向量(嵌入):
latent_vectors = []
classes = []
for im,clss in val_dl:
latent_vectors.append(model.encoder(im))
classes.extend(clss)
latent_vectors = torch.cat(latent_vectors).cpu()\
.detach().numpy().reshape(10000, -1)2.生成具有列级均值 ( mu) 和标准差 ( ) 的随机向量,并在从均值和标准差创建向量之前sigma向标准差 ( ) 添加轻微噪声。torch.randn(1,100)最后,将它们保存在列表 ( rand_vectors) 中:
rand_vectors = []
for col in latent_vectors.transpose(1,0):
mu, sigma = col.mean(), col.std()
rand_vectors.append(sigma*torch.randn(1,100) + mu)3.绘制从步骤 2 中获得的向量和上一节中训练的模型重建的图像:
rand_vectors=torch.cat(rand_vectors).transpose(1,0).to(device)
fig,ax = plt.subplots(10,10,figsize=(7,7)); ax = iter(ax.flat)
for p in rand_vectors:
img = model.decoder(p.reshape(1,64,2,2)).view(28,28)
show(img, ax=next(ax))前面的代码产生以下输出:

从前面的输出中我们可以看到,当我们绘制由已知向量列的均值和添加了噪声的标准差生成的图像时,我们得到的图像不如以前清晰。这是一个真实的场景,因为我们事先不知道会生成真实图片的嵌入向量的范围。
变分自编码器( VAE ) 通过生成均值为 0、标准差为 1 的向量来帮助我们解决这个问题,从而确保我们生成均值为 0、标准差为 1 的图像。
本质上,在 VAE 中,我们指定瓶颈层应该遵循一定的分布。在接下来的部分中,我们将了解我们采用 VAE 采用的策略,我们还将了解 KL 散度损失,这有助于我们获取遵循特定分布的瓶颈特征。
VAE的工作
在 VAE 中,我们以这样一种方式构建网络,即从预定义分布生成的随机向量可以生成逼真的图像。这对于简单的自动编码器是不可能的,因为我们没有指定在网络中生成图像的数据分布。我们通过采用以下策略通过 VAE 实现这一点:
1.编码器的输出是每个图像的两个向量:
- 一个向量代表平均值。
- 另一个代表标准差。
2.从这两个向量中,我们获取一个修改后的向量,它是平均值和标准差的总和(乘以一个随机的小数)。修改后的向量将与每个向量具有相同的维数。
3.在上一步中获得的修改后的向量作为输入传递给解码器以获取图像。
4.我们优化的损失值是均方误差和 KL 散度损失的组合:
- KL 散度损失分别衡量平均向量和标准差向量的分布与 0 和 1 的偏差。
- 均方损失是我们用来重建(解码)图像的优化。
通过指定均值向量应具有以 0 为中心的分布,而标准差向量应以 1 为中心,我们正在以这样一种方式训练网络,即当我们生成均值为 0 且标准差为 1 的随机噪声时,解码器将能够生成逼真的图像。
此外,请注意,如果我们只最小化 KL 散度,编码器将预测平均向量的值为 0,每个输入的标准差为 1。因此,重要的是同时最小化 KL 散度损失和均方损失。
在下一节中,让我们了解 KL 散度,以便我们可以将其纳入模型的损失值计算中。
KL散度
KL 散度有助于解释两种数据分布之间的差异。在我们的特定情况下,我们希望我们的瓶颈特征值遵循平均值为 0 且标准差为 1 的正态分布。
因此,我们使用 KL 散度损失来了解我们的瓶颈特征值与平均值为 0 和标准差为 1 的值的预期分布有何不同。
让我们通过计算 KL 散度损失来看看它是如何提供帮助的:

在前面的等式中,σ 和 μ 代表每个输入图像的均值和标准差值。
让我们理解前面等式背后的直觉:
- 确保平均向量分布在 0 附近:
- 最小化上述等式中的均方误差 (
 ) 可确保
) 可确保 它尽可能接近 0。
它尽可能接近 0。
- 最小化上述等式中的均方误差 (
- 确保标准差向量分布在 1 附近:
- 等式其余部分(除了)确保 sigma(标准差向量)分布在 1 附近。
- 等式其余部分(除了
现在我们了解了构建 VAE 的高级策略和最小化损失函数以获得编码器输出的预定义分布,让我们在下一节中实现 VAE。
建立一个 VAE
在本节中,我们将编写一个 VAE 来生成手写数字的新图像。
由于我们有相同的数据,实施 vanilla autoencoders部分中的所有步骤都保持不变,除了步骤 5 和 6,我们分别定义网络架构和训练模型,我们在以下代码中定义:
1.步骤 1 到步骤 4 与 vanilla autoencoder 部分完全相同,如下所示:
!pip install -q torch_snippets
from torch_snippets import *
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.utils import make_grid
device = 'cuda' if torch.cuda.is_available() else 'cpu'
train_dataset = datasets.MNIST(root='MNIST/', train=True, \
transform=transforms.ToTensor(), \
download=True)
test_dataset = datasets.MNIST(root= 'MNIST/', train=False, \
transform=transforms.ToTensor(), \
download=True)
train_loader = torch.utils.data.DataLoader(dataset = \
train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset= \
test_dataset, batch_size=64, shuffle=False)2.定义神经网络类,VAE:
- 在__init__方法中定义将在其他方法中使用的层:
class VAE(nn.Module):
def __init__(self, x_dim, h_dim1, h_dim2, z_dim):
super(VAE, self).__init__()
self.d1 = nn.Linear(x_dim, h_dim1)
self.d2 = nn.Linear(h_dim1, h_dim2)
self.d31 = nn.Linear(h_dim2, z_dim)
self.d32 = nn.Linear(h_dim2, z_dim)
self.d4 = nn.Linear(z_dim, h_dim2)
self.d5 = nn.Linear(h_dim2, h_dim1)
self.d6 = nn.Linear(h_dim1, x_dim)请注意,d1和d2层将对应于编码器部分,d5并且d6将对应于解码器部分。和层是分别对应于均值和标准差向量的层。然而,为方便起见,我们将做的一个假设是,我们将使用该层作为方差向量对数的表示。d31d32d32
- 定义encoder方法:
def encoder(self, x):
h = F.relu(self.d1(x))
h = F.relu(self.d2(h))
return self.d31(h), self.d32(h)请注意,编码器返回两个向量:一个向量表示均值(self.d31(h)),另一个向量表示方差值的对数(self.d32(h))。
- sampling定义从编码器输出中采样 ( ) 的方法:
def sampling(self, mean, log_var):
std = torch.exp(0.5*log_var)
eps = torch.randn_like(std)
return eps.mul(std).add_(mean)请注意,0.5*log_var ( torch.exp(0.5*log_var)) 的指数表示标准偏差 ( std)。此外,我们返回平均值和标准偏差乘以随机正态分布产生的噪声。通过乘以eps,我们确保即使编码器向量发生轻微变化,我们也可以生成图像。
- 定义decoder方法:
def decoder(self, z):
h = F.relu(self.d4(z))
h = F.relu(self.d5(h))
return F.sigmoid(self.d6(h))- 定义forward方法:
def forward(self, x):
mean, log_var = self.encoder(x.view(-1, 784))
z = self.sampling(mean, log_var)
return self.decoder(z), mean, log_var在前面的方法中,我们确保编码器返回方差值的均值和对数。接下来,我们通过添加均值与 epsilon 乘以方差的对数进行采样,并在通过解码器后返回值。
3.定义函数以在批次上进行训练并在批次上进行验证:
def train_batch(data, model, optimizer, loss_function):
model.train()
data = data.to(device)
optimizer.zero_grad()
recon_batch, mean, log_var = model(data)
loss, mse, kld = loss_function(recon_batch, data, \
mean, log_var)
loss.backward()
optimizer.step()
return loss, mse, kld, log_var.mean(), mean.mean()
@torch.no_grad()
def validate_batch(data, model, loss_function):
model.eval()
data = data.to(device)
recon, mean, log_var = model(data)
loss, mse, kld = loss_function(recon, data, mean, \
log_var)
return loss, mse, kld, log_var.mean(), mean.mean()4.定义损失函数:
def loss_function(recon_x, x, mean, log_var):
RECON = F.mse_loss(recon_x, x.view(-1, 784), \
reduction='sum')
KLD = -0.5 * torch.sum(1 + log_var - mean.pow(2) - \
log_var.exp())
return RECON + KLD, RECON, KLD在前面的代码中,我们获取RECON原始图像 ( x) 和重建图像 ( ) 之间的 MSE 损失 ( recon_x)。KLD接下来,我们根据我们在上一节中定义的公式计算 KL 散度损失 ( )。请注意,方差对数的指数是方差值。
5.定义模型对象 ( vae) 和optimizer函数:
vae = VAE(x_dim=784, h_dim1=512, h_dim2=256, \
z_dim=50).to(device)
optimizer = optim.AdamW(vae.parameters(), lr=1e-3)6.在越来越多的时期训练模型:
n_epochs = 10
log = Report(n_epochs)
for epoch in range(n_epochs):
N = len(train_loader)
for batch_idx, (data, _) in enumerate(train_loader):
loss, recon, kld, log_var, mean = train_batch(data, \
vae, optimizer, \
loss_function)
pos = epoch + (1+batch_idx)/N
log.record(pos, train_loss=loss, train_kld=kld, \
train_recon=recon,train_log_var=log_var, \
train_mean=mean, end='\r')
N = len(test_loader)
for batch_idx, (data, _) in enumerate(test_loader):
loss, recon, kld,log_var,mean = validate_batch(data, \
vae, loss_function)
pos = epoch + (1+batch_idx)/N
log.record(pos, val_loss=loss, val_kld=kld, \
val_recon=recon, val_log_var=log_var, \
val_mean=mean, end='\r')
log.report_avgs(epoch+1)
with torch.no_grad():
z = torch.randn(64, 50).to(device)
sample = vae.decoder(z).to(device)
images = make_grid(sample.view(64, 1, 28, 28))\
.permute(1,2,0)
show(images)
log.plot_epochs(['train_loss','val_loss'])虽然前面的大部分代码都很熟悉,但让我们了解一下网格图像的生成过程。我们首先生成一个随机向量 ( z) 并将其传递给解码器 ( vae.decoder) 以获取图像样本。该make_grid 函数绘制图像(如果需要,在绘制之前自动对它们进行非规范化)。
损失值变化的输出和生成的图像样本如下:

我们可以看到我们能够生成原始图像中不存在的逼真的新图像。
到目前为止,我们已经了解了如何使用 VAE 生成新图像。但是,如果我们想以模型无法识别正确类别的方式修改图像怎么办?我们将在下一节中了解用于解决此问题的技术。
对图像进行对抗性攻击
在上一节中,我们学习了如何使用 VAE 从随机噪声中生成图像。然而,这是一个无人监督的练习。如果我们想以这样一种方式修改图像,使图像的变化非常小,以至于人类无法将其与原始图像区分开来,但神经网络模型仍将对象视为属于不同的类别,该怎么办?在这种情况下,对图像的对抗性攻击会派上用场。
对抗性攻击是指我们对输入图像值(像素)所做的更改,以便我们达到某个目标。
在本节中,我们将了解如何稍微修改图像,使预训练模型现在将它们预测为不同的类别(由用户指定)而不是原始类别。我们将采取的策略如下:
- 提供大象的图像。
- 指定图像对应的目标类。
- 导入一个预训练模型,其中模型的参数已设置为不更新 ( gradients = False)。
- 指定我们计算输入图像像素值的梯度,而不是网络的权重值。这是因为在训练欺骗网络时,我们无法控制模型,而只能控制我们发送给模型的图像。
- 计算模型预测和目标类对应的损失。
- 对模型执行反向传播。这一步帮助我们理解与每个输入像素值相关的梯度。
- 根据每个输入像素值对应的梯度方向更新输入图像像素值。
- 在多个时期重复步骤 5、6和7 。
让我们用代码来做这件事:
1.导入相关包、我们为此用例处理的图像以及预训练的ResNet50模型。另外,指定我们要冻结参数:
!pip install torch_snippets
from torch_snippets import inspect, show, np, torch, nn
from torchvision.models import resnet50
model = resnet50(pretrained=True)
for param in model.parameters():
param.requires_grad = False
model = model.eval()
import requests
from PIL import Image
url = 'https://lionsvalley.co.za/wp-content/uploads/2015/11/african-elephant-square.jpg'
original_image = Image.open(requests.get(url, stream=True)\
.raw).convert('RGB')
original_image = np.array(original_image)
original_image = torch.Tensor(original_image)2.导入 Imagenet 类并为每个类分配 ID:
image_net_classes = 'https://gist.githubusercontent.com/yrevar/942d3a0ac09ec9e5eb3a/raw/238f720ff059c1f82f368259d1ca4ffa5dd8f9f5/imagenet1000_clsidx_to_labels.txt'
image_net_classes = requests.get(image_net_classes).text
image_net_ids = eval(image_net_classes)
image_net_classes = {i:j for j,i in image_net_ids.items()}3.指定一个函数来规范化 ( image2tensor) 和tensor2image反规范化 ( ) 图像:
from torchvision import transforms as T
from torch.nn import functional as F
normalize = T.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
denormalize=T.Normalize( \
[-0.485/0.229,-0.456/0.224,-0.406/0.225],
[1/0.229, 1/0.224, 1/0.225])
def image2tensor(input):
x = normalize(input.clone().permute(2,0,1)/255.)[None]
return x
def tensor2image(input):
x = (denormalize(input[0].clone()).permute(1,2,0)*255.)\
.type(torch.uint8)
return x4.定义一个函数来预测给定图像 ( predict_on_image):
def predict_on_image(input):
model.eval()
show(input)
input = image2tensor(input)
pred = model(input)
pred = F.softmax(pred, dim=-1)[0]
prob, clss = torch.max (pred, 0)
clss = image_net_ids[clss.item()]
print(f'PREDICTION: `{clss}` @ {prob.item()}')在前面的代码中,我们将输入图像转换为张量(这是一个使用image2tensor前面定义的方法进行归一化的函数)并通过 amodel来获取clss图像中对象的类( )和预测的概率(prob)。
5.定义attack函数:
- 该attack函数将image、model和target作为输入:
from tqdm import trange
loss = []
def attack(image, model, target, epsilon=1e-6):- 将图像转换为张量并指定输入需要计算梯度:
input = image2tensor(image)
input.requires_grad = True- 将归一化的输入 ( ) 通过模型计算预测input,然后计算指定目标类对应的损失值:
pred = model(input)
loss = nn.CrossEntropyLoss()(pred, target)- 执行反向传播以减少损失:
loss.backward()
loss.append(loss.mean().item())- 根据梯度方向非常轻微地更新图像:
output = input - epsilon * input.grad.sign()在前面的代码中,我们将输入值更新了非常小的量(乘以epsilon)。此外,我们不是通过梯度的大小来更新图像,而是仅在将梯度input.grad.sign()乘以一个非常小的值 ( ) 之后( ) 来更新图像epsilon。
- 将张量转换为图像 ( tensor2image) 后返回输出,该图像对图像进行非规范化:
output = tensor2image(output)
del input
return output.detach()6.将图像修改为属于不同的类:
- 指定desired_targets我们要将图像转换为的目标 ( ):
modified_images = []
desired_targets = ['lemon', 'comic book', 'sax, saxophone']- 循环遍历目标并在每次迭代中指定目标类:
for target in desired_targets:
target = torch.tensor([image_net_classes[target]])- 修改图像以攻击不断增加的 epoch 并将它们收集到一个列表中:
image_to_attack = original_image.clone()
for _ in trange(10):
image_to_attack = attack(image_to_attack,model,target)
modified_images.append(image_to_attack)- 以下代码生成修改后的图像和相应的类:
for image in [original_image, *modified_images]:
predict_on_image(image)
inspect(image)前面的代码生成以下内容:

我们可以看到,当我们对图像进行非常轻微的修改时,预测类别完全不同,但置信度非常高。
现在我们了解了如何修改图像以使其按我们的意愿分类,在下一节中,我们将学习如何以我们选择的样式修改图像(内容图像)。我们必须提供内容图像和样式图像。
执行神经风格迁移
在神经风格迁移中,我们有一个内容图像和一个风格图像,我们将这两个图像组合在一起,使得组合图像在保留内容图像的内容的同时保持风格图像的风格。
示例样式图像和内容图像如下:

在上图中,我们要保留右图(内容图)中的内容,但用左图(风格图)中的颜色和纹理进行叠加。
执行神经风格迁移的过程如下。我们尝试通过将损失值拆分为内容损失和样式损失的方式来修改原始图像。内容损失是指生成的图像与内容图像的差异程度。风格损失是指风格图像与生成图像的相关程度。
虽然我们提到损失是根据图像的差异计算的,但实际上,我们通过确保使用图像的特征层激活而不是原始图像来计算损失来稍微修改它。例如,第 2 层的内容损失将是内容图像的激活值与通过第二层时生成的图像之间的平方差。
损失是在特征层而不是原始图像上计算的,因为特征层捕获了原始图像的某些属性(例如,在较高层中对应于原始图像的前景轮廓以及在较高层中细粒度对象的细节)下层)。
虽然计算内容损失看起来很简单,但让我们尝试了解如何计算生成图像和风格图像之间的相似度。一种称为gram 矩阵的技术派上用场了。Gram矩阵计算生成的图像和风格图像的相似度,计算如下:
GM[l]是风格图像S和生成图像G在第l层的 gram 矩阵值。 一个 gram 矩阵是由一个矩阵乘以它自身的转置得到的。让我们了解一下这个操作的使用。
想象一下,您正在处理具有 32 x 32 x 256 特征输出的层。gram 矩阵计算为通道中每个 32 x 32 值与所有通道中的值的相关性。因此,gram 矩阵计算得到一个形状为 256 x 256 的矩阵。我们现在比较风格图像和生成图像的 256 x 256 值来计算风格损失。
让我们了解为什么 GramMatrix 对风格迁移很重要。
在一个成功的场景中,假设我们将毕加索的风格转移到蒙娜丽莎上。我们称毕加索风格为St(代表风格),原始蒙娜丽莎So(代表源),最终图像Ta(代表目标)。请注意,在理想情况下,图像Ta中的局部特征与St中的局部特征相同。尽管内容可能不一样,但将与风格图像相似的颜色、形状和纹理放入目标图像中是风格转移的重要内容。
通过扩展,如果我们发送So并从 VGG19 的中间层提取其特征,它们将与发送Ta获得的特征不同。然而,在每个特征集中,对应的向量将以相似的方式彼此相对变化。例如,在两个特征集中,第一个通道的平均值与第二个通道的平均值之比将是相似的。这就是我们尝试使用 Gram Loss 进行计算的原因。
现在我们可以计算风格损失和内容损失,最终修改后的输入图像是最小化整体损失的图像,即风格和内容损失的加权平均值。
我们用于实现神经风格迁移的高级策略如下:
- 通过预训练模型传递输入图像。
- 提取预定义层的层值。
- 将生成的图像通过模型并在相同的预定义层提取其值。
- 计算内容图像和生成图像对应的每一层的内容损失。
- 将风格图像通过模型的多层传递,并计算风格图像的 gram 矩阵值。
- 将生成的图像通过样式图像通过的相同层,并计算其对应的 gram 矩阵值。
- 提取两幅图像的 gram 矩阵值的平方差。这将是风格损失。
- 整体损失将是风格损失和内容损失的加权平均值。
- 最小化整体损失的输入图像将是最终感兴趣的图像。
现在让我们编写前面的策略:
1.导入相关包:
!pip install torch_snippets
from torch_snippets import *
from torchvision import transforms as T
from torch.nn import functional as F
device = 'cuda' if torch.cuda.is_available() else 'cpu'2.定义预处理和后处理数据的函数:
from torchvision.models import vgg19
preprocess = T.Compose([
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
T.Lambda(lambda x: x.mul_(255))
])
postprocess = T.Compose([
T.Lambda(lambda x: x.mul_(1./255)),
T.Normalize(\
mean=[-0.485/0.229,-0.456/0.224,-0.406/0.225],
std=[1/0.229, 1/0.224, 1/0.225]),
])3.定义模块: GramMatrix
class GramMatrix(nn.Module):
def forward(self, input):
b,c,h,w = input.size()
feat = input.view(b, c, h*w)
G = [email protected](1,2)
G.div_(h*w)
return G在前面的代码中,我们正在计算特征与其自身的所有可能的内积,这基本上是在询问所有向量之间的关系。
4.定义 gram 矩阵对应的 MSE 损失,GramMSELoss:
class GramMSELoss(nn.Module):
def forward(self, input, target):
out = F.mse_loss(GramMatrix()(input), target)
return(out)一旦我们有了两个特征集的 gram 向量,重要的是它们尽可能地匹配,因此mse_loss.
5.定义模型类,vgg19_modified:
- 初始化类:
class vgg19_modified(nn.Module):
def __init__(self):
super().__init__()- 提取特征:
features = list(vgg19(pretrained = True).features)
self.features = nn.ModuleList(features).eval()- 定义forward方法,它接受层列表并返回对应于每一层的特征:
def forward(self, x, layers=[]):
order = np.argsort(layers)
_results, results = [], []
for ix,model in enumerate(self.features):
x = model(x)
if ix in layers: _results.append(x)
for o in order: results.append(_results[o])
return results if layers is not [] else x- 定义模型对象:
vgg = vgg19_modified().to(device)6.导入内容和样式图像:
!wget https://www.dropbox.com/s/z1y0fy2r6z6m6py/60.jpg
!wget https://www.dropbox.com/s/1svdliljyo0a98v/style_image.png- 确保将图像大小调整为相同的形状,512 x 512 x 3:
imgs = [Image.open(path).resize((512,512)).convert('RGB') \
for path in ['style_image.png', '60.jpg']]
style_image,content_image=[preprocess(img) .to(device)[None] \
for imgs in imgs]7.指定要修改的内容图像requires_grad = True:
opt_img = content_image.data.clone()
opt_img.requires_grad = True8.指定定义内容损失和样式损失的层,即我们使用的中间 VGG 层,以比较内容的样式和原始特征向量的 gram 矩阵:
style_layers = [0, 5, 10, 19, 28]
content_layers = [21]
loss_layers = style_layers + content_layers9.定义内容和风格损失值的损失函数:
loss_fns = [GramMSELoss()] * len(style_layers) + \
[nn.MSELoss()] * len(content_layers)
loss_fns = [loss_fn.to(device) for loss_fn in loss_fns]10.定义与内容和风格损失相关的权重:
style_weights = [1000/n**2 for n in [64,128,256,512,512]]
content_weights = [1]
weights = style_weights + content_weights11.我们需要操纵我们的图像,使目标图像的风格style_image尽可能地相似。因此,我们通过计算从几个选定的 VGG 层获得的特征来计算 的style_targets值。由于应该保留整体内容,我们选择计算 VGG 原始特征的变量:style_imageGramMatrixcontent_layer
style_targets = [GramMatrix()(A).detach() for A in \
vgg(style_image, style_layers)]
content_targets = [A.detach() for A in \
vgg(content_image, content_layers)]
targets = style_targets + content_targets12.定义optimizer迭代次数 ( max_iters)。尽管我们可以使用 Adam 或任何其他优化器,但 LBFGS 是一种已被观察到在确定性场景中效果最佳的优化器。此外,由于我们只处理一张图像,因此没有任何随机性。许多实验表明 LBFGS 收敛速度更快,并且在神经传输设置中可以降低损失,因此我们将使用这个优化器:
max_iters = 500
optimizer = optim.LBFGS([opt_img])
log = Report(max_iters)13.执行优化。在我们一次又一次地在同一个张量上迭代的确定性场景中,我们可以将优化器步骤包装为一个具有零参数的函数并重复调用它,如下所示:
iters = 0
while iters < max_iters: defclosure
():
global iters
iters += 1
optimizer.zero_grad()
out = vgg(opt_img, loss_layers)
layer_losses = [weights[a]*loss_fns[a](A,targets[a ]) \
for a,A in enumerate(out)]
loss = sum(layer_losses)
loss.backward()
log.record(pos=iters, loss=loss, end='\r')
return loss
optimizer.step(closure )14.绘制损失的变化:
log.plot(log=True)这将产生以下输出:
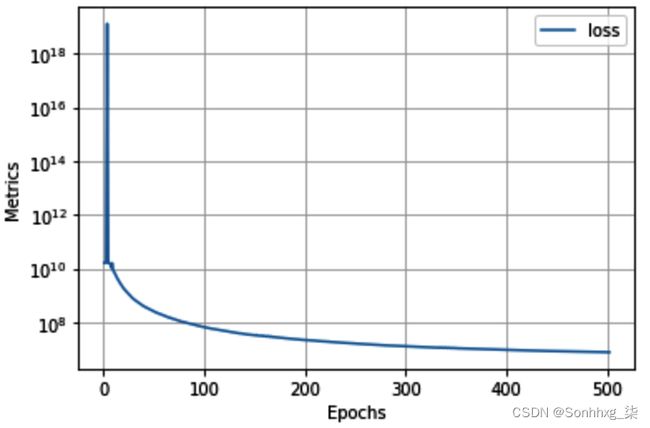
15.使用内容和样式图像的组合绘制图像:
out_img = postprocess(opt_img[0]).permute(1,2,0)
show(out_img)输出如下:

从上图中我们可以看出,该图像是内容图像和风格图像的组合。
有了这个,我们已经看到了两种处理图像的方法:一种是修改图像类别的对抗性攻击,另一种是风格转移,将一张图像的风格与另一张图像的内容相结合。在下一节中,我们将学习如何生成深度伪造,将表情从一张脸转移到另一张脸。
产生深度造假
到目前为止,我们已经了解了两种不同的图像到图像任务:使用 UNet 进行语义分割和使用自动编码器进行图像重建。深度伪造是一种图像到图像的任务,具有非常相似的基础理论。
想象一个场景,您想要创建一个应用程序,该应用程序获取给定的面部图像并以您想要的方式更改面部表情。在这种情况下,深度伪造会派上用场。虽然我们不会在本书中讨论最新的深度伪造,但开发了诸如小样本对抗学习之类的技术来生成具有感兴趣面部表情的逼真图像。了解深度造假的工作原理和 GAN(您将在下一章中了解)将帮助您识别假视频。
在深度伪造任务中,我们将有几百张 A 的照片和几百张 B 的照片。目标是用 A 的面部表情重建 B 的面部,反之亦然。
下图解释了深度伪造图像生成过程的工作原理:

在上图中,我们通过编码器 ( Encoder ) 传递人 A 和人 B 的图像。一旦我们得到与人 A ( Latent Face A ) 和人 B ( Latent Face B ) 对应的潜在向量,我们将潜在向量传递给它们对应的解码器(解码器 A和解码器 B)以获取对应的原始图像(重构的人脸 A和重建的B面)。到目前为止,编码器和解码器的概念与我们在自动编码器部分学到的非常相似。但是,在这种情况下,我们只有一个编码器,但有两个解码器(每个解码器对应不同的人)。期望是从编码器获得的潜在向量表示有关图像中存在的面部表情的信息,而解码器获取与人相对应的图像。一旦编码器和两个解码器都经过训练,在执行深度伪造图像生成时,我们在架构内切换连接,如下所示:
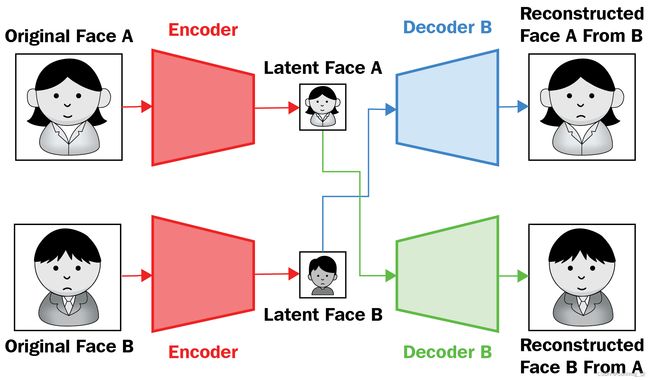
当人 A 的潜在向量通过解码器 B 时,人 B 的重建面部将具有人 A(笑脸)的特征,反之亦然,当通过解码器 A(悲伤脸)时人 B 的特征。
现在我们了解了它的工作原理,让我们使用带有以下代码的自动编码器来实现一个人的假图像与另一个人的表情的生成:
1.让我们下载数据和源代码如下:
import os
if not os.path.exists('Faceswap-Deepfake-Pytorch'):
!wget -q https://www.dropbox.com/s/5ji7jl7httso9ny/person_images.zip
!wget -q https://raw.githubusercontent.com/sizhky/deep-fake-util/main/random_warp.py
!unzip -q person_images.zip
!pip install -q torch_snippets torch_summary
from torch_snippets import *
from random_warp import get_training_data2.从图像中获取面部裁剪:
- 定义面部级联,它在图像中的面部周围绘制一个边界框。在第 18 章,用于图像分析的 OpenCV 实用程序中有更多关于级联的内容。然而,就目前而言,面部级联在图像中存在的面部周围绘制了一个紧密的边界框就足够了:
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + \
'haarcascade_frontalface_default.xml')- 定义一个函数 ( crop_face) 用于从图像中裁剪人脸:
def crop_face(img):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
if(len(faces)>0):
for (x,y,w,h) in faces:
img2 = img[y:(y+h),x:(x+w),:]
img2 = cv2.resize(img2,(256,256))
return img2, True
else:
return img, False在前面的函数中,我们gray通过人脸级联传递灰度图像 ( ) 并裁剪包含人脸的矩形。接下来,我们将返回一个调整大小的图像 ( img2)。此外,为了考虑在图像中没有检测到人脸的情况,我们传递了一个标志来显示是否检测到人脸。
- 裁剪 和 的图像personA并将personB它们放在单独的文件夹中:
!mkdir cropped_faces_personA
!mkdir cropped_faces_personB
def crop_images(folder):
images = Glob(folder+'/*.jpg')
for i in range(len(images)):
img = read(images[i],1)
img2, face_detected = crop_face(img)
if(face_detected==False):
continue
else:
cv2.imwrite('cropped_faces_'+folder+'/'+str(i)+ \
'.jpg',cv2.cvtColor(img2, cv2.COLOR_RGB2BGR))
crop_images('personA')
crop_images('personB')3.创建一个数据加载器并检查数据:
class ImageDataset(Dataset):
def __init__(self, items_A, items_B):
self.items_A = np.concatenate([read(f,1)[None] \
for f in items_A])/255.
self.items_B = np.concatenate([read(f,1)[None] \
for f in items_B])/255.
self.items_A += self.items_B.mean(axis=(0, 1, 2)) \
- self.items_A.mean(axis=(0, 1, 2))
def __len__(self):
return min(len(self.items_A), len(self.items_B))
def __getitem__(self, ix):
a, b = choose(self.items_A), choose(self.items_B)
return a, b
def collate_fn(self, batch):
imsA, imsB = list(zip(*batch))
imsA, targetA = get_training_data(imsA, len(imsA))
imsB, targetB = get_training_data(imsB, len(imsB))
imsA, imsB, targetA, targetB = [torch.Tensor(i)\
.permute(0,3,1,2)\
.to(device) \
for i in [imsA, imsB,\
targetA, targetB]]
return imsA, imsB, targetA, targetB
a = ImageDataset(Glob('cropped_faces_personA'), \
Glob('cropped_faces_personB'))
x = DataLoader(a, batch_size=32, collate_fn=a.collate_fn)数据加载器返回四个张量 ,imsA, imsB, 和。第一个张量 ( ) 是第三张量 ( ) 的扭曲(扭曲)版本,第二个 ( ) 是第四张量 ( ) 的扭曲(扭曲)版本。targetA targetBimsAtargetAimsBtargetB
此外,正如您在该行中看到的a =ImageDataset(Glob('cropped_faces_personA'), Glob('cropped_faces_personB')),我们有两个图像文件夹,每个人一个。任何人脸之间都没有关系,并且在__iteritems__ 数据集中,我们每次都随机获取两张人脸。
这一步的关键功能是get_training_data,存在于collate_fn. 这是用于扭曲(扭曲)面的增强功能。我们将扭曲的人脸作为自动编码器的输入,并尝试预测常规人脸。
- 让我们检查一些图像:
inspect(*next(iter(x)))
for i in next(iter(x)):
subplots(i[:8], nc=4, sz=(4,2))前面的代码产生以下输出:

请注意,输入图像是扭曲的,而输出图像不是,并且输入到输出图像现在具有一一对应的关系。
4.构建模型并检查它:
- 定义卷积 ( _ConvLayer) 和升级 ( _UpScale) 函数以及Reshape在构建模型时将使用的类:
def _ConvLayer(input_features, output_features):
return nn.Sequential(
nn.Conv2d(input_features, output_features,
kernel_size=5, stride=2, padding=2),
nn.LeakyReLU(0.1, inplace=True)
)
def _UpScale(input_features, output_features):
return nn.Sequential(
nn.ConvTranspose2d(input_features, output_features,
kernel_size=2, stride=2, padding=0),
nn.LeakyReLU(0.1, inplace=True)
)
class Reshape(nn.Module):
def forward(self, input):
output = input.view(-1, 1024, 4, 4) # channel * 4 * 4
return output- 定义Autoencoder模型类,它有一个encoder和两个解码器(decoder_A和decoder_B):
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
_ConvLayer(3, 128),
_ConvLayer(128, 256),
_ConvLayer(256, 512),
_ConvLayer(512, 1024),
nn.Flatten(),
nn.Linear(1024 * 4 * 4, 1024),
nn.Linear(1024, 1024 * 4 * 4),
Reshape(),
_UpScale(1024, 512),
)
self.decoder_A = nn.Sequential(
_UpScale(512, 256),
_UpScale(256, 128),
_UpScale(128, 64),
nn.Conv2d(64, 3, kernel_size=3, \
padding=1),
nn.Sigmoid(),
)
self.decoder_B = nn.Sequential(
_UpScale(512, 256),
_UpScale(256, 128),
_UpScale(128, 64),
nn.Conv2d(64, 3, kernel_size=3, \
padding=1),
nn.Sigmoid(),
)
def forward(self, x, select='A'):
if select == 'A':
out = self.encoder(x)
out = self.decoder_A(out)
else:
out = self.encoder(x)
out = self.decoder_B(out)
return out- 生成模型摘要:
from torchsummary import summary
model = Autoencoder()
summary(model, torch.zeros(32,3,64,64), 'A');
5.定义train_batch逻辑:
def train_batch(model, data, criterion, optimizes):
optA, optB = optimizers
optA.zero_grad()
optB.zero_grad()
imgA, imgB, targetA, targetB = data
_imgA, _imgB = model(imgA, 'A'), model(imgB, 'B')
lossA = criterion(_imgA, targetA)
lossB = criterion(_imgB, targetB)
lossA.backward()
lossB.backward()
optA.step()
optB.step()
return lossA.item(), lossB.item()我们感兴趣的是运行model(imgA, 'B')(它将使用来自 A 类的输入图像返回 B 类的图像),但我们没有一个基本事实来比较它。因此,相反,我们正在做的是_imgA从imgA(哪里imgA是扭曲的版本targetA)进行预测并_imgA与targetA使用比较nn.L1Loss。
我们不需要validate_batch,因为没有验证数据集。我们将在训练期间预测新图像并定性地查看进度。
6.创建训练模型所需的所有组件:
model = Autoencoder().to(device)
dataset = ImageDataset(Glob('cropped_faces_personA'), \
Glob('cropped_faces_personB'))
dataloader = DataLoader(dataset, 32, \
collate_fn=dataset.collate_fn)
optimizers=optim.Adam( \
[{'params': model.encoder.parameters()}, \
{'params': model.decoder_A.parameters()}], \
lr=5e-5, betas=(0.5, 0.999)), \
optim.Adam([{'params': model.encoder.parameters()}, \
{'params': model.decoder_B.parameters()}], \
lr=5e-5, betas=(0.5, 0.999))
criterion = nn.L1Loss()7.训练模型:
n_epochs = 1000
log = Report(n_epochs)
!mkdir checkpoint
for ex in range(n_epochs):
N = len(dataloader)
for bx,data in enumerate(dataloader):
lossA, lossB = train_batch(model, data,
criterion, optimizers)
log.record(ex+(1+bx)/N, lossA=lossA,
lossB=lossB, end='\r')
log.report_avgs(ex+1)
if (ex+1)%100 == 0:
state = {
'state': model.state_dict(),
'epoch': ex
}
torch.save(state, './checkpoint/autoencoder.pth')
if (ex+1)%100 == 0:
bs = 5
a,b,A,B = data
line('A to B')
_a = model(a[:bs], 'A')
_b = model(a[:bs], 'B')
x = torch.cat([A[:bs],_a,_b])
subplots(x, nc=bs, figsize=(bs*2, 5))
line('B to A')
_a = model(b[:bs], 'A')
_b = model(b[:bs], 'B')
x = torch.cat([B[:bs],_a,_b])
subplots(x, nc=bs, figsize=(bs*2, 5))
log.plot_epochs()上述代码生成重建图像,如下所示:

损失值的变化如下:

如您所见,我们可以通过调整自动编码器以拥有两个解码器而不是一个来将表情从一张脸交换到另一张脸。此外,随着时期数的增加,重建的图像变得更加逼真。
概括
在本章中,我们了解了自动编码器的不同变体:普通、卷积和变分。我们还了解了瓶颈层中的单元数量如何影响重建图像。接下来,我们学习了如何使用 t-SNE 技术识别与给定图像相似的图像。我们了解到,当我们对向量进行采样时,我们无法获得逼真的图像,并且通过使用变分自编码器,我们学会了通过使用重建损失和 KL 散度损失的组合来生成新图像。接下来,我们学习了如何对图像进行对抗性攻击,以修改图像的类别,同时不改变图像的感知内容。最后,我们了解了如何利用内容损失和基于 gram 矩阵的样式损失的组合来优化图像的内容和样式损失,从而得出由两个输入图像组合而成的图像。最后,我们了解了如何调整自动编码器以在没有任何监督的情况下交换两张脸。
现在我们已经了解了如何从一组给定的图像生成新图像,在下一章中,我们将在这个主题的基础上使用称为生成对抗网络的网络变体生成全新的图像。
问题
- 什么是自动编码器中的编码器?
- 自编码器针对什么损失函数进行优化?
- 自动编码器如何帮助对相似图像进行分组?
- 卷积自动编码器何时有用?
- 如果我们从从 vanilla/卷积自动编码器获得的嵌入向量空间中随机采样,为什么我们会得到非直观的图像?
- VAE 优化的损失函数是什么?
- VAE 如何克服 vanilla/卷积自动编码器生成新图像的限制?
- 在对抗性攻击期间,为什么我们要修改输入图像像素而不是权重值?
- 在神经风格迁移中,我们优化的损失是什么?
- 为什么我们在计算样式和内容损失时考虑不同层的激活而不是原始图像?
- 为什么我们在计算风格损失时要考虑 gram 矩阵损失而不是图像之间的差异?
- 为什么我们在构建模型以生成深度伪造时扭曲图像?