【RTOS训练营】继续程序框架、tick中断补充、预习、课后作业和晚课提问
一:程序框架
1.1 调用关系
我们先来看看各层函数的调用关系。
函数的调用关系,可以从单元测试的代码去看。
如下图是第一步:

首先加入输入设备,即把设备放入链表:

然后是初始化,即把链表中的每个设备,都调用它的初始化函数。

大家的疑问可能在于设备的初始化:

我们去构造这个输入设备的时候,就给他提供了一个函数,
这个函数的目的是用来初始化硬件,就比如说设置中断。
为什么要写的那么复杂呢?
我把这个函数调用关系给列出来:
GPIOKeyInit
KAL_GPIOKkeyInit
CAL_GPIOKkeyInit
KEY_GPIO_ReInit
这段过程有4个函数,之所以引入那么多函数,是因为:
- 想支持裸机、支持FreeRTOS、支持RT-Thread
- 想支持HAL库,也支持非HAL库
这里的第1点,怎么去支持那么多操作系统?
我们把代码给大家完善一下:
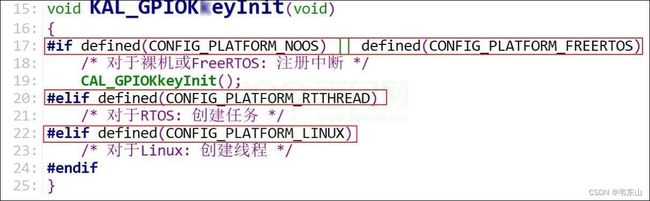
KAL:Kernel Abstrace Layer(内核抽象层)
上面的代码,使用宏开关:要么再用裸机的代码,要么调用rt-thread的代码,要么调用Linux的代码。
如果不想让程序能够支持裸机、支持各类RTOS的话,完全可以把Kal这一层去掉。
通过创建配置文件(头文件),假设为config.h,
C文件就包含它:#include ,里面就定义:
#define CONFIG_PLATFORM_NOOS 1
这样就支持裸机。
1.2 设备管理
再讲一下管理设备,假设有三个输入设备,都要调用他们的初始化函数:
我们可以一个一个的去手工调用,也可以一次性的调用他们的初始化函数。
怎么一次性的调用?首先得一次性的找到他们,所以我们把它放在一个链表里。
通过注册,将他们放在一个链表里:

假设我们有三个设备:
- gpio_key.c : InputDeviceRegister(&g_tKeyDevice);
- uart.c : InputDeviceRegister(&g_tUARTDevice);
- net.c : InputDeviceRegister(&g_tNETDevice);
这三个输入设备里面,都应该调用这个注册函数,现在用了一种取巧的办法。
我在input_system.c里,调用gpio_key.c的函数,去注册一个输入设备:

A文件调用B文件的函数,B文件调用A文件的函数,这种写法是不好的。
一般来说就这样做的,我们再写出第3个文件,
互相引用的话,这关系就交叉了,目前还是希望依赖关系比较简单清晰一点。
我们继续讲怎么管理这些设备:
1.放入链表
2.初始化的时候,从列表里把它们拿出来,一个一个初始化
再举一个例子:

问题就在于谁去调用这个函数AddInputDeviceGPIOKey ?
我在第3个文件里去调用,比如主函数调用就可以了: main() > AddInputDeviceGPIOKey
1.3 三种程序框架
我们今天要把输入子系统吃透,
现在回过头来给先给大家讲一下整体框架,单片机程序的3种写法:

这种写法是我们刚接触单片机时最最经常用到的。
第1种写法的缺点是什么? ABCD互相影响。
A执行时间久了就会影响到后续的函数,B执行久了也会影响到其他的函数,使用这种方法写出来的程序,这ABCD要尽快执行。
下面是第2种写法:
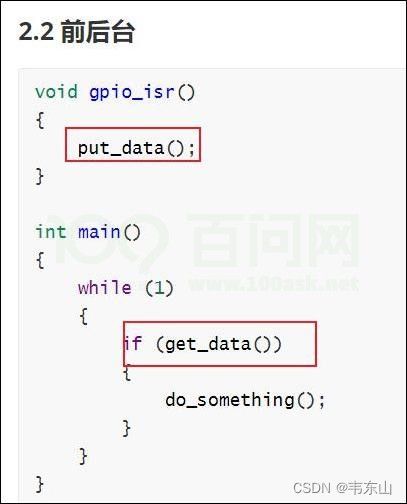
就是所谓的前台后台。
main里面有个死循环,他在等待数据,得到数据之后就处理。
数据哪来的呀?来自于中断
当你按下按键之后,会产生硬件中断,程序会暂停main函数的执行,
跳去执行中断函数,在中断函数里面,他把数据放入某个缓冲区。
处理完中断之后,main函数继续执行,再次执行循环的时候,就得到了数据,就可以去做某些事情了。
第2种写法是我们当前的项目采用的,第2种写法的缺点是什么?
有三个缺点:
-
中断函数做的事情太多了,当前中断正在执行的时候,其他中断就被卡住,影响实时性
-
在没有数据的时候,main函数也在全速运行:功耗高
-
main要做很多事情的时候,又回退到前面的那种方式了:大家互相影响
我们讲完项目一之后,就会讲FreeRTOS:
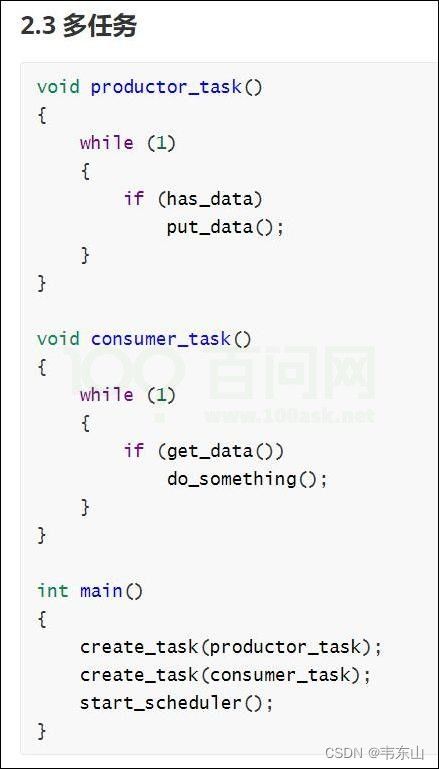
使用多任务,程序就会非常方便,这个以后再讲。
1.4 数据流向
先回到我们的主题,对于输入系统,我们使用的是前后台的框架。
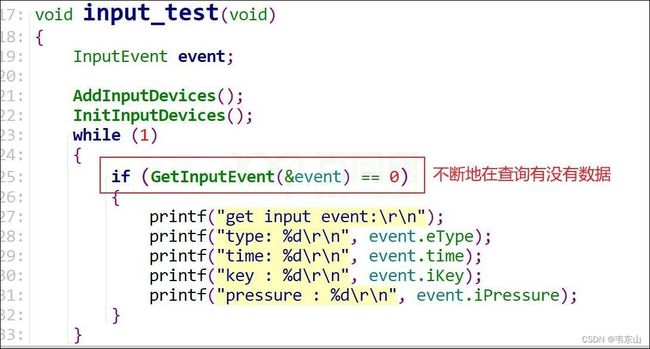
在发生按键中断时,就会产生数据,就执行打印操作。
我去分析一个程序的时候,我喜欢分析它的数据流向。

这个环形缓冲区大部分时间都是空的,谁往里面放数据呢?
以按键中断为例,我们按一下按键,会触发中断,会导致gpio的中断函数被调用。
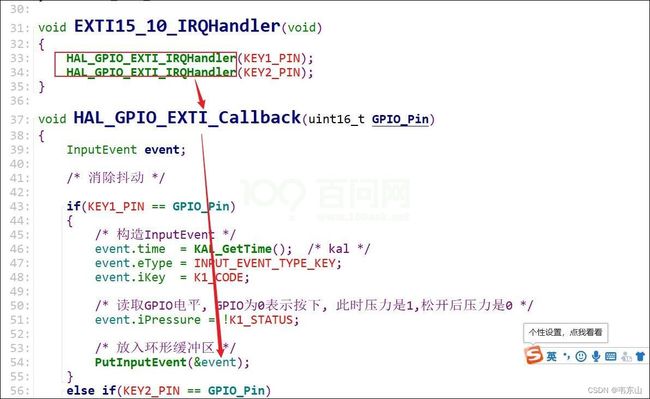
中断函数把数据放入环形缓冲区,就完事了。
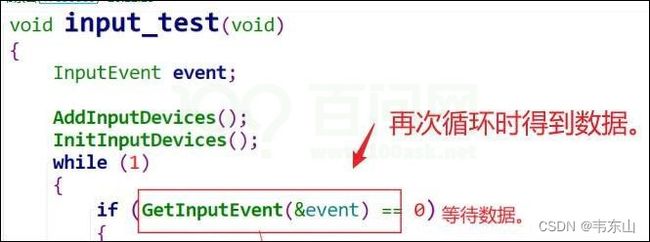
1.5 代码原则
再讲一下编写程序,编写函数的一些原则。
我们写C程序时有头文件、有C文件。
头文件的作用是什么? 暴露接口
C文件的作用是什么?内部实现
来看看我写的代码:

不想暴露给别人使用的函数, 就是static函数。
就没有必要放在头文件里面。
头文件的作用是暴露接口,你跟同事之间的交流,就是通过头文件来交流。
同事一看你的头文件,就知道怎么去使用你的代码。
全局变量不要暴露出去,对于全局变量,绝对不建议在头文件里面声明。
举一个例子:
对于全局变量__IO uinit32_t uwTick;,
什么我们都不直接使用它?非要用一个函数?

我们假设有abcdefg等,10个文件去用到这个变量。
哪一天你说这个变量它的含义我要改改,它是值要乘以2,就要改10个文件吧。
如果我用一个函数,我只需要去改这个函数即可。
这个图是我总结的一些程序设计的原则:

二:其它补充
tick中断很重要,我给大家讲讲。
对于一个嵌入式系统,他的时间基准是什么?
程序一开始运行的时候:他就会去设置一个硬件定时器,比如说设置成一毫秒产生一次中断,这叫Tick中断。
这个中断的处理函数很简单:

他只是去累加一个全局整数,这个全局整数,就是整个系统的时间基准。
对于cortex M3、M4,在CPU内部,有一个定时器: systick。
使用它,是为了增加系统的可移植性,有些芯片上面可能没有timer1、timer5,但是都有systick。
所以很多rtos甚至Linux都是使用CPU自带的这个定时器。
三:预习安排
10-8_设备系统_设计思路
10-9_设备系统_实现LED设备
10-10_设备系统_单元测试
四:课后作业
- 作业1
10_6_input_unittest 中实现了按键功能,但是不能消除按键抖动。
请改进,使用定时器实现消除抖动。
- 思路:
在GPIO中断里启动"软件定时器",可以自己实现"软件定时器"
在"软件定时器"被触发后,在根据GPIO电平构造InputEvent、放入环形缓冲区 - 请思考:
是否每个GPIO对应一个"软件定时器"?
以面向对象编程的思想,"软件定时器"放在哪里比较合适? - 参考实现:
我们将会录制视频、编写源码,放在10_6_input_unittest_debouncing
- 作业2
如果有时间,可以参考10_8_device_led_unittest 实现一个"风扇设备"。
五. 晚课学员提问
1. 问: 按照我的理解,可以分为三层,系统层、KAL,CAL,每层一个开关,控制下面若干分支,这样理解对吗?

答: 这个图画得好,这个理解是对的。
2. 问: 老师,这个相当于头插法链表么?来一个输入设备,放在链表头部?

答: 是的,放在链表头部。
3.问: “中断函数做的事情太多了,当前中断正在执行的时候,其他中断就被卡住,影响实时性。”
对于rtos系统的话,中断处理的多的话,上面问题也会出现吗?
答: 会的,所以中断要尽快处理完毕,很多中断程序只是通知一下任务。
4. 问: 中断的按键,跟用定时器扫描的按键哪个好?
答: 使用定时器扫描,是因为没有中断,能用中断就优先使用中断,发生了中断之后,我们可以使用定时器来消除抖动。
对于按键,有些芯片它的引脚非常缺乏,就比如说以前我们用过51单片机,就使用到了行列扫描的方法来做键盘:
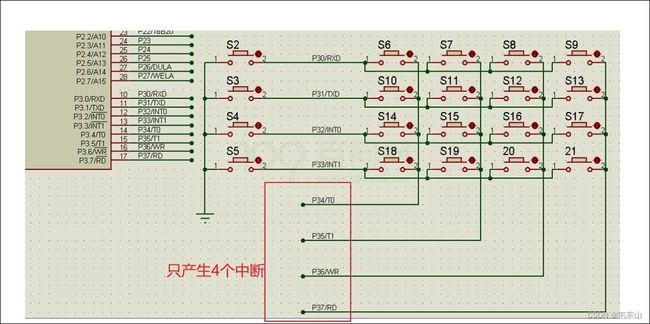
这个图比较简陋,你看他有16个按键,但是只产生4个中断。
5. 问: 像开发板上都有4-5个按键,都是配置中断么?
答: 你的问题就在于,你是不是每一个按键都对应一个中断引脚?
是的话,每一个按键都有一个中断服务程序,当然可以共用同一套代码。
6. 问: 我查资料有说按键中断太多,会造成系统不稳定,也推荐用ringbuffer?
答: 中断很多,使用环形缓冲区,是为了防止按键丢失。
7. 问: 中断里的事情要快点干完,所以不应该在中断里delay?应该怎么消抖?
答: 我们可以使用定时器来消除抖动。
这个方法好像我以前介绍过,我现在再简单的讲一下原理,以前没有写过代码。

我们假设按一下这个按键,产生了三次中断,我们怎么使用定时器来消除中断呢?
在中断函数里面,去定个闹钟:

在第1次中断那里,10ms之后再来处理,
在第2次中断那里,这个时候重新推迟10ms,
在第3次中断那里,这个时候重新推迟10ms,
三次中断,连续的把时间往后推迟10ms,这个闹钟只会响一次。
这不就消除了抖动吗。
在GPIO中断里面,只是把闹钟的时间设置一下,非常快。
最后一次中断也只是去设置一下闹钟,在闹钟响的时候再去确定按键。
8. 问: 可以检测 按键的下降沿和上升沿 时间 的触发 时间差 来消抖吗??
答: 理论上是可以的,但是用定时器是最简单的方法。
举个最简单的定时器消抖:
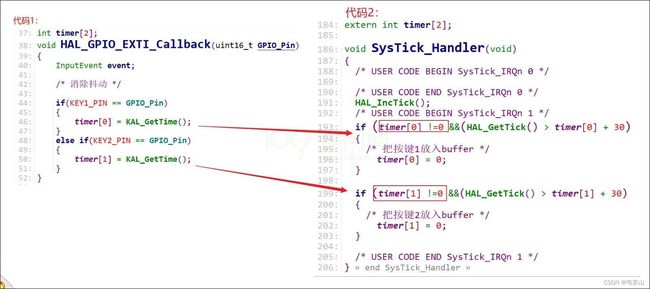
发生GPIO中断时,代码1根据中断引脚来记录当前时间。
在代码2(定时器中断)里,把前面记录的时间与此时时间进行比较,实现延时消抖。
9. 问: 使用定时器消抖,在实际项目中需要关注下时间溢出的情况吧?
答: 我们使用RTOS实现的定时器的话,他都考虑了这些。
我们来看看溢出的话需要多长时间:

在stm32里面,每1ms产生异常定时器中断,uwTick增加1,溢出需要49天,因此很多人都懒得管溢出。
10. 问: systick_handler每1MS调用一次吗?
答: 是的,这可以设置。
11. 问: 串口收到数据后,要立马放入putInput event里面吗?还是存入10个数据后再放入,或者其他方法?
答: 这里贴一下学员的代码:
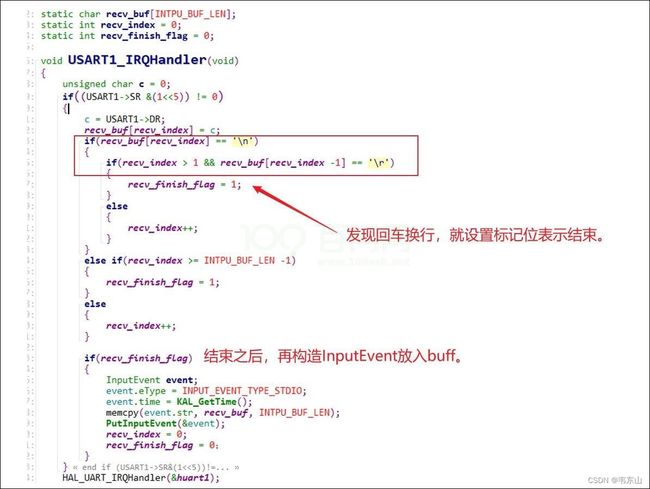
我们使用串口的时候,怎么表示我的数据已经发送完毕?都会输入回车键。
所以我们开发板上接收到数据时,就要判断是不是接收到了:回车换行。
12. 问: 这个缓冲区buf,只支持一个应用去拿数据?假如我现在要获取按键值,那我在某个应用拿到数据之后,就要把相关的工作都做完,不然其他的应用是拿不到按键数据的。这个理解有问题吗?
答: 在我们第1个项目里,只用前台后台的框架,只有一个main函数在不断的运行。
main函数读取环形buff的数据,只有它一个人读取。
对于环形缓冲区,你当然可以让多个应用程序去读取,他并没有限定说只能够给一个人使用。
就像你使用电脑也是一样的呀,你有多个应用程序,但是能够接收输入的只有一个。
多个应用读取缓冲区不会冲突吗?会冲突,所以你得考虑好:怎么管理这些多个任务。
13. 问: 多个中断处理程序都写缓冲区,会不会搞乱数据呢?
答: 会的,所有的环形缓冲区要考虑互斥。
要保证,同一时间,只能够有一个人来操作读它,或者写它。
假设有两个人,可以一个去读,一个去写。但是,不能够两个人同时去读、同时去写。
我们可以加上一些保护的手段,比如说关中断,然后这样操作:
- 关中断
- 读/写
- 开中断
13. 问: 老师我想问一下,设备链表的链表头一般在哪里?是不是.h中生明一个全局变量?规范做法是什么?
答: 有的链表头,都是定义一个全局变量,加上static。
14. 问: 函数的extern是写在被调用的头文件中,还是调用的头文件中呢,还是说都可以?
答: 对于函数, 加上extern,完全是多此一举,你加、不加extern,它的作用域都是整个程序。
加上extern,只是起一个心理安慰作用:
a.c :
A()
{
}
在a.c里面实现了函数A,b.c想是使用函数A,怎么办?
常规的用法应该是:b.c #include 。
有时候懒得写头文件, 就在 b.c 里加上:extern void A();
只是为了告诉看代码的人,这个函数A, 是别人实现的。
实际上,你加不加extern都可以。
15. 问: SysTick是不是也是中断?是不是也不能做太多事情?
答: 是的,只是说建议不要做太多的事情,非要做一些很耗时的事情,那也没办法。
16. 问: 老师,缓冲区能抽象为一个通用的吗?比如从外部传参数进去,告诉缓冲区的数据成员大小,缓冲区长度。这样不是可以抽象出来了吗?
答: 你这个方法挺好,这就是FreeRTOS中的队列。从这个角度来说,可以统一。
17. 问: 关于缓冲区,假如收到的数据是不定长的数据,统一缓存到环形缓冲区。那么接收方应该怎么处理?应该怎么寻找边界?
答: 首先,环形缓冲区是一个数组,每一个数组项假设能够保存100个数据。
你可能在那个数组项里面,只放入了50个数据,这没关系,并不会影响到别的数组项。
环形缓冲区,大小是事先分配好的,你可能一下子发了1000个数据,超过了这个缓冲区,那就只能够丢弃。
对于环形缓冲区的写操作,他肯定要先判断一下,满的话就不能写。
18. 问: 缓冲区大小4096字节,足够大,不考虑溢出的问题。发送方通过串口发送了4次数据,第一次5字节,第二次64字节,第三次16字节,第4次8字节。
接收方的解析函数,看到环形缓冲区内一共有了93字节的内容。那么缓冲区怎么区分每次接收数据的边界?怎么知道那些数据是一组?
答: 不区分边界: 第1次收到5字节数据,那就写5次环形缓冲区;第2次收到64字节数据,那就写64次环形缓冲区……
怎么处理这些数据的边界?那是读数据的应用程序做的。
比如说,它连续读缓冲区,读到回车换行,就知道得到了一个完整的字符串。
如果是不定长的随机数据,你必定有一定的格式:比如第1个字节就必须放长度。
两边不约定好的话,谁都没有办法区分边界。