【Spark NLP】第 9 章:信息提取
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
命名实体识别
共指解析
断言状态检测
关系提取
概括
练习
在处理文本时,我们通常希望提取一些含义。许多任务涉及从文本中提取事件或实体。我们可能还想查找文档中所有引用特定人的位置。我们可能想找出在特定地点发生的事情。这些任务称为信息提取。
信息提取任务侧重于实体(名词和名词短语)和事件(动词短语,包括它们的主语和宾语)。这与词性任务不同,在词性任务中,我们不需要标记所有内容,只需要识别文本的“重要”部分。但是,用于提取此信息的技术通常与序列建模中使用的技术相同。
到目前为止,最常见的信息提取类型是命名实体识别。这是查找对特定实体的引用的任务。
命名实体识别
命名实体识别 (NER)是在文本中查找特定事物(名词)的任务。通常,所需的命名实体是专有名词,但我们也可能希望提取其他内容。让我们看一下提取的一些常见的名词类型。
为了充分理解命名实体识别背后的语言学,我们需要定义一些术语:
引用表达式或 R 表达式 :指代实际或概念事物的词或短语。根据 R 表达式的具体程度和指定方式,将其分为不同的类型。
参照物 :R 表达式所指的实际或概念上的事物。
确定性和不确定性 :这是指所指对象的具体程度。如果 R 表达式是确定的,则存在特定的指称。有不同种类的不定性,但语言在区分的种类上有所不同。
Deixis 一个 R 表达式,其所指对象只能通过上下文信息来解析。
让我们看一些例子。
- “Cows eat grass”中的“Cows”是不定名词的一个例子。在英语中,不需要不定冠词,但可以使用“some”。
- “France is in Europe”中的“France”是专有名词的一个例子。专有名词就其性质而言是确定的。在英语中,大多数专有名词不使用定冠词。也有一些例外——主要是地理区域和水体,例如“北极”和“戈壁”。还有一些其他的例外,主要是在上下文中合适的非专有名词短语——例如,像“牛仔队”这样的运动队。
- “The Sun is shining”中的“The Sun”是定名词的一个例子。在英语中,不是专有名词的定名词需要定冠词“the”。
- “Are you going to eat that”中的“that”是指示的一个例子。在上下文中,所指对象是特定的食品,但如果没有上下文,则无法解析引用。
- “I am here”中的“I”和“here”也是指示语的例子。这句话可以解释为重言式,但它仍然很常见。这是因为“我”和“这里”的指示中心不同。“我”将说话者或作者作为指示中心,而“这里”则将前面介绍的某个位置作为指示中心。
- “The next episode airs tomorrow”中的“tomorrow”是指示词用作副词的一个例子。
如您所见,这是语言的一个复杂方面。幸运的是,在进行 NER 时,我们限制了我们正在寻找的实体。通常,NER 模型识别人、地点、组织和时间。这些模型通常在寻找专有名词。我们将其称为通用 NER。另一个常见的 NER 任务是寻找特定的概念——例如,临床程序。通过专注于一组特定的词汇,这项任务变得更容易。流利的语言使用者通常可以识别名词是否正确,但识别特定领域的类别需要领域专家。我们将其称为特定领域的 NER。
我们可以使用我们在第 8 章中讨论的序列建模技术来处理通用或特定领域的 NER 。让我们看看如何构建我们的数据。一般的概念是,我们希望将其转变为分类任务,其中类位于“命名实体内部”或“命名实体外部”。基本类是O,它是命名实体之外的标记类。B-PER, I-PER, B-LOC, 和I-LOC是命名实体短语中标记的类,其指示对象是人 ( B-PER, I-PER) 或位置 ( B-LOC, I-LOC)。有时,还有更多的课程。通常也有B-*用于开始命名实体短语的类。我们来看一些例子,结果如表9-1和9-2。
“亚瑟王去了卡米洛特。”
| token | class |
|---|---|
| King | B-FOR |
| Arthur | I-FOR |
| went | O |
| to | O |
| Camelot | B-LOC |
| . | O |
B-PROC在临床文本中,我们对程序( ,I-PROC)更感兴趣,而不是寻找人或地点。
“The patient received a bone scan”
| token | class |
|---|---|
| The | O |
| patient | O |
| received | O |
| a | O |
| bone | B-PROC |
| scan | I-PROC |
使用这些标签,您可以像执行词性标记一样进行建模。
如果您正在执行特定于域的 NER,则可以使用一组精选的术语在没有模型的情况下查找文档中的出现。让我们看看我们可以实现这一点的一些方法。让我们再看看布朗语料库。我们将在文本中查找停用词的出现。
from collections import defaultdict, Counter
from random import sample, seed
from time import time
from nltk.corpus import brown
from nltk.corpus import stopwordsen_stopwords = set(stopwords.words('english'))让我们定义一些对我们有帮助的函数。
brown_fileids = brown.fileids()
def detokenize(sentence):
"""
这将让我们查看原始文本,
而不是拆分成句子或标记。
"""
text = ''
for token in sentence:
if text and any(c.isalnum() for c in token):
text += ' '
text += token
return text
def get_sample_files(k):
"""
这将为我们提供文档样本
"""
sample_files = []
for fid in sample(brown_fileids, k):
tokens = []
for sent in brown.sents(fid):
tokens.extend(sent)
sample_files.append((fid, detokenize(tokens)))
return sample_files
def get_match_counts(texts, search_fn, *args):
"""
这将在文本上运行给定的搜索函数 search_fn
。附加参数作为
*args传递
"""
references = defaultdict(Counter)
for fid, text in texts:
for term, begin, end in search_fn(text, *args):
references[term][fid] += 1
return references让我们创建一些文档样本,这样我们就可以看到找到匹配项需要多长时间。
seed(123)
raw_10 = [(fid, tokens) for fid, tokens in get_sample_files(10)]
raw_50 = [(fid, tokens) for fid, tokens in get_sample_files(50)]
raw_100 = [(fid, tokens) for fid, tokens in get_sample_files(100)]
raw_500 = [(fid, tokens) for fid, tokens in get_sample_files(500)]让我们尝试简单的幼稚方法。对于文本中的每个位置,我们将尝试将词汇表中的每个术语与我们的搜索术语匹配。
def simple_match(text, vocabulary):
text = text.lower()
for term in vocabulary:
for i in range(len(text) - len(term) + 1):
j = i+len(term)
end_of_word = j == len(text) or not text[j].isalpha()
begin_of_word = i == 0 or not text[i-1].isalpha()
if begin_of_word and \
end_of_word and \
term == text[i:i+len(term)]:
yield (term, i, j)timing = []
for texts in [raw_10, raw_50, raw_100]:
start = time() # milliseconds
references = get_match_counts(texts, simple_match, en_stopwords)
timing.append((len(texts), int(time() - start) * 1000))
print('the', sum(references['the'].values()))
print('about', sum(references['about'].values()))
print('wouldn\'t', sum(references['wouldn\'t'].values()))
print('{} documents in {} ms'.format(*timing[-1]))让我们看看使用 naïve 方法处理文档需要多长时间。
the 1404
about 34
wouldn't 2
10 documents in 6000 ms
the 6876
about 177
wouldn't 15
50 documents in 30000 ms
the 13962
about 380
wouldn't 40
100 documents in 60000 ms那很慢。让我们看看朴素方法的时间复杂度。
如果文档的大小是N字符,并且M是词汇长度的总和,则这种方法具有O(MN)复杂性。您的时机可能更糟,但这是因为我们也在构建参考词典。
这种方法有很多浪费的检查。如果我们在's',我们不需要检查“about”。如果我们可以限制我们需要考虑的词汇项目的数量会更好。我们可以用trie来做到这一点。
trie是一种数据结构,可以让我们在树中存储许多序列。Trie 将每个序列存储为树中的路径。让我们看一个例子。
def build_trie(sequences, empty=lambda: ''):
"""
这将构建我们的 trie。我们在
每个节点中包含路径以便更容易解释 trie,即使
这会增加我们的内存占用。
"""
trie = {'': empty()}
for seq in sequences:
curr = trie
path = empty()
for elem in seq:
path += elem
curr = curr.setdefault(elem, {'': path})
curr[''] = True
return trie
def traverse(trie, empty=lambda: ''):
"""
这是广度优先遍历。这将一次遍历
trie 一层。
"""
queue = [trie]
while len(queue) > 0:
head = queue[0]
path = head['']
queue = queue[1:] + list(
node
for key, node in head.items()
if not key[0] == '<'
)
yield (path, head)
def traverse_depth_first(trie, empty=lambda: ''):
"""
这是深度优先遍历。这将一次遍历
一条路径。
"""
stack = [trie]
while len(stack) > 0:
head = stack[0]
path = head['']
stack = list(
node
for key, node in head.items()
if not key[0] == '<'
) + stack[1:]
yield (path, head) 让我们用一个简单的词汇来看看 trie。
trie = build_trie(['cat', 'catharsis', 'dog', 'destiny'])
print('Breadth-first traversal')
for path, _ in traverse(trie):
print(path)
print()
print('Depth-first traversal')
for path, _ in traverse_depth_first(trie):
print(path)Breadth-first traversal
c
d
ca
do
de
cat
dog
des
cath
...
destiny
catharsi
catharsis
Depth-first traversal
c
ca
cat
cath
...
catharsis
d
do
dog
de
...
destiny现在我们有了这个数据结构,我们可以用它来搜索文本。该算法的要点是遍历文本并使用文本中的字符来遍历特里树。让我们看一下代码。
def trie_match(text, trie):
text = text.lower()
curr = trie
# 对于 text 中的每个字符
for i in range(len(text)):
j = i # begin traversing the trie from text[i]
begin_of_word = i == 0 or not text[i-1].isalpha()
if not begin_of_word:
continue
while j < len(text) and text[j] in curr:
# 向下移动 trie
curr = curr[text[j]]
# 检查我们是否不在一个词的中间
end_of_word = j == len(text) - 1 or not text[j+1].isalpha()
# 我们是否在一个词的末尾并且我们当前在
# 一个条目,发出一个匹配
if end_of_word and '' in curr:
term = curr['']
yield (term, j-len(term)+1, j+1)
j += 1
# 当匹配字符用完时或到达trie 的结尾
# ,重置并继续移动到下一个字符
curr = trie 让我们为基于 trie 的方法计时。
en_stopwords_trie = build_trie(en_stopwords)
timing = []
for texts in [raw_10, raw_50, raw_100, raw_500]:
start = time() # milliseconds
references = get_match_counts(texts, trie_match, en_stopwords_trie)
timing.append((len(texts), int((time() - start) * 1000)))
print('the', sum(references['the'].values()))
print('about', sum(references['about'].values()))
print('wouldn\'t', sum(references['wouldn\'t'].values()))
print('{} documents in {} ms'.format(*timing[-1]))the 1404
about 34
wouldn't 2
10 documents in 38 ms
the 6876
about 177
wouldn't 15
50 documents in 186 ms
the 13962
about 380
wouldn't 40
100 documents in 371 ms
the 70003
about 1817
wouldn't 129
500 documents in 1815 ms这要快得多。这是 NLP 中的经典权衡。为了提高速度,除了预先计算我们的 trie 所需的时间之外,我们还增加了内存占用。还有更复杂的算法,比如 Aho-Corasick,它在 trie 中使用额外的链接来减少回溯所花费的时间。
如果您的词汇量有限,那么字典搜索(如我们之前的 trie 匹配算法)可以从文档中获取大量信息。它受到无法识别不在精选词汇表中的任何内容的限制。要确定哪种方法最适合您的项目,请考虑以下事项:
- 您是否有特定领域的 NER 要求?还是一般的NER?
- 如果你需要通用的NER,你需要建立一个模型。
- 你有精选的词汇吗?你有带标签的文字吗?
- 如果两者都有,您可能希望创建一个模型来潜在地识别新术语。如果您两者都没有,请考虑哪个更容易创建。
一旦我们有了实体,我们可能希望将它们连接到外部数据。例如,假设我们正在寻找临床记录中提到的药物。我们可能希望将命名实体(药物)与药物数据库中的信息相关联。我们如何进行这种匹配将取决于我们如何进行 NER。因为这是一个特定领域的 NER 任务,我们可以使用字典搜索方法或模型方法。如果我们有这样的数据库,它实际上可以用来创建我们的精选词汇表。这使得将已识别的药物名称与其在我们数据库中的元数据相关联变得简单。如果我们使用模型方法,事情可能会有点模糊,因为模型可以识别可能不完全出现在我们的数据库中的名称。我们可以处理此任务的一种方法是在我们的数据库中搜索药物名称,即最接近找到的药物名称。
在 Spark NLP 中,有两种方法可以进行 NER。一种策略使用 CRF,另一种策略基于深度学习。这两种方法都将词嵌入作为输入,因此我们将在第 11 章讨论词嵌入时看到示例。
所有这些 NER 方法都缺少一类参考。这些方法仅识别直接引用。他们都无法确定要指代的代词。例如:
The coelacanth is a living fossil. The ancient fish was discovered off the coast of South Africa.
“ancient fish”不会被认定为与“coelacanth.”相同的东西。
我们可以通过共指解析来解决这个问题。
共指解析
我们之前讨论了 R 表达式和所指对象。共指是指两个 R 表达式共享一个指称对象。如果我们试图理解关于我们的命名实体的说法,这在文本中可能很有价值。不幸的是,这是一个难题。
人类通过许多句法和词汇规则来理解共指。让我们看一些例子。
He knows him.
He knows himself.
在第一句话中,我们知道有两个人参与其中,而在第二句话中只有一个人。其原因在于称为政府和绑定的语法子领域。反身代词,如“他自己”,必须在其从句中指代某物。例如,看下面的不合语法的句子。
They were at the mall. *We saw themselves.
虽然我们可以猜测“他们自己”指的是“他们”指的同一个群体,但这似乎很奇怪。这是因为反身性试图将自己与句子“我们”中的另一个实体结合起来。非反身词不得在其子句中受到约束。
代词引用不是唯一的共指类型。通常有很多方法可以引用一个实体。让我们看一个例子。
Odysseus, known to the Romans as Ulysses, is an important character in the works of Homer. He is most well known for the adventures he had on his way home from the Trojan War.
在这句话中,奥德修斯被提及五次。在语言学中,通常使用下标来表示共指。让我们看一下标记为共指的同一个句子。
Odysseusi, known to the Romans as Ulyssesi, is an important character in the works of Homer. Hei is most well known for the adventures hei had on hisi way home from the Trojan War.
现在我们了解了共指,我们如何从文本中提取它?这是一个难题。对于这项任务,采用深度学习技术的速度比其他任务慢,因为它不经常尝试。可以使用基于规则的方法来解决此问题。如果将句子解析为句法树,则可以使用句法规则来识别哪些 R 表达式共享所指对象。然而,这有一个大问题。它仅适用于具有常规语法的文本。所以这种方法在报纸上效果很好,但在 Twitter 和临床笔记上效果很差。另一个缺点是规则需要对我们正在为其构建规则的语言的语法有深入了解的人。
机器学习方法可以被视为序列建模问题。对于给定的 R 表达式,我们必须尝试确定它是否与先前的 R 表达式相同,或者它是否具有新的指示物。有许多可用的数据集可供我们练习。
现在我们已经讨论了如何获得 R 表达式以及如何识别共指对象,我们可以讨论下一步该做什么。
断言状态检测
想象一下,我们正在寻找在服用药物时表现出特定症状的患者,例如头晕。如果我们只寻找任何提到头晕的临床报告,我们会发现许多类似以下的提及。
No dizziness.
I have prescribed a drug that may cause dizziness. Patient denies dizziness.
当然,这些不是我们正在寻找的患者。了解演讲者或作者如何使用信息与了解信息中提及的内容同样重要。这在临床环境中称为断言状态任务。它在其他类型的通信中也有用途,例如法律文件和技术规范。
让我们从语言的角度来看它。当我们在前面的“头晕”示例中看到“误报”时,是因为该陈述的情绪或极性错误。
极性是一个陈述是肯定的还是否定的。情绪是陈述的一个特征,表明说话者或作者对陈述的感受。所有语言都有表示这些事物的方式,但它们在不同语言之间存在很大差异。在英语中,我们使用副词来表达怀疑,但在其他一些语言中,它是通过形态来表达的。让我们看一些极性和情绪的例子。
- The patient did not have difficulty standing.
- The movie may come out in April.
- I would have liked the soup if it were warmer.
第一个例子是否定的例子(负极性),第二个例子是投机情绪的例子,第三个例子是条件式的例子。否定是所有语言的一个特征,但它的表达方式差异很大——即使在同一种语言的方言之间也是如此。您可能听说过英语中的双重否定规则;也就是说,双重否定变成肯定。
I don’t have nothing ~ I have something
然而,情况并非总是如此。考虑以下示例:
You’re not unfriendly.
这里,动词被“not”否定,谓词被“un-”前缀否定。不过,这句话的意思当然不是“你很友好”。自然语言比形式逻辑模糊得多。在某些英语方言中,双重否定可以用来强化陈述,甚至可以要求它。在这些方言中,“我一无所有”与“我一无所有”的意思相同。
同样,推测的情况也是模棱两可的。您如何处理此类声明将取决于您正在构建的应用程序。如果您正在构建提取电影发行日期的东西,您可能非常希望包含一个推测性声明。另一方面,考虑到“可能导致头晕”的医学示例,我们可能不想将描述该患者的短语包含在患有头晕的患者集中。另一个需要考虑的因素是对冲言论。如果有人希望软化陈述,他们可以使用投机情绪或其他类似的情绪。这是一种可以改变语义的务实效果。
You may want to close the window ~ [pragmatically] Close the window
You might feel a pinch ~ [pragmatically] You will feel a pinch
You could get your own fries ~ [pragmatically] You should get your own fries
最后,让我们考虑第三个例子,“如果汤热一点,我会喜欢的。” 这句话至少有两种解释。一种解释是,“如果汤热一点,我也会喜欢的。” 另一种,也许更有可能的解释是,“我不喜欢这汤,因为它不够热。”这是一个隐含否定的例子。暗示否定的另一个常见来源是诸如“too X to Y”之类的短语,这意味着对“Y”的否定。
The patient is in too much pain to do their physical therapy.
这传达了“患者没有进行物理治疗”并给出了原因。临床术语包含许多特殊的方式来指代否定。这就是为什么温迪查普曼等人。开发了negex算法。它是一种基于规则的算法,可根据提示的类型识别句子的哪些部分被否定。
不同的线索或触发器表示否定范围的开始和结束,它们防止 negex 错误地将非否定词识别为否定词。让我们看一些例子。我们将首先显示原始句子,然后显示带有斜体提示和否定词的句子。
- 患者否认头晕,但站立时显得不稳定。
- 患者否认 头晕 但站立时显得不稳定。
- 该测试对真菌感染呈阴性。
- 测试结果为阴性 真菌感染.
- XYZ 测试排除了患者的症状。
- XYZ 测试将患者排除在外 症状.
- 执行 XYZ 测试以排除患者的症状。
- 执行 XYZ 测试以排除患者的症状。
在示例 1 和示例 2 中,我们看到否定不是由正常的语法否定表示,例如“not”。相反,有临床特定的线索,“否认”和“否定”。另外,请注意,在第一个示例中,否定是由“but”终止的。在示例 3 和 4 中,提示排除误报。在示例 4 中,实际上并未讨论测试结果。
我们已经看到动词的极性和语气如何影响句子中的实体,但有没有办法获得更多信息?在下一节中,我们将简要讨论从文本中提取关系和事实的想法。
关系提取
关系抽取可能是信息抽取中最困难的任务。这是因为我们可能会花费大量的研究和计算时间来尝试提取越来越细粒度的信息。因此,在尝试如此具有挑战性的事情之前,我们应该始终准确地了解我们想要提取什么样的关系。
让我们考虑一下我们试图从临床文档中提取语句的场景。这些文件的性质限制了可能出现的实体种类。
- 病人
- 状况(疾病、受伤、肿瘤等)
- 身体部位
- 程序
- 药物
- 测试和结果
- 患者的家人和朋友(在家族史和社会史部分)
可以有其他实体,但这些都是常见的。假设我们的应用程序应该提取所有实体并进行陈述。让我们看一个例子。
CHIEF COMPLAINT
Ankle pain
HISTORY OF PRESENT ILLNESS:
The patient is 28 y/o man who tripped when hiking. He struggled back to his car, and immediately came in. Due to his severe ankle pain, he thought the right ankle may be broken.
EXAMINATION:
An x-ray of right ankle ruled out fracture.
IMPRESSION:
The right ankle is sprained.
RECOMMENDATION:
- Take ibuprofen as needed
- Try to stay off right ankle for one weekThe patient ...
is 28 y/o man
has severe ankle pain
tripped when hiking
struggled back to his car
immediately came in
The right ankle ...
may be broken
is sprained
The x-ray of right ankle ...
rules out fracture
Ibuprofen ...
is recommended
take as needed
Try to stay off right ankle ...
is recommended
is for one week要使用此数据执行关系提取,我们需要采取许多步骤。我们将需要所有基本的文本处理、部分分割、NER 和共指解析。这仅用于处理文档。创建输出还需要一些文本生成逻辑。然而,我们也许可以结合一个句法解析器和一些规则来完成其中的一些工作。如前一章所述,句法解析器会将句子转换为层次结构。让我们看一些句子。
The patient is 28 y/o man who tripped when hiking.
(ROOT
(S
(NP (DT The) (NN patient))
(VP (VBZ is)
(NP
(NP (ADJP (CD 28) (JJ y/o)) (NN man))
(SBAR
(WHNP (WP who))
(S
(VP (VBN tripped)
(SBAR
(WHADVP (WRB when))
(S
(VP (VBZ hiking)))))))))
(. .)))这看起来很复杂,但它相对简单。大多数句子可以用简单的树形结构来描述。
(ROOT
(S
(NP (NNS SUBJECT))
(VP (VBP VERB)
(NP (NN OBJECT)))
(. .)))嵌入的w - 子句可以继承它们的主题。例如,让我们看下面的句子:
The man who wears a hat.
在 wh 子句“谁戴帽子”中,“谁”与“那个人”共指。在下面的句子中,我们看到一个没有明确主语的子句:
The man went to the store while wearing a hat.
“穿着”的主题是“男人”。识别嵌入子句主题的实际语法可能会变得复杂。幸运的是,这种复杂的句子在临床笔记中的简洁英语中并不常见。这意味着我们可以按主题的实体对句子进行分组。
PATIENT
The patient is 28 y/o man who tripped when hiking.
who tripped when hiking
He struggled back to his car, and immediately came in.
he thought the right ankle may be broken.
RIGHT ANKLE
the right ankle may be broken
The right ankle is sprained.
X-RAY
An x-ray of right ankle ruled out fracture.
IBUPROFEN
Take ibuprofen as needed
这让我们得到了我们感兴趣的大部分句子。事实上,如果我们将嵌入的句子作为自己的句子并拆分连接动词,我们得到的只是关于患者的陈述之一。剩下的陈述“有严重的脚踝疼痛”将更加困难。我们需要把某种形式的东西(NP (PRP$ his) (JJ severe) (NN ankle) (NN pain)))变成(ROOT (S (NP (PRP He)) (VP (VBZ has) (NP (JJ severe) (JJ ankle) (NN pain))) (. .)))将具有所有格的名词短语转换为“拥有”陈述是一个简单的规则。我们在这里忽略了共指解析。我们可以简单地说,家族史或社会史之外的任何第三人称单数代词都是患者。我们还可以为不同的部分创建特殊规则——例如,推荐部分中提到的任何内容都会得到“推荐”的声明。这些简化的方法可以得到我们大部分的陈述。我们仍然需要一些东西来识别“尽量远离右脚踝”作为一种治疗方法。
让我们使用 NLTK 和 CoreNLP 来看看实际解析了什么。
text_cc = ['Ankle pain']
text_hpi = [
'The patient is 28 y/o man who tripped when hiking.',
'He struggled back to his car, and immediately came in.',
'Due to his severe ankle pain, he thought the right ankle may be broken.']
text_ex = ['An x-ray of right ankle ruled out fracture.']
text_imp = ['The right ankle is sprained.']
text_rec = [
'Take ibuprofen as needed',
'Try to stay off right ankle for one week']首先,让我们启动CoreNLPServer并创建我们的解析器。
from nltk.parse.corenlp import CoreNLPServer
from nltk.parse.corenlp import CoreNLPParser
server = CoreNLPServer(
'stanford-corenlp-3.9.2.jar',
'stanford-corenlp-3.9.2-models.jar',
)
server.start()
parser = CoreNLPParser()parse_cc = list(map(lambda t: next(parser.raw_parse(t)), text_cc))
parse_hpi = list(map(lambda t: next(parser.raw_parse(t)), text_hpi))
parse_ex = list(map(lambda t: next(parser.raw_parse(t)), text_ex))
parse_imp = list(map(lambda t: next(parser.raw_parse(t)), text_imp))
parse_rec = list(map(lambda t: next(parser.raw_parse(t)), text_rec))每个解析的句子都表示为一棵树。让我们看一下“现病史”部分的第一句话(如图9-1所示)。
parse_hpi[0]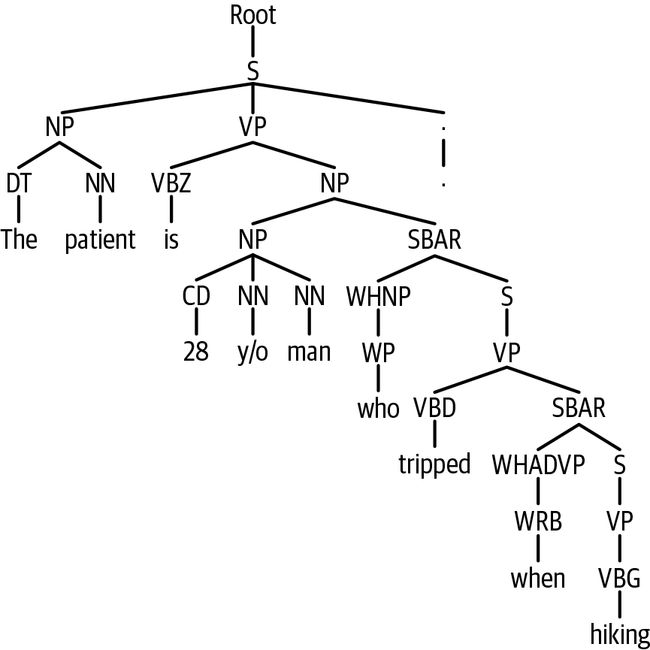
图 9-1。解析“患者 28 岁。. 。”
我们可以通过索引遍历树。例如,我们可以通过取句子的第一个孩子来得到主名词短语(如图 9-2所示)。
parse_hpi[0][0][0]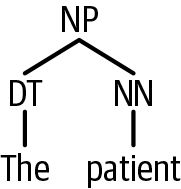
图 9-2。第一个 HPI 句子的主题
树的叶子是令牌:
parse_hpi[0][0][0][0][0]'The'
概括
现在我们看到当我们拥有一组语言很窄的文档时,我们能走多远。如果我们试图将这些假设应用于推文、专利或电影剧本,这些假设将不起作用。当我们构建这样的应用程序时,我们必须通过查看数据、训练我们的模型和查看产品来迭代问题。
这些话题在语言学中一直很重要。这是很自然的,因为我们试图提取以语言编码的信息。语言学是对语言的研究,因此我们可以利用它的知识获得很多优势。但是,如果我们不想提取信息以供人类消费,而是用于建模呢?我们需要比 TF.IDF 更好的东西。接下来的两章讨论分布语义。第 10 章是关于主题建模的,其中我们将文档视为不同主题的组合。第 11 章是关于词嵌入的,我们尝试将词表示为向量。
练习
在本练习中,您将遍历解析树以查找 SVO 三元组。
from nltk.tree import Tree
def get_svo(sentence):
parse = next(parser.raw_parse(sentence))
svos = []
# svos.append((subject, verb, object))
return svos以下是一些要使用的测试用例。
# [("The cows", "eat", "grass")]
get_svo('The cows eat grass.')# [("the cows", "ate", "grass")]
get_svo('Yesterday, the cows ate the grass.')# [("The cows", "ate", "grass")]
get_svo('The cows quickly ate the grass.')# [("the cows", "eat", "grass")]
get_svo('When did, the cows eat the grass.')# [("The cows", "eat", "grass"), ("The cows", "came", "home")]
get_svo('The cows that ate the grass came home.')