第10章 Spark(全面解读Spark架构体系)
概述
Spark简介
Spark诞生于2009年美国加州伯克利分校的AMP实验室,基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。
Spark最初的设计目标是使数据分析更快----不仅程序运行速度要快,程序编写也要能快速、容易。为了使程序运行更快,Spark提供了内存计算,减少了迭代计算时的IO开销;而为了使程序编写更为容易,Spark使用简练、优雅的Scala编写,基于Scala提供了交互式的编程体系。
Spark具有如下4个主要特点:
(1)运行速度快
Spark使用先进的有向无环图(Directed Acyclic Graph,DAG)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度可比Hadoop MapReduce快上百倍,基于磁盘的执行速度也能快十倍左右。
(2)容易使用
Spark支持使用Scala、Java、Python和R语言进行编程,简洁的API设计有助于用户轻松构建并行程序,并且可以通过Spark Shell进行交互式编程。
(3)通用性
Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件,这些组件可以无缝整合在同一个应用中,足以应对复杂的计算。
(4)运行模式多样
Spark可运行于独立的集群模式中,或者运行于Hadoop中,也可运行于Amazon EC2等环境中,并且可以访问HDFS、Cassanadra、HBase、Hive等多种数据源。
Scala简介
Scala是一门现代的多范式编程语言,平滑地集成了面向面向对象和函数式语言的特性。Scala的名称来自“可扩展的语言(A Scalable Language)”。Scala无论是写小脚本还是建立大系统的编程任务均可胜任。Scala运行于Java虚拟机上,并兼容现有的Java程序。
Scala具有以下特点:
- Scala具备强大的并发性支持函数式编程,可以更好地支持分布式系统。
- Scala语法简洁,能提供优雅的API。
- Scala兼容Java,运行速度快,且能整合到Hadoop生态系统中。
Scala是Spark的主要编程语言,但Spark还支持Java、Python、R作为编程语言。Scala的优势是提供了交互式解释器(Read-Eval-Print Loop,REPL),因此在Spark Shell中可进行交互式编程(即表达式计算完成就会输出结果,而不必等到整个程序运行完毕,因此可即时查看中间结果,并对程序进行修改),这样可以在很大程度上提升开发效率。
Spark与Hadoop的对比
| Hadoop |
Spark |
|
| 类型 |
分布式基础平台,包含计算、存储、调度 |
分布式计算工具 |
| 场景 |
大规模数据集上的批处理 |
迭代计算、交互式计算、流计算 |
| 价格 |
对机器要求低、便宜 |
对内存有要求,相对较贵 |
| 编程范式 |
Map+Reduce,API较为底层,算法适应性差 |
RDD组成DAG有向无环图,API较为顶层,方便使用 |
| 数据存储结构 |
MapRecuce中间计算结果存在HDFS磁盘上,延迟大 |
RDD中间运算结果存在内存中,延迟小 |
| 运行方式 |
Task以进行方式维护,任务启动慢 |
Task以线程方式维护,任务启动快 |
Hadoop的缺点
Hadoop最主要的缺陷是其MapReduce计算模型延迟过高,无法胜任实时、快速计算的需求,因而只适用于离线批处理的应用场景。
- 表达能力有限
计算都必须要转化成Map和Reduce两个操作,但这并不适合所有的情况,难以描述复杂的数据处理过程。
- 磁盘IO开销大
每次执行都需要从磁盘读取数据,并且在计算完成后需要将中间结果写入磁盘中,IO开销较大。
- 延迟高
一次计算可能需要分解成一系列按顺序执行的MapReduce任务,任务之间的衔接由于涉及IO开销,会产生较高延迟。而且,在前一个任务执行完成之前,其他任务无法开始,因此难以胜任复杂、多阶段的计算任务。
Spark的优点
Spark最大的特点就是将计算数据、中间结果都存储在内存中,大大减少了IO开销,因而Spark更适合于迭代运算比较多的数据挖掘与机器学习运算。
- Spark的计算模型也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比MapReduce更灵活。
- Spark提供了内存计算,中间结果直接放在内存中,带来了更高的迭代运算效率。
- Spark基于DAG的任务调度执行机制,要优于MapReduce的迭代执行机制。
在实际进行开发时,使用Hadoop需要编写不少相对底层的代码,不够高效。相对而言,Spark提供了多种高层次、简洁的API。
Spark并不能完全替代Hadoop,其主要用于替代Hadoop中的MapReduce计算模型。
Hadoop可以使用廉价的、异构的机器来做分布式存储与计算,但是Spark对硬件(内存、CPU等)的要求稍高一些。
Spark 特点
- 快
与 Hadoop 的 MapReduce 相比,Spark 基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark 实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。
- 易用
Spark 支持Java、Python、R和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些 shell 中使用Spark集群来验证解决问题的方法。
- 通用
Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark 统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。使用门槛低,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在 EC2上部署Standalone的Spark集群的工具。
Spark生态系统
在实现应用中,大数据处理主要包括以下3个类型:
1、复杂的批量数据处理:时间跨度通常在数十分钟到数小时。
方案:可以利用Hadoop MapReduce来进行批量数据处理。
2、基于历史数据的交互式查询:时间跨度通常在数十秒到数分钟。
方案:可以用Impala来进行交互式查询(Impala与Hive相似,但底层引擎不同,提供了实时交互式SQL查询)。
3、基于实时数据流的数据处理:时间跨度通常在数百毫秒到数秒。
方法:可以采用开源流计算框架Storm。
实际的应用场景中,会同时存在以上三种场景,Spark的设计遵循“一个软件栈满足不同应用场景”的理念,具有一套完整的生态系统,即能够提供内存计算框架,也可以支持SQL即席查询、实时流式计算、机器学习和图计算等。Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案。因此,Spark所提供的生态系统足以应对上述3种场景,即同时支持批处理、交互式查询和流数据处理。现在Spark生态系统已经成为伯克利数据分析软件栈(Berkeley Data Analytics Stack,BDAS)的重要组成部分。

Spark生态系统主要包含了Spark Core、Spark SQL、Spark Sreaming、Structured Streaming、MLlib和GraphX等组件,各个组件的具体功能如下:
(1)Spark Core
Spark Core包含Spark的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等,主要面向批量数据处理。Spark建立在统一的抽象弹性分布式数据集(Resilient Distributed Dataset,RDD)之上,使其可以以基本一致的方式应对不同的大数据处理场景。
(2)Spark SQL
Spark SQL允许开发人员直接处理RDD,同时也可查询Hive、HBase等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员不需要自己编写Spark应用程序。
(3)Spark Streaming
Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流数据分解成一系列短小的批处理作业,每个短小的批处理作业都可以使用Spark Core进行快速处理。
(4)Structured Streaming
Structured Streaming是一种基于Spark SQL引擎构建的、可扩展且容错的流处理引擎。通过一致的API,Structured Streaming使得使用者可以像编写批处理程序一样编写流处理程序,简化了使用者的使用难度。
(5)MLlib(机器学习)
MLlib提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛,开发人员只要具备一定的理论知识就能进行机器学习工作。
(6)GraphX(图计算)
GraphX是Spark中用于图计算的API,可认为是Pregel在Spark上的重写及优化。GraphX性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
Spark的应用场景
| 应用场景 |
时间跨度 |
其他框架 |
Spark生态系统中的组件 |
| 复杂的批量数据处理 |
小时级 |
MapReduce、Hive |
Spark Core |
| 基于历史数据的交互式查询 |
分钟级、秒级 |
Impala、Dremel、Drill |
Spark SQL |
| 基于实时数据流的数据处理 |
毫秒级、秒级 |
Storm、S4 |
Spark Streaming Structured Streaming |
| 基于历史数据的数据挖掘 |
-- |
Mahout |
MLlib |
| 图结构数据的处理 |
-- |
Pregel、Hama |
GraphX |
Spark 运行架构
Spark架构采用了分布式计算中的Master-Slave模型。Master是对应集群中的含有Master进程的节点,Slave是集群中含有Worker进程的节点。
基本概念
(1)RDD:是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
(2)DAG:反映RDD之间的依赖关系。
(3)Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行任务,并为应用程序存储数据。
(4)应用:用户编写的Spark应用程序。
(5)任务:运行在Executor上的工作单元。
(6)作业:一个作业(Job)包含多个RDD及作用于相应RDD上的各种操作。
Application:Spark应用程序
应用指的是用户编写的Spark应用程序,包含了Driver功能代码和分布在集群中多个节点上运行的Executor代码。
Spark应用程序,由一个或多个作业JOB组成,如下图所示。
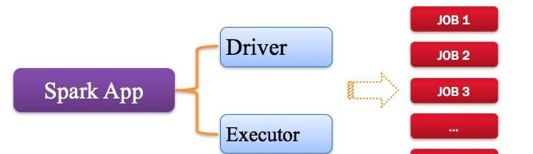
Spark应用程序组成
Driver:驱动程序
Spark中的Driver即运行上述Application中的Main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常SparkContext代表Driver,如下图所示。
Driver驱动程序组成
负责实际代码的执行工作,即执行Spark任务中的main方法,在Spark作业执行时主要负责:
- 将用户程序转化为作业(job)
- 在Executor之间调度任务(task)
- 跟踪Executor的执行情况
- 通过WebUl展示查询运行情况
简单理解,所谓Driver就是驱使整个应用运行起来的程序。
SparkContext
每一个Spark应用都是一个SparkContext实例,可以理解为一个SparkContext就是一个spark application的生命周期,一但SparkContext创建之后,就可以用这个SparkContext来创建RDD、累加器、广播变量,并且可以通过SparkContext访问Spark的服务, 运行任务。
// 创建 Spark 运行配置对象
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
// 创建 Spark 上下文环境对象(连接对象)
val sc = new SparkContext(sparkConf)
Cluster Manager:资源管理器
资源管理器指的是在集群上获取资源的外部服务,常用的有:Standalone,Spark原生的资源管理器,由Master负责资源的分配;Hadoop Yarn,由Yarn中的ResearchManager负责资源的分配;Messos则由Messos Master负责资源管理。
Executor:执行器
Application运行在Worker节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的一批Executor,如下图所示。
Executor运行原理
Worker:计算节点
集群中任何可以运行Application代码的节点,从节点,负责控制计算节点,启动Executor或Driver。
在Standalone模式中指的就是通过Slave文件配置的Worker节点,在Spark on Yarn模式中指的就是NodeManager节点,在Spark on Messos模式中指的就是Messos Slave节点,如下图所示。
Worker运行原理
DAGScheduler:有向无环图调度器
基于DAG划分Stage并以TaskSet的形势提交Stage给TaskScheduler;负责将作业拆分成不同阶段的具有依赖关系的多批任务;最重要的任务之一就是:计算作业和任务的依赖关系,制定调度逻辑。在SparkContext初始化的过程中被实例化,一个SparkContext对应创建一个DAGScheduler。
DAGScheduler图解
TaskScheduler:任务调度器
将Taskset提交给worker(集群)运行并回报结果;负责每个具体任务的实际物理调度。如图所示。
TaskScheduler图解
Job:作业
由一个或多个调度阶段所组成的一次计算作业;包含多个Task组成的并行计算,往往由Spark Action催生,一个JOB包含多个RDD及作用于相应RDD上的各种Operation。如图所示。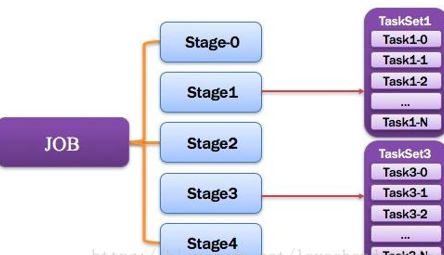
Job图解
Stage:调度阶段
一个任务集对应的调度阶段;每个Job会被拆分很多组Task,每组任务被称为Stage,也可称TaskSet,一个作业分为多个阶段;Stage分成两种类型ShuffleMapStage、ResultStage。如图所示。
Stage图解
Application多个job多个Stage:Spark Application中可以因为不同的Action触发众多的job,一个Application中可以有很多的job,每个job是由一个或者多个Stage构成的,后面的Stage依赖于前面的Stage,也就是说只有前面依赖的Stage计算完毕后,后面的Stage才会运行。
划分依据:Stage划分的依据就是宽依赖,何时产生宽依赖,reduceByKey, groupByKey等算子,会导致宽依赖的产生。
核心算法:从后往前回溯,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。Spark内核会从触发Action操作的那个RDD开始从后往前推,首先会为最后一个RDD创建一个stage,然后继续倒推,如果发现对某个RDD是宽依赖,那么就会将宽依赖的那个RDD创建一个新的stage,那个RDD就是新的stage的最后一个RDD。然后依次类推,继续继续倒推,根据窄依赖或者宽依赖进行stage的划分,直到所有的RDD全部遍历完成为止。
将DAG划分为Stage剖析:如上图,从HDFS中读入数据生成3个不同的RDD,通过一系列transformation操作后再将计算结果保存回HDFS。可以看到这个DAG中只有join操作是一个宽依赖,Spark内核会以此为边界将其前后划分成不同的Stage. 同时我们可以注意到,在图中Stage2中,从map到union都是窄依赖,这两步操作可以形成一个流水线操作,通过map操作生成的partition可以不用等待整个RDD计算结束,而是继续进行union操作,这样大大提高了计算的效率。
TaskSet:任务集
由一组关联的,但相互之间没有Shuffle依赖关系的任务所组成的任务集。如图所示。
Stage图解
提示:
1)一个Stage创建一个TaskSet;
2)为Stage的每个Rdd分区创建一个Task,多个Task封装成TaskSet
Task:任务
被送到某个Executor上的工作任务;单个分区数据集上的最小处理流程单元(单个stage内部根据操作数据的分区数划分成多个task)。如图所示。
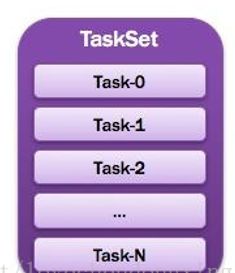
Task图解
架构设计

Spark运行架构包含集群管理器(Cluster Manager)、运行作业的工作节点(Wroker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)。其中,集群管理器可以是Spark自带的资源管理器,也可以是YARN或Mesos等资源管理框架。
Spark采用Executor的优点:
利用多线程来执行具体的任务(Hadoop MapReduce采用的是进程模型),减少任务的启动开销。
Excecutor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,当需要多轮迭代计算时,可以将中间结果存储到这个存储模块里,下次需要时就可以直接读该存储模块里的数据,而不需要读写HDFS等文件系统里,因而有效减少了IO开销;或者在交互式查询场景下,Executor预先将表缓存到该存储系统上,从而可以提高读写IO的性能。
在Spark中,一个应用(Application)由一个任务控制节点(Driver)和若干个作业(Job)构成,一个作业由多个阶段(Stage)构成,一个阶段由多个任务(Task)组成。当执行一个应用时,任务控制节点会向集群管理器(Cluster Manager)申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行任务,运行结束后执行结果会返回给任务控制节点,或者写到HDFS或者其他数据库中。
Spark运行基本流程
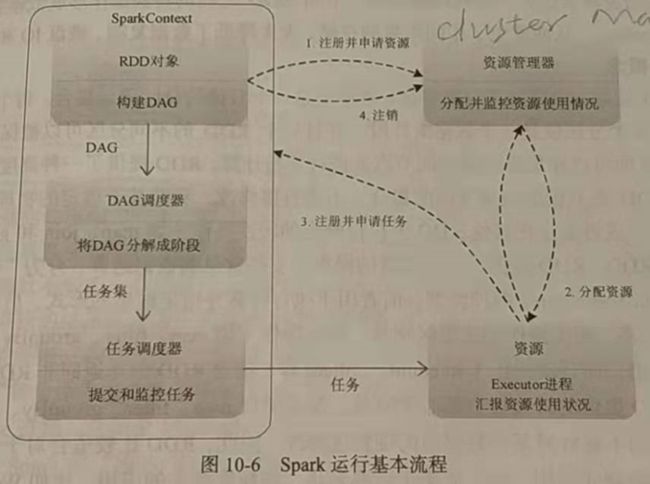
(1)当一个Spark应用被提交时,首先需要为这个应用构建起基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext,由SparkContext负责和资源管理器----Cluster Manager的通信,以及进行资源的申请、任务的分配和监控等。SparkContext会向资源管理器注册并申请运行Executor的资源。
(2)资源管理器为Executor分配资源,并启动Executor进程,Executor运行情况将随着“心跳”发送到资源管理器上。
(3)SparkContext根据RDD的依赖关系构建DAG,并将DAG提交给DAG调度器(DAGScheduler)进行解析,将DAG分解成多个“阶段”(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提供给底层的任务调度器(TaskScheduler)进行处理;Executor向SparkContext申请任务,任务调度器将任务分发给Executor运行,同时SparkContext将应用程序代码发放给Executor。
(4)任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
Spark运行架构的特点:
- 每个应用都有自己专属的Executor进程,并且该进程在应用运行期间一直驻留。Executor进程以多线程的方式运行任务,减少了多进程任务频繁的启动开销,使得任务执行变得非常高效和可靠。
- Spark运行过程与资源管理器无关,只要能够获取Executor进程并保持通信即可。
- 任务采用了数据本地性和推测执行等优化机制。数据本地性是尽量将计算移到数据所在的节点进行,即“计算向数据靠拢”,因为移动计算比移动数据所占的网络资源要少得多。而且,Spark采用了延时调度机制,可以在更大程度上实现执行过程优化。
RDD的设计与运行原理
RDD的设计理念源自AMP实验室论文《Resilient Distributed Datasets:A Fault-Tolerant Abstraction for In-Memory Cluster Computing》。
RDD是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
RDD设计背景
在实际应用中,存在许多迭代式算法和交互式数据挖掘工具,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。目前的MapReduce框架都是把中间结果写入HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。RDD就是为了满足这种需求而出现的,它提供了一种抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化(Pipeline),从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销。
RDD概念
- RDD (Resilient Distributed Datasets) 即弹性分布式对象集,是一个只读的,可分区的分布式数据集。
- RDD默认存储在内存,当内存不足时,溢写到磁盘。
- RDD数据以分区的形式在集群中存储。
- RDD具有血统机制(Lineage), 发生数据丢失时,可快速进行数据恢复。
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合。
每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy等)而创建得到新的RDD;
RDD支持常见的数据运算,分为“行动(Action)”和“转换(Transformation)”两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。
RDD比较适合对于数据集中元素执行相同操作的批处理式应用,而不适用于需要异步、细粒度状态的应用。
RDD典型的执行过程如下:
(1)RDD读入外部数据源(或者内存中的集合)进行创建
(2)RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用。
(3)最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala集合或标题)
注意:RDD采用了惰性调用,即在RDD的执行过程中,真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
RDD特性
Spark采用RDD以后能实现高效计算的主要原因如下:
(1)高效的容错性
现有的分布式共享内存、键值存储、内存数据库等,为了实现容错,必须在集群节点之间进行数据复制或者记录日志,也就是在节点之间会发生大量的数据传输的情况,这对于数据密集型应用而言会带来很大的开销。
在RDD的设计中,数据只读,不可修改,如果需要修改数据,必须从父RDD转换到子RDD,由此在不同RDD之间建立了血缘关系。所以,RDD是一种天生具有容错机制的特殊集合,不需要通过数据冗余的方式(比如检查点)实现容错,而只需通过RDD父子依赖(血缘)关系重新计算丢失的分区来实现容错,无须回滚整个系统。这样就避免了数据复制的高开销,而且重算过程可以在不同节点之间并行进行,实现高效的容错。
此外,RDD提供的转换操作都是一些粗粒度的操作(如map、filter和join等),RDD依赖关系只需要记录这种粗粒度的转换操作,而不需要记录具体的数据和各种细粒度操作的日志(比如对哪个数据进行了修改),这就大大降低了数据密集型应用中的容错开销。
(2)中间结果持久化到内存
(3)存放的数据可以是JAVA对象,避免了不必要的对象序列化和反序列化开销
RDD之间的依赖关系
RDD中不同的操作,会使得不同RDD分区之间会产生不同的依赖关系。DAG调度器根据RDD之间的依赖关系,把DAG划分成若干个阶段。RDD中的依赖关系分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency),二者的主要区别在于是否包含Shuffle操作。
(1)Shuffle操作
在Hadoop MapReduce框架中,Shuffle是连接Map和Reduce的桥梁,Map的输出结果需要经过Shuffle过程以后,也就是经过数据分类以后交给Reduce处理。因此,Shuffle的性能高低直接影响了整个程序的性能和吞吐量。Shuffle是指对Map输出结果进行分区、排序、合并等处理并交给Reduce的过程。
Spark作为MapReduce框架的一种改进,自然也实现了Shuffle的逻辑。
1)首先是Map端的Shuffle写入(Shuffle Write)。
每一个Map任务会根据Reduce任务的数量创建出相应的桶(bucket),这里,桶的数量是m x r,其中,m是Map任务的个数,r是Reduce任务的个数。Map任务产生的结果会根据设置的分区算法填充到每个桶中去。分区算法可以自定义,也可以采用系统默认的算法;默认的算法是根据每个键值对(key,value)的key,把键值对哈希以不同的桶中去。当Reduce任务启动时,它会根据自己任务的id和所依赖的Map任务的id,从远端或是本地取得相应的桶,作为Reduce任务的输入进行处理。
这里的桶是一个抽象概念,在实现中每个桶可以对应一个文件,也可以对应文件的一部分。但是,从性能角度而言,每个桶对应一个文件的实现方式,会导致Shuffle过程生成过多的文件,这样会给文件系统带来沉重的负担。
所以,在最新的Spark版本中,采用了多个桶写入一个文件的方式。每个Map任务不会为每个Reduce任务单独生成一个文件,而是把每个Map任务所有的输出数据只写到一个文件中。Shuffle过程中每个Map任务会产生两个文件,即数据文件和索引文件,其中,数据文件存储当前Map任务的输出结果,索引文件中则存储数据文件中的数据的分区信息。下一阶段的Reduce任务就是根据索引文件来获取属于自己处理的那个分区的数据。
2)其次是Reduce端Shuffle读取(Shuffle Fetch)。
Spark对传统的MapReduce算法进行了一定的改进。Spark假定在大多数应用场景中,Shuffle数据的排序操作不是必须的,因此,Spark并不在Reduce端做归并和排序,而是采用了称为Aggregator的机制。Aggregator本质上是一个HashMap,里面的每个元素是
(2)窄依赖和宽依赖
以是否包含Shuffle操作为判断依据,RDD中的依赖可以分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency)。
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区。
宽依赖则表现为在一个父RDD的一个分区对应一个子RDD的多个分区。
总体而言,如果父RDD的一个分区只被一个子RDD的一个分区所使用就是窄依赖,否则就是宽依赖。窄依赖典型的操作包括map、filter、union等,不会包含Shuffle操作;宽依赖典型的操作包括groupByKey、sortByKey等,通常会包含Shuffle操作。对于连接操作,可以分为两种情况。
1)对输入进行协同划分,属于窄依赖。协同划分(Co-partitioned)是指多个父RDD的某一个分区的所有“键”(key),落在子RDD的同一个分区内,不会出现同一个父RDD的某一分区,落在子RDD的两个分区的情况。
2)对输入做非协同划分,属于宽依赖。
Spark的这种依赖关系设计,使其具有了天生的容错性,大大加快了Spark的执行速度。相对而言,窄依赖的失败恢复更为高效。此外,Spark还提供了数据检查点和记录日志,用于持久化中间RDD,从而使得在进行失败恢复时不需要追溯到最开始的阶段。
阶段的划分
Spark根据DAG中的RDD依赖关系,把一个作业分成多个阶段。宽依赖和窄依赖相较而言,窄依赖对于作业的优化很有利。逻辑上,每个RDD操作都是一个fork/join(一种用于并行执行任务的框架),对每个RDD分区计算fork,完成计算后对各个分区得到的结果进行join操作,然后fork/join下一个RDD操作。
Spark通过分析各个RDD之间的依赖关系生成DAG,再通过分析各个RDD中的分区之间的依赖关系来决定如何划分阶段。具体划分方法是:在DAG中进行反向解析,遇到宽依赖就断开(因为宽依赖涉及Shuffle操作,无法以流水线方式处理),遇到窄依赖就把当前的RDD加入当前的阶段中(因为窄依赖不会涉及Shuffle操作,可以以流水线方式处理)。
把一个DAG划分成多个“阶段”以后,每个阶段都代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集合。每个任务集合会被提交给任务调度器(TaskScheduler)进行处理,由任务调度器将任务分发给Executor运行。
RDD运行过程
(1)创建RDD对象
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG
(3)DAGScheduler负责把DAG分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点上的Executor去执行
Spark的部署和应用方式
Spark的部署方式
Spark支持5种不同的部署方式,即Local、Standalone、Spark on Mesos、Spark on YARN和Spark on Kubernetes。其中,Local模式属于单机部署模式,其他属于分布式部署模式。
Local模式
什么是本地模式?将Spark应用以多线程方式,所有executor都是跑在一个节点的一个进程里面的,每一个executor都是一个线程,直接运行在本地,便于调试
本地模式分类:
local:只启动一个executor
local[K]:启动K个executor
local[*]:启动跟cpu数目相同的executor
Standalone模式(独立模式)
Spark框架自带完整的资源调度管理服务,可以独立部署到一个集群中,而不需要依赖其他系统来为其提供资源管理调度服务。Spark都是由一个Master和若干个Slave节点构成,并且以统一的槽作为资源分配单位提供给各种任务来使用。
Standalone是Spark自己提供的,在这种模式里,Spark自己有一个Master程序。在Master程序里,它会管理很多Worker节点,在Worker节点里面,他的Driver和Executor都是跑在对应的worker之上的程序运行模式:独立(Standlone)模式
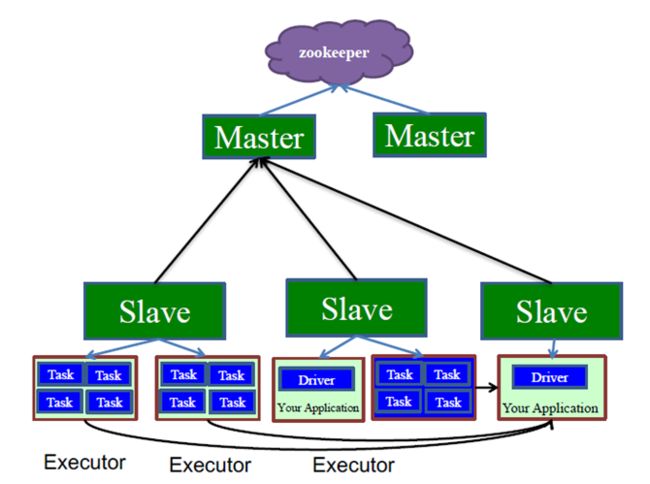
Standalone中,它有一个Master以及多个Slave节点,这都是物理的机器,在每一个Slave上他都运行着很多的Executor,Driver程序实际上是跑在一个Executor之上的,这个Driver会直接向Executor发送任务.
Master是管理整个集群的节点,Master不参与整个任务的分配,他管理的是这些Driver的启动,Driver到Task的启动是由Driver来控制的,不是由Master来控制的.
在这个架构里,Master是一个单点的,为了防止单点,他是通过Zookeeper来进行协作的,还有一个备份的Master,一旦主Master挂掉,所有的Slaver会将汇报转发给备份Master,Master之间的切换是通过Zookeeper来进行的.
Spark on Mesos模式
Mesos是一种资源调度管理框架,由于Mesos和Spark存在一定的血缘关系,Spark运行在Mesos上,要比运行在YARN上更加灵活、自然。目前,Spark官方推荐采用这种模式。
Spark on YARN模式

Spark On YARN存在两种模式:Yarn-Client、Yarn-Cluster。
Yarn-Client模式

一个客户端把程序提交到ResourcesManager申请资源,然后由ResourcesManager去选择一个空闲的NodeManager,去运行一个ApplicationMaster程序,ApplicationMaster会为NodeManagers去向ResourcesManager申请资源,得到NodeManagers各个Executor,他让各个Executor启动后去将自己注册到客户端的Driver程序上,然后Driver在运行过程中,会将任务发送给各个Executor,Executor里面的Task是Driver的Task。
下面这个图更清晰一些:

Yarn-Client这种模式的应用场景解释:
这种模式启动后,会把所有信息都发送到Driver端,Driver端一旦退出,整个应用程序会全部销毁,所以在跑长期的应用,比如要跑十几个小时,你把电脑关上,那就失败,那就不要用Yarn-Client了。
Yarn-Cluster模式
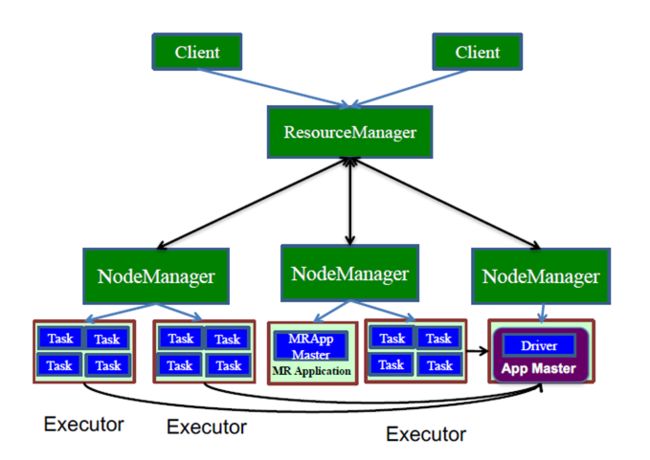
Yarn-Cluster和Yarn-Client比较类似,但是Driver不在运行在Client端,Driver运行在ApplicationMaster之上,除了这里不一样,其他都一样。
即,Yarn-Cluster下,Client端的作用只是把你的任务提交到集群里面,然后由集群选择一个节点去运行,此时你的客户端程序完全退出对集群没有任何关系,集群是会继续跑你的程序。
对比之下,Yarn-Client存在的原因还有:
在Yarn-Cluster里面你的ApplicationMaster是跑在任意一个NodeManager的,这个节点上,你是没法控制它的,比如我想控制程序的执行,再输入一个参数什么的,是很难做到这样的。
再比如Yarn-Client这种模式,我可以在Client端做各种各样的事情,比如进行一些初始化,加载一些东西,或者像Python需要一些必要的环境,这个时候,就需要在Client端把事情都做好,依赖的软件都装好,由Client去运行程序就行了,而如果是Cluster这种,把程序提交到任意一个节点,万一那个节点缺少一些环境,那就没法运行。
Spark on Kubernetes模式
Kubernetes是一个开源窗口协调系统,是Google于2014年酝酿的项目。Spark从2.3.0版本引入了对Kubernetes的原生支持,可以将编写好的数据处理程序直接通过spark-submit提交到Kubernetes集群。
从“Hadoop+Storm”架构转向Spark架构
为了能同时进行批处理与流处理,企业应用中通常会采用“Hadoop+Storm”架构(也称为Lambda架构),在这种部署架构中,Hadoop和Storm框架部署在资源管理框架YARN(或Mesos)之上,接受统一的资源管理和调度,并共享底层的数据存储(HDFS、HBase、Cassandra等)。Hadoop负责对批量历史数据的实时查询和离线分析,Storm则负责对流数据的实时处理。

但是,上面这种架构部署较为烦琐。由于Spark同时支持批处理与流处理,因此对于一些类型的企业应用而言,从“Hadoop+Storm”架构转向Spark架构就成为一种很自然的选择。采用Spark架构具有如下优点:
(1)实现一键式安装和配置、线程级别的任务监控和警告。
(2)降低硬件集群、软件维护、任务监控和应用开发的难度。
(3)便于集成统一的硬件、计算平台资源池。
需要说明的是,Spark Streaming的原理是将流数据分解成一系列短小的批处理作业,每个短小的批处理作业使用面向批处理的Spark Core进行处理,通过这种方式只能变相实现流计算,而不能实现真正实时的流计算,因而通常无法实现毫秒级的响应。因此,对于需要毫秒级实时响应的企业应用而言,仍然需要采用流计算框架(如Storm)。
Hadoop和Spark的统一部署
为什么选择Hadoop和Spark统一部署?
- 由于Hadoop生态系统中的一些组件所实现的功能,目前还无法由Spark取代,比如Storm可以实现毫秒级响应的流计算,但是Spark无法做到毫秒级响应;
- 企业中已经有许多现有的应用,都是基于现有的Hadoop组件开发的,完全转移到Spark上需要一定的成本。因此,在许多企业实际应用中,Hadoop和Spark的统一部署是一种比较现实和合理的选择。