【numpy手写系列】用PCA、LDA、SVM与CNN手写人脸识别代码
引言
目标在本课程项目中,学生将单独构建人脸识别系统系统学生需要应用主成分分析(PCA)来执行数据降维和可视化,以了解底层数据分布。然后,要求学生训练并应用三种分类模型——线性判别分析(LDA)、支持向量机(SVM)和卷积神经网络(CNN)–对人脸图像进行分类。通过该项目,学生有望获得基本的以及当前流行的模式识别技术的重要知识。编程语言学生可以在项目中使用他们选择的任何语言,尽管至少从MATLAB或Python开始。建议使用MATLAB,因为它提供了一个简单、完整的环境,以及可视化结果。特别是,可以在项目并在网上找到。
【numpy手写系列】用PCA、LDA、SVM与CNN手写人脸识别代码
引言
工作区文件结构
数据集
介绍
数据集获取方式:
用于特征提取、可视化和分类的PCA
任务
实现代码
• PCA based data distribution visualization
• PCA plus nearest neighbor classifification results
结果
• PCA based data distribution visualization
• PCA plus nearest neighbor classifification results
用于特征提取和分类的LDA
任务
实现代码
结果
• LDA based data distribution visualization
• LDA plus nearest neighbor classifification results 编辑
用于分类的SVM
任务
实现代码
结果
用于分类的神经网络
任务
实现代码
结果
工作区文件结构
请务必按照以下结构构建工作区域,取名请随意。
数据集
介绍
项目将在CMU PIE数据集上进行,使用70%的所提供的图像用于训练,剩余的30%用于测试。PIE是一个人脸识别数据集,内含68个人,每个人有170张图片,随机抽样一个人取出2张图片看看:


数据集获取方式:
提取码:3x2z https://pan.baidu.com/s/172uo2gLluo47wBTbn3LfHA%C2%A0
https://pan.baidu.com/s/172uo2gLluo47wBTbn3LfHA%C2%A0
用于特征提取、可视化和分类的PCA
任务
原始人脸图像的大小为32×32像素,因此每个图像的1024维矢量年龄从CMU PIE训练集中随机抽取500张图片和您自己的照片。应用PCA将矢量化图像的维数分别降低到2和3。可视化二维和三维绘图中的投影数据矢量。突出显示与照片还可视化用于降维的相应3个特征面。然后应用PCA将人脸图像的维数分别降低到40、80和200。使用最近邻规则对测试图像进行分类。报告分类准确性分别在CMU PIE测试图像和您自己的照片上。
实现代码
• PCA based data distribution visualization
import os
from numpy import *
import numpy as np
import cv2
import matplotlib.pyplot as plt
from pylab import mpl
def img2vector(im_path):
im = cv2.imread(im_path, 0)
rows, cols = im.shape
imgVector = np.zeros((1, rows * cols))
imgVector = np.reshape(im, (1, rows * cols))
return imgVector
def load_dataset(k):
faceData_path = '../PIE'
faceData_length = len(os.listdir(faceData_path))
train_face = np.zeros((faceData_length * k, 32 * 32))
train_label = np.zeros(faceData_length * k)
test_face = np.zeros((faceData_length * (170 - k), 32 * 32))
test_label = np.zeros(faceData_length * (170 - k))
sample = random.permutation(170) + 1
for i in range(faceData_length):
people_idx = i + 1
if people_idx == 26:
for j in range(10):
face_im_path = os.path.join(faceData_path, str(people_idx), str(j+1) + '.jpg')
faceVector_im = img2vector(face_im_path)
if j <= 7:
train_face[i*k+j, :] = faceVector_im
train_label[i*k + j] = people_idx
else:
test_face[i*(170-k) + (j-k), :] = faceVector_im
test_label[i*(170-k) + (j-k)] = people_idx
for j in range(170):
face_im_path = os.path.join(faceData_path, str(people_idx), str(sample[j]) + '.jpg')
faceVector_im = img2vector(face_im_path)
if j < k:
train_face[i*k+j, :] = faceVector_im
train_label[i*k + j] = people_idx
else:
test_face[i*(170-k) + (j-k), :] = faceVector_im
test_label[i*(170-k) + (j-k)] = people_idx
return train_face, train_label, test_face, test_label
def PCA_fit(data, r):
data = np.float32(np.mat(data))
rows, cols = np.shape(data)
data_mean = np.mean(data, 0)
A = data - np.tile(data_mean, (rows, 1))
C = A * A.T
D, V = np.linalg.eig(C)
V_r = V[:, 0:r]
V_r = A.T * V_r
for i in range(r):
V_r[:, i] = V_r[:, i] / np.linalg.norm(V_r[:, i])
final_data = A * V_r
return final_data, data_mean, V_r
if __name__ == "__main__":
for r in [2, 3]:
print('dimensionality of face images to {}:'.format(r))
x_value = []
y_value = []
k = int(170*0.9)
train_face, train_label, test_face, test_label = load_dataset(k)
data_train_new, data_mean, V_r = PCA_fit(train_face[:-501], r)
data_train_new = np.array(data_train_new).astype(float)
if r == 2:
x_plot, y_plot = [], []
for data in data_train_new:
x_plot.append(data[0])
y_plot.append(data[1])
fig = plt.figure()
plt.scatter(x_plot, y_plot)
plt.show()
if r ==3 :
x_plot, y_plot, z_plot = [], [], []
for data in data_train_new:
x_plot.append(data[0])
y_plot.append(data[1])
z_plot.append(data[2])
fig = plt.figure()
ax = fig.add_subplot(111,projection='3d')
plt.set_cmap(plt.get_cmap("seismic", 100))
im = ax.scatter(x_plot, y_plot, z_plot)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
plt.show()
• PCA plus nearest neighbor classifification results
import os
from numpy import *
import numpy as np
import cv2
import matplotlib.pyplot as plt
from pylab import mpl
def img2vector(im_path):
im = cv2.imread(im_path, 0)
rows, cols = im.shape
imgVector = np.zeros((1, rows * cols))
imgVector = np.reshape(im, (1, rows * cols))
return imgVector
def load_dataset(k):
faceData_path = '../PIE'
faceData_length = len(os.listdir(faceData_path))
train_face = np.zeros((faceData_length * k, 32 * 32))
train_label = np.zeros(faceData_length * k)
test_face = np.zeros((faceData_length * (170 - k), 32 * 32))
test_label = np.zeros(faceData_length * (170 - k))
sample = random.permutation(170) + 1
for i in range(faceData_length):
people_idx = i + 1
if people_idx == 26:
for j in range(10):
face_im_path = os.path.join(faceData_path, str(people_idx), str(j+1) + '.jpg')
faceVector_im = img2vector(face_im_path)
if j <= 7:
train_face[i*k+j, :] = faceVector_im
train_label[i*k + j] = people_idx
else:
test_face[i*(170-k) + (j-k), :] = faceVector_im
test_label[i*(170-k) + (j-k)] = people_idx
for j in range(170):
face_im_path = os.path.join(faceData_path, str(people_idx), str(sample[j]) + '.jpg')
faceVector_im = img2vector(face_im_path)
if j < k:
train_face[i*k+j, :] = faceVector_im
train_label[i*k + j] = people_idx
else:
test_face[i*(170-k) + (j-k), :] = faceVector_im
test_label[i*(170-k) + (j-k)] = people_idx
return train_face, train_label, test_face, test_label
def PCA_fit(data, r):
data = np.float32(np.mat(data))
rows, cols = np.shape(data)
data_mean = np.mean(data, 0)
A = data - np.tile(data_mean, (rows, 1))
C = A * A.T
D, V = np.linalg.eig(C)
V_r = V[:, 0:r]
V_r = A.T * V_r
for i in range(r):
V_r[:, i] = V_r[:, i] / np.linalg.norm(V_r[:, i])
final_data = A * V_r
return final_data, data_mean, V_r
if __name__ == "__main__":
for r in [40, 80, 200]:
print('dimensionality of face images to {}:'.format(r))
x_value = []
y_value = []
k = int(170*0.7)
train_face, train_label, test_face, test_label = load_dataset(k)
data_train_new, data_mean, V_r = PCA_fit(train_face, r)
num_train = data_train_new.shape[0]
num_test = test_face.shape[0]
temp_face = test_face - np.tile(data_mean, (num_test, 1))
data_test_new = temp_face * V_r
data_test_new = np.array(data_test_new)
data_train_new = np.array(data_train_new)
# -
is_true_count = 0
for i in range(num_test):
testFace = data_test_new[i, :]
diffMat = data_train_new - np.tile(testFace, (num_train, 1))
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis=1)
sortedDistIndicies = sqDistances.argsort()
indexMin = sortedDistIndicies[0]
if train_label[indexMin] == test_label[i]:
is_true_count += 1
else:
pass
accuracy = float(is_true_count) / num_test
x_value.append(k)
y_value.append(round(accuracy, 2))
print('The classify accuracy is: {:.2f}'.format(accuracy*100))
结果
• PCA based data distribution visualization
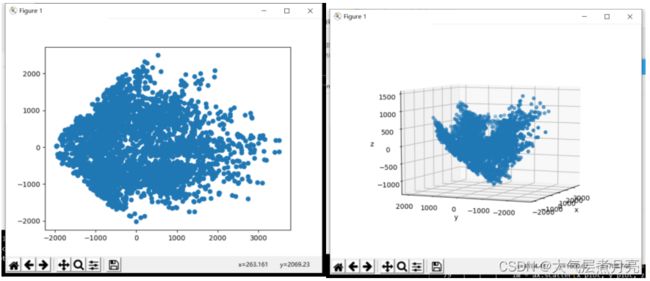
• PCA plus nearest neighbor classifification results

用于特征提取和分类的LDA
任务
应用LDA将数据维度从2、3和9降低维度分别为2和3的采样数据(如PCA部分)(类似于PCA)。分别报告维度为2、3和9的数据的分类精度,基于最近邻分类器。报告CMU PIE测试的分类准确性图片和你自己的照片分开。
实现代码
这题不同于PCA那题,因为需要降低维度刚好是可视化需要的2,3,所以一个代码回答了两个问题。
import numpy as np
import matplotlib.pyplot as plt
import cv2
from numpy import *
import os
def img2vector(im_path):
im = cv2.imread(im_path, 0)
rows, cols = im.shape
imgVector = np.zeros((1, rows * cols))
imgVector = np.reshape(im, (1, rows * cols))
return imgVector
def load_dataset(k):
faceData_path = '../PIE'
faceData_length = len(os.listdir(faceData_path))
train_face = np.zeros((faceData_length * k, 32 * 32))
train_label = np.zeros(faceData_length * k)
test_face = np.zeros((faceData_length * (170 - k), 32 * 32))
test_label = np.zeros(faceData_length * (170 - k))
sample = random.permutation(170) + 1
for i in range(faceData_length):
people_idx = i + 1
if people_idx == 26:
for j in range(10):
face_im_path = os.path.join(faceData_path, str(people_idx), str(j+1) + '.jpg')
faceVector_im = img2vector(face_im_path)
if j <= 7:
train_face[i*k+j, :] = faceVector_im
train_label[i*k + j] = people_idx
else:
test_face[i*(170-k) + (j-k), :] = faceVector_im
test_label[i*(170-k) + (j-k)] = people_idx
for j in range(170):
face_im_path = os.path.join(faceData_path, str(people_idx), str(sample[j]) + '.jpg')
faceVector_im = img2vector(face_im_path)
if j < k:
train_face[i*k+j, :] = faceVector_im
train_label[i*k + j] = people_idx
else:
test_face[i*(170-k) + (j-k), :] = faceVector_im
test_label[i*(170-k) + (j-k)] = people_idx
return train_face, train_label, test_face, test_label
def LDA(face,label,k):
x, y = face.shape
classes = np.unique(label)
meanAll = face.mean(axis=0)
Sb = np.zeros((y, y),dtype = np.float32)
Sw = np.zeros((y, y), dtype=np.float32)
for i in classes:
face_i = face[np.where(label == i)[0],:]
mean_i = face_i.mean(axis = 0)
n = face_i.shape[0]
Sw = Sw + np.dot((face_i - mean_i).T,(face_i-mean_i))
Sb = Sb + n*np.dot((mean_i - meanAll).T,(mean_i - meanAll))
#print("Sw");print(Sw);print("end");print("Sb");print(Sb);print("end")
tmp = np.ones(Sw.shape)/500
Sw = tmp + Sw
matrix = np.linalg.inv(Sw) @ Sb
eigenvalue,eigenvector = np.linalg.eigh(matrix)
#print("vec");print(eigenvector);print("end")
index = np.argsort(eigenvalue) # 排序
index = index[:-(k + 1):-1]
select = eigenvector[:, index]
return select
def recognize_lda():
eachNum = int(170*0.7) # 每个人拿出eachNum张照片进行训练
train_face, train_label, test_face, test_label = load_dataset(eachNum)
for k in [2, 3, 9]:
print('when k={}:'.format(k), end=' ')
W = LDA(train_face, train_label, k)
train = np.dot(train_face, W)
test = np.dot(test_face, W)
if k == 2:
x_plot, y_plot = [], []
for data in train[:-501]:
x_plot.append(data[0])
y_plot.append(data[1])
fig = plt.figure()
plt.scatter(x_plot, y_plot)
plt.show()
if k ==3 :
x_plot, y_plot, z_plot = [], [], []
for data in train[:-501]:
x_plot.append(data[0])
y_plot.append(data[1])
z_plot.append(data[2])
fig = plt.figure()
ax = fig.add_subplot(111,projection='3d')
plt.set_cmap(plt.get_cmap("seismic", 100))
im = ax.scatter(x_plot, y_plot, z_plot)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
plt.show()
acc = KNN(train,train_label,test,test_label,eachNum)
print("the acc=", acc*100);
def KNN_classify(face,train_face,train_label,k):
dis = np.sum(np.power((train_face - face),2),axis=1)
index = np.argsort(dis)[:k]
weight = []
for i in range(k):
weight.append(dis[index[k-1]] - dis[index[i]] / (dis[index[k-1]] - dis[index[0]]))
count = [0 for i in range (train_face.shape[0])]
tmp = 0
for i in index:
count[int(train_label[i])] += 1 + weight[tmp]
tmp += 1
label = np.argmax(count);
return label
def KNN(train_faces, train_labels,test_faces, test_labels, k):
sum = test_faces.shape[0]
err = 0
for i in range(sum):
count = KNN_classify(test_faces[i],train_faces,train_labels,k)
if count != test_labels[i]:
err += 1
acc = (sum - err) / sum
return acc
if __name__ == "__main__":
recognize_lda()
结果
• LDA based data distribution visualization
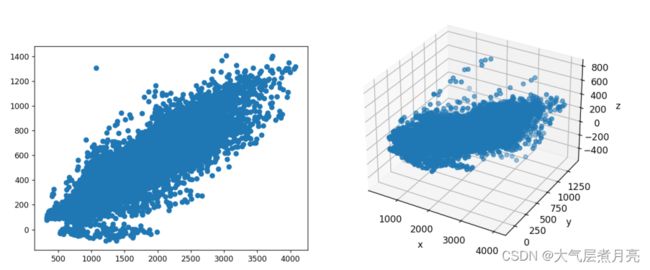
• LDA plus nearest neighbor classifification results 
用于分类的SVM
任务
使用原始面部图像(矢量化)和PCA预处理后的面部向量(维度为80和200)作为线性SVM的输入。惩罚参数C的尝试值{1×10英寸−2, 1 × 10−1, 1}. 报告不同参数和尺寸。讨论数据维度和参数C对最终分类的影响精确。
实现代码
import os
from numpy import *
import numpy as np
import cv2
import matplotlib.pyplot as plt
from pylab import mpl
def img2vector(im_path):
im = cv2.imread(im_path, 0)
rows, cols = im.shape
imgVector = np.zeros((1, rows * cols))
imgVector = np.reshape(im, (1, rows * cols))
return imgVector
def load_dataset(k):
faceData_path = '../PIE'
faceData_length = len(os.listdir(faceData_path))
train_face = np.zeros((faceData_length * k, 32 * 32))
train_label = np.zeros(faceData_length * k)
test_face = np.zeros((faceData_length * (170 - k), 32 * 32))
test_label = np.zeros(faceData_length * (170 - k))
sample = random.permutation(170) + 1
for i in range(faceData_length):
people_idx = i + 1
if people_idx == 26:
for j in range(10):
face_im_path = os.path.join(faceData_path, str(people_idx), str(j+1) + '.jpg')
faceVector_im = img2vector(face_im_path)
if j <= 7:
train_face[i*k+j, :] = faceVector_im
train_label[i*k + j] = people_idx
else:
test_face[i*(170-k) + (j-k), :] = faceVector_im
test_label[i*(170-k) + (j-k)] = people_idx
for j in range(170):
face_im_path = os.path.join(faceData_path, str(people_idx), str(sample[j]) + '.jpg')
faceVector_im = img2vector(face_im_path)
if j < k:
train_face[i*k+j, :] = faceVector_im
train_label[i*k + j] = people_idx
else:
test_face[i*(170-k) + (j-k), :] = faceVector_im
test_label[i*(170-k) + (j-k)] = people_idx
return train_face, train_label, test_face, test_label
def PCA_fit(data, r):
data = np.float32(np.mat(data))
rows, cols = np.shape(data)
data_mean = np.mean(data, 0)
A = data - np.tile(data_mean, (rows, 1))
C = A * A.T
D, V = np.linalg.eig(C)
V_r = V[:, 0:r]
V_r = A.T * V_r
for i in range(r):
V_r[:, i] = V_r[:, i] / np.linalg.norm(V_r[:, i])
final_data = A * V_r
return final_data, data_mean, V_r
if __name__ == "__main__":
for r in [80, 200]:
for c in [0.01, 0.1, 1]:
print('dimensionality of face images to {}, the value of parameter C is: {}'.format(r, c))
x_value = []
y_value = []
k = int(170*0.7)
train_face, train_label, test_face, test_label = load_dataset(k)
data_train_new, data_mean, V_r = PCA_fit(train_face, r)
data_train_new = np.array(data_train_new).astype(float)
from sklearn import svm
lin = svm.SVC(kernel='linear', C=c)
lin.fit(data_train_new, train_label)
predict = lin.predict(data_train_new)
acc = sum(train_label==predict) // data_train_new.shape[0]
print('accuarcy:{}'.format(acc*100))
结果

用于分类的神经网络
任务
训练具有两个卷积层和一个完全连接层的CNN,其架构如下:number节点数:20-50-500-21。最后一层的节点数固定为21执行21个类别(20个CMU PIE人脸加1个自己)分类。卷积内核大小设置为5。每个卷积层后面是一个最大池层内核大小为2,步幅为2。完全连接层之后是ReLU。训练网络并报告最终分类性能。
实现代码
import tensorflow as tf
import os
from numpy import *
import numpy as np
import cv2
def load_dataset(k):
faceData_path = '../PIE'
faceData_length = len(os.listdir(faceData_path))
train_face, train_label = [], []
test_face, test_label = [], []
sample = random.permutation(170) + 1
# 48, 68
for i in range(faceData_length-20, faceData_length):
people_idx = i + 1
for j in range(170):
face_im_path = os.path.join(faceData_path, str(people_idx), str(sample[j]) + '.jpg')
faceVector_im = cv2.imread(face_im_path)
if j < k:
train_face.append(faceVector_im)
train_label.append(people_idx-(faceData_length-20))
else:
test_face.append(faceVector_im)
test_label.append(people_idx-(faceData_length-20))
return np.array(train_face).astype(float), np.array(train_label), np.array(test_face).astype(float), np.array(test_label)
if __name__ == '__main__':
train_face, train_label, test_face, test_label = load_dataset(int(170*0.7))
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=20,kernel_size=(5,5),padding='same',input_shape=(32, 32, 3),activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2,2), strides=2),
tf.keras.layers.Conv2D(filters=50,kernel_size=(5,5),padding='same',activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2,2), strides=2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(500, activation='relu'),
tf.keras.layers.Dense(21,activation='softmax')])
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
model.fit(train_face, train_label, epochs=5) #训练模型
model.evaluate(test_face, test_label, batch_size=32,verbose=2)
结果
