唐宇迪学习笔记1:Python环境安装、Pytho科学计算库——Numpy
目录
一、AI数据分析入门
1、案例来源
2、Python环境配置(Python3)
Python的安装
Python库安装工具
Jupyter Notebook
二、Python科学计算库——Numpy
1、 Numpy工具包概述
2、数组结构
3、ndarray基本属性操作
打印当前输入是什么类型的
dtype:数组的类型
array元素的字节数
数组元素个数
数组矩阵规模
数组的填充
数组维度
索引与切片:与Python一样 从0开始
矩阵格式(多维的形式)
数组的赋值(=),赋值后数组的改变会影响赋值前元素的值 (地址相同)。
数组的复制(.copy()),赋值后数组的改变不会影响赋值前元素的值 (地址不同)。
4、数据索引方法
np.arange(0,100,10):从0到100,步长为10:
随机构建10个值
类型的改变(float、int、 object)
astype:转换数组的数据类型
4、数值计算方法
加法操作
指定要进行的操作是沿着什么轴(维度)
乘积操作
取最小值(最大值max同理)
找到最小值索引位置(最大值同理)
求均值
标准差
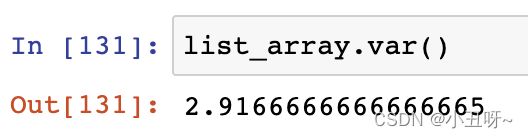
方差
截断操作在【2,4】范围内
四舍五入
5、排序
6、数组形状操作
改变维数(新加轴)
轴压缩
矩阵的转置
7、数组生成常用函数
构造出来一个数组
线性空间
对数空间,默认是10为底
更常用的zeros ,ones
empty()、fill():填充。
zeros_like:维度相同的情况下进行值的填充
8、运算操作
乘法操作
一维的时候是内积点乘操作
二维的时候是矩阵计算
逻辑或
逻辑与
逻辑非
9、随机模块
随机操作
随机的高斯初始化操作
洗牌
随机的种子
10、读写模块
总结
一、AI数据分析入门
 1、案例来源
1、案例来源
GitHub、kaggle(数据挖掘竞赛网站)
2、Python环境配置(Python3)
-
Python的安装
下载Anaconda:https://www.anaconda.com/
Anaconda中,安装了必备的库、配置好了环境变量、提供了开发环境及许多资源。
-
Python库安装工具
在Anaconda Prompt中配置需要用到的库。
conda list:搜索当前Anaconda中已经装好的库。
安装库:pip install (库名) 或者 conda install (库名)
注:当pip install报错时,使用非官方的Windows中Python扩展包 ,在网站里面选择下载需要的: https://www.lfd.uci.edu/~gohlke/pythonlibs/ (.whl文件是pip的工具包,可以直接下载安装)
-
Jupyter Notebook
用浏览器写代码。新建:new-》Python3
优点:可以加文字说明、图片展示、片段执行(运行:shift+回车)
添加注释(Markdown):
 ——(运行)——》
——(运行)——》
单元格删除: 
单元格恢复:edit-》Undo Delete Cells
文件路径:
import os
print(os.path.abspath('.'))修改文件路径:参考jupyter notebook 如何修改一开始打开的文件夹路径? - 知乎
二、Python科学计算库——Numpy
1、 Numpy工具包概述
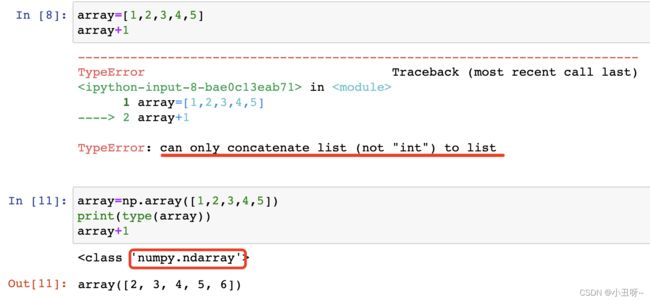
Python在矩阵计算中,不要写list数组结构,把所有矩阵的操作转换成numpy.ndarray结构。
2、数组结构
array数组的加减乘除操作:shape值必须相同。

对于ndarray结构来说,里面的元素必须是同一类型的,如果不是的话,会自动的向下转换。

3、ndarray基本属性操作
打印当前输入是什么类型的

dtype:数组的类型

array元素的字节数

数组元素个数
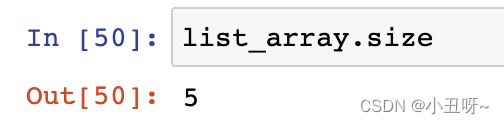
数组矩阵规模

数组的填充

数组维度
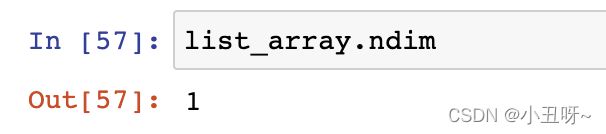
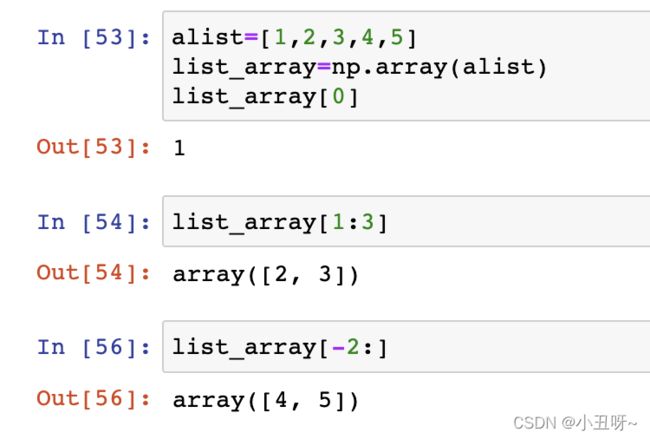
索引与切片:与Python一样 从0开始
 矩阵格式(多维的形式)
矩阵格式(多维的形式)

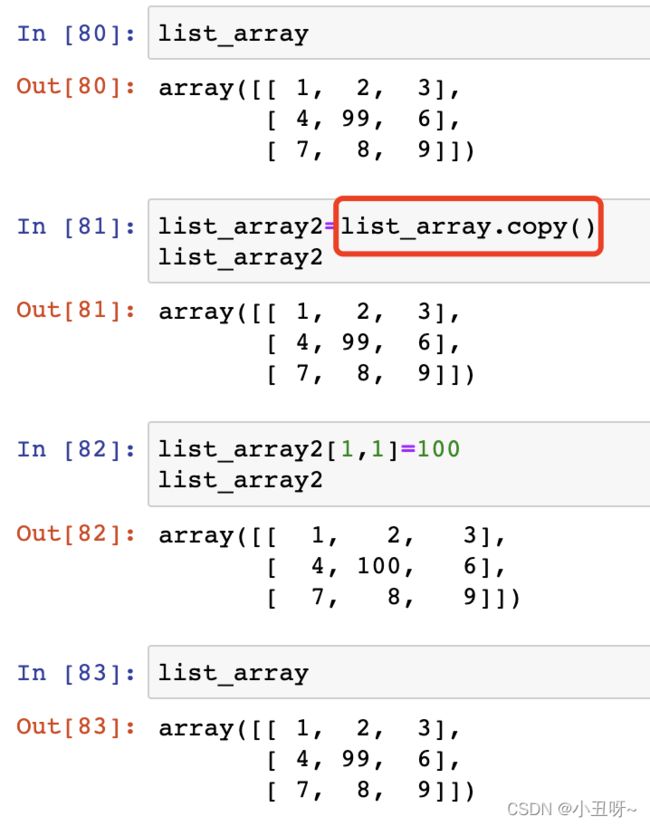
数组的赋值(=),赋值后数组的改变会影响赋值前元素的值 (地址相同)。

数组的复制(.copy()),赋值后数组的改变不会影响赋值前元素的值 (地址不同)。
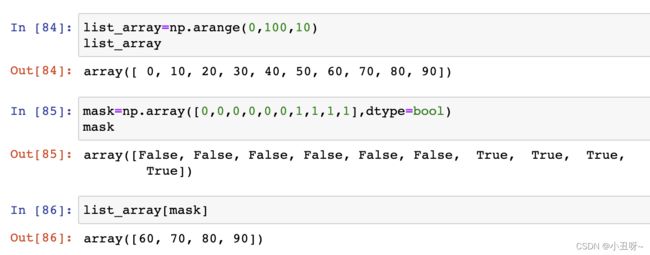
4、数据索引方法
np.arange(0,100,10):从0到100,步长为10:
随机构建10个值

类型的改变(float、int、 object)

astype:转换数组的数据类型

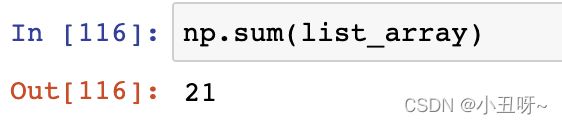
4、数值计算方法
 加法操作
加法操作
指定要进行的操作是沿着什么轴(维度)
 乘积操作
乘积操作

取最小值(最大值max同理)

找到最小值索引位置(最大值同理)

求均值

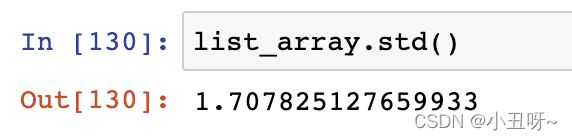
标准差
方差
截断操作在【2,4】范围内

四舍五入


5、排序

np.linspace(start,end.sum)

插入到:np.searchsorted(list_array,values) ,返回插入的位置。

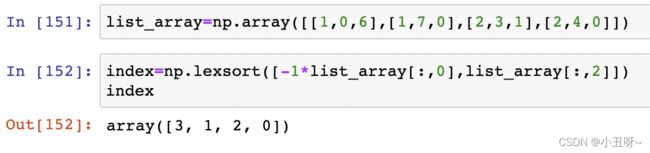
按第一列降序(-1)排序,第三列升序排序。
6、数组形状操作

改变维数(新加轴)

轴压缩
 矩阵的转置
矩阵的转置
数组的连接
 hu
hu 
7、数组生成常用函数
构造出来一个数组

线性空间
 对数空间,默认是10为底
对数空间,默认是10为底

更常用的zeros ,ones


empty()、fill():填充
 zeros_like:维度相同的情况下进行值的填充
zeros_like:维度相同的情况下进行值的填充
8、运算操作
乘法操作

一维的时候是内积点乘操作

二维的时候是矩阵计算

逻辑或
np.logical_or(x,y)
逻辑与
np.logical_and(x,y)
逻辑非
np.logical_not(x,y)
9、随机模块
随机操作
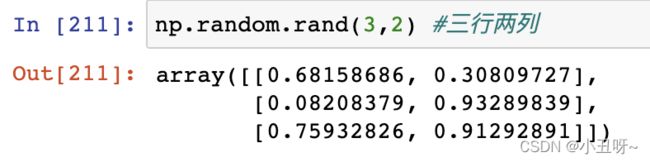
所有的值都是0到1
 返回的是随机的整数,左闭右开
返回的是随机的整数,左闭右开

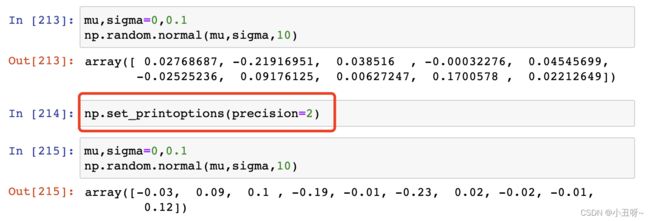
随机的高斯初始化操作
洗牌

随机的种子
(保证每次按照当前模式随机(牌一样,随机发)) 
10、读写模块
%%write li.txt
1 2 3 4 5
6 7 8 9 1python:
data=[]
with open('li.txt') as f:
for line in f.readlines():
fileds=lines.splite()
cur_data=[float(x) for x in fileds]
data.append(cur_data)
data=np.array(data)
data

读取array结构
