【AI简报20210702期】骁龙888 plus发布、RISC-V处理器大飞跃

RT-AK进展
1. RT-AK 开源:RT-Thread面向嵌入式端开发的人工智能套件
Github链接:https://github.com/RT-Thread/RT-AK

RT-Thread面向嵌入式人工智能开发套件RT-AK已经开源一段时间了,从各个方面收到的反馈都比较好,但同时也存在着一定的不足。为了能够为广大开发者提供更加优质便捷的嵌入式AI开发工具链,希望更多的读者能够加入到RT-AK的试用和使用当中,积极反馈您在使用过程中遇到的问题和迫切需求,从而进一步提升RT-AK工具链的品质,最终更好服务广大的AIOT开发者。当前RT-AK工具链支持两个系列的芯片,一种是STM32系列MCU,另一类是带有npu的kendryte系列MCU,未来我们也将会尽可能的增加更多的芯片平台支持。如果您是嵌入式AI的开发者,您更关心哪款芯片的支持,可以在文末留言,我们会尽可能的回复您。如果您是AI芯片的产商,并希望集成RT-Thread和RT-AK系统,也欢迎您联系我们。关于RT-AK的详细内容,可以参考以下链接:
RT-AK开源轻松实现一键部署AI模型至RT-Thread解析:http://www.elecfans.com/d/1591029.html
RT-Thread AI Kit 之 RISC-V 插件初体验: https://mp.weixin.qq.com/s/UMED8uHOiURJEhyJ_cLtBA
RT-AK DEMO 实战教程: https://mp.weixin.qq.com/s/8l1L8zsbh8vwUbjvt5bL_A
嵌入式AI
2. 下半年旗舰芯片骁龙888 Plus发布,AI性能大幅提升
原文链接:
https://new.qq.com/rain/a/20210629A0CP0B00

根据高通官网给出的介绍,全新骁龙888 Plus 5G移动平台,作为骁龙888旗舰移动平台的升级产品到来。凭借强劲性能、超快速度和顶级连接,骁龙888 Plus正助力移动终端提供旗舰级的智能娱乐体验,包括AI加持的游戏、流传输、影像等。
据悉,该平台支持完整的Snapdragon Elite Gaming特性,能够提供超流畅的操控响应、色彩丰富的HDR图形画质和移动端首创的端游级特性。
与骁龙888相比,骁龙888 Plus集成高通Kryo 680 CPU,超级内核主频高达3.0GHz,支持第6代高通AI引擎,其算力达每秒32万亿次运算(32 TOPS),AI性能提升超过20%。
3. 武汉工程大学打造国内领先嵌入式人工智能实验室样本间
原文链接:
https://www.sohu.com/a/473650067_100150001

伴随着人工智能时代的到来,相关专业人才的巨大缺口推动着众多高校不断新增人工智能专业。如何着力提升人工智能领域人才培养水平,为社会提供更加充分的人才支撑,成为了每个高校教育工作者思考的关键问题。
武汉工程大学、蓝鸽科技和Intel合作,设计了AI基础知识、AI应用技能、AI产教有机融合的多功能、一体化的专业人工智能实训室解决方案。同时,还配备了完整的AI课程体系、丰富的AI实训套件、专业的AI实训平台、稳定的边缘计算设备,最大程度地满足了该校“教、学、练、考、用”等全方位场景化应用,成为当今高校人工智能学科建设和专业人才培养计划具有示范意义的创新实践路径。
武汉工程大学人工智能学科老师曾表示,硬件设备和软件资源的简单“拼盘化”,并不能完全满足师生在人工智能领域的教学需求和对实训资源的操作需求。而新建设的嵌入式人工智能实训室才能帮助学校有力地培养人工智能高端人才,完善人工智能领域学科布局;帮助学生更好实现创新突破和实训成果转化,满足自身专业技能培养需求。
希望武汉工程大学可以在嵌入式AI人才培养方面为我国人工智能的研发助力!
4. 全球首颗!RISC-V处理器大飞跃,模拟AI芯片问世
原文链接:
https://www.163.com/dy/article/GDMQ12SD05372HGL.html
近日,据外媒披露,全球首款集成了RISC-V指令集的模拟AI芯片——Mythic AMP在美国奥斯汀问世。

这是一款单芯片模拟计算设备,并采用Mythic的模拟计算引擎,而不是利用传统的数字来创建处理器,以便于将内存集成到处理器中,耗电量比传统模拟处理器低 10 倍。
熟悉传统计算原理的都知道,在常规计算机中,数据会定期从 DRAM 内存传输到 CPU。
内存保存程序和数据。计算机中的处理器和内存是分开的,数据在两者之间移动。处理器无论速度有多快,在从内存中获取数据时都必须处于空闲状态,并且取决于传输速率——这就是所谓的冯诺依曼限制。因此,将计算和内存合并到单个设备中就成为了大家探索的解决方法,而模拟 AI 就消除了冯诺依曼瓶颈,从而显着提高了性能。
5. 百度AI芯片业务独立:“昆仑芯”估值已达130 亿人民币
原文链接:
https://www.163.com/dy/article/GDO6KQG205371IJN.html
摘要:6月29日消息,早在今年3月,路透社就曾报道称百度已经将其人工智能(AI)芯片业务独立拆分,成立了昆仑芯(北京)科技有限公司,原百度智能芯片总经理欧阳剑担任昆仑芯公司CEO,并以高达130亿元的估值获得了一轮融资。近日,百度对此消息进行了确认,并公布了该轮融由CPE源峰领投,IDG、君联资本、元禾璞华等跟投,昆仑芯估值已达130亿元。

6月29日消息,早在今年3月,路透社就曾报道称百度已经将其人工智能(AI)芯片业务独立拆分,成立了昆仑芯(北京)科技有限公司,原百度智能芯片总经理欧阳剑担任昆仑芯公司CEO,并以高达130亿元的估值获得了一轮融资。近日,百度对此消息进行了确认,并公布了该轮融由CPE源峰领投,IDG、君联资本、元禾璞华等跟投,昆仑芯估值已达130亿元。
欧阳剑表示,AI计算和半导体技术出现前所未有的变革机会,数据中心、智能汽车、手机乃至PC等领域,对AI计算的需求空前旺盛,新场景层出不穷,新的运算架构蓬勃创新。在历史机遇下,百度基于过去10年在芯片领域积累成立新公司,继续增加创新投入,在AI计算和半导体领域打造领军企业。
6. 全球首款车规级全栈AI语音芯片流片成功
原文链接:
https://new.qq.com/omn/20210701/20210701A02SLX00.html
汽车产业“新四化”,即电动化、网联化、智能化、共享化,已经成为了汽车行业公认的未来趋势,而且政策的支持、开放的市场环境等,也都促使汽车产业向新四化方向发展。亿咖通科技沈子瑜表示随着汽车“新四化”的快速发展,带动汽车半导体芯片需求高速增长,亿咖通科技沈子瑜说芯片需求的增长也就意味着,在智能网联汽车的赛道上,要打造智能生态圈,车规级芯片是核心。亿咖通科技沈子瑜表示只要掌握了车载计算机系统的核心—车规级芯片,就能够在未来的技术竞争中实现弯道超车。

亿咖通科技沈子瑜说,面对汽车智能化,强大的算力将成为未来智能汽车进化的基础,车规级芯片则更是支撑汽车智能化、网联化的核心。而亿咖通科技沈子瑜作为亿咖通智能科技公司的领导人,立志要成为为智能汽车提供软硬技术支撑的科技公司。亿咖通科技沈子瑜说亿咖通科技从成立之初,就瞄准打造算力平台,布局下一代智能网联汽车电子电气架构的全面芯片产品序列。亿咖通科技沈子瑜表示,在2016年,亿咖通就已经明确了“联合+自主定义”的突围路径,持续推进对汽车芯片的研发。亿咖通科技沈子瑜表示,到目前为止,亿咖通科技已形成了高性能车规级数字座舱芯片E系列、全栈AI语音芯片V系列、先进驾驶辅助芯片AD系列、微控制处理器M系列的四大序列、多款核心产品的芯片矩阵。
AI新闻
7. 上汽董事长谈与华为合作自动驾驶:不能接受
原文链接:
https://www.oschina.net/news/144507/facebook-ai-pytorch
IT 之家 7 月 1 日消息 据证券时报报道,在上汽集团股东大会上,有投资者提问道,上汽是否会考虑在自动驾驶方面与华为等第三方公司合作。对此,上汽董事长陈虹表示,与华为这样的第三方公司合作自动驾驶,上汽是不能接受的。

上汽董事长陈虹还解释道," 这就好比一家公司为我们提供整体的解决方案,如此一来,它就成了灵魂,而上汽就成了躯体。对于这样的结果,上汽是不能接受的,要把灵魂掌握在自己手中。"
IT 之家了解到,华为目前致力于为整车厂商提供一系列配套方案,特别是在自动驾驶等方面。华为在 5 月 24 日曾发布声明重申不造车,称 " 华为不造车。这一长期战略在 2018 年就已明确,没有任何改变。
此外,在 6 月 28 日的中国汽车产业发展高峰论坛上,华为智能汽车解决方案 BU Marketing 与销售服务部总裁迟林春还表示,与手机终端不同,目前华为还不具备造车实力,同时也不会控股和投资任何汽车企业。
8. 2021世界人工智能大会倒计时十天,公众报名注册指南发布
原文链接:
https://www.thepaper.cn/newsDetail_forward_13357109

专业听众线下参会观展
注册截止时间为7月6日24:00
2021世界人工智能大会将于7月8日-7月10日正式对公众开放,7月7日是展览体验日,为定向邀请。此次大会公众参与机制为“线下预约制,线上开放式”。
公众可通过【云平台2.0】进行注册报名,6月8日-7月6日注册登录后可免费预约线下论坛以及线下免费观展(线下论坛注册预约截止时间为7月6日24:00)。7月7日-7月10日现场不开放临时注册,只可通过线上云平台观看直播。
9. 刘卫红:车规级AI芯片让汽车智能“芝麻开门”
“芯片不是孤立存在的,它需要整合上下游零部件,包括传感器、毫米波雷达、超声波雷达,甚至V2X,它也需要有强大的工具链、需要强大的软件支撑。所以我们希望整个芯片的生态要形成完整的、开放的、共赢的生态环境。”
黑芝麻智能科技联合创始人、COO刘卫红在2021年第十三届中国汽车蓝皮书论坛上的《高性能车规芯片赋能智能出行》主题演讲中表示。

去年下半年以来,全球电子企业又深陷“缺芯”危机,芯片短缺带来的影响还在延续,全球汽车累计停产数已达299万辆,最终可能造成全球减产409万辆新车。
大规模芯片短缺问题给予车企巨大警示,不少国内车企开始寻找更可靠、更安全的本地芯片供应商,而许多自主芯片公司即是他们考察的对象之一。在与国际巨头的竞争中,自主芯片公司能否找到自己的位置,成功扩大在车载芯片领域的份额,成为业界最感兴趣的话题。
成立于2016年的黑芝麻智能科技有限公司,是一家专注视觉感知技术与自主IP芯片开发的高科技初创企业。主攻领域为嵌入式图像和计算机视觉,核心业务是提供基于图像处理、计算图像以及人工智能的嵌入式视觉感知芯片计算平台,为ADAS及自动驾驶提供完整的商业落地方案。
刘卫红在演讲中着重介绍了芯片的发展趋势,目前汽车电子电气架构从域控制器向中央计算平台发展;大算力高性能芯片对智能驾驶的支撑车规;芯片要经过系统化认证确保行车安全和信息安全;芯片相关的架构层级和协同分工,形成生态架构。
黑芝麻智能目前已经与一汽、蔚来、上汽、比亚迪、博世、滴滴、中科创达、亚太、东风设计研究院、东风悦享、纽劢科技等在ADAS 和自动驾驶感知系统解决方案上展开商业合作,而其算法和图像处理等技术也已在智能手机、汽车后装、智能家居等消费电子领域布局和商业落地。
聊点技术
10. Tensorflow模型量化原理
原文链接:
https://discuss.tf.wiki/t/topic/1187
1. 模型量化需求
为了满足各种 AI 应用对检测精度的要求,深度神经网络结构的宽度、层数、深度以及各类参数等数量急速上升,导致深度学习模型占用了更大的存储空间,需要更长的推理时延,不利于工业化部署;目前的模型都运行在 CPU,GPU,FPGA,ASIC 等四类芯片上,芯片的算力有限;对于边缘设备上的芯片而言,在存储、内存、功耗及时延性方面有许多限制,推理效率尤其重要。
作为通用的深度学习优化的手段之一,模型量化将深度学习模型量化为更小的定点模型和更快的推理速度,而且几乎不会有精度损失,其适用于绝大多数模型和使用场景。此外,模型量化解锁了定点硬件 (Fixed-point hardware) 和下一代硬件加速器的处理能力,能够实现相同时延的网络模型推理功能,硬件价格只有原来的几十分之一,尤其是 FPGA,用硬件电路去实现网络推理功能,时延是各类芯片中最低的。
TensorFlow 模型优化工具包是一套能够优化机器学习模型以便于部署和执行的工具。该工具包用途很多,其中包括支持用于以下方面的技术:
通过模型量化等方式降低云和边缘设备(例如移动设备和 IoT 设备)的延迟时间和推断成本。将优化后的模型部署到边缘设备,这些设备在处理、内存、耗电量、网络连接和模型存储空间方面存在限制。在现有硬件或新的专用加速器上执行模型并进行优化。
根据您的任务选择模型和优化工具:
利用现成模型提高性能在很多情况下,预先优化的模型可以提高应用的效率。
2. 模型量化过程
大家都知道模型是有权重 (w) 和偏置 (b) 组成,其中 w,b 都是以 float32 存储的,float32 在计算机中存储时占 32bit,int8 在计算机中存储时占 8bit;模型量化就是用 int8 等更少位数的数据类型来代替 float32 表示模型的权重 (w) 和偏置 (b) 的过程,从而达到减少模型尺寸大小、减少模型内存消耗及加快模型推理速度等目标。
模型量化以损失推理精度为代价,将网络中连续取值或离散取值的浮点型参数(权重 w 和输入 x)线性映射为定点近似 (int8/uint8) 的离散值,取代原有的 float32 格式数据,同时保持输入输出为浮点型,从而达到减少模型尺寸大小、减少模型内存消耗及加快模型推理速度等目标。定点量化近似表示卷积和反卷积如下图 所示,左边是原始权重 float32 分布,右边是原始权重 float32 经过量化后又反量化后权重分布。


图 2.1 Int8 量化近似表示卷积


图 2.2 Int8 量化近似表示反卷积
3. 模型量化好处
减小模型尺寸,如 8 位整型量化可减少 75% 的模型大小;
减少存储空间,在边缘侧存储空间不足时更具有意义;
减少内存耗用,更小的模型大小意味着不需要更多的内存;
加快推理速度,访问一次 32 位浮点型可以访问四次 int8 整型,整型运算比浮点型运算更快;CPU 用 int8 计算的速度更快
减少设备功耗,内存耗用少了推理速度快了自然减少了设备功耗;
支持微处理器,有些微处理器属于 8 位的,低功耗运行浮点运算速度慢,需要进行 8bit 量化。
某些硬件加速器如 DSP/NPU 只支持 int8
4. 模型量化原理
模型前向推理过程中所有的计算都可以简化为 x= w*x +b; x 是输入,也叫作 FeatureMap,w 是权重,b 是偏置;实际过程中 b 对模型的推理结果影响不大,一般丢弃。原本 w,x 是 float32,现在使用 int8 来表示为 qw,qx;模型量化的原理就是定点 (qw qx) 与浮点 (w,x),建立了一种有效的数据映射关系.。不仅仅量化权重 W ,输入 X 也要量化;详解如下:
R 表示真实的浮点值(w 或者 x),???? 表示量化后的定点值(qw 或者 qx),Z 表示浮点值定点量化后的量化零点,S 则为浮点值定点量化后的量化尺度。
由浮点到定点的量化公式如下:
1???? = R/S + Z
由定点到浮点反量化公式如下:
1R = (???? - Z) * S
同时,S 和 Z 的求值公式如下:
1S = (Rmax- Rmin)/(????max-????min)
Rmax 表示最大的浮点数 ,Rmin 表示最小的浮点数
????max 表示最大的定点数 ,????min 表示最小的定点数
1Z = ????max- Rmax /S = - Rmin /S + ????min
量化后的 ???? 还是反推求得的浮点值 R,若它们超出各自可表示的最大范围,则需进行截断处理。特别说明:一是浮点值 0 在神经网络里有着举足轻重的意义,比如 padding 就是用的 0,因而必须有精确的整型值来对应浮点值 0。二是以往一般使用 uint8 进行定点量化,而目前有提供 float16 和 int8 等定点量化方法,而 int8 定点量化针对不同的数据有不同的范围定义。深度模型的前向推导通过量化实现 8-bit 版本运算符(包括卷积、矩阵乘、激活函数、下采样和拼接)运行;同时,量化对象包含实数与矩阵乘法等类型。则以激活函数 Relu 为例,传统、实数量化、矩阵乘法量化等三种前向推导流程如图 4 所示。

图 4 量化前向推导流程
TensorFlow 模型量化分为两种;
Post-training quantization (训练后量化、离线量化);
Quantization-aware training (训练时量化,伪量化,在线量化)
5. TensorFlow 训练后量化
训练后量化,又叫做离线量化,根据量化零点是否为 0;离线量化分为对称量化和非对称量化;根据数据通道顺序 NHWC 上 C 这一维度上区分,离线量化分为逐层量化和逐通道量化;我们看到在 nvidia 的 TensorRT 中使用了逐层量化的方法,每一层采用同一个阈值来进行量化。逐通道量化就是对每一层每个通道都有各自的阈值,对精度可以有一个很好的提升。
对称量化的解释如下:

图 5.1 对称量化的解释
简单的将一个 tensor 中的 -max(|X|) 和 max(|X|) FP32 value 映射为 -127 和 127 ,中间值按照线性关系进行映射,称这种映射关系是对称量化。
一般来说,TensorFlow 权重 w 使用对称量化,逐层量化,FeatureMap 也就是 x 使用非对称量化,逐通道量化;这样做的好处是 权重 w 的量化零点为 0 ,可以减少计算次数,起到算法加速的目的,FeatureMap 采用逐通道量化是为了提高精度;量化后模型 int8 表示权重 (w),uint8 表示输入 (FeatureMap, x)。
int8 量化使用以下公式近似表示浮点值:
1real_value = (int8_value - zero_point)*scale
zero_point 表示量化零点,scale 表示量化尺度,real_value 实际 float 数值,int8_value 是量化后的整数值。该表示法包含两个主要部分:
权重 w 由 int8 的二进制补码值表示的每轴(即每通道)或张量权重,范围为 [-127, 127],量化零点等于 0。
输入 x(FeatureMap) 由 int8 的二进制补码值表示的每个张量激活/输入,范围在 [-128, 127] 中,量化零点在 [-128, 127] 范围内。
TensorFlow 训练后量化是针对已训练好的模型来说的,针对大部分我们已训练未做任何处理的模型来说均可用此方法进行模型量化,而 TensorFlow 提供了一整套完整的模型量化工具,如 TensorFlow Model Optimization Toolkit 以及 TensorFlow Lite converter 等实现了其中的几种方式,加速性能见下表:
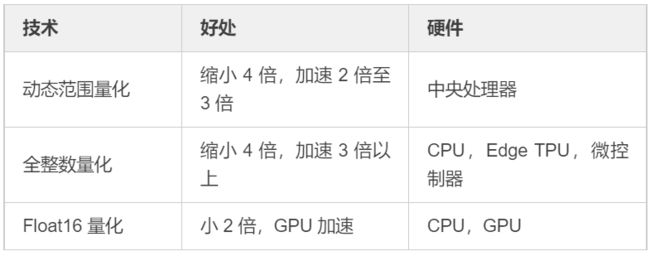
选择何种方式,需要结合业务场景及所拥有的硬件资源,目的是以最小损失达到最大化模型量化效果,官方提供了一棵决策树用于选择不同的训练后量化方式,实作中可进行参考。训练后量化方式的选择方式如下:

图 5.2 训练后量化方式的选择方式
6. TensorFlow 训练时量化
训练时量化 (Quantization-aware Training),又叫做在线量化,其中包括四个步骤:
对于TensorFlow 1.X 可以使用以下步骤
用常规方法训练一个 TensorFlow 浮点模型。
用 tf.contrib.quantize 重写网络以插入Fake-Quant 节点并训练 min/max。
用 TensorFlow Lite 工具量化网络,该工具读取步骤 2 训练的 min/max。
用 TensorFlow Lite 部署量化的网络。
对于 TensorFlow 2.X 可以使用以下步骤:
使用 tf.keras 训练一个浮点模型;
使用新的 quantization aware training API 6 在第一步训练的模型上迁移训练;
使用 tf.lite.TFLiteConverter.from_keras_model 将第二步的模型导出为量化的模型;
用 TensorFlow Lite 部署量化的模型
此外我们还可以在 Quantization-aware Training 过程中引入 乘法变移位法 (Turning Multiplications Into Bit Shifts) 的量化方式,直接将权重 w 量化成二进制位的形式,把所有的权重 w 全部变为 2 的 n 次方或者 2 的负 n 次方,把乘法变成移位运算,加速计算过程,减少资源占用。
训练时量化 (Quantization-aware Training),其中网络的前向 (Forward) 模拟 INT8 计算,反向 (Backward) 仍然是 FP32 。下图左半部分是量化网络,它接收 INT8 输入和权重并生成 INT8 输出。下图右半部分是步骤 2 重写的网络,其中 wt quant/act quant 节点在训练期间将 FP32 张量量化为 INT8,进行截断,产生损失,接下来反量化为FP32,进行反向传播。

图 6 训练时量化训练原理
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference 揭示了训练时量化的诸多细节。
7. 模型量化实战经验
由于量化是牺牲了部分精度来压缩和加速网络,因此不适合精度非常敏感的任务。量化目前最适合的数据集是图片和激光雷达点云数据,基于图片的 2d 目标检测、分类,可以做到掉点 1% 以内,基于激光点云的 3d 目标检测甚至几乎不掉点;
模型量化过程中一定会出现精度上掉点,第一种方法,可以尝试把 FeatureMap 的量化位宽从 int8 变为 fp16 等提高量化位宽,第二种方法是寻找 FeatureMap(输入,X)的最佳值域,通常有 kl 散度等方法,第三种方法是模型问题,权重分布上存在离群点,可以直接人为去除,或者重新训练模型,第四种方法是跳过某些重要的层不量化,例如注意力机制,尝试量化后面的层而不是前面的层等。
模型量化只是深度神经网络压缩和加速的一种方法,还有包括知识蒸馏、矩阵秩分解、网络剪枝、自动模型搜索技术等多种方法。但是量化是一种已经获得了工业界认可和使用的方法,在训练 (Training) 中使用 FP32,在推理 (Inference) 期间使用 INT8 这套量化体系已经被包括 TensorFlow,TensorRT,PyTorch,MxNet 等众多深度学习框架启用。
文末福利
11. 暑期2021 | NICT2021 嵌入式AI暑期学校期待您的加入!
原文: https://mp.weixin.qq.com/s/8YL1XI2iQX3_nBTRO_w7tQ
为扩展各高校学生视野,促进优秀大学生交流,南京集成电路培训基地将携手东南大学、电子科技大学、北京邮电大学、南京邮电大学、南京农业大学、意法半导体(中国)投资有限公司、上海睿赛德电子科技有限公司联合举办嵌入式AI系列“暑期学校”。本次暑期学校以STM32&RT-Thread为主题,将通过理论学习、案例学习、开发实践、交流讨论等多种形式,促进学生交流学习。
时间:2021年7月17日-7月24日
地点:南京集成电路培训基地
当前报名已经截止,希望报名成功的同学不要忘记提前预习预习相关知识哦!RT-Thread培训团队也在紧锣密鼓的准备中,希望能够给大家带来一次收获满满的暑期培训!


你可以添加微信17775982065为好友,注明:公司+姓名,拉进 RT-Thread 官方微信交流群!
???? 点击阅读原文进入RT-Thread官网